struct) 안에 선언할 수 있음을 다양한 예제로 보여준다. 클래스(class)의 개념을 소개한다. 유형변환을 더 자세하게 다룬다. 새로 많은 유형을 소개하고 C에 비해 크게 발전한 것들을 연구한다.
const 키워드는 C 문법에 포함되지만 사용법은 C보다 C++에서 더 중요하며 더 널리 더 엄격하게 사용된다.
const 키워드는 인자나 변수의 값이 불변임을 알리는 수식어이다. 다음 예제에서 ival 변수의 값을 바꾸려고 하지만 실패한다.
int main()
{
int const ival = 3; // 상수 int
// 3으로 초기화
ival = 4; // 할당하면
// 에러 메시지 출력
}
이 예제를 보면 ival은 정의할 때 주어진 값으로 초기화된다. 나중에 값을 바꾸려는 시도는 (즉, 할당 시도는) 허용되지 않는다.
const로 선언된 변수는 C와 대조적으로 다음 예제와 같이 배열의 크기를 지정할 수 있다.
int const size = 20;
char buf[size]; // 20 개의 문자 크기
const 키워드의 또다른 사용법은 포인터 선언, 예를 들어 포인터-인자에 있다. 다음 선언을 보면
char const *buf;
buf는 한 무더기 char를 가리키는 포인터 변수이다. buf가 가리키는 것은 무엇이든 buf를 통하여 변경할 수 없다. char가 const로 선언되어 있기 때문이다. 그렇지만 포인터 buf 자체는 바꿀 수 있다. 그러므로 다음과 같은 *buf = 'a'; 서술문은 허용되지 않지만 ++buf는 허용된다.
다음 선언에서는
char *const buf;
buf 자체가 바꿀 수 없는 const 포인터이다. buf가 가리키는 char는 얼마든지 마음대로 바꿀 수 있다.
마지막으로 다음 선언도 역시 가능하다.
char const *const buf;
포인터도 그 대상도 변경되지 않는다.
const 키워드의 위치에 대하여 제일 원칙은 다음과 같다. 키워드 왼쪽에 나타나는 것은 무엇이든 바꿀 수 없다.
단순하지만 이 제일 규칙을 사용한다. 예를 들어, 비야네 스트롭스트룹(Bjarne Stroustrup)의 언급에 의하면 (참조 http://www.stroustrup.com/bs_faq2.html#constplacement):
"const"를 유형 앞에 두어야 할까 아니면 뒤에 두어야 할까?그러나 예제에서 이미 보았듯이본인은 앞에 놓지만 그것은 개인의 취향 문제이다. "const T"와 "T const"는 언제나 (둘 다) 허용되며 동등하다. 예를 들어:
const int a = 1; // 좋다. int const b = 2; // 역시 좋다.생각건대 첫 번째 버전이 좀 더 프로그래머에게 명료할 것이다 (``더 관용구적이다'').
const 키워드를 이렇게 그냥 `앞쪽'에 배치한다는 규칙은 생각ㅎ지 못한 (즉, 바람직하지 않은) 결과를 초래한다. 잠시 후 (아래에서) 살펴 보겠다. 게다가 `관용구적인' 앞쪽-배치 전략도 const 함수의 표기법과 충돌한다. 이에 관해서는 7.7절에 언급한다. const 함수 표기법 때문에 const 키워드는 함수 이름 앞이 아니라 뒤에 배치되기도 한다.
선언이나 정의는 (const가 있든 없든) 언제나 변수나 함수 식별자로부터 유형 식별자 쪽으로 거슬러 읽어야 한다.
``Buf는 상수 문자를 가리키는 상수 포인터이다''이런 제일 규칙은 특히 혼란이 일어날 경우에 유용하다. 다른 곳에서 C++ 코드의 예를 보면 종종 그 반대의 경우를 만나기도 한다.
const 앞에 변경되면 안될 것이 오기도 한다. 이 때문에 허술한 코드가 되어 버리는 것을 위의 두 번째 예제가 보여준다.
char const *buf;
여기에서 무엇이 상수로 남을까? 우리의 헐렁한 해석 방법에 따르면 포인터는 변경할 수 없다 (const가 포인터 앞에 있기 때문이다). 실제로 여기에서 char 값들은 상수 개체이다. 다음 프로그램을 컴파일해 보면 확실히 알 수 있다.
int main()
{
char const *buf = "hello";
++buf; // 컴파일러가 수락
*buf = 'u'; // 컴파일러가 거부
}
컴파일은 *buf = 'u'; 서술문에서 실패한다. ++buf 서술문에서는 실패하지 않는다.
마샬 클라인(Marshall Cline)의 C++ FAQ를 보면 비슷한 문맥에 같은 규칙을 적용하는 것을 볼 수 있다 (문단 18.5):
[18.5] "const Fred* p", "Fred* const p" 그리고 "const Fred* const p" 사이의 차이점은 무엇인가?그렇지만 마샬 클라인의 조언은 개선할 수 있다. 다음은 아무리 복잡한 선언이라도 별 수고 없이 분석해 줄 요리법이다.포인터 선언을 오른쪽에서 왼쪽으로 읽을 필요가 있다.
char const *(* const (*(*ip)())[])[]
ip 변수의 이름부터 시작한다.
'ip'는
ip) 닫는 괄호를 만난다. 거꾸로 간다.
-->
(*ip) 짝이 되는 여는 괄호를 발견한다.
<- '~를 가리키는 포인터이다'
(*ip)()) 다음으로 짝 없는 닫는 괄호를 만난다.
--> '함수를 (인자를
기대하지 않음)'
(*(*ip)()) 짝이 되는 열린 괄호를 찾는다.
<- '~를 포인터로 돌려준다'
(*(*ip)())[]) 다음의 닫는 괄호를 만난다.
--> '배열의'
(* const (*(*ip)())[]) 짝이 되는 열린 괄호를 찾는다.
<-------- '~를 가리키는 상수 포인터이다'
(* const (*(*ip)())[])[] 끝까지 읽는다.
-> '배열의'
char const *(* const (*(*ip)())[])[] 나머지를 거꾸로 읽는다.
<----------- '상수 문자를 가리키는 포인터이다'
char const *(* const (*(*ip)())[])[]에 대하여 모든 부분을 모아 보면 ip는 (인자를 기대하지 않는) 함수를 가리키는 포인터이고 상수 포인터 배열을 포인터로 돌려주며 배열의 포인터들은 상수 문자를 가리킨다. 이것이 바로 ip가 나타내는 것이다. 이 요리법이면 어떤 선언이라도 해석할 수 있다.
sin 함수를 정의하고 싶어하지만 호도(radians)를 다루는 표준 sin 함수의 능력을 잃고 싶지 않다면 이름 충돌이 일어날 수 있다.
이름공간은 제 4 장에 더 자세하게 다룬다. 지금은 대부분의 컴파일러가 명시적으로 std라는 표준 이름공간의 선언을 요구한다는 사실을 지적하는 것으로 만족하겠다. 그래서 따로 표시하지 않는 한, 모든 예제는 이제 묵시적으로 다음 선언을 사용한다.
using namespace std;
그래서 실제로 제공되는 예제를 컴파일하고 싶다면 소스 위쪽이 using 선언으로 시작하는지 확인하라.
::)가 있다. 이 연산자는 지역변수가 이미 있는데 같은 이름으로 전역 변수가 존재하는 상황에 사용할 수 있다.
#include <stdio.h>
double counter = 50; // 전역 변수
int main()
{
for (int counter = 1; // 이 변수는
counter != 10; // 지역 변수를 가리킨다.
++counter)
{
printf("%d\n",
::counter // 전역 변수
/ // 나누기
counter); // 지역 변수
}
}
위의 예제에는 지역 변수 대신에 이름이 같은 전역 변수에 접근하는데 영역 연산자를 사용한다. C++에서 영역 지정 연산자는 곳곳에 사용된다. 그러나 이름이 같은 지역 변수로 가려지는 전역 변수에 접근하기 위해 사용되는 경우는 거의 없다. 그의 주 목적은 제 7장에서 만나 본다.
#include <iostream>
using namespace std;
int main()
{
int ival;
char sval[30];
cout << "숫자를 입력하시오:\n";
cin >> ival;
cout << "문자열을 입력하시오:\n";
cin >> sval;
cout << "숫자: " << ival << "\n"
"문자열: " << sval << '\n';
}
이 프로그램은 숫자와 문자열을 cin 스트림으로부터 (보통은 키보드로부터) 읽고 그리고 이 데이터들을 cout에 인쇄한다. 스트림에 관하여 다음을 눈여겨보기를 바란다.
iostream 헤더 파일에 선언되어 있다. 이 책의 예제에서 이 헤더 파일은 명시적으로 언급하지 않는다. 그렇지만 (직접적이든 간접적이든) 반드시 포함해야 이 스트림을 사용할 수 있다. using namespace std; 구문을 사용하듯이 표준 스트림이 사용되는 예제라면 반드시 #include <iostream>이 있을 것이라고 예상해야 한다.
cout과 cin 그리고 cerr는 이른바 클래스 유형의 변수이다. 이런 변수들을 객체라고 부른다. C++에서 널리 사용되는 클래스는 제 7장에 더 자세하게 논의한다.
cin 스트림은 데이터를 스트림으로부터 추출하여 변수에 그 정보를 복사한다 (위의 예제에서는 ival에 복사함). 추출 연산자를 사용한다 (> 문자 두 개 즉, >>). 여기에서 보여주는 것처럼 C++에서 어떻게 연산자들이 이미 정의된 방식과 다르게 행위할 수 있는지 나중에 설명하겠다. 함수 중복정의는 이미 언급했다. C++의 연산자 역시 여러 정의가 있는데, 이를 연산자 중복정의라고 부른다.
cin과 cout 그리고 cerr를 조작하는 연산자들은 다른 유형의 변수도 조작할 수 있다 (즉, >> 그리고 <<). 위의 예제에서 cout << ival는 결과적으로 정수 값을 인쇄한다. 반면에 cout << "Enter a number"는 문자열을 인쇄한다. 그러므로 연산자의 행위는 공급된 변수의 유형에 따라 달라진다.
"\n"이나 '\n'을 삽입하면 끝난다. 그러나 endl 심볼을 삽입하면 줄을 끝낸 후에 스트림의 내부 버퍼를 비운다. 그래서 좀 더 효율적인 코드를 위해 endl은 피하고 '\n'을 선호하기도 한다.
cin과 cout 그리고 cerr는 C++의 정규 문법이 아니다. 이 스트림들은 iostream 헤더 파일에 정의되어 있다. 이것을 printf와 같은 함수에 비교한다면 C 문법은 아니지만 처음부터 그런 함수들을 중요하다고 여기고 실행 시간 라이브러리에 수집한 것과 비슷하다.
