독자에게 미리 주의를 주는 바이다. 여러분이 C 프로그래밍 언어를 실제로 완전히 익혔다고 간주한다. C++ 주해서는 C 프로그래밍 언어가 끝나는 부분부터 시작한다. 다시 말해, 포인터라든가 기본적인 제어 흐름 그리고 함수 구조부터 시작한다.
어떤 요소들은 이 책에서 다루지 않는다. ({ 대신에 ??<를 사용하거나 } 대신에 ??>를 사용하는)) 세겹기호 그리고 ( [ 대신에 <:를 사용하거나 ] 대신에 >:를 사용하는) 두겹기호등과 같은 특정한 어휘 토큰은 이 책에서 다루지 않는다. 이런 토큰들은 C++ 소스 코드에 거의 등장하지 않기 때문이다. 게다가 세겹기호는 앞으로 C++17 표준에서 제거될 것이 거의 확실하다.
이 책의 버전 번호는 내용이 바뀔 때마다 갱신된다 (현재 10.9.0). 맨 앞의 번호는 핵심 번호이고 아마도 당분간 변경되지 않을 것이다. 크게 개작되었음을 의미하기 때문이다. 가운데 번호는 새로 정보가 추가되면 증가한다. 마지막 번호는 작은 변경이 있었음을 알린다. 오자나 탈자가 교정되면 마지막 번호가 증가한다.
이 책은 네델란드에 있는 그로닝겐 대학의 정보 기술 센터(Center of Information Technology)에서 출간하였다. GNU 공중 공개 라이선스의 보호를 받는다.
이 책의 식자는 yodl 포맷팅 시스템에 의하여 처리되었다.
이 책에 관하여 제안이나 추가하고 싶은 것 또는 개선하고 싶은 것이 있다면 모두 저자에게 알려 주시기 바란다.
Frank B. Brokken
Center of Information Technology,
University of Groningen
Nettelbosje 1,
P.O. Box 11044,
9700 CA Groningen
The Netherlands
(email: f.b.brokken@rug.nl)
이 장은 C++에 정의된 특징을 대략 살펴본다. 몇가지 C 확장을 검토하고 객체 기반의 프로그래밍 그리고 객체 지향 프로그래밍의 개념을 간략하게 소개한다.
g++ 컴파일러로 구현되었으므로 표준에 붙이던 참조를 제거했다. ( ptr_fun이나 random_shuffle 같이) C++17에서 더 이상 지원하지 않는 주제도 삭제했다. 람다 표현식을 `연산자 중복정의'로 이동했다 (제 11장). 람다 표현식은 이제 표준 구문 규칙을 사용하여 컴파일된다. STL에 제공되는 것처럼 미리 정의된 템플릿이 아니다. std::system_error에 관한 항을 재작성했고, 두 부분으로 나누어 한 쪽에는 편의기능을 소개했고 (제 10장), 다른 한 편에는 system_error가 인정하는 클래스를 어떻게 설계하는지 기술했다 (제 23장). STL에 관한 장에 std::(experimental::)filesystem 이름공간을 다루는 절을 추가했다 (제 18장).
random_shuffle을 더 이상 다루지 않는다.
new Type[size]()를 사용하여 할당된 POD 객체 배열을 초기화 하는 법; 그리고 명시적인 변환 연산자에 관하여 전반적인 설명을 추가했다.
std::localtime과 std::gmtime 그리고 std::put_time (20.1.5항)이 포함되며 put_time이 인식하는 형식 지정자 전체를 모두 표에 실었다.
cplusplus.css에 추가함으로써 어느 정도 세밀하게 조율이 가능해졌다.
std::placeholders 이름공간을 소개했으며 총칭 bind-바인더를 다루었다. C++11는 이제 사실상 현재의 C++ 표준이므로 명시적으로 기술하지 않게 되었다. C++14의 기술은 유지되며 앞으로 올 C++17 표준에 관한 언급이 포함되었다.
std::distance등, 몇가지 새로운 구문 요소들).
g++ 컴파일러에 구현되었다 (4.8.2). 그렇지만 컴파일러가 C++11 확장을 활성화하기를 원한다면 --std=c++11 컴파일러 옵션이 여전히 필요함을 주의하라.
noexcept에 관한 항을 추가. throw 리스트 비추천. 문자열에 관한 장도 업데이트 했다.
Allocators). make_shared과 shared_ptr 그리고 (new)를 조합해 설명.
make_shared에 관한 절을 새로 추가. shared_ptr과 new를 조합함.
static_cast와 reinterpret_cast 설명을 더 세련되게 다듬었다.
flex를 사용하던 절들은 이제 flexc++를 사용한다 (24.8절).
g++ 컴파일러 버전 4.7에 구현된 언어의 여러 요소들을 기술하는 절이 새로 여럿 추가됨. 이 책의 내용에서 이런 절은 C++11, 4.7로 명료하게 표식을 붙였다. 단순히 C++11 표식만 붙은 절은 적어도 Gnu 컴파일러 버전 4.6에서 사용할 수 있다고 간주해도 좋다. C++, ?으로 표식이 붙은 절은 C++11 (C++11) 표준에서 아직 Gnu g++ 컴파일러에 구현되지 않았다는 뜻이다. 이제 C++11은 새 표준의 `공식적인' 이름이므로 C++0x이라고 참조되던 것들은 C++11로 교체되었다.
다양한 정수 유형의 한계치는 종종 <climits> 헤더 파일에 설정된 #define을 사용하여 얻는다. 그렇지만, numeric_limits 템플릿은 (더 좋은) 대안을 제공한다. numeric_limits은 템플릿을 정의할 때에도 사용할 수 있기 때문이다. 자세한 것은 제 21장을 참고하라.
배포본의 ./contributions 디렉토리에 깔끔하게 제본된 C++ 주해서 책을 만들기 위해서 주렌 복마(Jurjen Bokma (jurjen dot bokma at rug dot nl))의 'makebook' 요리법을 추가했다. 결과는 감동적이다! 주렌(Jurjen)에게 감사의 말씀을 전한다!
지금부터 `무엇이 새로운가'에서 변경 사항들은 현재와 이전의 주요 배포본으로 제한했다. 이전의 변경 사항은 배포본의 whatsnew.yo.old 파일에서 보실 수 있다.
마지막으로 오자를 교정했다.
