멀티 쓰레딩은 광범위하고 복잡한 주제이다. 이 주제에 관하여 훌륭한 참고서가 많이 있다. C++의 멀티 쓰레딩은 pthreads 라이브러리가 제공하는 편의기능 위에 건설되었다 (Nichols, B, et al.의 Pthreads 프로그래밍, O'Reilly ). 그렇지만 오늘날의 C++ 철학에 맞게 멀티-스레딩 구현은 높은 수준의 인터페이스를 제공한다. 날 상태의 pthread 빌딩 블록을 사용할 필요가 거의 없다 (참고. Williams, A. (2012): C++ Concurrency in action, Manning).
이 장은 C++가 지원하는 멀티 쓰레딩을 위한 편의기능들을 다룬다. 스스로 멀티 쓰레드 프로그램을 만들 수 있을 정도로 도구들과 예제를 제공한다. 그만큼 다루는 것을 목표로 하지만 완벽하게 모두 다룰 수는 없다. 멀티 쓰레딩이라는 주제는 다루기에 너무 광범위하다. 언급한 참고서 중에서 멀티 쓰레딩의 연구를 더 깊이 시작할 곳을 찾아 보라.
실행 쓰레드는 (보통 thread로 지칭) 프로그램 안에서 단일 실행 흐름이다. fork(1) 시스템 호출로 만들어져 따로따로 실행되는 프로그램과 다르다. 쓰레드는 모두 한 프로그램 안에서 실행되는 반면에 fork(1)는 실행 프로그램을 따로 복사해 만들기 때문이다. 멀티-쓰레딩은 여러 과업을 한 프로그램 안에서 병행적으로 실행하는 것을 의미한다. 그리고 쓰레드가 처음이든 마지막이든 또는 어떤 순간에 있든 어떤 가정도 하지 않는다.
특히 쓰레드의 갯수가 코어의 갯수를 넘어가지 않으면 각 쓰레드는 동시에 활성화될 수 있다. 쓰레드의 갯수가 코어의 갯수를 초과하면 운영 체제는 작업 전환에 기대어, 각 쓰레드마다 시간을 분배해 각 과업을 수행할 수 있도록 해준다. 과업 전환은 시간이 든다. 수확 체감의 법칙이 여기에도 적용된다. 쓰레드의 갯수가 코어의 갯수를 많이 초과하면 그 때문에 손상된 부담이 병행적으로 여러 과업을 수행하는 장점을 넘어갈 수 있다 (과잉생성(overpopulation)).
한 프로그램 안에서 실행중이기 때문에 모든 쓰레드는 프로그램의 데이터와 코드를 공유한다. 같은 데이터를 여러 쓰레드에서 접근할 때 그리고 하나의 쓰레드라도 이 데이터를 변경하려면 동기적으로 접근해야 한다. 한 쓰레드가 데이터를 읽는 동안 다른 쓰레드가 그 데이터를 변경하면 안되기 때문이다. 그리고 여러 쓰레드가 같은 데이터를 동시에 변경하면 안되기 때문이다.
그래서 C++로 어떻게 멀티-쓰레드 프로그램을 실행해야 하는가? hello world 프로그램을 멀티 쓰레드 방식으로 살펴 보자:
1: #include <iostream>
2: #include <thread>
3:
4: void hello()
5: {
6: std::cout << "hello world!\n";
7: }
8:
9: int main()
10: {
11: std::thread hi(hello);
12: hi.join();
13: }
thread 헤더를 포함해 컴파일러에게 std::thread 클래스의 존재를 알린다 (20.2.2항).
std::thread hi 객체가 생성된다. 함수의 이름이 제공된다 (hello). 별도의 쓰레드로 호출될 것이다. std::thread가 이런 식으로 정의되면 실제로 hello를 실행하는 두번째 쓰레드가 즉시 시작된다.
main 함수 자체가 쓰레드를 대표한다. 프로그램의 첫 번째 쓰레드이다. 두 번째 쓰레드가 끝날 때까지 기다려야 한다. 이것은 12 번 줄에서 실현되는데, 여기에서 hi.join()는 hi 쓰레드가 작업을 마칠 때까지 기다린다. 그러면 더 이상 main에 서술문이 없으므로 프로그램은 즉시 끝난다.
hello 함수는 별게 아니다. 단순히 텍스트 `hello world'를 cout 안으로 삽입하고 끝난다. 그리하여 두 번째 쓰레드가 끝난다.
Gnu g++ 컴파일러를 사용하여 멀티-쓰레드 프로그램을 컴파일할 때 -pthread 옵션을 지정해야 한다. 링크 시간에 libpthread 라이브러리도 역시 사용할 수 있어야 한다.
소스 파일 multi.cc에 정의된 멀티-쓰레드 프로그램을 만들기 위해 g++ 컴파일러를 다음과 같이 호출할 수 있다.
g++ --std=c++11 -pthread -Wall multi.cc
미리-컴파일된 여러 객체를 링크해야 한다면 -lpthread 링커 옵션도 지정해야 한다.
멀티-쓰레드 프로그램에서 쓰레드는 보통 시간이 아주 짧기는 하지만 자주 지연된다. 예를 들어 쓰레드가 변수에 접근해야 하지만 그 변수를 현재 다른 쓰레드가 갱신중이라면 첫 번째 쓰레드는 두 번째 쓰레드가 갱신을 완료할 때까지 기다려야 한다. 변수를 갱신하는 것은 보통 시간이 별로 걸리지 않지만 예상치 못하게 시간이 걸리면 기다리는 쓰레드는 그에 관하여 고지를 받고 싶을 것이다. 그래야 두 번째 쓰레드가 변수 갱신을 완료하지 못하는 동안 다른 일을 할 수 있기 때문이다.
기다리는 데 sleep 함수와 select 함수를 사용할 수 있지만 이 도구들은 멀티 쓰레드가 보편화되지 않은 시기에 설계되었다. 그래서 멀티 쓰레드 프로그램에 사용할 때 약간 부족한 점이 있다.
그 간극은 STL로 채운다. 시간 전문 지정 클래스를 제공하는데 시간-종속적인 쓰레드 멤버와 아주 잘 어울린다. 쓰레드는 다음 20.2절의 주제이다. 그 전에 먼저 시간 지정의 편의기능을 살펴 보겠다.
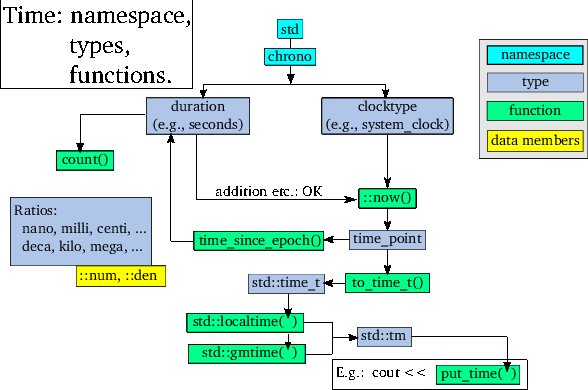
std::ratio 클래스 템플릿에 정의되어 있다 (측정 단위는 1초이다.).
ratio 클래스를 사용하려면 먼저 <ratio> 헤더를 포함해야 한다. 보통 <chrono> 헤더를 포함하면 되는데, 그 안에 ratio 헤더가 들어 있다. 그리고 시간 지정 편의기능들은 chrono 헤더를 포함한 후에 사용이 가능하다.
ratio 클래스 템플릿은 두 개의 정수 템플릿 인자를 기대한다. 양을 각각 피젯수와 젯수로 정의한다. 기본값으로 나누는 수는 1이며, 그러므로 ratio의 첫 인자(나뉘는 수)가 시간의 양을 나타낸다. 예를 들어:
ratio<1> - 1 초를 나타냄;
ratio<60> - 60 초를 나타냄
ratio<1, 1000> - 1/1000 초를 나타냄.