새-스타일의 스트림을 멀리하고 프로그램은 여전히 printf와 scanf 같은 구형-스타일의 함수를 사용할 수도 있다. 두 가지 스타일을 혼용해 사용할 수도 있다. 그러나 스트림은 여러 장점이 명백하다. 많은 C++ 프로그램은 완벽하게 구형 스타일의 C 함수들을 대신하여 사용한다. 스트림을 사용하여 얻는 장점은 다음과 같다.
printf와 scanf에 사용되는 형식 문자열은 인자에 엉터리 형식 지정자를 정의할 수도 있다. 그럼에도 컴파일러가 경고조차 할 수 없는 경우가 있다. 대조적으로 cin과 cout 그리고 cerr에서는 컴파일러가 인자를 점검해 준다. 결과적으로 int 인자를 형식 문자열에 맞게 문자열 인자가 나타나야 할 곳에 배치해서 에러를 일으키는 일은 불가능하다. 스트림은 형식화 문자열이 필요하지 않다.
printf 함수와 scanf 함수는 (형식화 문자열을 사용하는 다른 함수들도 마찬가지로) 사실 알고보면 실행 시간에 통역이 되는 미니-언어를 구현한 것이다. 대조적으로 C++ 컴파일러는 인자가 스트림으로 주어지면 입력을 수행할지 출력을 수행할지 정확하게 알고 있다. 여기에 미니 언어 같은 것은 전혀 없다.
printf 함수에 사용된 미니 언어는 확장이 불가능하다.
iostream 라이브러리는 cin과 cout 그리고 cerr 말고도 수 많은 기능을 제공한다. 제 6장 iostreams에서 더 자세하게 다룬다. printf와 그 친구들을 C++ 프로그램에 여전히 사용할 수는 있지만 스트림이 사실상 printf같은 구형-스타일의 C I/O 함수들을 대신한다. 여전히 printf와 그 관련 기능들을 사용할 필요가 있다고 생각한다면 다시 한 번 생각하라. 그러면 스트림 객체의 가능성을 완전히 이해할 기회를 놓치게 될 것이다.
아래의 조각 코드를 보면 구조체에 사람의 이름과 주소를 담을 데이터 필드가 있다. print 함수가 구조체 정의에 포함되어 있다.
struct Person
{
char name[80];
char address[80];
void print();
};
print 멤버 함수를 정의할 때 구조체의 이름(Person)과 영역 지정 연산자(::)가 사용된다.
void Person::print()
{
cout << "Name: " << name << "\n"
"Address: " << address << '\n';
}
Person::print 멤버 함수의 구현은 구조체의 유형 이름을 사용하지 않고서 어떻게 구조체의 필드에 접근할 수 있는지 보여준다. 여기에서 Person::print는 name 변수를 인쇄한다. Person::print는 자체가 Person 구조체에 포함되어 있기 때문에 name 변수는 암묵적으로 같은 유형을 참조한다.
다음과 같이 struct Person을 사용할 수 있다.
Person person;
strcpy(person.name, "Karel");
strcpy(person.address, "Marskramerstraat 33");
person.print();
멤버 함수의 장점은 호출된 함수가 자동으로 자신을 요청한 구조체의 데이터 필드에 접근한다는 것이다. person.print() 서술문에서 person 객체는 `실체(substrate)'이다. print에서 사용된 name 변수와 address 변수는 person 실체에 저장된 데이터를 참조한다.
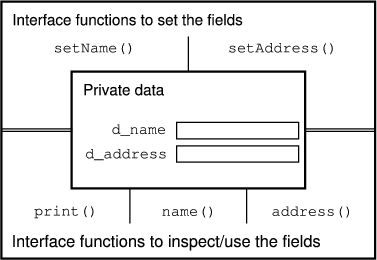
C++는 데이터 은닉과 관련하여 private(비밀)과 protected(보호) 그리고 public(공개) 세 개의 키워드가 있다. 이런 키워드를 구조체의 정의에 사용할 수 있다. public 키워드는 다음에 오는 구조체의 모든 필드에 모든 코드가 접근할 수 있도록 허용한다. private 키워드는 구조체 자체에서만 잇따르는 필드에 접근할 수 있도록 허용한다. protected 키워드는 제 13장에 다룬다. 지금의 연구 주제에서 약간 벗어나기 때문이다.
따로 명시적으로 언급하지 않는 한, 구조체에서 모든 필드는 공개이다. 이 지식을 활용하면 struct Person을 다음과 같이 확장할 수 있다.
struct Person
{
private:
char d_name[80];
char d_address[80];
public:
void setName(char const *n);
void setAddress(char const *a);
void print();
char const *name();
char const *address();
};
d_name 필드와 d_address 필드는 비밀 구역에 있으므로 구조체에 정의된 멤버 함수만 접근할 수 있다. 이 멤버 함수는 setName, setAddress 등등이다. 예를 들어 다음 코드를 연구해 보자:
Person fbb;
fbb.setName("Frank"); // 좋다. setName은 공개 함수이기 때문이다.
strcpy(fbb.d_name, "Knarf"); // 에러이다. x.d_name이 비밀이기 때문이다.
데이터 정합성은 다음과 같이 구현된다. Person 구조체의 실제 데이터는 정의 안에 언급된다. 데이터는 역시 정의의 일부이기도 한 특수한 함수를 사용하여 바깥 세계에서 접근한다. 이 멤버 함수들은 프로그램의 데이터 필드와 다른 부분 사이의 모든 통신을 제어한다. 그러므로 `인터페이스' 함수라고 부른다. 이렇게 구현된 데이터 은닉을 그림 2에 보여준다.
setName 멤버와 setAddress 멤버는 char const * 매개변수로 선언된다. 이것은 함수들이 인자로 공급된 문자열을 변경하지 않을 것이라는 사실을 알려준다. 비슷하게, name 멤버와 address 멤버는 char const *를 돌려준다. 컴파일러는 이런 멤버의 호출자가 그의 반환 값을 통하여 접근할 수 있는 정보를 변경하지 못하도록 방지한다.
struct Person의 멤버 함수의 두 가지 예를 아래에 보여준다.
void Person::setName(char const *n)
{
strncpy(d_name, n, 79);
d_name[79] = 0;
}
char const *Person::name()
{
return d_name;
}
데이터 은닉의 개념과 멤버 함수의 힘 덕분에 멤버 함수는 특별한 과업을 수행할 수 있다. 예를 들어 데이터의 유효성을 점검할 수 있다. 위의 예제에서 setName 멤버 함수는 자신의 인자로부터 name 데이터 멤버에 79 개의 문자만 복사한다. 그리하여 버퍼 범람을 피한다.
데이터 은닉의 개념을 보여주는 또다른 예는 다음과 같다. 데이터를 메모리에 보관하는 멤버 함수의 대안으로서 데이터를 파일에 저장하는 멤버 함수를 특징으로 하는 라이브러리를 개발할 수 있다. Person 구조체를 메모리에 저장하는 프로그램을 디스크에 저장하는 프로그램으로 변환하려면 특별한 변경이 필요하지 않다. 프로그램을 다시 컴파일해 새 라이브러리에 링크하고 나면 메모리 저장에서 디스크 저장으로 변환된다. 이 예제는 데이터 은닉보다 더 넓은 개념을 보여준다. 캡슐화(encapsulation)를 보여준다. 데이터 은닉은 일종의 캡슐화이다. 일반적으로 캡슐화는 프로그램에서 서로 다른 부분들 사이의 겹합도를 줄여준다. 이 덕분에 결과로 나온 소프트웨어의 재사용성과 유지관리성이 크게 개선된다. 구조체에 실제 저장 매체를 캡슐화해 넣으면 그 구조를 사용하는 프로그램은 실제 저장 매체에 얽매이지 않게 된다.
데이터 은닉은 구조체를 사용하여 구현할 수 있지만 대신에 (거의 언제나) 클래스가 훨씬 더 자주 사용된다. 클래스는 일종의 구조체이다. 단, 클래스는 비공개 접근이 기본이고 구조체는 공개 접근이 기본이다. 그러므로 class Person의 정의는 위에 보여준 정의와 동일하다. 단, class 키워드가 struct 키워드를 대신했고 처음의 private: 절을 생략할 수 있다. 클래스 이름의 철자 규칙은 (Person처럼) 대문자로 시작하고 나머지는 소문자를 사용하라고 제안한다 (그리고 프로그래머가 정의하는 다른 유형의 이름들도 마찬가지로 이 철자 규칙을 따르기를 제안한다).
/* 구조체 PERSON의 정의 C로 구현됨 */
typedef struct
{
char name[80];
char address[80];
} PERSON;
/* PERSON 구조체를 조작하기 위한 함수들 */
/* 이름과 주소로 필드를 초기화한다 */
void initialize(PERSON *p, char const *nm,
char const *adr);
/* 정보를 인쇄한다 */
void print(PERSON const *p);
/* etc.. */
C++는 관련 함수의 선언을 구조체나 클래스의 정의 안에 배치한다. 어느 구조체가 관련되어 있는지 알려주는 인자는 더 이상 사용하지 않는다.
class Person
{
char d_name[80];
char d_address[80];
public:
void initialize(char const *nm, char const *adr);
void print();
// etc..
};
C++는 구조체에 매개변수를 사용하지 않는다. 다음과 같이 호출하는 C 함수는:
PERSON x;
initialize(&x, "some name", "some address");
C++로 다음과 같이 된다.
Person x;
x.initialize("some name", "some address");
int int_value;
int &ref = int_value;
위의 예제에서 int_value 변수가 정의된다. 이어서 참조 ref가 정의되는데 (그의 초기화 때문에) int_value와 같은 메모리 위치를 참조한다. ref를 정의하면서 참조 연산자 &는 ref가 그 자체로 int가 아니라 int인 것을 참조한다고 알려준다. 다음 두 서술문은 효과가 같다.
++int_value;
++ref;
둘 다 int_value의 값을 증가시킨다. 그 위치를 int_value라고 부르든 ref라고 부르든 문제가 되지 않는다.
참조는 C++에서 중요한 기능이다. 변경 가능한 인자를 함수에 건네는 도구로 사용된다. 예를 들어 표준 C에서는 함수가 그의 인자의 값을 5만큼 늘리고 아무것도 돌려주지 않는다면 포인터 매개변수가 필요하다.
void increase(int *valp) // int를 가리키는
{ // 포인터를 기대함
*valp += 5;
}
int main()
{
int x;
increase(&x); // x의 주소를 건넴
}
이 구조를 C++에서도 사용할 수 있지만 참조를 사용하면 같은 효과를 얻을 수 있다.
void increase(int &valr) // int를 참조함
{
valr += 5;
}
int main()
{
int x;
increase(x); // 참조를 건넴
}
그렇지만 C의 방법에 비해 위의 코드가 더 좋다고 주장하기에는 논란의 여지가 있다. increase (x) 서술문은 x 자체가 아니라 사본이 건네진다는 것을 암시한다. 그럼에도 x의 값이 바뀌는데 increase()가 정의된 방식 때문이다. 그렇지만 참조를 사용하면 (복사나 const *가 필요 없이) 그냥 조사만 받을 객체를 건넬 수 있다. 아니면 변경해도 그 변경으로 인한 부작용을 받아들일 만 한 객체를 건네는 데에도 사용할 수 있다. 그 경우 참조를 사용하는 것이 값 복사나 포인터 전달 같은 기존의 대안보다 훨씬 더 좋다.