(절대로 변경이 되지 않을 문맥에서 객체를 변경 불능으로 적절하게 선언하는) 상수-정합성의 원칙은 언제나 볼 수 있었다. operator+와 같은 산술 이항 연산자의 이진 값은 항상 const로 정의하였다. 여기에서 C++ 주해서는 또다른 원리를 적용했다. `정수가 하는대로 하라'. 두 개의 int-값을 더할 때 그 결과는 관례적으로 변경 불가능으로 간주된다. 즉, (a + 5) += 4는 의미가 없다. 컴파일러는 컴파일을 거부한다. 그러나 a + 5은 상수인가? 이 문제에 간단하게 대답할 수는 없다. C++11이 출현하기 전에는 `그렇다'라고 대답했을 테지만, 충분히 이상하게도 그 대답은 언제나 `그런 것은' 아니다. 위의 a가 유형이 std::string이라면 (a + "b") += "c"는 놀랍게도 컴파일러가 허용한다. C++ 주해서는 이런 전략을 채택하지 않았지만 값을 돌려주는 함수의 반환 값을 const 값으로 정의함으로써 `정수가 하는대로 하라'의 규칙을 지켰다.
C++11에 rvalue 참조가 추가되었다. 필자는 결국 const 반환 값을 정의하는 것은 일반적으로 피하는 것이 좋다고 확신하게 되었다. C++11은 임시로 rvalue 참조에 연관되는 것을 허용하기 때문에 완전히 새로운 상황에 직면한다. 갑자기 중간 단계의 int 값이 변경이 가능하게 되었다. 다음 코드가 보여주듯이 말이다.
void fun(int &&tmp)
{
tmp += 4; // 컴파일 OK
}
int main()
{
int a = 8;
fun(a + 5);
}
이 코드는 또한 rvalue 참조를 `Type &&' 유형의 객체로 표준적으로 정의하는 방법을 보여준다. rvalue 참조 매개변수를 이런 식으로 정의하는 방법은 이제 값을 반환하는 함수의 반환 유형을 비-상수로 사용하는 것과 함께 C++ 주해서 곳곳에 사용된다.
많은 독자들이 8.3.1 버전 출시 이후로 개선을 제안해 주셨다. 여러분 모두에게 `감사를 드리지만', 특히 프란시스코 폴리(Francesco Poli)에게 감사드린다. 그는 거의 이년 간이나 개선을 열정적으로 제안해 주셨다. 그의 제안은 C++ 주해서의 거의 모든 부분을 개선하는데 귀중한 자원이 되었다. 이 문서를 개선하는데 열정을 다해 준 프란시스코에게 감사를 드리는 바이다!
결국 9.0.0 버전에서 새로 절이 추가되고 어떤 곳은 이동했다. 무제한 공용체(unrestricted unions)에 관한 절이 완성되었고 `컨테이너' 장으로 이동했다. 함수 템플릿을 이용한 이항 연산자를 클래스에 추가하는 방법에 관한 절이 마지막 장에 새로 추가되었다 (실전 예제).
g++ 컴파일러 버전 4.4를 사용한다고 간주한다. C++-0x 표준 요소가 버전 4.4 이상이기를 요구하면 요구된 버전은 이미 알고 있더라도 명시적으로 언급한다. 수 많은 독자들이 보내온 여러 제안을 반영하였다. C++ 주해서의 품질을 개선하기 위해 도와준 모든 분에게 감사한다!
shared_ptrs 유형변환에 관한 항과 ( 18.4.5항) 객체 배열 공유에 관한 항이 (18.4.6항) 추가되었다.
endl을 '\n'으로 교체했고 가상 함수에 비밀(private) 속성을 부여했다. 등등. 라벨이 C++11인 절들이 개선되었고 C++11을 보여주는 절들은 이제 새 특징을 사용할 수 있는 g++ 버전을 언급한다. 아직 잘 모를 경우는 ?를 사용했다. 이미 g++ 4.3에서 (또는 4.3.3 같은 하위 배포본에서) 해당 특징을 사용할 수 있으면 아무 표식이 없다. 필자는 프란시스코 폴리(Francesco Poli)로부터 수 많은 제안을 받았다 (필자가 교정할 수 있도록 프란시스코와 (기타 여러분들)이 보내 준 열정과 노력에 감사드리는 바이다).
http://en.wikipedia.org/wiki/C++11) (부분적으로) Gnu g++ 컴파일러에서 사용할 수 있게 되었다. 이 결과를 반영한 버전이다 (http://gcc.gnu.org/projects/cxx0x.html). (비공식적으로 C++0x 표준이라고 불리우는) 새 표준의 모든 요소들을 지금 당장 사용할 수 있는 것은 아니다. C++ 주해서의 새 배포본에 한 번 이상 나타나는 요소들은 g++ 컴파일러로 구현된다. 2.2.3항에서 새 표준을 활성화하는 법을 보여준다. 새 표준의 요소들을 다루는 새 항들은 C++11을 항 제목에 보여준다.
그리고 새로 두 개의 장을 추가했다. STL 장은 이제 두 개로 분할된다. STL 장은 STL만 다루고 총칭 알고리즘은 다른 장에 따로 다룬다. 원래 개론 장에 다루던 이름 공간은 이제 별도의 장으로 다룬다.
C++는 원래 `프리-컴파일러'로서 C의 프리-프로세서와 비슷하다. 소스 코드에서 특별한 구조를 평범한 C로 변환한다. 그 다음에 이 코드는 표준 C 컴파일러로 컴파일되었다. C++ 프리-컴파일러가 읽어 들이는 `프리-코드'는 일반적으로 확장자가 .cc, .C 또는 .cpp인 파일에 위치했다. 이 파일은 그러면 확장자가 .c인 C 소스 파일로 변환되었다. 그 위에 컴파일되고 링크되었다.
C++ 소스 파일의 유산은 살아 남아서 확장자 .cc와 .cpp가 여전히 사용된다. 그렇지만, C++ 프리-컴파일러의 선작업은 오늘날 실제 컴파일 시간에 수행된다. 종종 컴파일러는 확장자를 보고 소스 파일에 사용된 언어를 식별한다. 이 사실은 볼랜드사와 마이크로소프트사의 C++ 컴파일러에도 적용된다. C++ 소스 파일의 확장자가 .cpp라고 간주한다. Gnu 컴파일러인 g++은 오늘날 많은 유닉스 플랫폼에서 사용할 수 있다. 이 컴파일러는 C++의 확장자를 .cc라고 간주한다.
C++ 언어가 한 때 C 코드로 컴파일되었다는 사실은 C++ 언어가 C 언어의 상위 집합이라는 사실에서도 볼 수 있다. C++는 C 문법을 거의 완벽하게 제공하고 모든 C-라이브러리 함수를 지원하며 거기에 C++만의 특징을 추가한다. 이 덕분에 C에서 C++로 손쉽게 이전할 수 있다. C에 익숙한 프로그래머라면 .c 확장자 대신에 확장자가 .cc나 .cpp인 소스 파일을 사용하여 `C++ 프로그래밍'을 시작하면 된다. 그러면 C++가 제공하는 모든 가능성을 매끄럽게 익힐 수 있다. 익숙한 습관을 갑자기 바꾸지 않아도 된다.