ratio 클래스 템플릿은 직접 접근 가능한 데이터 필드를 두 개 정의한다. num은 나뉘는 수(분자)를 나타내고 den은 나누는 수(분모)를 나타낸다. ratio 정의 자체가 그냥 일정한 양을 정의한다. 다음 프로그램을 실행하면
#include <ratio>
#include <iostream>
using namespace std;
int main()
{
cout << ratio<5, 1000>::num << ',' << ratio<5, 1000>::den << '\n';
}
텍스트 1,200을 화면에 보여준다. 그것이 ratio<5, 1000>으로 나타내는 `양'이기 때문이다. ratio는 가능하면 분수를 약분한다는 것을 주의하라. 그러므로 1/200 초이다.
ratio 유형으로 상당히 큰 수가 미리 정의되어 있다. 좀 귀찮은 ratio<x> 또는 ratio<x, y> 규격 대신에 사용할 수 있다.
| 유형이름 | 단위 초 | 측정 단위 |
| yocto | 10-24 | std::ratio<1, 1000000000000000000000000> |
| zepto | 10-21 | std::ratio<1, 1000000000000000000000> |
| atto | 10-18 | std::ratio<1, 1000000000000000000> |
| femto | 10-15 | std::ratio<1, 1000000000000000> |
| pico | 10-12 | std::ratio<1, 1000000000000> |
| nano | 10-9 | std::ratio<1, 1000000000> |
| micro | 10-6 | std::ratio<1, 1000000> |
| milli | 10-3 | std::ratio<1, 1000> |
| centi | 10-2 | std::ratio<1, 100> |
| deci | 10-1 | std::ratio<1, 10> |
| deca | 101 | std::ratio<10, 1> |
| hecto | 102 | std::ratio<100, 1> |
| kilo | 103 | std::ratio<1000, 1> |
| mega | 106 | std::ratio<1000000, 1> |
| giga | 109 | std::ratio<1000000000, 1> |
| tera | 1012 | std::ratio<1000000000000, 1> |
| peta | 1015 | std::ratio<1000000000000000, 1> |
| exa | 1018 | std::ratio<1000000000000000000, 1> |
| zetta | 1021 | std::ratio<1000000000000000000000, 1> |
| yotta | 1024 | std::ratio<1000000000000000000000000, 1> |
예를 들어 10 초라면 std::ratio<10> == std::ratio<10, 1> == std::deca이다.
주의: yocto, zepto, zetta 그리고 yotta의 정의는 64비트가 넘는 정수형 상수를 사용한다. 이 상수들이 C++에 정의되어 있더라도 64 비트 이하의 골격구조라면 사용할 수 없다.
std::chrono::duration 클래스 템플릿은 std::chrono 이름 공간에 정의되어 있다. duration 클래스의 객체는 지속시간을 정의한다.
duration 클래스를 사용하려면 먼저 <chrono> 헤더를 포함해야 한다. 이 파일 안에 <ratio> 헤더 파일이 들어 있다.
duration 클래스 템플릿은 템플릿 유형 인자를 두 개 요구한다. 하나는 숫자 유형으로서 (보통 int64_t) 지속시간을 정의하고 다른 하나는 측정 단위로서 주기(Period)라고 부르는데 보통 ratio 클래스 템플릿을 사용하여 정의된다.
여기에서 미리 정의된 ratio 유형들은 세밀하게 단위를 고르는 작업을 도와준다. 30분을 지정하려면 다음과 같이 사용할 수 있다.
std::chrono::duration<int64_t, std::deca> halfHr(180)
결과는 1800초가 된다. 그러나 `using namespace std'와 `using namespace chrono'를 사용하더라도 이것은 좀 복잡하며 직관적이지 않다. 다행스럽게도 미리 정의된 지속시간의 유형이 다양하게 존재한다.
std::chrono::minutes halfHour(30)과 같이 손쉽게 정의할 수 있다.
duration 클래스 템플릿 자체에 두 가지 유형이 정의된다.
std::chrono::duration<Value, Period>::rep:
duration이 사용하는Value유형 (예를 들어,int64_t)
std::chrono::duration<Value, Period>::period:
duration이 사용하는ratio유형 (예를 들어,std::ratio::nano). (그래서 이전 항에 언급한 바와 같이period자체는 정적인 값num나누는 수와den나뉘는 수를 가진다).
이 유형들은 duration 객체로부터 decltype을 사용하여 열람할 수 있다. 예를 들어,
auto time(minutes(3) * 3);
cout << decltype(time)::period::num; // 출력 60
이 유형말고도 duration 클래스 템플릿은 다음 생성자를 제공한다.
constexpr duration():
기본 생성자는 0 시간 단위의 지속시간을 정의한다.
constexpr explicit duration(Value const &value):
value시간 단위의 지속시간을 지정한다. 여기에서Value는 지속시간의 숫치 유형을 참조한다 (예를 들어,int64_t). 그래서 다음과 같이 정의하면std::chrono::minutes halfHour(30);인자 30은int64_t안에 저장된다.
duration는 복사 생성자와 이동 생성자도 제공한다.
그리고 duration은 다음과 같은 멤버가 있다.
지속시간 객체는 숫치 값으로 더하고 빼고 곱하고 나눌 수 있다. 또한 나머지 연산자(modulo)도 지원한다. 이 경우 오른쪽 피연산자에 상수 정수를 사용한다. 이항 산술 연산자와 이항 반영 할당 연산자도 사용할 수 있다.
constexpr Value count() const:
duration객체 안에 저장된 value를 돌려준다.halfHour에 대하여 1800이 아니라 30을 돌려준다. 시간 단위 자체를duration<Value, Unit>::period유형으로부터 얻기 때문이다.
static constexpr duration zero():
정적 멤버로서 0 시간 단위의 지속을 나타내는 지속시간 객체를 돌려준다.
static constexpr duration min():
정적 멤버로서 numeric_limits<Rep>::lowest()를 나타내는 지속시간 객체를 돌려준다.
static constexpr duration max():
정적 멤버로서 numeric_limits<Rep>::max()를 나타내는 지속시간 객체를 돌려준다.
정밀도가 소실되지 않는 한, 다양한 duration 유형을 조합할 수 있다. 이항 산술 연산자를 사용하면 결과 duration은 둘 중 더 정밀한 값을 사용한다. 이항 반영 할당 연산자를 사용하면 왼쪽 피연산자의 정밀도는 적어도 오른쪽 피연산자의 정밀도와 같아야 한다. 그렇지 않으면 컴파일 에러가 일어난다. 예를 들어,
minutes halfHour(30);
seconds half_a_minute(30);
cout << (halfHour + half_a_minute).count(); // 1830을 보여줌
//halfHour += half_a_minute; 컴파일 안됨: 정밀도 소실
half_a_minute += halfHour;
cout << half_a_minute.count(); // 1830을 보여줌
C++14 표준은 정수 값에 대하여 접미사 h, min, s, ms, us, ns를 정의하여, 그에 상응하는 duration 시간 간격을 만든다. 예를 들어, minutes oneMinute = 1min이다.
std::chrono 이름공간에 정의되어 있다.
이 시계들을 사용하기 전에 <chrono> 헤더를 포함해야 한다.
std::chrono::time_point 클래스를 사용하여 시각을 참조할 때 시계 유형을 지정해야 한다 (다음 항 참고). 따로 자신만의 시계 유형을 정의하는 것도 가능하다 (이 책에서는 다루지 않는다. C++11 표준의 20.11.3 절에 시계 유형의 필수 조건이 기술되어 있다.).
미리 정의된 Clock 시계 유형은 다음의 유형을 정의한다.
std::chrono::Clock::duration:
Clock이 사용하는duration유형 (예를 들어std::chrono::nanoseconds)
std::chrono::Clock::period:
Clock이 사용하는 시간 간격 (예를 들어std::ratio::nano)
std::chrono::Clock::rep:
Clock이 지속시간을 저장하기 위하여 사용하는 값의 유형을 정의한다 (예를 들어int64_t)
std::chrono::Clock::time_point:
Clock에 사용되는 시각 (예를 들어std::chrono::time_point<system_clock, duration>)
이 유형 말고도 미리 정의된 시계는 다음 멤버를 제공한다.