배경 뒤에서 참조는 포인터를 사용하여 구현되어 있다. 그래서 컴파일러의 눈에는 C++의 참조는 그저 상수 포인터일 뿐이다. 그렇지만 참조가 있으면 프로그래머는 간접 참조의 깊이에 관하여 알 필요도 없고 신경쓸 필요도 없다. 평범한 포인터와 참조 사이의 중대한 차이는 물론 참조로는 절대로 간접 참조가 일어나지 않는다는 것이다. 예를 들어:
extern int *ip;
extern int &ir;
ip = 0; // ip를 재할당, 이제 0-포인터
ir = 0; // ir은 변경 안됨, 이를 참조하는 int 변수는
// 이제 0임.
혼동을 피하려면 다음 사실에 중심을 두기를 바란다.
void some_func(int val)
{
cout << val << '\n';
}
int main()
{
int x;
some_func(x); // 사본이 건네진다.
}
void by_pointer(int *valp)
{
*valp += 5;
}
void by_reference(string const &str)
{
cout << str; // str 변경 없음
}
int main ()
{
int x = 7;
by_pointer(&x); // 포인터가 건네짐
// x는 변경 가능
string str("hello");
by_reference(str); // str 변경 불가
}
참조는 인자가 함수에 의해서 변경되지 않지만 매개변수를 초기화하기 위해 인자를 복사하는 것이 바람직하지 않을 경우에 중요한 역할을 한다. 거대한 객체를 함수에 인자로 건네거나 함수가 돌려줄 경우에 복사 연산이 중대한 요소가 되는 경향이 있다. 왜냐하면 전체 객체를 복사해야 하기 때문이다. 당연히 참조가 바람직하다.
인자를 함수가 변경하지 않는다면 또는 호출자가 반환된 정보를 변경하지 말아야 한다면 const 키워드를 사용해야 한다. 다음 예제를 연구해 보자:
struct Person // 좀 큰 구조체
{
char name[80];
char address[90];
double salary;
};
Person person[50]; // 개인 데이터베이스
// printperson 함수는 구조체에 대한
// 참조를 기대하지만
// 변경하지는 않을 것이다.
void printperson (Person const &p)
{
cout << "Name: " << p.name << '\n' <<
"Address: " << p.address << '\n';
}
// indexvalue로 개인 기록 검색
Person const &person(int index)
{
return person[index]; // 참조가 반환됨,
} // person[index]의 사본이 아님
int main()
{
Person boss;
printperson (boss); // 포인터가 건네지지 않음,
// 그래서 변수는 함수가
// 변경하지 않을 것이다.
printperson(person(5));
// 사본이 아니라
// 여기에서는 참조가 건네짐
}
결과적으로 참조는 정말 '보기 흉한' 코드가 될 가능성이 있다. 함수는 변수를 참조로 건넬 수 있는데, 다음 예제를 보면:
int &func()
{
static int value;
return value;
}
이렇게 하면 다음과 같은 구조를 사용할 수 있다.
func() = 20;
func() += func();
아마도 이런 식의 생성은 사용하면 안된다는 것을 구지 지적할 필요도 없을 것 같다. 그럼에도 참조를 돌려주는게 유용한 상황이 있다. 실제로 앞에서 스트림을 언급할 때 이런 현상의 한 예를 이미 보았다. cout << "Hello" << '\n';과 같은 서술문에서 삽입 연산자는 cout를 참조로 돌려준다. 그래서 이 서술문에서 첫 "Hello"는 cout에 삽입되고 cout를 참조로 생산한다. 이어서 이 참조를 통하여 '\n'이 cout 객체에 삽입된다. 다시 cout를 참조로 생산하지만 이제는 무시된다.
포인터와 참조 사이의 여러 차이점들을 아래 리스트에 요약한다.
int &ref;ref가 과연 무엇을 참조할 것인가?
external로 선언할 수 있다. 이런 참조는 어디에선가 초기화되어 있어야 한다.
&를 참조에 사용하면 그 표현식은 참조가 적용된 변수의 주소를 산출한다. 대조적으로 보통의 포인터는 그 자체로 변수이다. 그래서 포인터 변수의 주소는 그 포인터가 가리키는 주소와 아무 상관이 없다.
const & 유형과 구별할 수 없다. C++는 새로운 참조 유형을 도입한다. rvalue 참조라고 부르는데 typename &&으로 정의되어 있다.
rvalue 참조라는 이름은 할당 서술문으로부터 파생되었다. 할당할 때 할당 연산자의 왼쪽에 있는 변수를 lvalue라고 부르고 오른쪽에 있는 표현식은 rvalue라고 부른다. 종종 rvalue는 임시의 익명 값으로서 함수가 돌려주는 값과 같다.
이런 비유로 C++ 참조는 lvalue 참조라고 간주해야 한다 (typename & 표기법 사용). rvalue 참조와 대조적이다 (typename && 표기법 사용).
rvalue 참조를 이해하는 열쇠는 익명 변수라는 개념이다. 익명 변수는 이름이 없다. 눈에 띄는 특징이 있다. 컴파일러는 선택해야 할 때 자동으로 그 익명변수를 rvalue 참조에 연관짓는다. 흥미로운 구조를 소개하기 전에 먼저 lvalue 참조가 사용되는 대표적인 상황을 살펴 보자. 다음 함수는 임시의 이름없는 값을 돌려준다.
int intVal()
{
return 5;
}
intVal의 반환 값은 int 변수에 할당할 수 있지만 그러려면 복사가 필요하다. 그런데 함수가 int를 돌려주지 않고 큰 객체를 돌려주는 경우라면 복사가 금지된다. 참조 또는 포인터는 익명의 반환 값을 수집하는 데에도 사용할 수 없다. 반환 값이 그 이후로 생존하지 못하기 때문이다. 그래서 다음은 적법하지 않다 (컴파일러가 알려준다):
int &ir = intVal(); // 실패: 임시값을 참조함
int const &ic = intVal(); // 허용: 변경불능 임시 값 참조
int *ip = &intVal(); // 실패: lvalue 값이 없음
intVal이 돌려주는 임시 값을 변경하는 것은 확실하게 불가능하다. 그러나 이제 다음 함수들을 연구해 보자:
void receive(int &value) // 주의: lvalue 참조
{
cout << "int value parameter\n";
}
void receive(int &&value) // 주의: rvalue 참조
{
cout << "int R-value parameter\n";
}
이제 이 함수를 main에서 호출해 보자:
int main()
{
receive(18);
int value = 5;
receive(value);
receive(intVal());
}
이 프로그램은 다음과 같이 출력한다.
int R-value parameter
int value parameter
int R-value parameter
익명 int를 인자로 받으면 컴파일러는 receive(int &&value)를 선택한다. 여기에 receive(18)이 해당되는 것을 눈여겨보라. 값 18은 이름이 없고 그리하여 receive(int &&value)가 호출된다. 내부적으로 실제로는 임시 값을 사용하여 18을 저장한다. 다음 예제에 보여 주듯이 receive를 변경한다.
void receive(int &&value)
{
++value;
cout << "int R-value parameter, now: " << value << '\n';
// 각각, 19와 6을 화면에 보여준다.
}
receive(int &value)를 receive(int &&value)에 대조하는 것은 int &value가 상수 참조가 아니라는 사실과는 전혀 관계가 없다. receive(int const &value)가 사용되면 같은 결과를 얻는다. 요컨대 함수를 익명 값으로 건네면 컴파일러는 rvalue 참조를 사용하여 중복정의 함수를 선택한다.
그렇지만 void receive(int &value)가 void receive(int value)로 교체되면 컴파일러는 문제에 봉착한다. 값 매개변수인지 참조 매개변수인지 (lvalue인가 rvalue인가) 컴파일러는 결정을 내리지 못하고 모호하다고 보고한다. 실제 상황에 이것이 문제는 아니다. rvalue 참조가 추가된 것은 두 가지 형태의 참조를 구별하기 위해서였다. 이름붙은 (lvalue 참조) 값과 이름없는 (rvalue 참조) 값을 구분하기 위해서였다.
이동 의미구조와 완벽한 전달의 구현은 이 구별 덕분이다. 이 시점에서는 이동 의미구조를 완전히 다룰 수는 없다 (깊은 연구는 9.7절 참고). 그러나 그 아래의 아이디어를 보여주는 것이 좋을 것 같다.
함수가 struct Data를 돌려주는데 그 안에 동적으로 할당된 문자들을 가리키는 포인터가 담겨 있는 상황을 연구해 보자. 게다가 구조체에는 copy(Data const &other) 멤버 함수가 정의되어 있어서 또다른 Data 객체를 받아 다른 객체의 데이터를 현재 객체 안에 복사한다. (부분적으로) struct Data를 정의하면 대략 다음과 같을 것이다 (눈이 날카로운 독자들에게 이 예제에서 Data::copy()를 사용한 결과로 인한 메모리 누수는 무시합시다):
struct Data
{
char *text;
size_t size;
void copy(Data const &other)
{
text = strdup(other.text);
size = strlen(text);
}
};
다음으로 dataFactory 함수와 main 함수는 다음과 같이 정의한다.
Data dataFactory(char const *txt)
{
Data ret = {strdup(txt), strlen(txt)};
return ret;
}
int main()
{
Data d1 = {strdup("hello"), strlen("hello")};
Data d2;
d2.copy(d1); // 1 (본문 참고)
Data d3;
d3.copy(dataFactory("hello")); // 2
}
(1)에서 d2는 적절하게 d1의 텍스트 사본을 받는다. 그러나 (2)에서 d3은 임시 메모리에 저장된 텍스트 사본을 받는데 dataFactory 함수가 반환한 것이다. 이 임시 변수는 copy()를 호출한 후에 소멸하기 때문에 두 가지 불쾌한 결과를 볼 수 있다.
d3에 건네는 것이다. 이제 d3은 분명히 좀 끈질기게 살아 남아 있는 그 임시 객체의 데이터를 복사한다.
copy()를 호출하고 나서 임시의 Data 객체는 사라진다. 불행하게도 동적으로 할당된 그의 데이터는 사라지고 그 때문에 메모리 누수가 일어난다.
copy 멤버를 copy(Data &&other) 멤버로 재정의함으로써 컴파일러는 상황 (1)과 (2)를 구별할 수 있다. 이제 (1) 상황에서는 앞의 copy() 멤버를 호출하고 (2)의 상황에서는 새로 중복정의 copy() 멤버를 호출한다.
struct Data
{
char *text;
size_t size;
void copy(Data const &other)
{
text = strdup(other.text);
}
void copy(Data &&other)
{
text = other.text;
other.text = 0;
}
};
중복정의 copy() 함수는 그저 other.text 포인터를 현재 객체의 text 포인터로 이동시키고 그 다음에 other.text에 0을 재할당할 뿐이다. Struct Data는 갑자기 이동을-인식하고서 이동 의미구조를 구현함으로써 앞에서 보여준 접근법의 단점을 제거한다.
other.text는 동적으로 할당된 메모리를 더 이상 가리키지 않으므로 메모리 누수를 방지한다.