LaTeX를 사용하여 작성했다. 시간이 지나자 카렐은 1994년 9월 (당연히) 영어로 본문을 재작성했다.
이 가이드의 첫 버전이 1994년 10월에 인터넷에 올라왔다. 그 때쯤 SGML로 변환되었다.
점차 장들이 새로 추가되고 내용이 변경되어 더욱 개선되었다 (아낌없이 의견을 보내 준 독자 여러분 덕분이다).
버전 4에서 프랭크는 새 장들을 추가했고 문서를 SGML에서 yodl로 변환했다.
C++ 주해서는 자유롭게 배포해도 된다. 법률 고지를 꼭 읽어 보시기 바란다.이 문서가 마음에 들면 친구들에게 소개하라. 필자에게 이메일을 보내 알려 주면 더 좋다.이 시점을 넘어서 계속 읽고 계시다면 해당 법률 고지를 인지하고 있고 동의한다는 뜻이다.
.cc로 바꾸고 그 파일을 C++ 컴파일러를 통하여 실행하면 몇 가지 차이를 만나게 될 것이다.
sizeof('c')는 sizeof(int)와 동등하다. 'c'가 ASCII 문자이기만 하면 된다. 그 아래에 깔린 생각은 아마도 함수에 인자로 char를 건네면 그것은 어쨌든 정수라는 것이다. 게다가 C 컴파일러는 'c'와 같은 문자 상수를 정수 상수로 취급한다. 그러므로 C에서 다음 함수 호출은
putchar(10);
다음과 동등하다.
putchar('\n');
대조적으로 C++에서 sizeof('c')는 언제나 1이다 (3.4.2항). 그렇지만 int는 여전히 int이다. 나중에 보겠지만 (2.5.4항) 아래의 함수 호출은
somefunc(10);
다음 함수 호출과
somefunc('\n');
서로 다른 함수로 취급된다. C++는 함수를 구별하는데 함수 이름은 물론 인자의 유형도 사용한다. 이 때문에 이 두 함수의 호출이 달라진다. 앞의 함수는 int 인자를 사용하고 뒤의 함수는 char 인자를 사용한다.
void func();
func()라는 함수가 존재하고 값을 돌려주지 않는다는 뜻이다. 이 선언은 함수가 (있더라도) 어떤 인자를 받는지 지정하지 않는다.
그렇지만 C++에서 위의 선언은 func() 함수가 인자를 전혀 받지 않는다는 뜻이다. 거기에 인자를 건네면 컴파일 시간 에러를 일으킨다.
함수를 선언할 때 extern 키워드를 요구하지 않음을 주목하라. 함수 정의는 그냥 함수의 몸체를 쌍반점으로 교체하면 함수 선언이 된다. 그렇지만 변수를 선언할 때는 extern 키워드가 필요하다.
C++14 표준의 특징을 사용하려면 컴파일러에 --std=c++14 옵션을 제공해야 한다. C++17 표준을 활성화하려면 --std=c++17 옵션을 지정하라. C++ 주해서는 예제를 컴파일할 때 이 옵션이 사용된다고 간주한다.
g++ 컴파일러의 윈도우즈 이식본을 위한 토대를 제공한다.
무료 g++ 컴파일러를 얻기 위해 위의 URL에 방문하면 install now 버튼을 클릭하라. 이렇게 하면 setup.exe 파일을 내려 받는데, 이 파일을 실행하면 cygwin을 설치할 수 있다. 설치될 소프트웨어는 인터넷으로부터 setup.exe를 통하여 내려 받을 수 있다. 다른 방법도 있다 (예를 들어, CD-ROM을 이용). 다른 방법은 Cygwin 페이지에 기술되어 있다. 설치는 대화식으로 진행된다. 제안하는 기본값이 합리적이며 별 다른 이유가 없다면 받아 들이는 편이 좋다.
최신의 Gnu g++ 컴파일러는 http://gcc.gnu.org에서 얻을 수 있다. Cygnus 배포판에서 얻은 컴파일러가 최신 버전에 비해 느린 감이 있다면 최신 버전의 소스를 내려 받아 이미 있는 컴파일러로 새 컴파일러를 빌드할 수 있다. (위에 언급한) 컴파일러의 웹 페이지를 보면 처리하는 법을 자세하게 볼 수 있다. 필자의 경험에 의하면 새 컴파일러를 Cygnus 환경에서 빌드하면 깔끔하게 작동한다.
source.cc'을 컴파일할 수 있다.
g++ source.cc
이렇게 하면 이진 프로그램이 생산된다 (a.out 또는 a.exe). 기본 이름이 마음에 안들면 -o 플래그를 사용하여 실행 파일의 이름을 지정할 수 있다 (여기에서는 프로그램을 source로 생산함):
g++ -o source source.cc
단순히 컴파일만 필요하면 컴파일된 모듈은 다음 -c 옵션으로 생산할 수 있다.
g++ -c source.cc
이렇게 하면 파일 source.o가 생성된다. 나중에 다른 모듈에 링크할 수 있다. 지적했듯이 컴파일러 옵션으로 --std=c++11 (주의: 옆줄 두 개)를 제공하면 C++11 표준의 특징을 활성화할 수 있다. 또 --std=c++14를 지정하면 C++14 표준의 특징이 활성화된다. --std=c++17을 지정하면 더 최신의 C++17 표준을 사용하여 소스를 컴파일할 수도 있다 (권장함).
C++ 프로그램은 순식간에 너무 복잡해져서 `수작업'으로 관리할 수 없다. 무게감 있는 모든 프로그래밍 프로젝트에 프로그램 관리 도구가 사용된다. 표준적인 make 프로그램을 사용하여 C++ 프로그램을 관리하는 것이 보통이지만 좋은 대안이 있다. 예를 들어 icmake
또는 ccbuild 프로그램 관리 유틸리티가 있다.
C++를 연구하면서 관리 유틸티리를 사용하시기를 적극 권고한다.
g++ 컴파일러에 활성화시키려면 --std=c++14를 지정하면 된다.
C++ 주해서는 C++14 표준에 관련된 변경사항들을 반영했다. C++14 표준이 언급되는 곳이면 인덱스에서 C++14 항목을 참고하라.
현재 표준은 C++17이다. C++ 주해서의 여러 곳에서 C++17 표준을 언급한다. C++ 주해서의 인덱스를 보면 C++17에 적절한 항목으로 빠르게 갈 수 있다. C++17 표준을 Gnu의 g++ 컴파일러에 활성화시키려면 --std=c++17을 지정하라.