세 가지 시계 유형이 미리 정의되어 있다.
std::chrono::system_clock:
`바탕화면 시계'의 시간 즉, 시스템의 실시간 시계를 사용한다.now말고도system_clock은 다음 두 개의 정적 멤버를 제공한다.
static std::time_t std::chrono::system_clock::to_time_t (std::chrono::time_point const & timePoint)std::time_t값이 사용된다 ( C의 time(2) 함수가 돌려주는 유형과 같다).timePoint와 같은 시각을 나타낸다. 예제:std::chrono::system_clock::to_time_t( std::chrono::system_clock().now() )static std::chrono::time_point std::chrono::system_clock::from_time_t (std::time_t seconds)time_point값이다.time_t와 같은 시각을 나타낸다.
std::chrono::steady_clock:
실시간의 증가와 병행하여 시각이 같이 증가하는 시계.
std::chrono::high_resolution_clock:
컴퓨터에서 가장 빠른 시계 (즉, 측정-주기가 가장 짧은 시계). 사실상 system_clock이다.
예제: 현재 시각에 접근하려면 다음과 같이 하면 된다.
auto point = std::chrono::system_clock::now();
time_point 클래스는 std::chrono 이름공간에 정의되어 있다. std::chrono::time_point 클래스의 객체는 시각을 정의한다.
std::chrono::time_point 클래스를 사용하기 전에 <chrono> 헤더를 포함해야 한다.
time_point는 클래스 템플릿이다. Clock 유형과 Duration 유형 두 개의 템플릿 유형을 인자로 요구한다. Clock 유형은 chrono::system_clock과 같이 미리 정의된 시계 유형 중 하나이다. Duration 유형은 생략해도 된다. 이경우 Clock의 지속시간 유형이 사용된다. 명시적으로 Duration 유형을 제공할 수도 있다.
이전 항에서 auto 키워드를 사용하여 system_clock::now 반환 값의 유형을 지정했다. 명시적으로 정의하면 다음과 같다.
std::chrono::time_point<std::chrono::system_clock> now =
std::chrono::system_clock::now();
std::chrono::time_point 클래스는 세 가지 생성자를 갖추고 있다.
time_point():시계의 시작을 나타내는 기본 생성자: 1970년 1월 1일 00:00시가 기원(epoch)이다.
time_point(time_point<Clock, Duration> const &timeStep):
time_point객체를 초기화하여timeStep과Duration단위로 해당 시계의 기원 이후로 경과한 시각을 나타낸다.
time_point(time_point<Clock, Duration2> const &timeStep):
이 생성자는 멤버 템플릿으로 정의된다. 템플릿 헤더template <typename Duration2>를 사용한다.Duration2유형은std::chrono::duration(또는 그 비슷한) 유형이다.time_point의Duration유형보다 좀 더 큰 단위를 사용한다. 해당 시계의 기원 이후로 경과한 시각을timeStep과Duration2단위로 나타내도록time_point객체를 초기화한다.
std::chrono::time_point 클래스는 다음 연산자와 멤버가 있다.
std::chrono::time_point &operator+=(Duration const &duration):
이 연산자는 (순서에 상관 없이) 이항 산술 연산자로도 사용할 수 있다. 인자로std::chrono::time_point const &와Duration const &를 기대한다.duration이 나타내는 시간의 양이 현재time_point값에 더해진다. 예제:std::chrono::system_clock::now() + seconds(5);
std::chrono::time_point &operator-=(Duration const &duration):
이 연산자는 이항 산술 연산자로 사용할 수도 있다. (순서에 상관없이) 인자로std::chrono::time_point const &와Duration const &를 기대한다.duration이 나타내는 시간의 양을 현재time_point값으로부터 뺀다. 예제:auto point = std::chrono::system_clock::now(); point -= seconds(5);
constexpr Duration time_since_epoch() const:
기원 이후로 객체의 Duration을 돌려준다.
static constexpr time_point min():
시각의 duration::min 값이 반환한 값을 돌려주는 정적 멤버이다.
static constexpr time_point max():
시각의 duration::max 값이 반환한 값을 돌려주는 정적 멤버이다.
미리 정의된 시계는 모두 측정 단위로 나노초를 사용한다. 더 큰 측정 단위로 표현하려면 time_point 객체의 count 멤버가 돌려주는 값을 나노초로 변환하여 더 큰 측정 단위로 나누자. 기원 이후로 지난 시간은 다음과 같다.
using namespace std;
using namespace chrono; // 간결하게 선언
cout << system_clock::now().time_since_epoch().count() /
nanoseconds(hours(1)).count() << " hours since the epoch\n";
6.3.2항에 std::put_time 함수를 간략하게 소개했다. 이 항은 std::put_time 클래스와 그에 관련된 함수들을 더 자세하게 살펴 본다.
그림 22는 다양한 시간을 C++이 어떻게 처리하는지 보여준다. 시작점은 system_clock::now 함수로부터 얻은 time_point이다. time_point 실체의 주소는 to_time_t 함수에 건넬 수 있다. 그러면 std::time_t를 돌려준다.
std::time_t 값을 처리하는 데 두 개의 함수를 사용할 수 있다.
std::tm *std::localtime(std::time_t const *time):
이 함수는 std::tm 실체를 포인터로 돌려준다. 이 실체는 지역 시간의 요소들을 화면에 보여주는 데 사용되는 데이터를 담고 있다.
std::tm *std::gmtime(std::time_t const *time):
이 함수는 std::tm 실체를 포인터로 돌려준다. 이 객체는 UTC (universal time coordinated(협정 세계시: CUT(Coordinated Universal Time)와 TUC(프랑스어: Temps Universel Coordonné)를 조율함) 요소를 화면에 보여주는 데 사용되는 데이터를 담고 있다.
std::tm 실체는 단일 정적 실체라는 것을 눈여겨보라. localtime과 gmtime이 반환한 포인터들이 이 실체를 가리킨다. 이 함수들을 여러 쓰레드로부터 호출하려면 std::mutex로 보호해야 한다.
실제로 이 시간 요소들을 화면에 보여주는 것은 Type std::put_time(std::tm const *time, char const *fmt) 함수가 맡는다. 이 함수는 <iomanip> 헤더 파일에 정의되어 있다. 다음 단계를 거치면 std::tm 실체가 탄생하고 그의 주소를 put_time에 건넬 수 있다.
chrono::time_point 실체를 얻는다. 예를 들어 chrono::time_point<system_clock>::now() 정적 함수는 현재 지역 시간을 돌려준다. 이 time_point 실체는 지속시간을 빼거나 더해서 변경할 수 있다 (chrono::seconds 실체를 사용);
system_clock::to_time_t 정적 함수는 chrono::time_point를 기대하고 std::time_t 값을 돌려준다.
localtime이나 gmtime 함수는 time_t 값의 주소를 받는다. 그 반환 값은 std::tm *으로서 직접적으로 put_time에 건넬 수 있다.
std::put_time가 돌려주는 값은 지정되어 있지 않다. 그러나 std::ostream 실체에는 확실하게 삽입할 수 있다. char const *fmt 형식화 문자열은 텍스트는 물론이고 화면에 보여줄 시간의 요소를 선택하는 형식화 지정자도 담을 수 있다. put_time의 모든 형식 지정자는 다음 항에서 표에 다룬다.
다음 예제에 using namespace std가 선언되어 있지만 using namespace chrono는 선언되어 있지 않다. 어느 요소가 chrono 이름공간에 있는 것인지 명시적으로 나타내기 위해서이다. 실제로 using namespace chrono는 using namespace std 다음에 바로 선언되는 경우가 흔하다.