*this에 대한 rvalue 참조와 그리고 rvalue로 클래스 객체를 초기화하는 것은 아직 g++ 컴파일러가 지원하지 않는다.
역사적으로 C 언어는 lvalue와 rvalue를 구분한다. 이 용어는 할당 표현식에 근거가 있는데, 할당 연산자의 왼쪽이 값을 받는 반면에 (예를 들어, 변수 처럼 값을 써 넣을 수 있는 메모리의 위치를 참조한다) 오른쪽은 값을 나타낼 뿐이기 때문이다 (임시 변수나 상수 값 또는 변수 안에 저장된 값이 될 수 있다):
lvalue = rvalue;
C++는 이 기본적인 구분 방식에다 값을 참조하는 여러가지 방식을 새로 추가했다.
lvalue: C++에서 lvalue는 C에서의 의미와 같다. 마치 변수나 변수에 대한 참조 또는 역참조 포인터처럼 값을 저장할 수 있는 위치를 참조한다.
xvalue: xvalue는 소멸 값을 표시한다. 소멸 값은 곧바로 사망할 객체를 참조한다 (제 7장). 그런 객체는 (동적으로 할당된 메모리와 같이) 자신이 소유한 자원도 역시 확실하게 소멸시켜야 한다. 그러나 그런 자원은 객체가 사망하기 전에 또다른 위치로 이동할 경우가 있어서 소멸을 방해할 가능성이 있다.
gvalue: gvalue는 일반화된 lvalue이다. 일반화된 lvalue는 값을 받는 것은 무엇이든 참조한다. lvalue이거나 아니면 xvalue이다.
prvalue: prvalue는 순수한 rvalue이다. (1.2e3과 같이) 문자 그대로의 값 또는 변경 불능 객체 (불변std::string함수로부터 반환된 값 (제 5장))
표현식의 값은 다음과 같은 경우 xvalue이다.
.* (멤버를 가리키는 포인터) 표현식이다 (제 16장).
이 표현식에서 왼쪽 피연산자는 xvalue이고 오른쪽 피연산자는 데이터 멤버를 가리키는 포인터이다. 다음은 작은 예제이다. 다음의 간단한 구조체를 연구해 보자:
struct Demo
{
int d_value;
};
여기에다 다음과 같이 함수가 선언되고 정의되어 있다.
Demo &&operator+(Demo const &lhs, Demo const &rhs);
Demo &&factory();
Demo demo;
Demo &&rref = static_cast<Demo &&>(demo);
다음과 같은 표현식은 xvalue이다.
factory();
factory().d_value;
static_cast<Demo &&>(demo);
demo + demo
그렇지만 다음 표현식은 lvalue이다.
rref;
많은 경우 실제로 어떤 종류의 gvalue 또는 rvalue가 사용되었는지 아는 것은 별로 중요하지 않다. C++ 주해서에서 lhs (left hand side)라는 용어는 이항 연산자의 왼쪽에 씌여지는 피연산자를 표시하기 위해 사용하고 rhs (right hand side)라는 용어는 오른쪽 피연산자를 표시하기 위해 사용한다. lhs 피연산자와 rhs 피연산자는 실제로는 (보통의 변수를 나타내는) gvalue일 수 있지만, (덧셈 연산자로 더해진 숫자 값과 같이) prvalue일 수도 있다. lhs와 rhs가 glvalue 인지의 여부는 언제든지 사용되는 문맥에 따라 결정할 수 있다.
int 값이다. 그러므로 유형의 안전성을 훼손할 수 있다. 예를 들어, 서로 유형이 다른 열거체의 값을 동등한지 (아닌지) 비교할 수 있다. 물론 (정적) 유형 변환을 통해서 말이다.
현재의 enum 유형에 관련한 또다른 문제는 값이 열거 유형의 이름 자체에 제한되는 것이 아니라 열거체가 정의된 영역에 제한된다는 것이다. 결과적으로 두 개의 열거체가 영역이 같으면 동일한 이름을 가질 수 없다.
그런 문제는 열거형 클래스를 정의하면 해결된다. enum class는 다음 예제와 같이 정의할 수 있다.
enum class SafeEnum
{
NOT_OK, // 0, 묵시적
OK = 10,
MAYBE_OK // 11, 묵시적
};
Enum 클래스는 기본값으로 int 값을 사용하지만 사용된 값의 유형은 쉽게 바꿀 수 있다. 다음과 같이 : type 표기법을 사용하면 된다.
enum class CharEnum: unsigned char
{
NOT_OK,
OK
};
enum 클래스에 정의된 값을 사용하려면 그의 열거 이름도 제공해야 한다. 예를 들어, OK는 정의되어 있지 않다. CharEnum::OK는 정의되어 있다.
직접 데이터 유형을 지정하면 (기본값이 int임에 주목) 열거형 클래스를 전방 선언에 사용할 수 있다.
예를 들어,
enum Enum1; // 불법: 크기가 지정이 안됨
enum Enum2: unsigned int; // 적법: 명시적으로 선언된 유형
enum class Enum3; // 적법: 기본 int 유형이 사용됨
enum class Enum4: char; // 적법: 명시적으로 선언된 유형
강력하게 유형이 정의되는 열거형의 심볼 연속을 생략 구문을 사용하여 switch 문에 나타낼 수도 있다. 이것을 다음 예제에 보여준다.
SafeEnum enumValue();
switch (enumValue())
{
case SafeEnum::NOT_OK ... SafeEnum::OK:
cout << "Status is known\n";
break;
default:
cout << "Status unknown\n";
break;
}
C++는 이 개념을 확장한다. initializer_list<Type> 유형을 도입했다. 여기에서 Type은 초기화 리스트에 사용된 값들의 유형 이름으로 교체된다. C++에서 초기화 리스트는 C의 초기화 리스트를 닮았다. 그래서 다-차원 배열과 구조체 그리고 클래스와 함께 사용할 수 있다.
initializer_list를 사용하려면 먼저 <initializer_list> 헤더를 포함시켜야 한다.
C에서처럼 초기화 리스트는 활괄호로 둘러싼 값 리스트로 구성된다. 그러나 C와는 다르게 함수에 초기화 리스트 매개변수를 정의할 수 있다. 예를 들어,
void values(std::initializer_list<int> iniValues)
{
}
values 함수는 다음과 같이 호출할 수 있다.
values({2, 3, 5, 7, 11, 13});
초기화 리스트는 마치 값 리스트 인자를 활괄호로 둘러싼 것처럼 보인다. 초기화 리스트의 재귀적 성격 때문에 이-차원 배열의 값도 건넬 수 있다. 다음 예제에 보여주는 바와 같이 말이다.
void values2(std::initializer_list<std::initializer_list<int>> iniValues)
{}
values2({{1, 2}, {2, 3}, {3, 5}, {4, 7}, {5, 11}, {6, 13}});
초기화 리스트는 상수 표현식이며 변경할 수 없다. 그렇지만 begin 멤버와 end 멤버 그리고 size를 사용하여 크기와 값을 열람할 수 있다. 예를 들어:
void values(initializer_list<int> iniValues)
{
cout << "Initializer list having " << iniValues.size() << "values\n";
for
(
initializer_list<int>::const_iterator begin = iniValues.begin();
begin != iniValues.end();
++begin
)
cout << "Value: " << *begin << '\n';
}
초기화 리스트는 클래스 객체를 초기화하는 데에도 사용된다 (7.5절).
auto 키워드는 변수의 유형 정의를 간단하게 하고 컴파일러가 함수나 변수의 적절한 유형을 분별할 수 있을 경우에 함수의 유형을 돌려준다.
그리고 auto를 저장 클래스 지정자로 사용하는 것은 이제 더 이상 C++에서 지원하지 않는다. auto int var와 같이 변수를 정의하면 컴파일 에러이다.
이것은 변수의 유형을 미리 결정하기가 매우 어려운 상황에 아주 유용할 수 있다. 이런 상황이 템플릿의 문맥에서 가끔 일어난다. 이 주제는 제 18장부터 제 23장에 걸쳐 다룬다. 또 알고는 있지만 이름이 몹시 길고 컴파일러에게 자동으로 알려지는 경우라면 auto를 사용해 기다란 유형 정의를 피할 수도 있다.
이 시점에서는 간단한 예제만 제공할 수 있다. 또 auto 키워드의 일반적인 사용법에 관하여 약간의 힌트만 제공한다. auto 키워드와 더불어 (decltype 함수와 관련된) 더 자세한 정보는 21.1.2 목을 참고하라.
int variable = 5로 변수를 정의하고 초기화하면 초기화 표현식의 유형이 잘 드러난다. 그 유형은 int이고 프로그래머의 의도에 어긋나지 않는 한, 이 유형을 사용하여 variable의 유형을 정의할 수 있다 (물론 정상적인 상황에서는 코드의 명료성을 개선하기보다 가리기 때문에 사용하면 좋지 않다):
auto variable = 5;
다음은 auto를 사용하면 유용할 만한 예제들이다. 제 5장에 반복자(iterator)라는 개념을 소개한다 (제 12장과 18장). 반복자는 유형이 길게 정의되는 경우가 자주 있다. 예를 들어
std::vector<std::string>::const_reverse_iterator
함수라면 이런 유형을 돌려줄 수 있다. 컴파일러는 함수가 돌려주는 유형을 알고 있기 때문에 auto를 사용하면 이 사실을 활용할 수 있다. begin() 함수가 다음과 같이 선언되어 있다고 가정하자:
std::vector<std::string>::const_reverse_iterator begin();
번잡하게 변수를 정의하는 대신에 (// 1) 훨씬 더 짧게 정의할 수 있다 (// 2):
std::vector<std::string>::const_reverse_iterator iter = begin(); // 1
auto iter = begin(); // 2
이런 유형의 변수를 추가로 쉽게 정의할 수 있다. iter를 사용하여 그런 변수들을 초기화할 때 auto 키워드를 사용할 수도 있다.
auto start = iter;
auto 키워드로 변수를 정의할 때 그 유형은 초기화 표현식으로부터 추론된다. 단순 유형과 포인터 유형은 그대로 사용되지만 초기화 표현식이 참조 유형이면 그 참조의 기본 유형이 사용된다 (참조가 없다면 const volatile 지정은 생략된다).
참조 유형이 요구되면 auto & 또는 auto &&를 사용하면 된다. 마찬가지로 auto 키워드 자체와 조합하여 const 와 포인터 지정을 사용할 수 있다. 다음은 몇 가지 예제이다.
int value;
auto another = value; // 'int another'가 정의된다.
string const &text();
auto str = text(); // 단순 유형으로서 문자열이다. 그래서
// string str로 정의되며,
// string const str로 정의되지 않는다.
str += "..."; // 그래서 OK이다.
int *ip = &value;
auto ip2 = ip; // int *ip2가 정의된다.
int *const &ptr = ip;
auto ip3 = ptr; // int *ip3이 정의된다, const &가 생략된다.
auto const &ip4 = ptr; // int *const &ip4가 정의된다.