그렇지만 위의 C++와 관련하여 다음과 같이 지원한다.
struct나 typedef 등등을 사용하면 된다. 그래서 이런 유형들로부터 다른 유형을 파생시킬 수 있다. struct 안에 struct등등의 유형을 파생시킨다. C++에서 이런 편의기능들은 자체로 책임지고 자동으로 메모리를 관리하는 데이터 유형을 정의하면서 점점 불어난다 (예를 들어 Java에서 사용하듯이 독립적으로 작동하는 메모리 관리 시스템에 의존할 필요가 없다.).
xmalloc과 xrealloc 같은 C 전용 함수를 사용할 때 그렇다 (메모리 풀이 고갈되면 메모리를 할당하거나 프로그램을 끝낸다.). 그렇지만 malloc 같은 함수는 실수하기가 쉽다. C 프로그램에서 자주 일어나는 에러들은 추적해 들어가 보면 malloc을 사용할 때 계산을 잘못했기 때문인 경우가 많다. 대신에 C++는 operator new를 사용하여 메모리를 안전하게 할당하는 편의기능이 있다.
static 변수를 사용할 수 있으며 전용 함수로 struct와 같은 데이터 유형을 조작할 수 있다. 그런 테크닉을 사용하면 데이터 은닉을 C에서도 구현할 수 있다. 그렇지만 C++는 특별한 구문을 제공하며 그래서 C보다 C++에서 훨씬 더 쉽게 `데이터 은닉'을 구현할 수 있다는 사실을 인정하지 않을 수 없다 (일반적으로 `캡슐화'는 더욱 그렇다).
C에서 C++로 이전할 때 이 책이 독자들에게 도움이 되기를 바란다. C에 비하여 C++에 추가된 것들에 초점을 두고 평범한 C는 다루지 않았다. 모쪼록 독자 여러분이 이 책을 좋아하고 혜택을 누리시기를 바라는 바이다.
C++로의 여행을 즐기시고 좋은 결과를 얻으시기를 바란다!
static 변수를) 통하여 통신한다.
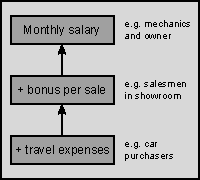
이와 대조적으로 객체 기반의 접근법은 문제 서술에 사용된 핵심어( keywords)들을 식별한다. 이런 핵심어들은 다이어그램에 묘사되고 화살표를 핵심어 사이에 그려서 내부적인 계통도를 묘사한다. 핵심어들은 구현에서 객체가 되고 계통도로 이 객체들 사이의 관계가 정의된다. 객체라는 용어로 정의가 잘된 구조체를 기술한다. 여기에 한 객체에 관한 모든 정보를 즉, 데이터 유형과 그 데이터를 조작할 함수들을 담는다. 객체 지향 접근법의 예를 들어 보자:
위의 월급 관리를 표현한다면 키워드는 mechanics, owner, salesmen 그리고 purchasers가 될 것이다. 각 특성은 다음과 같다. 월급과 구매나 판매에 따른 보너스 그리고 출장 경비 보상이 있다. 이런 방식으로 문제를 분석하면 다음과 같은 표현에 다다른다.자동차 중개와 수리를 하는 회사의 사원과 사장은 다음과 같이 보수를 받는다.
- 첫째, 차고에서 일하는 정비공은 매달 일정한 보수를 받는다.
- 둘째, 사장은 고정 월급을 받는다.
- 셋째, 전시장에서 일하는 판매 사원이 있고 매달 월급에 차를 팔 때마다 보너스를 더 받는다.
- 마지막으로, 돌아다니며 중고차를 사들이는 구매 사원이 있다. 구매 사원은 매달 월급을 받고 차를 살 때마다 보너스를 받으며 출장 경비를 보상받는다.
객체 계통도에서 앞 두 객체 사이에 의존성을 정의할 수 있다. 판매 사원은 사장과 정비공으로부터 `파생시킬 수 있다'.
위와 같은 계통도를 정의하는데 있어서 전반적인 처리는 가장 간단한 유형을 기술하면서 시작한다. 전통적으로 더 복잡한 유형은 기본 집합으로부터 파생시킨다 (객체 지향 언어에서 여전히 인기가 있다). 파생시킬 때마다 약간의 기능을 추가한다. 전체 문제가 표현될 때까지 이 파생 유형으로부터 더 복잡한 유형을 무한대로 파생시킬 수 있다. 그렇지만 해가 갈 수록 이런 접근법은 C++에서 인기를 잃고 있다. 전형적으로 결합도가 과도하게 높아져서, 복잡한 프로그램의 이해와 유지 관리 그리고 테스트 가능성을 개선하기는 커녕 오히려 줄이는 결과가 되었기 때문이다. C++에서 객체 지향 프로그램은 점점 더 작고 이해하기 쉬운 계통도와 절제된 결합 그리고 디자인 패턴이 주요한 역할을 하는 개발 과정이 인기를 점점 더 끌게 되었다 (참조 Gamma et al. (1995)).
그럼에도 C++에서 클래스는 객체의 특징을 정의하는데 자주 사용된다. 클래스는 유용한 일을 하기 위해 필요한 기능을 포함한다. 클래스는 일반적으로 다른 클래스의 객체에 모든 기능을 제공하지는 않는다 (그리고 전형적으로 자신의 데이터는 제공하지 않는다). 앞으로 보듯이 클래스는 바깥 세계에서 직접적으로 수정할 수 없도록 자신의 특성을 숨긴다. 대신에 전용 함수를 사용하여 객체의 특성에 접근하거나 수정한다. 그리하여 클래스-유형의 객체는 자신의 정합성을 유지한다. 여기에서 핵심 개념은 캡슐화이다. 데이터 은닉은 그저 한 예에 불과하다. 이런 개념은 제 7 장에 더 자세히 설정한다.
main 함수가 두 가지 형태만 있다. 하나는 int main()이고 다른 하나는 int main(int argc, char **argv)이다.
주의:
main 함수의 반환 유형은 int이며, void가 아니다;
main 함수는 중복정의할 수 없다 (위에 언급된 서명은 제외한다);
main 함수가 끝날 때 명시적으로 return 서술문을 사용하지 않아도 된다. 생략하면 0을 돌려준다.
argv[argc]의 값은 0이다.
char **envp 매개변수'는 표준으로 정의되는 것이 아니며 피해야 한다. 대신에, 전역 변수 extern char **environ을 선언해서 프로그램의 환경 변수에 접근할 수 있도록 해 주어야 한다. 마지막 원소는 값이 0이다.
main 함수가 반환되면 정상으로 종료한다. main에 function try block을 사용하는 것도 역시 정상적으로 C++ 프로그램을 끝내는 것으로 간주된다 (10.11절). C++가 정상적으로 종료할 때 (9.2절) 전역에 정의된 객체의 소멸자가 활성화된다. exit(3) 같은 함수는 C++ 프로그램을 정상으로 끝내지 않는다. 그러므로 그런 함수를 사용하는 것은 추천하지 않는다.