#include <iostream>
#include <chrono>
#include <iomanip>
using namespace std;
struct days: public chrono::hours
{
days(size_t count)
:
chrono::hours(count * 24)
{}
};
int main()
{
// 현재 시각을 얻는다.
chrono::time_point<chrono::system_clock>
timePoint{chrono::system_clock::now()};
// 현재 시각을 std::time_t로 변환한다.
time_t time = chrono::system_clock::to_time_t(timePoint);
// 그 시각을 기원 이후로 경과한 초의 갯수로 보여준다.
cout << time << '\n';
// std::tm value를 얻는다.
tm tmValue{*localtime(&time)};
// 그 시각을 보여준다.
cout << put_time(&tmValue, "current time: %c") << '\n';
// 그 시각을 rfc2822 형식으로 보여준다.
cout << put_time(&tmValue, "rfs2822 format: %a, %e %b %Y %T %z")
<< '\n';
// '시각'을 수정한다.
timePoint += days(7);
// 시각의 값을 std::time_t로 변환한다.
time = chrono::system_clock::to_time_t(timePoint);
// gmtime을 화면에 보여준다. 직접적으로 gmtime의 반환 값을 사용한다.
cout << put_time(gmtime(&time),
"gmtime, one week from now: %c %z") << '\n';
}
/* 출력 예:
1481452063
current time: Sun Dec 11 19:27:43 2016
rfs2822 format: Sun, 11 Dec 2016 19:27:43 +0900
gmtime, one week from now: Sun Dec 18 10:27:43 2016 +0000
*/
std::put_time 함수의 형식화 문자열에 사용할 수 있는 모든 형식 지정자를 담고 있다.
지정자는 %로 시작한다. 퍼센트 문자를 보여주려면 %%와 같이 두 번 쓰면 된다. 표준 피신 연속열 말고도 \n 대신에 %n을 사용할 수 있고 \t 대신에 %t를 사용할 수 있다.
| 년도 지정 | ||||
| 지정자 | 의미 | std::tm field(s) | ||
| %Y | 네 자리 십진수 년도 | tm_year | ||
| %EY | 다른 표현의 년도 | tm_year | ||
| %y | 마지막 2 자리는 십진수 년도임 (range [00,99]) | tm_year | ||
| %Oy | 보조 숫자 시스템을 사용하는 년도의 마지막 2 자리 | tm_year | ||
| %Ey | 로케일의 보조 달력 주기인 %EC (로케일-의존적)로부터 상대적 위치로 나타낸 년도 | tm_year | ||
| %C | 십진수로 된 앞의 두 자리 년도 (범위 [00,99]) | tm_year | ||
| %EC | 로케일의 보조 표현의 기본 연도의 이름(주기) | tm_year | ||
| %G | ISO 8601 주-기반의 년도. 즉, 지정된 주를 포함하는 년도 | tm_year, tm_wday, tm_yday | ||
| %g | ISO 8601 주-기반의 년도에서 뒤의 2 자리 (범위 [00,99]) | tm_year, tm_wday, tm_yday | ||
| 월 지정자 | ||||
| 지정자 | 의미 | std::tm 필드 | ||
| %b | 약칭 월 이름. 예를 들어 Oct | tm_mon | ||
| %h | 위와 동일 | tm_mon | ||
| %B | 월 이름. October | tm_mon | ||
| %m | 십진수 월 (범위 [01,12]) | tm_mon | ||
| %Om | 보조 숫자 시스템을 사용하는 월 | tm_mon | ||
| 주 지정자 | ||||
| 지정자 | 의미 | std::tm 필드 | ||
| %U | 십진수 년안의 주 번호 (일요일은 주의 첫 날이다) (범위 [00,53]) | tm_year, tm_wday, tm_yday | ||
| %OU | 년 안의 주 번호, %U와 같지만 보조 숫자 시스템을 사용한다 | tm_year, tm_wday, tm_yday | ||
| %W | 년의 십진수 주 번호 (월요일이 주의 첫 날이다) (범위 [00,53]) | tm_year, tm_wday, tm_yday | ||
| %OW | 년의 주 번호, %W와 같지만 보조 숫자 시스템을 사용한다 | tm_year, tm_wday, tm_yday | ||
| %V | 년도의 ISO 8601 주 번호 (범위 [01,53]) | tm_year, tm_wday, tm_yday | ||
| %OV | 년도의 주 번호, %V와 같지만 보조 숫자 시스템을 사용한다 | tm_year, tm_wday, tm_yday | ||
| 년도/월 지정자의 날짜 | ||||
| 지정자 | 의미 | std::tm 필드 | ||
| %j | 년 안의 십진수 날짜 (범위 [001,366]) | tm_yday | ||
| %d | 월 안의 십진수 날짜 (범위 [01,31]) | tm_mday | ||
| %Od | 0-기반의 월별 날짜. 보조 숫자 시스템 사용 | tm_mday | ||
| %e | 월별 십진수 날짜 (범위 [1,31]) | tm_mday | ||
| %Oe | 1-기반의 월별 날짜. 보조 숫자 시스템 사용 | tm_mday | ||
| 요일 지정자 | ||||
| 지정자 | 의미 | std::tm 필드 | ||
| %a | 요일 이름의 약칭, 예를 들어 Fri | tm_wday | ||
| %A | 요일 이름, 예를 들어 Friday | tm_wday | ||
| %w | 십진수 요일. 일요일은 0이다 (범위 [0-6]) | tm_wday | ||
| %Ow | 요일, 일요일은 0이다, 보조 숫자 시스템을 사용한다 | tm_wday | ||
| %u | 십진수 요일, 월요일은 1이다. (ISO 8601 형식) (범위 [1-7]) | tm_wday | ||
| %Ou | 요일, 일요일은 1이다. 보조 숫자 시스템을 사용한다 | tm_wday | ||
| 시, 분, 초 지정자 | ||||
| 지정자 | 의미 | std::tm 필드 | ||
| %H | 십진수 시, 24 시간제 (범위 [00-23]) | tm_hour | ||
| %OH | 보조 숫자 시스템을 사용하는 24 시간제 시 | tm_hour | ||
| %I | 십진수 시, 12 시간제 (범위 [01,12]) | tm_hour | ||
| %OI | 보조 숫자 시스템을 사용하는 12 시간제 시 | tm_hour | ||
| %M | 십진수 분 (범위 [00,59]) | tm_min | ||
| %OM | 보조 숫자 시스템을 사용하는 분 | tm_min | ||
| %S | 십진수 초 (범위 [00,60]) | tm_sec | ||
| %OS | 보조 숫자 시스템을 사용하는 초 | tm_sec | ||
| 추가 지정자 | ||||
| 지정자 | 의미 | std::tm 필드 | ||
| %c | 표준 날짜와 시간 문자열. 예를 들어, Sun Oct 17 04:41:13 2010 | 모든 필드 | ||
| %Ec | 보조 날짜와 시간 문자열 | 모든 필드 | ||
| %x | 지역화된 날짜 표현 | 모든 필드 | ||
| %Ex | 보조 날짜 표현 | 모든 필드 | ||
| %X | 지역화된 시간 표현 | 모든 필드 | ||
| %EX | 보조 시간 표현 | 모든 필드 | ||
| %D | "%m/%d/%y"와 동등 | tm_mon, tm_mday, tm_year | ||
| %F | "%Y-%m-%d"와 동등 (ISO 8601 날짜 형식) | tm_mon, tm_mday, tm_year | ||
| %r | 지역화된 12 시간제 | tm_hour, tm_min, tm_sec | ||
| %R | "%H:%M"와 동등 | tm_hour, tm_min | ||
| %T | "%H:%M:%S"와 동등 (ISO 8601 시간 형식) | tm_hour, tm_min, tm_sec | ||
| %p | 지역화된 a.m. 또는 p.m. | tm_hour | ||
| %z | UTC로부터의 상대 시간, ISO 8601 형식 (예를 들어 -0430; 시간대 정보가 없으면 문자 없음) | tm_isdst | ||
| %Z | 시간대 이름 또는 약자 (시간대 정보가 없으면 문자 없음) | tm_isdst | ||
멀티 쓰레드 프로그램을 만들기 위한 C++의 핵심 도구는 std::thread 클래스이다. 그 중에 몇몇 예제는 이미 이 장을 시작할 때 보여 주었다.