마지막에 있는 auto 지정에서 (오른쪽에서 왼쪽으로 읽어서) 기본 유형을 가리키는 참조로부터 토큰들을 생략한다. 여기에서 const &가 ptr의 기본 유형에 추가되었다 (int *). 그러므로 int *ip2가 정의된다.
마지막의 auto 지정은 int *를 산출한다. 그러나 auto에 의하여 유형정의에 const &가 추가된다. 그래서 int *const &ip4가 정의된다.
단순히 auto를 사용하면 언제나 그 결과는 비-참조 유형이다. auto가 참조 유형을 참조해야 한다면 auto &&를 사용하면 된다.
기존의 변수를 사용하여 start를 즉시 초기화할 수 없으면 decltype 키워드와 함께 잘 알려진 변수나 함수를 사용할 수 있다. 예를 들어:
decltype(iter) start;
decltype(begin()) spare;
decltype 함수는 표현식도 인자로 받을 수 있다. 예를 들어 decltype(3 + 5)는 int를 나타내며 decltype(3 / double(3))는 double을 나타낸다.
auto와 다르게 decltype으로 도출된 유형은 값이거나 아니면 참조 유형이다. 이는 decltype에 건넨 표현식의 유형에 따라 달라진다. 예를 들어 int intVal와 int &&intTmp()를 사용할 수 있다면
decltype(intVal) iv(3); // iv는 int이다.
declType( (intVal) ) iref(intVal); // iref는 int &이다.
declType(intTmp()) tmpRef(f()); // tmpRef는 int &&이다.
게다가 C++14는 decltype(auto) 규격을 지원한다. 이 경우 decltype의 규칙에 auto가 적용된다. 예를 들어
decltype(auto) iref2((intVal)); // iref2는 int &이다.
auto iref3((intVal)); // iref3는 int이다.
함수의 반환 유형을 나중에 정의하는 데에도 auto 키워드를 사용할 수 있다. 10개의 int를 포인터로 돌려주는 intArrPtr 함수의 선언은 다음과 같다.
int (*intArrPtr())[10];
선언이 상당히 복잡하다. 그 중에서도 복잡한 것은 함수의 매개변수 리스트와 함께 괄호를 사용하여 `포인터를 보호해야' 한다는 것이다. 이와 같은 경우에 auto를 사용하여 반환 유형의 지정을 미루다가 다른 지정을 다 끝낸 후에 그 함수의 반환 유형을 지정할 수 있다. (예를 들어 먼저 상수 멤버 (7.7절) 또는 noexcept를 지정한 다음에 말이다 (23.7절)).
auto를 사용하여 위의 함수를 선언하려면:
auto intArrPtr() -> int (*)[10];
auto를 이용한 반환 유형 지정을 늦게-지정되는 반환 유형이라고 부른다.
auto 키워드는 auto에 연관된 실제 유형과 관련하여 정의된 유형에도 사용할 수 있다. 다음은 몇 가지 예이다.
vector<int> vi;
auto iter = vi.begin(); // 표준: auto는 vector<int>::iterator임
auto &&rref = vi.begin(); // auto는 반복자 유형에 대한 rvalue 참조이다.
auto *ptr = &iter; // auto는 반복자 유형을 가리키는 포인터이다.
auto *ptr = &rref; // 동일
auto를 돌려주는 함수에 대하여 C++14 표준은 더 이상 늦은 반환 유형의 지정을 요구하지 않는다. 그런 함수는 다음과 같이 선언할 수도 있다.
auto autoReturnFunction();
이 경우 함수 정의와 함수 선언에 모두 약간 제한이 있다.
auto만 돌려주는 함수는 컴파일러가 그의 정의를 보기 전에는 사용할 수 없다. 그래서 단순히 선언만으로는 사용할 수 없다.auto를 돌려주는 함수를 재귀 함수로 구현할 때 재귀 호출 전에 적어도 하나의 return 서술문은 보여야 한다.
예를 들어,
auto fibonacci(size_t n)
{
if (n <= 1)
return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
double, int, string 등등과 같이 단일한 값을 돌려주는 경우가 보통이다. 함수가 여러 값을 돌려줄 필요가 있다면 인자로 반환이라는 방법이 종종 사용된다. 변수의 주소가 함수에 건네지고 그래서 함수는 그 변수에 새 값을 할당할 수 있게 된다.
여러 값을 돌려 주어야 할 때 보통은 구조체를 사용한다. 그러나 std::pair (12.2절) 또는 std::tuple (22.6절)을 사용해도 된다. 다음은 간단한 예이다. fun 함수는 데이터 필드가 두 개 있는 구조체를 돌려준다.
struct Return
{
int first;
double second;
};
Return fun()
{
return Return{ 1, 12.5 };
}
(12.2절과 22.6절을 미리 간략하게 살펴보자:
fun 함수가 pair나 tuple을 돌려준다면 struct 정의를 완전히 생략할 수 있다. 그래도 코드는 여전히 유효하다.)
또다른 fun 함수 호출은 전통적으로 fun의 반환 유형과 유형이 같은 변수를 정의한다. 그리고 그 변수의 필드를 사용하여 first와 second에 접근한다. 타자하기가 귀찮다면 auto를 사용해도 된다.
int main()
{
auto r1 = fun();
cout << r1.first;
}
C++17 표준은 이 개념을 확장하여 구조화된 묶기 선언(structured binding declarations)을 도입했다. 여기에서 auto 다음에 (각괄호로 둘러 싸여) 쉼표로 분리된 변수 리스트가 따라온다. 이 리스트 안에 변수가 각각 정의된다. 그리고 호출된 함수의 반환 값에 각각 상응하는 요소나 필드의 값을 받는다. 그래서 위의 main 함수를 다음과 같이 작성해도 된다.
int main()
{
auto [one, two] = fun();
cout << one; // one과 two: 이제 정의됨
}
구조화된 묶기 선언을 참조 변수와 함께 사용할 수도 있다. 다음은 rone과 rtwo를 각각 int &&rone와 double &&rtwo로 정의한다.
int main()
{
auto &&[rone, rtwo] = fun();
}
함수-호출 자체보다 더 오래 생존하는 값을 호출된 함수가 돌려주는 경우에도 구조화된 묶기 선언을 사용하여 lvalue 참조 변수를 정의할 수 있다. 예를 들어,
Return &fun2()
{
static Return ret{4, 5};
return ret;
}
int main()
{
auto &[lone, ltwo] = fun2(); // OK: ret의 필드를 참조
}
구조화된 묶기 선언을 초기화할 때 함수가 반드시 구조체 안에 여러 값을 돌려줄 필요는 없다. 구조체를 익명으로 정의할 수도 있다:
int main()
{
auto &[lone, ltwo] = Return{4, 5};
}
심지어 이 구조체는 정의할 필요조차 없다. 12.2절에서 만나 볼 std::pair 컨테이너는 값 쌍을 정의한다. 그리고 터플이라는 일반화된 변종을 만나본다.
또 어떤 상황에서는 for 내포 서술문이나 선택 서술문에서 지역적으로 정의된 다른 유형의 변수들을 사용함으로써 혜택을 누릴 수 있다. 그런 변수들은 구조화된 묶기 선언을 사용하여 쉽게 정의할 수 있다. 이름없는 구조체나 페어 또는 터플로 초기화된다. 다음은 이를 보여주는 예제이다.
// 적절한 구조체를 정의한다 (또는 --상황에 따라-- 페어나 터플로 정의한다):
struct Three
{
size_t year;
double firstAmount;
double interest;
};
// 다음으로 유형이 다른 지역 변수를 사용하는
// for-서술문을 정의한다.
for (
auto [year, amount, interest] = Three{0, 1000, .03};
year <= 10;
++year, amount *= (1 + interest)
)
cout << "Year " << year << ": amount = " << amount << '\n';
/* 간략하게 출력:
Year 0: amount = 1000
Year 1: amount = 1030
Year 2: amount = 1060.9
...
Year 9: amount = 1304.77
Year 10: amount = 1343.92
*/
typedef는 복잡한 유형을 짧게 표기하여 정의하는 데 주로 사용된다. `double과 int를 기대하고 unsigned long long int를 돌려주는 함수를 가리키는 포인터에 대하여' 단축 표기를 정의하고 싶다고 해 보자. 그런 함수는 다음과 같다.
unsigned long long int compute(double, int);
그런 함수를 가리키는 포인터는 형태가 다음과 같다.
unsigned long long int (*pf)(double, int);
이런 종류의 포인터를 자주 사용한다면 typedef를 사용하여 정의하는 방법을 고려하라. 그냥 typedef를 그 앞에 놓으면 포인터의 이름이 한 유형의 이름으로 변환된다. 대문자로 만들면 유형의 이름임을 더 명확하게 나타낼 수 있다.
typedef unsigned long long int (*PF)(double, int);
이런 유형을 정의하고 난 후에 그런 포인터를 선언하거나 정의할 수 있다.
PF pf = compute; // 다음과 같은 함수를 가리키는 포인터로 초기화한다.
// 'compute'
void fun(PF pf); // fun 함수는 다음과 같은 함수를 포인터로 기대한다.
// 'compute'
그렇지만 포인터를 typedef 안에 포함하는 것은 별로 좋은 생각이 아닐 수 있다. pf가 포인터라는 사실이 가려지기 때문이다. 어쨌거나 PF pf는 `int *x' 보다는 `int x'와 더 비슷하다. pf가 실제로는 포인터라는 사실을 문서화하려면 typedef를 약간 바꾸자:
typedef unsigned long long int FUN(double, int);
FUN *pf = compute; // 이제 pf는 확실히 포인터이다.
typedef의 영역은 컴파일 단위로 제한된다. 그러므로 typedef는 일반적으로 헤더 파일에 내장된다. 그 다음 여러 소스 파일에 포함되고 거기에 typedef를 사용해야 한다.
typedef 말고도 C++는 using 키워드를 제공한다. 유형과 식별자를 연관지을 수 있다. 실제로 typedef와 using은 서로 바꾸어 사용할 수 있다. using 키워드가 유형을 좀 더 읽기 쉽게 정의한다. 다음 세 가지 (동등한) 정의를 연구해 보자:
typedef unsigned long long int FUN(double, int);
using을 적용해 유형 이름의 가시성을 개선한다. :
using FUN = unsigned long long int (double, int);
using FUN = auto (double, int) -> unsigned long long int;
for (init; cond; inc)
statement
보통은 초기화와 조건 그리고 증가 부분이 상당히 명확하다. 배열이나 벡터의 모든 원소들을 처리해야 하는 경우가 그런 상황이다. 그 목적으로 많은 언어에서 foreach 서술문을 제공한다. C++는 std::for_each 총칭 알고리즘을 제공한다 (19.1.17항 참고).