//으로 시작하고 줄끝 표식에서 끝난다. 표준 C 주석은 /*와 */으로 구분되는데 여전히 C++에 사용된다.
int main()
{
// 이것은 줄끝 주석이다.
// 한 줄 짜리 주석
/*
이것은 표준-C 주석이다.
여러 줄에 걸친다.
*/
}
예제는 이렇지만, C++ 함수 안에 C 형식의 주석은 사용하지 않기를 권한다. 가끔 기존의 코드를 임시로 억제해야 할 경우가 있다. 예를 들어 테스트를 하기 위해서라면 표준 C 주석을 사용할 수 있으며 아주 실용적이다. 그렇게 억제된 코드에 자체로 또 그런 여러 줄 주석이 들어 있다면, 주석 줄이 내포되어 있기 때문에 컴파일 에러가 일어날 것이다. 그러므로 지켜야할 규칙은 C 유형의 주석을 C++ 함수 안에 사용하지 않는 것이다 (물론 다른 방법으로 #if 0부터 #endif까지 프리-프로세서 지시어 쌍을 사용해도 된다).
int main()
{
printf("Hello World\n");
}
C 아래에서는 printf() 함수를 알지 못한다는 경고가 따르지만 컴파일은 된다. 그러나 C++ 컴파일러는 (당연히) 코드를 만들어 내지 못한다. 물론 이 에러는 #include <stdio.h>가 없기 때문에 야기된다 (C++에서는 #include <cstdio> 지시어로 포함된다).
그와 동시에 이미 보았듯이 C++에서 main 함수는 언제나 int를 반환 값으로 사용한다. 물론 명시적으로 return 서술문을 정의하지 않아도 int main()를 정의할 수 있지만 main 안에서 명시적인 int-표현식 없이 return 서술문을 사용하는 것은 안된다. 예를 들어:
int main()
{
return; // 컴파일되지 않는다. int 표현식을 기대한다.
// 예를 들어, return 1;
}
const 속성에 따라 달라진다). 아래에 예제를 보여준다.
#include <stdio.h>
void show(int val)
{
printf("Integer: %d\n", val);
}
void show(double val)
{
printf("Double: %lf\n", val);
}
void show(char const *val)
{
printf("String: %s\n", val);
}
int main()
{
show(12);
show(3.1415);
show("Hello World!\n");
}
위의 프로그램에서 show라는 이름으로 함수 세 개가 정의되는데, 매개변수 리스트만 다르고 이름이 같다. 각각 int와 double 그리고 char *를 기대한다. 이름은 같지만 매개변수 리스트가 다른 함수를 중복정의(overloaded) 되었다고 부른다. 그런 함수를 정의하는 행위를 `함수 중복정의'라고 부른다.
C++ 컴파일러는 함수 중복정의를 약간 간단한 방식으로 구현한다. (예제에서 show를 공유하듯이) 함수는 이름을 공유하지만 컴파일러 (링커)는 완전히 다른 이름을 사용한다. 소스 파일의 이름을 내부적으로 사용되는 이름으로 변환하는 것을 `이름 변조(name mangling)'라고 부른다. 예를 들어 C++ 컴파일러는 원형 void show (int)를 내부 이름 VshowI로 변환할 수 있지만 반면에 char * 인자를 가진 비슷한 함수는 VshowCP로 부를 수 있다. 내부적으로 사용되는 실제 이름은 컴파일러가 결정한다. 이런 이름이 라이브러리 목록에 나타날 때를 제외하고는 프로그래머가 신경쓸 일이 아니다.
함수 중복정의에 관련하여 추가로 한 마디 하면:
show 함수는 여전히 서로 관련이 있다 (정보를 화면에 인쇄한다는 공통점이 있다).
그렇지만 lookup을 두 개의 함수로 정의하는 것도 가능하다. 하나는 리스트에서 이름을 찾고 다른 하나는 비디오 모드를 결정하도록 말이다. 이 경우 두 함수의 행위는 공통성이 전혀 없다. 그러므로 그 행위를 제시하는 이름을 사용하는 것이 더 실용적이다. 예를 들어 findname과 videoMode 정도면 좋을 듯하다.
printf("Hello World!\n");
printf 함수의 반환 값에 관하여 아무 정보도 없다. 그러므로 반환 유형만 달라서는 두 개의 printf를 컴파일러가 구분할 수 없을 것이다.
const 멤버 함수의 표기법을 소개했다 (7.7절). 여기에서는 클래스가 이른바 그와 연관된 멤버 함수를 가진다는 사실만을 언급해 둔다. (예를 들어, 제 5장 서론에서 그 개념을 참고하라). 중복정의 멤버 함수가 매개변수 리스트를 다르게 사용한다는 점만 제외하면 멤버 함수를 const 속성으로 중복정의하는 것도 가능하다. 그러면 클래스는 이름이 동일하고 매개변수 리스트도 역시 동일한 멤버 함수 한 쌍을 가질 수 있다. 이 함수들은 const 속성으로 중복정의된다. 그런 경우에 한 함수만 const 속성을 가져야 한다.
#include <stdio.h>
void showstring(char *str = "Hello World!\n");
int main()
{
showstring("Here's an explicit argument.\n");
showstring(); // 실제로 다음과 같다.
// showstring("Hello World!\n");
}
기본 인자를 정의한 곳에는 인자를 생략하더라도 아무 문제가 없다. 명시적으로 인자를 지정하지 않고 호출하면 빠진 인자를 공급하는 책임을 컴파일러가 진다. 기본 인자를 사용했다고 코드가 더 짧아지는 것도 아니고 더 효율적인 것도 아니다.
기본 인자를 여럿 정의할 수 있다.
void two_ints(int a = 1, int b = 4);
int main()
{
two_ints(); // 인자: 1, 4
two_ints(20); // 인자: 20, 4
two_ints(20, 5); // 인자: 20, 5
}
two_ints 함수를 호출하면 컴파일러는 하나 또는 두 개의 인자를 필요에 따라 공급한다. 그렇지만 two_ints(,6)과 같은 서술문은 허용되지 않는다. 다시 말해, 인자를 생략한다면 반드시 오른쪽부터 생략해야 한다.
기본 인자는 컴파일 시간에 알려져야 한다. 그 시점에 인자가 함수에 공급되기 때문이다. 그러므로 기본 인자는 함수를 구현할 때가 아니라 선언할 때 지정해야 한다.