개별 쓰레드의 특징은 std::this_thread 이름공간에 질의할 수 있다. 또한, std::this_thread는 개별 스레드의 행위를 제어한다.
공유 데이터에 대한 접근을 동기화하기 위해 C++는 std::mutex로 구현한 상호배제(mutexes)와 std::condition_variable 클래스로 구현한 조건 변수를 제공한다.
낮은 수준의 에러 조건을 만나면 이 클래스의 멤버는 system_error 객체를 던질 수도 있다 (10.9절).
namespace std::this_thread는 현재 실행중인 쓰레드에 따로 연관된 함수들이 담겨 있다.
this_thread 이름공간을 사용하기 전에 <thread> 헤더를 포함해야 한다.
std::this_thread 이름공간 안에 여러 자유 함수가 정의되어 있다. 현재 쓰레드에 대한 정보를 제공하며 쓰레드의 행위를 제어하는 데 사용할 수 있다.
thread::id this_thread::get_id() noexcept:
현재 실행중인 쓰레드를 식별하는thread::id유형의 객체를 돌려준다. 활성 쓰레드에 대하여 반환된id는 유일하다. 현재 활성 쓰레드와 1:1로 짝지어져 있으면 다른 쓰레드는 반환하지 않는다는 점에서 유일하다. 쓰레드가 현재 실행중이 아니면std::thread객체의get_id멤버가thread::id()를 돌려준다.
void yield() noexcept:
쓰레드가 this_thread::yield()를 호출하면 현재 쓰레드는 잠깐 정지된다. 그래서 (대기 중인) 다른 쓰레드가 실행을 재개할 수 있다.
void sleep_for(chrono::duration<Rep, Period> const &relTime) noexcept:
쓰레드가this_thread::sleep_for(...)를 호출하면 인자에 지정한 시간 동안 정지된다. 예를 들어,std::this_thread::sleep_for(std::chrono::seconds(5));
void sleep_until(chrono::time_point<Clock, Duration> const &absTime) noexcept:
쓰레드가 이 멤버를 호출하면 지정된absTime시각에 다다를 때까지 정지된다. 다음 예제는 이전 예제와 효과가 같다.// 다음을 선언했다고 가정: using namespace std this_thread::sleep_until(chrono::system_clock().now() + chrono::seconds(5));대조적으로 다음 예제에서sleep_until호출은 즉시 반환된다.this_thread::sleep_until(chrono::system_clock().now() - chrono::seconds(5));
std::thread 클래스의 실체와 함께 시작한다. 이 클래스의 실체마다 따로따로 쓰레드를 처리한다.
쓰레드 객체를 사용하기 전에 <thread> 헤더를 포함해야 한다.
쓰레드 실체는 다양한 방식으로 생성할 수 있다.
thread() noexcept:
기본 생성자는 쓰레드 실체를 생성한다. 실행할 함수를 받지 않으므로 별도의 쓰레드를 실행하지 않는다. 예를 들어 클래스의 데이터 멤버로 사용된다면 클래스의 실체들은 시간이 지난 후 어느 시점에 각자의 쓰레드를 시작할 수 있다.
thread(thread &&tmp) noexcept:
이동 생성자는tmp가 통제하는 쓰레드의 소유권을 취한다. 반면에tmp는 쓰레드를 실행하고 있다면 제어권을 그의 쓰레드에게 넘겨 준다. 이 다음에tmp는 기본 상태가 된다. 그리고 새로 생성된 쓰레드는join을 호출할 책임을 진다.
explicit thread(Fun &&fun, Args &&...args):
이 멤버 템플릿은 함수나 함수객체를 첫 인자로 기대한다 (22.1.3항). 이 함수는 즉시 별도의 쓰레드로 실행된다. 그 함수나 함수객체가 인자를 기대하면 이 인자들을 첫 인자 바로 다음에 쓰레드의 생성자에 건넬 수 있다. 추가된 인자들은 적절한 유형과 값으로fun에 건네어진다. 쓰레드 실체가 생성된 다음, 별도로 쓰레드 실행이 시작된다.
Arg &&...args의 표기법은 함수에 인자들을 추가로 건넨다는 뜻이다. 쓰레드 생성자에 건네는 인자의 유형과 호출된 함수가 기대하는 유형이 서로 부합해야 한다. 값이면 같이 값이어야 하고 참조면 똑같이 참조여야 한다. 그리고 rvalue 참조라면 역시 rvalue 참조이어야 한다 (아니면 이동 생성을 지원해야 한다.). 다음 예제는 이 요구 조건을 보여준다.1: #include <iostream> 2: #include <thread> 3: 4: using namespace std; 5: 6: struct NoMove 7: { 8: NoMove() = default; 9: NoMove(NoMove &&tmp) = delete; 10: }; 11: 12: struct MoveOK 13: { 14: int d_value = 10; 15: 16: MoveOK() = default; 17: MoveOK(MoveOK const &) = default; 18: 19: MoveOK(MoveOK &&tmp) 20: { 21: d_value = 0; 22: cout << "MoveOK move cons.\n"; 23: } 24: }; 25: 26: void valueArg(int value) 27: {} 28: void refArg(int &ref) 29: {} 30: void r_refArg(int &&tmp) 31: { 32: tmp = 100; 33: } 34: void r_refNoMove(NoMove &&tmp) 35: {} 36: void r_refMoveOK(MoveOK &&tmp) 37: {} 38: 39: int main() 40: { 41: int value = 0; 42: 43: std::thread(valueArg, value).join(); 44: std::thread(refArg, ref(value)).join(); 45: std::thread(r_refArg, move(value)).join(); 46: 47: // std::thread(refArg, value); 48: 49: std::thread(r_refArg, value).join(); 50: cout << "value after r_refArg: " << value << '\n'; 51: 52: // std::thread(r_refNoMove, NoMove()); 53: 54: NoMove noMove; 55: // std::thread(r_refNoMove, noMove).join(); 56: 57: MoveOK moveOK; 58: std::thread(r_refMoveOK, moveOK).join(); 59: cout << moveOK.d_value << '\n'; 60: }
- 43번 줄과 45번 줄 사이에 값과 참조 그리고 rvalue 참조가
std::thread에 건네진다. 쓰레드들을 실행하는 함수들은 인자 유형이 부합하기를 기대한다.- 47번 줄에서 컴파일에 실패한다. 값 인자가
refArg가 기대하는 참조랑 일치하지 않기 때문이다. 이 문제는 43번 줄에서std::ref함수를 사용하면 해결된다.- 반면에 49번 줄과 58번 줄 사이는 컴파일에 성공한다.
int값 그리고 이동 연산을 지원하는 클래스-유형을 값으로 rvalue 참조를 기대하는 함수에 건넬 수 있기 때문이다. 이 경우 rvalue 참조를 기대하는 함수는 (이동 생성으로 수행된 조치는 제외하고) 제공된 인자에 접근하지 않는다는 것을 주의하라. 오히려 함수가 작동해야 할 임시 값이나 실체를 이동 생성한다.- 52번 줄과 55번 줄 사이는 컴파일되지 않는다.