전통적인 구문외에도 C++에서는 for-서술문에 새로운 구문이 추가된다. 범위-기반의 for-회돌이가 그것이다. 이 새로운 구문은 한 범위 안의 모든 원소들을 순서대로 처리한다. 범위는 세 가지 유형으로 구분된다.
int array[10]);
begin()과 end() 함수를 제공하여 이른바 반복자를 돌려주는 기타 유형 (18.2절).
// int array[30]이라고 가정
for (auto &element: array)
statement
쌍점의 왼쪽 부분을 for 범위 선언이라고 부른다. 선언된 element변수는 형식적 이름이다. 마음껏 식별자를 사용해도 된다. 이 변수는 내포된 서술문 안에서만 사용할 수 있고 첫 원소부터 마지막 원소까지 범위 안에 있는 각 원소들을 가리킨다 (또는 사본이다).
공식적으로 auto를 사용해야 할 필요가 있는 것은 아니지만 auto를 사용하면 유용할 상황이 아주 많다. 범위가 복잡한 유형의 원소들을 가리키거나 또는 범위 안의 원소들을 가지고 무엇을 해야 할지는 알지만 유형의 정확한 이름은 신경쓰고 싶지 않을 경우에 사용하면 무척 유용하다. 위의 예제에서는 int를 사용해도 된다.
참조 심볼(&)은 다음과 같은 경우에 중요하다.
BigStruct 원소로 구성된 배열이라면 쓸데없이 비효율적이다.
struct BigStruct
{
double array[100];
int last;
};
배열의 원소를 복사할 필요가 없기 때문이다. 대신에 참조를 사용하라.
BigStruct data[100]; // 어디에선가 적절하게 초기화되었다고 간주한다.
int countUsed()
{
int sum = 0;
// const &: 이 원소들은 변경되지 않는다.
for (auto const &element: data)
sum += element.last;
return sum;
}
원소의 갯수와 조합하여 그의 첫 원소를 가리키는 포인터로만 data를 사용할 수 있으면 범위-기반의 for 회돌이도 사용할 수 있지만 약간의 도움이 필요하다. 24.5절에 그런 경우 범위 기반 for 회돌이의 보편적인 사용법을 기술한다.
\n과 \\ 그리고 \"와 같은 피신 연속열을 제공한다. 그런 ASCII-문자열의 연속을 널-종료 바이트 문자열이라고 부른다 (null-terminated byte strings (단수: NTBS, 복수: NTBSs).
C의 NTBS가 그 바탕으로서 그 위에 수 많은 코드가 건설되어 왔다.
어떤 경우 (예를 들어, XML의 문맥에서) 문자열 피신을 피하는 것이 유용할 경우가 있다. 이 목적을 위해 C++는 날 문자열 기호상수를 제공한다.
날 문자열 기호상수는 R이 오고 다음에 겹따옴표가 오고 그 다음에 라벨이 오며 ((가 아닌 문자열) 다음에 (으로 시작한다. 날 문자열은 닫는 괄호 )와 다음에 라벨이 따라 오며 그 다음에 겹따옴표로 끝난다. 예를 들어:
R"(A Raw \ "String")"
R"delimiter(Another \ Raw "(String))delimiter"
첫 번째의 경우, "(과 )" 사이의 모든 것이 문자열의 일부이다. 피신 연속열은 지원되지 않기 때문에 첫 번째 날 문자열 기호상수 안의 텍스트 \ "는 세 개의 문자로 정의된다. 역사선 하나와 빈 문자 그리고 겹따옴표가 된다. 두 번째 예제는 "delimiter( 와 )delimiter" 표식 안에 정의된 날 문자열을 보여준다.
날 문자열 기호상수는 (사용법 정보라든가 기다란 html-연속열의 경우와 같이) 복잡하고 기다란 ascii-문자가 사용될 때 아주 편리하다. 요약해 말하면 기다란 NTBS 연속열에 딱맞춤이다. 코드와 분리하는 것이 가독성을 높이고 코드를 유지 관리하는 데 좋다.
예를 들어 bisonc++ 파서 생성기는 --prompt 옵션을 지원한다. 이 옵션을 지정하면 디버깅이 필요할 때 bisonc++에 의하여 생성된 코드가 주의 코드를 삽입해 준다. 주의 코드를 처리하는 함수 안으로 날 문자열 기호상수를 직접적으로 삽입하면 그 결과 아주 읽기 어려운 코드가 만들어진다.
void prompt(ostream &out)
{
if (d_genDebug)
out << (d_options.prompt() ? R"(
if (d_debug__)
{
s_out__ << "\n================\n"
"? " << dflush__;
std::string s;
getline(std::cin, s);
}
)" : R"(
if (d_debug__)
s_out__ << '\n';
)"
) << '\n';
}
소스 파일의 익명 이름공간에 NTBS로 이름을 붙여 날 문자열 기호 상수를 정의하면 가독성이 크게 개선된다 (제 4장):
namespace {
char const *noPrompt =
R"(
if (d_debug__)
s_out__ << '\n';
)";
char const *doPrompt =
R"(
if (d_debug__)
{
s_out__ << "\n================\n"
"? " << dflush__;
std::string s;
getline(std::cin, s);
}
)";
} // 익명 이름공간
void prompt(ostream &out)
{
if (d_genDebug)
out << (d_options.prompt() ? doPrompt : noPrompt) << '\n';
}
0b101를 사용할 수도 있다. 공식적으로 이진 상수는 C++14 표준 이후로 지원되지만 C++14 표준이 구현되기 전이라도 C++ 컴파일러들은 이 특징을 잘 지원한다.
이진 상수는 비트-깃발(flag) 같은 문맥에 사용하면 편리하다. 어느 비트-필드가 설정되어 있는지 즉시 보여주기 때문이다. 반면에 다른 표기법으로는 정보를 얻을 수 없다.
C++ 표준은 다음 속성이 정의되어 있다.
[[noreturn]]:[[noreturn]]함수가 반환되지 않는다는 사실을 가리킨다. 이 속성으로 선언되어 있는 함수가 실제로 반환될 경우[[noreturn]]의 행위는 정의되어 있지 않다. 표준 함수들은 다음과 같은 속성이 있다.std::_Exit,std::abort,std::exit,std::quick_exit,std::unexpected,std::terminate,std::rethrow_exception,std::throw_with_nested,std::nested_exception::rethrow_nested.다음은
[[noreturn]]속성을 사용하여 함수를 선언하고 정의하는 예이다.[[noreturn]] void doesntReturn(); [[noreturn]] void doesntReturn() { exit(0); }
[[carries_dependency]]: 이 속성은 아직 이 책에서 다루지 않았다. 이 시점에서는 무시해도 좋다.
[[deprecated]]:이 속성은 (그리고 그의 다른 형태[[deprecated("reason")]]는) C++14 표준부터 사용할 수 있다. 이 속성으로 선언된 객체나 이름을 사용해도 좋다는 뜻이기는 하다. 그러나 어떤 이유로 사용하지 않는 것이 좋다. 이 속성은 클래스, typedef-이름, 변수, 비-정적 데이터 멤버, 함수, 열거체, 그리고 템플릿 특정화에 사용할 수 있다. 기존의 비추천이 아닌 객체는 비추천으로 재선언할 수 있지만 일단 비추천으로 선언되면 철회할 수는 없다.[[deprecated]]속성을 만나면 컴파일러는 경고를 보여준다. 예를 들어,demo.cc:12:24: warning: 'void deprecatedFunction()' is deprecated [-Wdeprecated-declarations] deprecatedFunction(); demo.cc:5:21: note: declared here [[deprecated]] void deprecatedFunction()대안 형태를 사용하면 (예를 들어
[[deprecated("do not use")]] void fun()) 컴파일러는 겹따옴표 사이에 경고 텍스트를 보여준다. 예를 들어,demo.cc:12:24: warning: 'void deprecatedFunction()' is deprecated: do not use [-Wdeprecated-declarations] deprecatedFunction(); demo.cc:5:38: note: declared here [[deprecated("do not use")]] void deprecatedFunction()
for 반복 서술문은 선택적인 초기화 절과 함께 시작한다. 초기화 절로 변수들을 for 서술문의 영역안에 가둘 수 있다.
C++17은 이 개념을 선택 서술문까지 확장한다. 이미 if 서술문과 switch 서술문의 조건절에서 변수들을 정의하고 초기화할 수 있지만, C++17부터 정의와 할당을 가를 수 있게 되었다. 그래서 초기화 절을 선택 서술문에 사용할 수 있다.
표준 입력 스트림으로부터 읽어 들인 다음 줄이 go!와 같을 경우에 어떤 조치를 취해야 한다고 가정해 보자.
안에 다음 줄을 되도록이면 많이 담도록 문자열을 지역화할 생각일지라도, 함수 안에 사용될 때는 다음과 같이 구성해야 한다.
void function()
{
// ... 서술문 나열
{
string line; // line을 지역화
if (getline(cin, line))
action();
}
// ... 서술문 나열
}
C++17는 선택적인 초기화 절을 if 서술문과 while 서술문에 추가한다 (쌍반점도 선택적임을 눈여겨보라. for 서술문에 있는 (쌍반점 없는) 초기화 절과 다르다). 그러므로 위의 예제를 다음과 같이 재작성할 수 있다.
void function()
{
// ... 서술문 나열
if (string line; getline(cin, line))
action();
// ... 서술문 나열
}
if-서술문처럼 switch-서술문도 선택적인 초기화 절을 지원한다. 프로그램이 명령어를 처리한다고 생각해 보자. 표준 입력으로 줄들이 들어 오고 convert 함수가 그 명령어를 열거 값으로 변환한다. 초기화 절을 switch 서술문에 적용하면, 모든 명령어들은 다음과 같이 처리될 것이다.
void process()
{
while (true)
{
switch (string cmd; int select = convert(getline(cin, cmd)))
{
case CMD1:
...
break;
case CMD2:
...
break;
...
}
}
}
실제로 조건 절에 변수를 여전히 정의할 수 있음을 주목하자. 이 사실은 확장된 if 서술문과 switch 서술문에도 마찬가지이다. 그러나 조건 절을 사용하기 전에 초기화 절이 먼저 사용되어야 추가 변수를 정의할 수 있을 것이다 (변수가 여러 개일 경우는 쉼표로 분리한 리스트가 담길 수 있는데, for-서술문에 사용하는 구문과 비슷하다).
C++는 이 내장 유형에 여러 내장 유형을 추가하여 확장한다. (아주 긴 유형의 예제를 보려면 다음을 참조: ANSI/ISO draft (1995), par. 27.6.2.4.1).void,char,short,int,long,float그리고double
bool,wchar_t,long long그리고long double
long long 유형은 단순히 두 개짜리 long 데이터 유형이다. long double은 단순히 두 개짜리 double 데이터 유형이다. 이 내장 유형과 더불어 포인터 변수를 C++ 주해서에서는 원시 유형이라고 부른다.