// 샘플 헤더 파일
extern void two_ints(int a = 1, int b = 4);
// 예를 들어 two.cc에 있는 함수 코드
void two_ints(int a, int b)
{
...
}
함수를 정의할 때 기본 인자를 주는 것은 에러이다. 함수를 다른 소스가 사용할 때 컴파일러는 함수 정의가 아니라 헤더 파일을 읽기 때문이다. 결과적으로 컴파일러는 함수의 기본 인자 값을 결정할 방법이 없다. 현재 컴파일러는 함수 정의에서 기본 인자를 탐지하면 컴파일 시간 에러를 일으킨다.
0으로 코딩된다. C에서 NULL은 종종 포인터의 문맥에서 사용된다. 이 차이는 순전히 스타일의 문제이다. 그렇지만 널리 채택된 스타일이다. C++에서 NULL은 피해야 한다 (마크로이기 때문인데, 마크로는 C++에서 손쉽게 피할 수 있다 --그러므로 그렇게 하는 것이 좋다-- 8.1.4항). 대신에 0은 거의 언제나 사용할 수 있다.
그러나 거의 언제나이지 언제나는 아니다. C++는 함수 중복정의를 허용하므로 프로그래머는 2.5.4항에 보여준 상황에서 예상치 못한 함수 선택에 직면할 가능성이 있다.
#include <stdio.h>
void show(int val)
{
printf("Integer: %d\n", val);
}
void show(double val)
{
printf("Double: %lf\n", val);
}
void show(char const *val)
{
printf("String: %s\n", val);
}
int main()
{
show(12);
show(3.1415);
show("Hello World!\n");
}
이 상황에서 프로그래머가 show(char const *) 함수를 호출할 생각이라면 show(0) 함수를 호출할 것이다. 그러나 이것은 작동하지 않는다. 0이 int로 해석되고 그래서 show(int)가 호출된다. 그러나 show(NULL)를 호출해도 역시 작동하지 않는다. C++는 NULL을 0으로 정의하지 ((void *)0)으로 정의하지 않기 때문이다. 그래서 다시 또 show(int)가 호출된다. 이런 종류의 문제를 풀기 위하여 C++ 표준으로 nullptr 키워드가 새로 도입되었다. 0 포인터를 나타낸다. 현재 예제에서 프로그래머는 show(nullptr)을 호출해야만 올바르게 함수를 선택할 수 있다. nullptr 값은 또 포인터 변수를 초기화하는 데에도 사용할 수 있다. 예를 들어,
int *ip = nullptr; // OK
int value = nullptr; // 에러: 값이 포인터가 아님
void func();
선언된 함수의 원형에 인자 리스트가 없다는 뜻이다. 그러므로 이런 원형을 사용하는 함수에 대하여 컴파일러는 인자에 상관없이 func를 호출하더라도 경고하지 않는다. C에서 함수를 전혀 인자 없이 명시적으로 선언하고 싶다면 다음과 같이 void 키워드가 사용된다.
void func(void);
C++는 정적 유형 점검을 강제하기 때문에 빈 매개변수 리스트는 매개변수가 완전히 없음을 나타낸다. 그러므로 void 키워드는 생략된다.
__cplusplus 심볼이 정의되어 있다. 마치 소스 파일마다 앞에 #define __cplusplus 전처리기 지시어가 붙은 것처럼 말이다.
이 심볼의 사용법을 다음 항에서 살펴 보겠다.
예를 들어 다음의 조각 코드는 xmalloc 함수를 C 함수로 선언한다.
extern "C" void *xmalloc(int size);
이 선언은 C에서의 선언과 유사하다. 원형 앞에 extern "C"가 붙는다는 점만 제외하면 말이다.
약간 다른 방식으로 C 함수를 선언하는 방법은 다음과 같다.
extern "C"
{
// C-선언은 여기에 둔다.
}
전처리 지시어를 선언의 위치에 놓아도 된다. 예를 들어 C 언어 myheader.h 헤더 파일에 C 함수가 선언되어 있다면 다음과 같이 C++ 소스 파일에 포함시킬 수 있다.
extern "C"
{
#include <myheader.h>
}
두 방법을 모두 사용할 수 있지만 실제로는 C++ 소스 파일에서 만날 일이 거의 없다. 외부의 C 함수를 선언하기 위해 더 자주 사용되는 방법은 다음 항에서 만난다.
__cplusplus 심볼과 extern "C" 함수를 조합하면 C와 C++ 모두를 위해 헤더 파일을 만들 수 있다. 헤더 파일에 C와 C++ 프로그램 모두에 사용될 일군의 함수를 선언할 수 있다.
그런 헤더 파일 설정은 다음과 같다.
#ifdef __cplusplus
extern "C"
{
#endif
/* C-데이터와 함수 선언은 여기에 삽입한다. 예를 들어, */
void *xmalloc(int size);
#ifdef __cplusplus
}
#endif
이 설정을 사용하여 정상 C 헤더 파일은 파일의 상단에서 extern "C" {와 그리고 파일 하단에서 }로 둘러 싸인다. #ifdef 지시어는 C인지 C++인지 컴파일의 종류를 테스트한다. `표준' C 헤더 파일, 예를 들어 stdio.h같은 파일은 이런 식으로 구성되었고 그러므로 C와 C++에 모두 사용할 수 있다.
그리고 C++ 헤더는 삽입 보호기능을 제공해야 한다. C++에서 같은 소스 파일에 같은 헤더 파일을 두 번 포함하는 것은 바람직하지 않다. 헤더가 중복 삽입되는 문제는 헤더 파일에 #ifndef 지시어를 사용하면 쉽게 피할 수 있다. 예를 들어:
#ifndef MYHEADER_H_
#define MYHEADER_H_
// #ifdef __cplusplus 등등의 지시어를 사용하여
// 헤더 파일의 선언은 여기에 삽입된다,
#endif
이 파일을 전처리기가 처음 스캔할 때 심볼 MYHEADER_H_는 아직 정의되어 있지 않다. #ifndef 조건은 성공하고 모든 선언이 스캔된다. 그리고 심볼 MYHEADER_H_가 정의된다.
같은 소스 파일을 컴파일하는 동안 다시 이 파일을 스캔할 때 심볼 MYHEADER_H_가 이미 정의되어 있기 때문에 결과적으로 컴파일러는 #ifndef와 #endif 사이의 모든 정보를 버린다.
이 문맥에서 심볼 이름 MYHEADER_H_는 인지의 목적으로만 기여한다. 그러려면 헤더 파일의 이름을 대문자로 하고 점 대신에 밑줄 문자를 사용하면 된다.