NoMove구조체에 이동 생성자가 없기 때문이다.지역 변수를 인자로 쓰레드 실체에 건넬 때 조심하라: 지역 변수가 사용된 함수가 종료해도 쓰레드가 계속 실행되면 그 쓰레드는 갑자기 허상 포인터 또는 허상 참조를 사용하게 되어 버린다. 지역 변수가 더 이상 존재하지 않기 때문이다. 이런 일이 일어나지 않도록 방지하려면 다음 예제와 같이 하라:
- 지역 변수의 익명의 사본을 인자로 쓰레드에 건네거나 아니면
- 쓰레드 실체에
join을 호출하여 그 쓰레드가 지역 변수의 생애 안에서 확실하게 끝나도록 확인하라.1: #include <iostream> 2: #include <thread> 3: #include <string> 4: #include <chrono> 5: 6: void threadFun(std::string const &text) 7: { 8: for (size_t iter = 1; iter != 6; ++iter) 9: { 10: std::cout << text << '\n'; 11: std::this_thread::sleep_for(std::chrono::seconds(1)); 12: } 13: } 14: 15: std::thread safeLocal() 16: { 17: std::string text = "hello world"; 18: return std::thread(threadFun, std::string(text)); 19: } 20: 21: int main() 22: { 23: std::thread local(safeLocal()); 24: std::cout << "safeLocal has ended\n"; 25: local.join(); 26: }18번 줄에서
std::ref(text)를 호출하지 않도록 주의하라.std::string(text)을 호출해야 한다.쓰레드를 생성할 수 없으면
std::system_error예외가 던져진다.이 생성자는 첫 인자로 함수는 물론이고 함수객체에도 접근하기 때문에 지역 문맥을 함수객체의 생성자에 건넬 수 있다. 다음은 지역 문맥을 사용하는 함수객체를 받는 쓰레드의 예이다.
#include <iostream> #include <thread> #include <array> using namespace std; class Functor { array<int, 30> &d_data; int d_value; public: Functor(array<int, 30> &data, int value) : d_data(data), d_value(value) {} void operator()(ostream &out) { for (auto &value: d_data) { value = d_value++; out << value << ' '; } out << '\n'; } }; int main() { array<int, 30> data; Functor functor(data, 5); thread funThread(functor, ref(cout)); funThread.join(); };
std::thread 클래스는 복사 생성자가 없다.
다음 멤버를 사용할 수 있다.
thread &operator=(thread &&tmp) noexcept:
왼쪽 피연산자(lhs)가 부착이 가능한 쓰레드라면terminate가 호출된다. 그렇지 않으면tmp는 왼쪽 피연산자(lhs)에 할당되고tmp의 상태는 쓰레드의 기본 상태로 변한다 (즉,thread()).
void detach():
true를 돌려주기 위해joinable을 요구한다 (아래 참고).detach가 호출된 쓰레드는 실행을 계속한다.detach를 호출한 (부모) 쓰레드는detach를 호출한 후에도 실행을 계속한다.object.detach()를 호출하고 나면 `object'는 더 이상 실행 쓰레드를 대표하지 않는다. 여전히 실행은 되더라도 이제는 분리되어 있다. 실행이 끝나면 분리된 쓰레드는 자원을 해제하는 것을 구현할 책임이 있다.
detach는 실행 프로그램으로부터 쓰레드를 분리하기 때문에main은 쓰레드의 완료를 더 이상 기다릴 수 없다.main이 끝나 프로그램이 끝나면 여전히 실행중인 분배된 쓰레드도 역시 멈춘다. 다음 예제에 보듯이 프로그램은 자신의 모든 쓰레드를 적절하게 끝낼 수 없다.#include <thread> #include <iostream> #include <chrono> void fun(size_t count, char const *txt) { for (; count--; ) { std::this_thread::sleep_for(std::chrono::milliseconds(100)); std::cout << count << ": " << txt << std::endl; } } int main() { std::thread first(fun, 5, "hello world"); first.detach(); std::thread second(fun, 5, "a second thread"); second.detach(); std::this_thread::sleep_for(std::chrono::milliseconds(400)); std::cout << "leaving" << std::endl; } /* 출력 예 4: hello world 4: a second thread 3: hello world 3: a second thread 2: hello world 2: a second thread leaving 1: hello world */쓰레드를 분리한 함수가 끝난 후에도 분리된 쓰레드는 실행을 계속할 수도 있다. 여기에서도 역시 지역 변수를 분리된 쓰레드에 건네지 않도록 주의해야 한다. 지역 변수를 정의한 함수가 종료하는 순간, 참조나 포인터가 미정의 상태가 되어 버리기 때문이다.
#include <iostream> #include <thread> #include <chrono> using namespace std; using namespace chrono; void add(int const &p1, int const &p2) { this_thread::sleep_for(milliseconds(200)); cerr << p1 << " + " << p2 << " = " << (p1 + p2) << '\n'; } void run() { int v1 = 10; int v2 = 20; // thread(add, ref(v1), ref(v2)).detach(); // 절대로 이렇게 하면 안됨 thread(add, int(v1), int(v2)).detach(); // 이것은 괜찮다. 따로 사본이 있다. } void oops() { int v1 = 0; int v2 = 0; } int main() { run(); oops(); this_thread::sleep_for(seconds(1)); }
id get_id() const noexcept:
현재 실체가 실행 쓰레드를 대표하지 않으면thread::id()가 반환된다. 그렇지 않으면 그 쓰레드의 유일한 ID가 반환된다.this_thread::get_id()으로 얻은 쓰레드로 얻을 수도 있다.
void join():
true를 돌려주기 위해joinable을 요구한다.join을 호출한 쓰레드가 완료될 때까지 정지된다. 완료한 후join멤버가 호출된 그 실체는 더 이상 실행 쓰레드를 대표하지 않는다. 그의get_id멤버는std::thread::id()를 돌려줄 것이다.이 멤버는 지금까지 여러 예제에 사용되었다. 지적했듯이
main이 끝날 때 여전히 부착이 가능한 쓰레드가 실행중이면terminate가 호출되어 프로그램을 끝낸다.
bool joinable() const noexcept:
object.get_id() != id()를 돌려준다.object는joinable멤버가 호출된 쓰레드 실체이다.
void swap(thread &other) noexcept:
swap이 호출된 쓰레드 실체의 상태와other쓰레드의 상태를 서로 교환한다. 이 쓰레드들은 언제나 교환할 수 있음에 주의하라. 심지어 쓰레드 함수들이 현재 실행 중일지라도 교환할 수 있다.
unsigned thread::hardware_concurrency() noexecpt:
이 정적 멤버는 현재 컴퓨터에서 동시에 실행할 수 있는 쓰레드의 갯수를 돌려준다. 독립적 멀티-코어 컴퓨터라면 (아마도) 코어의 갯수를 돌려줄 것이다.
다음은 눈여겨볼 것들이다.
join을 호출하지 않는 한, 익명 쓰레드는 실행되지 않는다. 예를 들어,
void doSomething();
int main()
{
thread(doSomething); // 아무 일도 일어나지 않는가??
thread(doSomething).join() // doSomething은 실행되었는가??
}
이 비슷한 상황을 7.5절에서도 만나 보았다. 첫 번째 서술문은 익명의 쓰레드 실체를 전혀 정의하지 않는다. 그냥 쓰레드 실체를 doSomething으로 정의했을 뿐이다. 결론적으로 두 번째 서술문은 컴파일에 실패한다. thread(thread &) 생성자가 없기 때문이다. 첫 번째 서술문을 생략하면 doSomething 함수는 두 번째 서술문에서 실행된다. 두 번째 서술문을 생략하면 기본 생성된 쓰레드 실체가 doSomething의 이름으로 정의된다.
thread object(thread(doSomething));
이동 생성자는 doSomething을 실행하는 익명의 쓰레드로부터 object 쓰레드로 제어를 이전한다. object의 생성이 완료된 후에야 비로서 doSomething이 별도의 쓰레드에서 시작된다.
packaged_task와 future를 사용하여 시작 쓰레드에 건넬 수 있다 (각각 20.12절과 20.9절 참고).
쓰레드는 자신을 실행한 함수가 끝날 때 같이 종료한다. 쓰레드 실체가 파괴될 때 그의 쓰레드 함수가 여전히 실행중이면 terminate가 호출되어 프로그램을 끝낸다. 나쁜 소식이 있다. 기존 실체의 소멸자는 호출되지 않는다. 던져진 예외는 잡히지 않는다. 이런 일이 다음 프로그램에서 일어난다. main이 끝났는데도 쓰레드가 여전히 살아 있음을 눈여겨보자:
#include <iostream>
#include <thread>
void hello()
{
while (true)
std::cout << "hello world!\n";
}
int main()
{
std::thread hi(hello);
}
이 문제를 해결하는 여러가지 방법이 있다. 그 중에 하나를 다음 목에 연구한다.