32-비트로 개발된 어플리케이션의 골격구조를 64비트로 변환할 때 알아야 할 미묘한 문제가 있다. long 유형과 포인터 유형만 크기가 32비트에서 64비트로 바뀐다. int 유형은 크기가 그대로 32비트이다. 이 때문에 포인터나 long 유형을 int 유형으로 변환할 때 데이터가 잘려 나갈 가능성이 있다. 또한, int보다 짧은 유형을 사용하여 표현식을 unsigned long이나 포인터에 할당할 때 부호 확장의 문제가 일어날 수 있다. 이 문제에 관한 더 상세한 정보는 여기에서 얻을 수 있다.
이런 내장 유형 외에도 클래스 유형의 string을 문자열 처리에 사용할 수 있다. 데이터 유형 bool과 wchar_t는 다음 절에 다룬다. string 데이터 유형은 제 5장에 다룬다. 최신 버전의 C라면 이런 새 데이터 유형을 이미 채택하고 있을 수도 있다 (bool과 wchar_t에 주목). 그렇지만 전통적으로 C는 그것들을 지원하지 않는다. 그러므로 여기에서 언급한다.
이제 새로운 유형을 소개했으므로 기호문자(letters)에 대한 기억을 되살려 보자. 다양한 유형의 기호 상수에 사용할 수 있다.
b 또는 B: 십육진 값을 나타내는 외에도 이진 상수도 정의할 수 있다. 예를 들어0b101는 십진수 5와 동등하다.0b접두사는 C++14 표준부터 이진 상수를 지정한다.
E 또는 e: 부동 소수점 기호 상수 값에서 지수 문자. 예를 들어1.23E+3. 여기에서E이하는 10의 3승(제곱)이라고 읽고 번역해야 한다. 그러므로1.23E+3는 값1230을 나타낸다.
F 비-정수형 상수 뒤에 접미사로 붙어float유형의 값을 나타낸다. 기본값인double이 아니다. 예를 들어12.F(점은 12를 부동 소수점 값으로 변환한다);1.23E+3F(앞 예제 참조.1.23E+3는double값이다. 반면에1.23E+3F는float값이다).
L 접두사로 사용해 문자열이wchar_t유형의 문자로 구성되어 있음을 나타낸다. 예를 들어L"hello world".
L 정수 값에 접미사로 사용해long유형의 값을 나타낼 수 있다. 기본 값인int가 아니다.short유형을 나타내는 데는 기호가 없음을 주목하자. 그를 위해서는static_cast<short>()를 사용해야 한다.
p십육진 부동소수점수에서 지수를 지정한다. 예,0x10p4. 지수 자체는 십진 상수로 읽는다. 그러므로 0x로 시작할 수 없다. 지수부는 2의 제곱으로 번역된다. 그래서0x10p2는 (십진수) 64와 동등하다.16 * 2^2.
U 정수 값 뒤에 접미사로 사용하면int가 아니라unsigned값을 나타낸다. 접미사L과 조합하면unsigned long int값을 생산할 수도 있다.
x 문자와 a, b, c, d, e 그리고 f 문자는 십육진 상수를 지정한다 (선택적으로 대문자를 사용할 수도 있다).
bool 유형은 불리언(논리) 값을 나타낸다. 값으로 (예약된) 상수 true와 false를 사용할 수 있다. 이렇게 예약된 값을 제외하고, 정수 값을 bool 유형의 변수에 할당할 수 있는데 그러면 묵시적으로 다음의 변환 규칙을 따라 true나 false로 변환된다 (intValue는 int-변수로 그리고 boolValue는 bool-변수로 간주한다):
// 정수에서 부울 값으로:
boolValue = intValue ? true : false;
// 부울 값에서 정수로:
intValue = boolValue ? 1 : 0;
게다가 bool 값이 스트림으로 삽입되면 true는 1로 표현되고 false는 0으로 표현된다. 다음 예제를 연구해 보자:
cout << "A true value: " << true << "\n"
"A false value: " << false << '\n';
bool 데이터 유형은 다른 프로그래밍 언어에서도 발견된다. Pascal은 Boolean 유형이 있고 Java는 boolean 유형이 있다. 이런 언어와 다르게 C++의 bool 유형은 일종의 int 유형처럼 작동한다. 주로 문서화를 개선하기 위한 유형이다. 단지 두 개의 값으로 true와 false만 있다. 실제로 이 값들은 1과 0에 대한 enum 값으로 해석할 수 있다. 그렇게 하면 bool 데이터 유형 뒤의 철학에 위배되지만 그럼에도 true를 int 변수에 할당하더라도 경고나 에러가 일어나지 않는다.
bool-유형을 사용하는 것이 int를 사용하는 것보다 더 명확하다. 다음 원형을 연구해 보자:
bool exists(char const *fileName); // (1)
int exists(char const *fileName); // (2)
첫 번째 원형을 보면 독자는 주어진 파일 이름이 기존의 파일 이름이면 함수가 true를 돌려줄 것이라고 기대한다. 그렇지만 두 번째 원형은 약간 모호하다. 직관적으로 반환 값 1이 그럴듯 해 보인다. 다음과 같이 구성할 수 있기 때문이다.
if (exists("myfile"))
cout << "myfile exists";
반면에 (access와 stat 그리고 기타 등등의) 많은 시스템 함수는 0을 돌려주어 연산에 성공했음을 알린다. 다른 값들은 다양한 유형의 에러를 나타내기 위해 예약되어 있다.
필자는 다음을 제일 규칙으로 삼기를 제안한다. 함수가 그의 호출자에게 성공이나 실패 여부를 알려주어야 한다면 그 함수에게 bool 값을 돌려주도록 한다. 함수가 다양한 유형의 에러 유형이나 성공 여부를 돌려주어야 한다면 그 함수에게 enum 값을 사용하도록 한다. 다양한 심볼 상수로 상황을 문서화한다. 함수가 개념적으로 의미 있는 정수 값을 돌려줄 때만 (두 int 값을 더한 결과) 그 함수가 int 값을 돌려주도록 한다.
wchar_t 유형은 광폭(wide) 문자 값을 포용하기 위해 char 내장 유형을 확장한 것이다 (다음 절도 참고). g++ 컴파일러는 sizeof(wchar_t)를 4로 보고한다. 이 정도면 65,536 개의 서로 다른 모든 유니코드 문자 값을 쉽게 수용한다.
Java의 char 데이터 유형은 C++의 wchar_t 유형에 비교된다는 것에 주목하라. 그렇지만 Java의 char 유형은 2 바이트 너비이다. 반면에 Java의 byte 데이터 유형은 C++의 char 유형과 비교된다. 1 바이트이다. 혼란스럽다!
L을 두면 (예, L"hello") wchar_t 문자열 기호상수를 정의한다.
C++는 또 8, 16 그리고 32 비트 유니코드 인코드 문자열을 지원한다. 게다가, 두 개의 데이터 유형을 새로 도입했다. char16_t와 char32_t가 그것으로서 각각 UTF-16 유니코드 값과 UTF-32 유니코드 값을 저장한다.
그리고 char 유형의 값은 utf_8 유니코드 값에 딱 맞는다. 값이 256 개를 넘어가면 (char16_t이나 char32_t처럼) 광폭 유형을 사용해야 한다.
유니코드 인코딩의 다양한 유형에 대하여 문자열 기호상수는 (그리고 연관 변수는) 다음과 같이 정의할 수 있다.
char utf_8[] = u8"이것은 UTF-8 인코드.";
char16_t utf16[] = u"이것은 UTF-16 인코드.";
char32_t utf32[] = U"이것은 UTF-32 인코드.";
다른 방식으로 유니코드 상수는 \u 피신 연속열을 사용하여 정의가 가능하다. 다음에 십육진 값을 배치하면 된다. 유니코드 변수 또는 상수의 유형에 따라 UTF-8이나 UTF-16 또는 UTF-32 값이 사용된다. 예를 들어,
char utf_8[] = u8"\u2018";
char16_t utf16[] = u"\u2018";
char32_t utf32[] = U"\u2018";
유니코드 문자열은 겹따옴표로 나눌 수 있지만 날 문자열 기호상수도 사용할 수 있다.
long long int 유형을 지원한다. 32 비트 시스템에서 적어도 64 개의 비트를 사용할 수 있다.
size_t 유형은 실제로는 내장된 원시 데이터 유형은 아니다. 그러나 POSIX가 양의 정수 값에 유형이름으로 사용하라고 밀어주는 데이터 유형이다. `얼마나 많이'와 같은 질문에 응답하려면 unsigned int 말고 이 유형을 사용해야 한다. C++에 국한된 유형이 아니며 C에도 사용할 수 있다. 시스템 헤더 파일을 포함할 때 묵시적으로 정의된다. C++ 문맥에서 size_t를 `공식적으로' 정의하고 있는 시스템 헤더 파일은 cstddef이다.
size_t를 사용하면 개념적 유형이라는 장점이 있다. 수식자로 변경이 되는 표준 유형이 아니다. 그래서 소스 코드의 자가 문서화의 가치를 개선한다.
어떤 경우 함수가 명시적으로 unsigned int를 사용하기를 요구하는 경우가 있다. 예를 들어, amd-골격구조에서 X-windows 함수인 XQueryPointer는 그의 인자 중 하나로 unsigned int 변수를 가리키는 포인터를 명시적으로 요구한다. 그렇다면 size_t 변수를 가리키는 변수를 사용할 수 없다. unsigned int 주소를 제공해야 한다. 그렇지만 그런 경우는 예외적인 경우이다.
다른 유용한 비트-표현 유형도 존재한다. 예를 들어, uint32_t는 32-비트 무부호 값을 보유한다고 보증한다. 비슷하게 int32_t는 32-비트 부호 값을 보유한다고 보증한다. 상응하는 유형이 8, 16 그리고 64 비트 값에도 존재한다. 이런 유형은 헤더 파일 cstdint에 정의되어 있다.
1'000'000
3.141'592'653'589'793'238'5
''123 // 컴파일 안됨
1''23 // 역시 컴파일 불가
(typename)expression
여기에서 typename은 유효한 유형의 이름이고 expression은 표현식이다.
C 스타일의 유형변환은 이제 추천하지 않는다. C++ 프로그램은 새 스타일의 C++ 유형변환을 사용해야 한다. 유형변환을 인지하는 컴파일러가 검증하도록 편의를 제공하기 때문이다. 이 편의기능은 고전적인 C-스타일의 유형변환에서 제공하지 않는다.
자주 사용되는 생성자 표기법과 유형변환을 서로 혼동하면 안된다.
typename(expression)
생성자 표기법은 유형변환이 아니라 expression으로부터 typename 유형의 (익명) 변수를 생성하라고 컴파일러에게 요구한다.
유형변환이 실제로 필요하면 여러 새-스타일의 유형변환 중에 하나를 사용해야 한다. 이 새 스타일의 유형변환을 다음 절에 소개한다.
static_cast<type>(expression)는 `개념적으로 비슷하거나 관련있는 유형'을 서로 변환한다. 여기는 물론 다른 C++ 스타일의 유형 변환에서 expression은 type 유형으로 변환되어야 한다.