이 외에도 관례는 C 헤더 파일에 확장자 .h를 주고 C++ 헤더 파일에 확장자를 부여하지 않도록 진화하였다. 예를 들어 표준 iostream으로서 cin과 cout 그리고 cerr는 iostream.h가 아니라 iostream 헤더를 포함한 후에야 사용할 수 있다. 이 책은 표준 C++ 헤더 파일에 이 관례를 사용하지만 모든 곳에 꼭 그렇게 하는 것은 아니다.
헤더 파일에 관하여 할 말이 아직 많이 남아 있다. 7.11절에 C++ 헤더 파일을 조직하는 방법을 깊이 연구한다.
게다가 지역 변수는 사용하기 바로 전에 서술문 안에 정의할 수 있다. 전형적인 예는 for 서술문이다.
#include <stdio.h>
int main()
{
for (int i = 0; i < 20; ++i)
printf("%d\n", i);
}
이 프로그램에서 i 변수는 for 서술문의 초기화 부분에 생성된다. ANSI-표준에 따르면 이 변수는 for-서술문보다 먼저 존재하지 않고 for-서술문을 넘어서서 존재하지 않는다. 구형 컴파일러라면 이 변수가 for-서술문 이후에도 생존하는 경우가 있지만 오늘날에는 다음과 같이
warning: name lookup of `i' changed for new ANSI `for' scoping using obsolete binding at `i'변수가
경고: 새로운 ANSI `for' 영역에 `i'의 이름 찾기 방식이 변경됨. 폐기된 바인딩을 `i'에 사용함
for-회돌이 밖에 사용되면 경고가 따른다.
그 의미는 명백하다. 서술문을 넘어서서 해당 변수를 사용해야 한다면 for-서술문 바로 앞에 정의하라. 그렇지 않으면 변수는 for-서술문 안에 정의해야 한다. 이렇게 되도록이면 생존 영역을 좁혀주는 것은 아주 바람직한 특징이다.
필요할 때 지역 변수를 정의하려면 좀 익숙해져야 한다. 그렇지만 결국 가독성이 더 좋아지고 유지보수가 더 편해지며 더 효율적인 코드를 생산하는 경향이 있다. 지역 변수를 정의할 때 다음과 같은 규칙을 따르기를 권고한다.
for-서술문은 물론이고 함수를 통하여 부분적으로만 변수가 필요한 모든 상황에 적용된다.
잘 생각해 보면, 보조 변수를 지역화하는 데 내포된 블록을 사용할 수 있다. 그렇지만 어떤 경우는 내포된 서술문 안에 지역 변수가 적절하다고 생각되는 상황이 존재한다. 물론 방금 언급한 for 서술문이 해당 사례이지만 지역 변수는 if-else 서술문 안의 조건 절과 switch 서술문 안의 선택 절 그리고 while 서술문 안의 조건 절에도 정의할 수 있다. 그런 식으로 정의된 변수는 내포된 서술문을 포함하여 완전한 서술문에 사용할 수 있다. 예를 들어 다음의 switch 서술문을 연구해 보자:
#include <stdio.h>
int main()
{
switch (int c = getchar())
{
case 'a':
case 'e':
case 'i':
case 'o':
case 'u':
printf("Saw vowel %c\n", c);
break;
case EOF:
printf("Saw EOF\n");
break;
case '0' ... '9':
printf("Saw number character %c\n", c);
break;
default:
printf("Saw other character, hex value 0x%2x\n", c);
}
}
`c' 문자의 정의가 위치한 곳을 눈여겨보라. switch 서술문의 표현식 부분에 정의되어 있다. 이것은 `c'를 내포된 (하위) 서술문을 포함하여 switch 서술문 안에서는 사용할 수 있지만 switch 바깥 영역에서는 사용할 수 없다는 뜻이다.
if와 while 서술문에도 같은 접근법을 사용할 수 있다. if와 while 서술문에서 조건 부분에 정의된 변수는 내포된 서술문에서 사용할 수 있다. 그렇지만 약점이 약간 있다.
if나 while 서술문에서 논리 조건을 평가할 수 있으려면 변수의 값이 0(false) 또는 0-아닌 값 (true)으로 해석이 가능해야 한다. 이것은 문제가 되지 않지만 C++에서 객체는 (std::string 유형의 객체 (제 5장)) 종종 함수에 의하여 반환된다. 그런 객체는 숫자 값으로 번역될 수도 있고 안될 수도 있다. 그렇지 않다면 (std::string 객체의 사례와 같이) 그런 변수는 조건 서술문이나 반복 서술문의 조건 또는 표현 절에 정의할 수 없다. 그러므로 다음 예제는 컴파일되지 않는다:
if (std::string myString = getString()) // getString이
{ // std::string 값을 돌려준다고 간주
// myString 처리
}
위의 예제는 설명이 더 필요하다. 변수는 지역 영역에 배치하는 것이 유익하지만 초기화한 다음 곧바로 더 점검할 필요가 있다. 초기화와 테스트를 모두 하나의 표현식에 조합해 넣을 수 없다. 대신에 내포된 서술문 두 개가 필요하다. 결과적으로 다음 예제도 역시 컴파일되지 않는다.
if ((int c = getchar()) && strchr("aeiou", c))
printf("Saw a vowel\n");
이런 상황이 일어나면 내포된 if 서술문을 두 개 사용하거나 아니면 내포된 복합 서술문을 사용하여 int c의 정의를 지역화하라.
if (int c = getchar()) // 내포된 if-서술문
if (strchr("aeiou", c))
printf("Saw a vowel\n");
{ // 내포된 복합 서술문
int c = getchar();
if (c && strchr("aeiou", c))
printf("Saw a vowel\n");
}
typedef 키워드는 여전히 C++에서 사용되지만 공용체(union)나 구조체(struct) 또는 열거체(enum)를 정의할 때 더 이상 필수 조건은 아니다. 다음 예제에서 이를 보여준다.
struct SomeStruct
{
int a;
double d;
char string[80];
};
struct나 union 또는 기타 복합 유형을 정의할 때 이런 유형의 태그를 유형 이름으로 사용할 수 있다 (다음은 위의 예제에 있는 SomeStruct이다):
SomeStruct what;
what.d = 3.1415;
struct Point의 정의를 아래에 조각 코드로 제공한다. 이 구조체는 int 데이터 필드 두 개와 draw 함수 하나를 선언한다.
struct Point // 화면 위의 점 하나 정의
{
int x; // 좌표
int y; // x/y
void draw(); // 그리기 함수
};
아마도 그리기 프로그램의 구조가 이와 비슷할 것이다. 예를 들어 픽셀을 나타낼 수 있다. 이 구조체(struct)에 관하여 주목할 것은 다음과 같다.
struct 정의 안에 언급된 draw 함수는 그저 선언에 불과하다. 조치를 수행할 함수의 실제 코드는 다른 곳에 있다 (struct 안의 함수라는 개념은 3.2절에 더 깊게 다룬다).
struct Point의 크기는 int 두 개의 크기와 같다. 구조체 안에 선언된 함수는 크기에 영향을 미치지 않는다. 컴파일러는 draw 함수를 Point라는 문맥 안에서만 허용한다.