이 간접적 데이터 레벨을 thread_local 키워드가 제공한다. thread_local로 정의된 전역 변수는 각 쓰레드 안에서 전역적이다. 각 쓰레드마다 thread_local 변수의 사본을 소유한다. 그리고 마음대로 그 사본을 바꿀 수 있다. 한 쓰레드 안의 thread_local 변수는 또다른 쓰레드 안의 그 변수와 완전히 격리된다. 다음은 한 예이다.
1: #include <iostream>
2: #include <thread>
3:
4: using namespace std;
5:
6: thread_local int t_value = 100;
7:
8: void modify(char const *label, int newValue)
9: {
10: cout << label << " before: " << t_value << ". Address: " <<
11: &t_value << endl;
12: t_value = newValue;
13: cout << label << " after: " << t_value << endl;
14: }
15:
16: int main()
17: {
18: thread(modify, "first", 50).join();
19: thread(modify, "second", 20).join();
20: modify("main", 0);
21: }
thread_local 변수 t_value가 정의된다. 100으로 초기화되고 각각의 실행 쓰레드마다 초기 값이 된다.
modify 함수가 정의된다. 새 값을 t_value에 할당한다.
modify를 호출한다.
이 프로그램을 실행하면 각 쓰레드마다 t_value를 100부터 시작하고 다음에 그 값을 변경한다. 다른 쓰레드가 사용하는 t_value 값에 영향을 주지 않는다.
t_value는 각 쓰레드마다 유일하지만 그 중에 주소가 동일하게 보일 수도 있다는 것을 눈여겨보라. 각 쓰레드마다 자신만의 스택을 사용하기 때문에 이 변수들은 각각의 스택 안에서 같은 상대 위치를 점유할 수 있다. 그 때문에 물리적 주소가 동일한 듯한 오해를 불러 일으킨다.
void childActions();
void doSomeWork();
void parent()
{
thread child(childActions);
doSomeWork();
child.join();
}
그렇지만 doSomeWork이 자신의 일을 완수하지 못할 수 있다. 그리고 예외를 던져서 부모(parent) 밖에서 잡도록 할 수 있다. 불행하게도 이 때문에 parent가 끝나버리고 child.join()은 갈 곳을 잃어 버린다. 결과적으로 프로그램은 부착되지 못한 쓰레드 때문에 종료되어 버린다.
분명한 것은 모든 예외를 잡아야 하고 join을 반드시 호출해야 하며 그리고 그 예외는 되던져야 한다는 것이다. 그러나 parent는 함수를 try-블록으로 사용할 수 없다. 짝이 되는 catch-절에 실행이 도달할 쯤이면 쓰레드 객체가 이미 영역을 벗어났기 때문이다. 그래서 다음과 같이 하면:
void childActions();
void doSomeWork();
void parent()
{
thread child(childActions);
try
{
doSomeWork();
child.join();
}
catch (...)
{
child.join();
throw;
}
}
보기에 안 좋다. 갑자기 함수가 try-catch 절로 한가득이다. 게다가 코드-중복도 다음에 안 든다.
이 상황은 객체 기반의 프로그래밍을 사용하면 피할 수 있다. 예를 들어 소멸자를 사용하여 동적으로 할당된 메모리의 파괴를 캡슐화하는 유일한 포인터처럼, 그 비슷한 테크닉을 사용하여 쓰레드의 부착 책임을 객체의 소멸자에 캡슐화해 넣을 수 있다.
쓰레드 객체를 클래스 안에 캡슐화해 넣으면 그 객체가 영역을 벗어날 즈음이면 childActions 함수가 예외를 던질지라도 쓰레드의 join 멤버가 호출된다는 것을 알 수 있다. 다음은 핵심만 구현한 JoinGuard 클래스이다. 부착-보장을 제공한다 (간결하게 인라인 멤버로 구현함):
1: #include <thread>
2:
3: class JoinGuard
4: {
5: std::thread d_thread;
6:
7: public:
8: JoinGuard(std::thread &&threadObj)
9: :
10: d_thread(std::move(threadObj))
11: {}
12: ~JoinGuard()
13: {
14: if (d_thread.joinable())
15: d_thread.join();
16: }
17: };
JoinGuard 클래스의 d_thread 데이터 멤버로 이동한다.
JoinGuard 실체가 존재하기를 멈출 때 생성자는 여전히 부착이 가능하면 (줄 14와 15) 쓰레드가 부착되어 있는지 확인한다 (줄 12).
JoinGuard 클래스를 사용하는 방법이다.
1: #include <iostream>
2: #include "joinguard.h"
3:
4: void childActions();
5:
6: void doSomeWork()
7: {
8: throw std::runtime_error("doSomeWork throws");
9: }
10:
11: void parent()
12: {
13: JoinGuard{std::thread{childActions}};
14: doSomeWork();
15: }
16:
17: int main()
18: try
19: {
20: parent();
21: }
22: catch (std::exception const &exc)
23: {
24: std::cout << exc.what() << '\n';
25: }
childActions가 선언된다. 그의 구현은 자손 쓰레드의 행위를 정의한다 (여기에서는 제공하지 않음).
main 함수는 (줄 17부터 25까지) parent가 던진 예외를 잡기 위하여 함수 try-블록을 제공한다.
parent 함수는 익명의 JoinGuard 실체를 생성한다 (줄 13). 이 실체는 익명의 쓰레드 실체를 받는다. 익명 객체가 사용된다. 부모 함수에 더 이상 접근할 필요가 없기 때문이다.
doSomeWork이 호출된다. 이 때문에 예외가 던져지고 parent가 끝나지만 그 바로 전 JoinGuard의 소멸자 덕분에 자손-쓰레드가 이미 부착된 것을 확신할 수 있다.
상호배제를 사용하기 전에 <mutex> 헤더를 포함해야 한다.
멀티 쓰레드 프로그램의 핵심적 특징 중 하나는 쓰레드가 데이터를 공유할 수 있다는 것이다. 별도의 쓰레드로 실행되는 함수들은 모든 전역 변수에 접근한다. 그리고 부모 쓰레드의 지역 데이터도 공유할 수있다. 그렇지만 적절하게 조치하지 않으면 이 때문에 쉽게 데이터 부패가 일어날 수 있다. 다음에 멀티 쓰레드 프로그램에서 만날 수 있는 여러 단계를 따라가 보자:
---------------------------------------------------------------------------
Time step: Thread 1: var Thread 2: 설명
---------------------------------------------------------------------------
0 5
1 starts T1 활성화
2 writes var T1 쓰기 시작
3 stopped 문맥 전환
4 starts T2 활성화
5 writes var T2 쓰기 시작
6 10 assigns 10 T2 10을 쓴다.
7 stopped 문맥 전환
8 assigns 12 T1 12를 쓴다.
9 12
----------------------------------------------------------------------------
이 예제에서 쓰레드 1과 쓰레드 2는 var 변수를 공유한다. 처음에는 값이 5이다. 1 단계에서 쓰레드 1이 시작된다. 그리고 값을 var에 쓰기 시작한다. 그렇지만 문맥 전환에 의해서 인터럽트된다. 그리고 쓰레드 2가 (4단계에서) 시작되었다. 쓰레드 2도 역시 값을 var에 쓰고 싶어 하고 7단계에 다다르면 성공한다. 이 때 또다른 문맥 전환이 일어나기 때문이다. 이제 var는 10이다. 그렇지만 쓰레드 1도 값을 var에 쓰는 중에 있었고 그 일을 완료할 기회를 주었다. 8단계에 이르면 12를 var에 할당한다. 9 단계에 도달하면 쓰레드 2는 var가 분명히 10일 것이라는 (잘못된) 가정하에 진행을 계속한다. 확실히 쓰레드 2의 관점에서 그 데이터는 부패한 셈이다.