다음은 static_cast를 사용할 수 있는 (또는 사용해야 하는) 상황의 예이다.
int를 double로 변환할 때
예를 들어 이런 일은 두 개의 int 값으로 나눗셈에서 분수 부분을 잃지 않고 몫을 계산해야 할 경우에 일어난다. sqrt 함수를 두 개의 다음 분수로 호출하면 2를 반환한다.
int x = 19; int y = 4; sqrt(x / y);반면에 다음과 같이
static_cast를 사용하면 2.179를 반환한다.
sqrt(static_cast<double>(x) / y);여기에서 눈여겨볼 점은 그의
expression의 표현을 목표 유형이 사용하는 표현으로 바꾸는 데 static_cast가 허용된다는 것이다.
또 주목할 것은 나눗셈은 유형변환 표현식의 바깥에 배치되어 있다는 사실이다. (static_cast<double>(x / y)과 같이) 나눗셈이 유형변환의 expression 안에서 수행되면 정수 나눗셈이 먼저 수행되고 나서 피연산자의 유형을 double 유형으로 변환할 기회를 가진다.
enum 값을 int 값으로 변환할 때 (방향에 상관 없음).
여기에서 두 유형은 표현이 같지만 의미구조가 다르다. 평범한 enum 값을 int에 할당하면 유형을 변환하지 않아도 된다. 그러나 강력하게 유형이 정의되는 열거체라면 유형을 변환해야 한다. 반대로 int 값을 열거체 유형의 변수에 할당할 때 static_cast가 요구된다. 다음은 예이다.
enum class Enum
{
VALUE
};
cout << static_cast<int>(VALUE); // 숫치 값을 보여준다.
클래스 상속의 문맥에서 이른바 `파생 클래스'를 가리키는 포인터를 그의 `바탕 클래스'를 가리키는 포인터로 변환하는 데 static_cast가 사용된다 (제 13장). 관련 없는 유형을 서로 변환하는 곳에는 사용할 수 없다 (예를 들어 short를 가리키는 포인터를 int를 가리키는 포인터로 변환하는 데 static_cast를 사용할 수 없다).
void *는 총칭 포인터이다. C 라이브러리 함수에 자주 사용된다 (예를 들어 memcpy(3)). 총칭 포인터이기 때문에 다른 모든 포인터와 관련이 있으므로 static_cast를 사용하여 void *를 원하는 목표 포인터로 변환해야 한다. 이것은 C로부터 물려 받은 약간 고약한 유산인데 아마도 그 문맥 안에서만 사용되어야 할 것이다. 다음은 한 예이다.
C 라이브러리의 qsort 함수는 두 개의 void const * 매개변수가 있는 (비교) 함수를 포인터로 기대한다. 실제로 이 매개변수들은 배열에서 정렬될 데이터 원소들을 가리킨다. 그래서 비교 함수는 반드시 void const * 매개변수를 정렬될 배열 원소들을 가리키는 포인터로 변환해야 한다. 그래서 배열이 int array[]이고 비교 함수의 매개변수가 void const *p1과 void const *p2이라면 비교 함수는 다음과 같이 p1이 가리키는 int의 주소를 얻는다.
static_cast<int const *>(p1);
int인 변수의 부호-수식자를 해제하거나 도입할 때 (표현식의 표현을 바꾸는 데 static_cast가 허용된다는 사실을 기억하라!).
다음은 한 예이다. C 언어의 tolower 함수는 unsigned char 값을 나타내는 int를 요구한다. 그러나 char는 기본으로 부호가 있는 유형이다. char ch를 사용하여 tolower를 호출하려면 다음과 같이 사용해야 한다.
tolower(static_cast<unsigned char>(ch))
const 키워드는 유형변환에서 지위가 특별하다. 무엇이든 const이면 합당한 이유가 있어서 불변이다. 그럼에도 const를 무시해도 좋은 상황이 있다. 이런 특별한 상황을 위해 const_cast를 사용한다. 그 구문은 다음과 같다.
const_cast<type>(expression)
(포인터) 유형의 const 속성을 해제하기 위해 const_cast<type>(expression) 표현식이 사용된다.
전통적으로 그래야 할 경우에도 언제나 상수를 인지하지 못하는 표준 C 라이브러리의 함수와 조합해 사용하면 const_cast가 필요할 경우가 있다. strfun(char *s) 함수도 사용이 가능하다. 실제로 s가 가리키는 문자들을 변경하지 않고 char *s 매개변수에 연산을 수행한다. char const hello[] = "hello";를 strfun에 건네면 경고가 일어난다.
passing `const char *' as argument 1 of `fun(char *)' discards const
const_cast가 그 경고를 방지하는 적절한 방법이다.
strfun(const_cast<char *>(hello));
reinterpret_cast 연산자는 정보의 해석을 바꾼다. 약간 static_cast와 비슷해 보이지만 reinterpret_cast는 정의된 정보가 실제로 무엇인가 완전히 다른 것으로 해석될 수 있다는 것이 확실할 때에만 사용해야 한다. 그 구문은 다음과 같다.
reinterpret_cast<pointer type>(pointer expression)
reinterpret_cast를 공용체를 제공하는 유형변환이라고 생각하라. 같은 메모리 위치를 완전히 다르게 해석할 수 있다.
예를 들어 reinterpret_cast는 스트림에 사용가능한 write 함수와 조합하여 사용된다. C++에서 스트림은 디스크-파일보다 선호되는 인터페이스이다. std::cin과 std::cout 같은 표준 스트림도 객체이다.
쓰기용 스트림은 (cout 같은 `출력 스트림') write 멤버를 제공한다. 원형은 다음과 같다.
write(char const *buffer, int length)
double 변수에 저장된 값을 해석되지 않은 이진 형태로 스트림에 쓰기 위해 스트림의 write 멤버가 사용된다. 그렇지만 double *과 char *는 전혀 다른 서로 관련이 없는 표현을 사용하는 포인터를 가리키기 때문에 static_cast를 사용할 수 없다. 이 경우 reinterpret_cast가 필요하다. double value 변수의 날 바이트를 cout에 쓰기 위해 다음과 같이 사용한다.
cout.write(reinterpret_cast<char const *>(&value), sizeof(double));
유형변환은 무엇이든 잠재적으로 위험하다. 그 중에서도 reinterpret_cast가 가장 위험하다. 효과적으로 컴파일러에게 알린다. 되돌아가 보면 우리는 무엇을 하고 있는지 알고 있으므로 추론을 멈춘다. 원점으로 되돌아가 다음과 같은 상황에 우리가 무엇을 하고 있는지 알아 두는 게 좋다. 해당 사례로서 다음 코드를 연구해 보자:
int value = 0x12345678; // 32-비트 int로 간주
cout << "Value's first byte has value: " << hex <<
static_cast<int>(
*reinterpret_cast<unsigned char *>(&value)
);
위의 코드는 컴퓨터의 종료형에 따라 결과가 달라진다. 작은값 종료형 컴퓨터는 값으로 78을 보여주고 큰값 종료형 컴퓨터는 값으로 12를 보여준다. 꼭 유념하라. 컴퓨터의 종료형에 따라 표현이 다르기 때문에 이전의 예제가 (cout.write(...)) 골격구조가 다른 컴퓨터를 건너 이식이 불가능하게 되어 버렸다.
제일 규칙으로서 유형을 변환해야 한다면 확실하게 그 이유를 코드에 문서화하라. 유형변환으로 인해 결국 프로그램이 잘못 행동하지는 않는지 거듭 확인하라. 사용하지 않아도 된다면 reinterpret_casts는 피하는 게 좋다.
dynamic_cast<type>(expression)
조치가 컴파일 시간에 완전히 결정되는 static_cast와 다르게 dynamic_cast의 조치는 실행 시간에 결정된다. 클래스의 객체를 가리키는 포인터를 (예를 들어, Base) 또다른 클래스의 객체를 가리키는 포인터로 (예를 들어, Derived) 변환한다. 이른바 클래스 계통도를 따라 내려가 발견된다. 이것을 하향 유형변환(downcasting)이라고도 부른다.
아직 이 시점에서 dynamic_cast는 광범위하게 다룰 수 없지만 14.6.1항에 다시 이 주제를 다룬다.
shared_ptr 클래스의 문맥에서 이는 18.4절에 다루는데, 여러 새 스타일의 유형변환을 더 사용할 수 있다. 이런 특수 목적의 유형변환은 실제로 나중으로 미루어서 18.4.5항에 다룬다.
다음과 같은 특수 유형변환이 있다.
static_pointer_cast - 파생 클래스 객체의 바탕-클래스 부분을 가리키는 shared_ptr을 돌려준다.
const_pointer_cast - 상수 객체를 가리키는 shared_ptr 비-상수 객체를 가리키는 shared_ptr을 돌려준다.
dynamic_pointer_cast - 바탕 클래스를 가리키는 shared_ptr로부터 파생 클래스 객체를 가리키는 shared_ptr을 돌려준다.
alignas char32_t enum namespace return typedef alignof class explicit new short typeid and compl export noexcept signed typename and_eq concept extern not sizeof union asm const false not_eq static unsigned auto const_cast float nullptr static_assert using axiom constexpr for operator static_cast virtual bitand continue friend or struct void bitor decltype goto or_eq switch volatile bool default if private template wchar_t break delete import protected this while case do inline public thread_local xor catch double int register throw xor_eq char dynamic_cast long reinterpret_cast true char16_t else mutable requires try
주의:
export 키워드는 더 이상 C++에서 자주 사용되지 않지만 키워드로 유지되고 있고 미래의 사용을 위해 예약되어 있다.
register 키워드는 더 이상 사용되지 않는다. 그러나 여전히 예약어로 남아 있다. 다시 말해 다음과 같이 정의하면
register int index;
컴파일 에러가 일어난다. 또 register는 더 이상 저장 클래스 지정자(storage class specifier)로 간주되지 않는다 (저장 클래스 지정자로는 extern, thread_local, mutable 그리고 static이 있다).
and, and_eq, bitand, bitor, compl, not, not_eq, or, or_eq, xor 그리고 xor_eq는 각각 &&, &=, &, |, ~, !, !=, ||, |=, ^ 그리고 ^= 심볼로 대체된다.
final과 override를 특별한 식별자로 인지한다. 이 식별자들은 다형적 함수나 클래스를 정의할 때 특별한 의미가 있다. 14.4절에 더 자세하게 다룬다.
키워드는 의도된 목적으로만 사용할 수 있으며 다른 개체를 위한 (예를 들어, 변수나 함수, 클래스 이름 등등) 이름으로 사용할 수 없다. 키워드와 더불어 밑줄로 시작하고 전역 이름공간에 존재하는 식별자는 (즉, 명시적인 이름공간을 사용하지 않거나 단순히 :: 이름공간만을 사용하는 식별자) 또는 std 이름공간에 존재하는 식별자는 구현자 전용으로 사용된다는 점에서 예약된 식별자나 다름없다.