Point 구조체는 다음과 같이 사용할 수 있다.
Point a; // 화면 위의
Point b; // 두 개의 점
a.x = 0; // 첫 번째 점을 정의하고
a.y = 10; // 그 점을 그린다.
a.draw();
b = a; // a를 b에 복사
b.y = 20; // y-좌표를 재정의하고
b.draw(); // 그 점을 그린다.
위의 예제에서 보듯이 구조체 안의 함수는 점 (.) 연산자를 사용하여 선택한다 (화살표 (->) 연산자는 객체를 포인터로 사용할 수 있을 때 사용된다). 그러므로 이것은 구조체의 데이터 필드를 선택하는 방식과 동일하다.
이 구문적 생성 방법 뒤에 숨은 아이디어는 여러 유형이 안에 이름이 동일한 함수를 포함할 수 있다는 것이다. 예를 들어 원을 나타내는 구조체는 세 개의 int 값을 포함할 수 있다. 두 개의 값은 원의 중심 좌표를 나타내고 나머지 하나는 반지름을 나타낸다. Point 구조체처럼 이제 Circle도 원을 그리는 draw 함수를 가질 수 있다.
g++ 컴파일러 (7.0.0 이후) 버전에 반영하는 작업이 진행 중이다.
작업 초안을 자유롭게 얻을 수 있다. 다음 깃 저장소 https://github.com/cplusplus/draft.git로부터 복제하면 된다.
그 사이에 C++ 주해서는 C++17 표준에 관련된 변화들을 반영할 것이다. 인덱스에서 C++17 항목을 보면 C++17 표준이 언급되어 있는 곳으로 가실 수 있다.
집합체를 (예, structs) 초기화하기 위해 익숙한 활괄호 표기법을 사용할 수 있다. C++17은 초기화 방법을 확장해서 상속을 사용하는 구조체도 활괄호 표기법으로 초기화할 수 있다. 예를 들어:
struct Base
{
int value;
};
struct Derived: public Base
{
string text;
void member();
};
// Derived 객체를 초기화:
Derived der{{value}, "hello world"};
// -------
// (첫 번째) 바탕 클래스 초기화.
C++17에 이르기까지 논리 연산자 and와 or는 제외하고 이항 연산자의 피연산자를 평가하는 순서는 정의되어 있지 않다. C++17에서 후위 표현식과 할당 표현식 (복합 서술문 포함) 그리고 shift 연산자에 대하여 이를 바꾸었다.
first는 second보다 먼저 평가된다. 그 다음에 third, 그 다음 fourth가 평가된다. 단순 변수나 괄호 표현식 또는 함수 호출이든 상관이 없다.
first.second
fourth += third = second += first
first << second << third << fourth
first >> second >> third >> fourth
그리고 연산자를 중복정의할 때, 그것을 구현한 함수는 일반적으로 평가되는 순서가 아니라 내장 연산자처럼 평가된다.
switch 서술문의 case 엔트리에 내포된 서술문들이 계속해서 그 아래의 case 엔트리나 default 엔트리로 이어지면 컴파일러는 `누출(falling through)' 경고를 보여준다. 의도적인 것이라면 [[fallthrough]] 속성을 사용해야 한다. 다음은 주석을 붙인 예제이다.
void function(int selector)
{
switch (selector)
{
case 1:
case 2: // 누출은 아니지만, 진입점들이 병합되었다.
cout << "cases 1 and 2\n";
[[fallthrough]];
case 3:
cout << "case 3\n";
case 4: // 경고
cout << "case 4\n";
[[fallthrough]]; // 에러: 이 다음에 아무것도 없다.
}
}
이 속성은 클래스, typedef-이름, 변수, 비-정적 데이터 멤버, 함수, 열거체에 적용할 수 있다. 적용하면 그 개체가 사용되든 안 되든 경고하지 않는다.
void fun([[maybe_unused]] size_t argument)
{
// 인자가 사용되지 않더라도
// 경고하지 않는다.
}
함수나 클래스 또는 열거체를 선언할 때 [[nodiscard]] 속성을 지정할 수 있다. 함수가 [[nodiscard]]로 선언되거나 또는 함수가 이전에 [[nodiscard]]으로 선언된 개체를 돌려준다면 그런 함수의 반환 값은 무시할 수 없다. 단, 명시적으로 void로 형변환한 경우는 제외한다. 반환 값이 사용되지 않으면 경고가 제출된다. 예를 들어:
int [[nodiscard]] importantInt();
struct [[nodiscard]] ImportantStruct { ... };
ImportantStruct factory();
int main()
{
importantInt(); // 경고
factory(); // 경고
}
템플릿 정의에서 if constexpr 서술문 다음의 표현식 값에 따라 함수 정의의 일부를 실체화할 수 있다. 21.16절에 더 자세하게 설명한다.
인라인 함수 말고도 인라인 변수를 여러 번역 단위에 정의할 수 있다 (동일하게 초기화할 수 있다). 예를 들어 헤더 파일에 다음과 같이 담을 수 있다.
inline int value = 15; OK
class Demo
{
// static int s_value = 15; ERROR
static int constexpr s_value = 15; OK
static int s_inline; NEW, 아래 참고
};
inline int Demo::s_inline = 20; OK
export 키워드와 register 키워드는 더 이상 사용되지 않는다. 그러나 여전히 식별자로 미래의 사용을 위해 예약되어 있다. 다음과 같이 정의하면
register int index;
컴파일 에러를 일으킨다. register 키워드도 더 이상 저장소 분류 지정자로 간주되지 않는다 (저장소 분류 지정자는 extern, thread_local, mutable 그리고 static이다).
람다 표현식이 확장되었다. 18.7절에서 C++17 표식이 붙은 항목들을 찾아 보라.
내포된 이름공간은 영역 지정 연산자를 사용하면 직접적으로 참조할 수 있다. 예를 들어,
namespace Outer::Middle::Inner
{
// 여기에 있는 개체는 Inner 이름공간에 선언된다/정의된다.
// Inner 이름공간은 Middle 이름공간에 정의된다.
// Middle 이름공간은 Outer 이름공간에 정의된다.
}
클래스 템플릿을 위한 템플릿 인자는 컴파일러가 문맥에 따라 추론할 수 있다. 자세한 것은 22.0.1항을 참고하라.