위에서 데이터가 훼손된 것은 여러 쓰레드가 같은 데이터에 아무 통제없이 접근했기 때문이다. 이를 방지하기 위하여 공유 데이터에 대한 접근은 한 번에 한 쓰레드만 접근하도록 보호해야 한다.
상호배제(Mutexes)를 사용하면 데이터에 제한없이 접근하는 문제를 방지할 수 있다. 상호배제를 잠글 수 있는 쓰레드만 데이터에 접근한다는 것을 보장한다. 상호배제는 데이터 접근을 동기화하는 데 사용된다.
독점적으로 데이터에 접근하는 것은 온전히 쓰레드 사이의 협력에 달려 있다. 쓰레드 1은 상호배제를 사용하지만 쓰레드 2는 그렇지 않다면 쓰레드 2는 자유롭게 그 데이터에 접근할지도 모른다. 물론 그것은 나쁜 관행이다. 반드시 피해야 한다.
상호배제를 사용하는 것은 프로그래머의 책임이지만 그의 구현은 프로그래머의 책임이 아니다. 상호배제는 필요한 원자 호출을 제공한다. 상호배제-잠금을 요청할 때 요청 쓰레드가 잠금을 획득할 때까지 쓰레드는 정지된다. 즉, mutex 서술문은 반환되지 않는다.
std::mutex 클래스 말고도 std::recursive_mutex 클래스를 사용할 수 있다. 같은 쓰레드에서 recursive_mutex을 여러 번 호출하면 잠금-횟수가 증가한다. 다른 쓰레드들이 그 보호 데이터에 접근하기 전에 재귀적 상호배제는 다시 잠긴 그만큼 풀어 주어야 한다. 그리고 std::timed_mutex 클래스와 std::recursive_timed_mutex 클래스를 사용할 수 있다. 이 형태의 잠금은 풀어질 때 만료할 뿐만 아니라 일정 시간이 지난 후에도 만료한다.
mutex 클래스의 멤버는 원자 행위를 수행한다. 원자 행위 중에는 문맥 전환이 일어나지 않는다. 그래서 두 쓰레드가 상호배제를 잠그려고 시도하면 하나의 쓰레드만 성공할 수 있다. 위의 예제에서 두 쓰레드가 모두 상호배제를 사용하여 var에 접근을 제어하려고 하면 쓰레드 2는 12를 var에 할당할 수 없을 것이다. 쓰레드 1이 그 값은 10이라고 간주하기 때문이다. 심지어 두 개의 쓰레드를 순수하게 병행적으로 (두 개의 별도 코어에서) 실행할 수도 있다.
-------------------------------------------------------------------------
Time step: Thread 1: Thread 2: 설명
-------------------------------------------------------------------------
1 starts starts T1과 T2 활성화
2 locks locks 두 쓰레드 모두
상호배제(mutex)를 시도
3 blocks... obtains lock T2 잠금 획득,
그러므로 T1 대기
4 (blocked) processes var T2 var를 처리,
T1 여전히 정지 상태
5 obtains lock releases lock T2 잠금 해제,
그러므로 T1 즉시
잠금 획득
6 processes var 이제 T1 var 처리
7 releases lock T1도 잠금 해제
-------------------------------------------------------------------------
상호배제는 프로그램에 직접적으로 사용할 수 있지만 이것은 자주 일어나는 일은 아니다. 보통은 상호배제 처리를 잠금 클래스 안에 싸 넣어 사용한다. 그래야 상호배제 잠금이 더 이상 필요하지 않을 때 자동으로 다시 상호배제가 풀리는 것을 확신할 수 있다. 그러므로 이 절은 그냥 상호배제 클래스의 인터페이스만 개관한다. 사용 예제는 다음 20.4절에 보여 드리겠다.
모든 상호배제 클래스는 다음 생성자와 멤버를 제공한다.
mutex() constexpr:
기본 constexpr 생성자가 유일하게 사용할 수 있는 생성자이다.
~mutex():
소멸자는 잠긴 상호배제를 풀어주지 않는다. 잠겨 있으면 명시적으로 unlock 멤버를 사용하여 풀어 주어야 한다.
void lock():
호출 쓰레드는 상호배제를 획득할 때까지 정지된다. 재귀적 상호배제에 대하여 lock을 호출하지 않는 한, 쓰레드가 이미 잠금을 소유하고 있으면 system_error가 던져진다. 재귀적 상호배제는 내부 잠금 횟수를 증가시킨다.
bool try_lock() noexcept:
호출 쓰레드는 상호배제의 소유권을 얻으려고 시도한다. 소유권을 획득하면true가 반환된다. 그렇지 않으면false가 반환된다. 호출 쓰레드가 이미 잠금을 소유하고 있으면 역시true가 반환된다. 그리고 이 경우 재귀적 상호배제도 자신의 내부 잠금 횟수를 증가시킨다.
void unlock() noexcept:
호출 쓰레드가 상호배제의 소유권을 풀어준다. 그 쓰레드가 잠금을 소유하고 있지 않으면 system_error가 던져진다. 재귀적 상호배제는 내부 잠금 횟수를 증가시키고 잠금 횟수가 0으로 줄어들면 소유권을 해제한다.
시간 제한 상호배제 클래스도 (timed_mutex, recursive_timed_mutex) 다음 멤버를 제공한다.
bool try_lock_for(chrono::duration<Rep, Period> const
&relTime) noexcept:호출 쓰레드는 지정된 시간 동안 상호배제의 소유권을 얻으려고 시도한다. 소유권을 얻으면true를 돌려준다. 그렇지 않으면false를 돌려준다. 호출 쓰레드가 이미 잠금을 소유하고 있으면true가 반환된다. 이 경우 재귀적 상호배제도 내부 잠금 횟수를 증가시킨다.Rep와Duration유형은 실제relTime인자로부터 추론한다. 예를 들어,std::timed_mutex timedMutex; timedMutex.try_lock_for(chrono::seconds(5));
bool try_lock_until(chrono::time_point<Clock, Duration> const &absTime) noexcept:
호출 쓰레드는absTime시각에 이를 때까지 상호배제의 소유권을 얻으려고 시도한다. 소유권을 얻으면true를 돌려준다. 그렇지 않으면false를 돌려준다. 호출 쓰레드가 이미 잠금을 소유하고 있으면 역시true를 돌려준다. 이 경우 재귀적 시간 제한 상호배제도 자신의 내부 잠금 횟수를 증가시킨다.Clock과Duration유형은 실제absTime인자로부터 추론한다. 예를 들어,std::timed_mutex timedMutex; timedMutex.try_lock_until(chrono::system_clock::now() + chrono::seconds(5));
std::once_flag와 std::call_once 함수를 사용하려면 먼저 <mutex> 헤더를 포함해야 한다.
단일 쓰레드 프로그램에서 전역 데이터의 초기화가 반드시 같은 곳에서 일어나는 것은 아니다. 싱글턴 클래스 객체의 초기화가 한 예이다 (참고 Gamma et al. (1995), Design Patterns, Addison-Wesley). 싱글턴 클래스는 한 개의 Singleton *s_object 정적 포인터 멤버를 정의할 수 있다. 이 포인터는 싱글턴 객체를 가리킨다. 그리고 instance 정적 멤버를 제공할 수 있다. 그러면 다음과 같이 구현된다.
Singleton &Singleton::instance()
{
return s_object ?
s_object
:
(s_object = new Singleton);
}
다중-쓰레드 프로그램에서 이 접근법은 얼마 못 가 복잡해진다. 예를 들어, 두 개의 쓰레드가 동시에 instance를 호출하고, 한편 s_object는 여전히 0이면 두 쓰레드는 new Singleton을 호출하게 되고 결과적으로 동적으로 할당된 하나의 Singleton 실체에 접근이 불가능해진다. 처음으로 s_object가 초기화된 후 호출되면 다른 쓰레드는 그 실체를 참조로 돌려주거나 아니면 두 번째 쓰레드로 초기화된 실체를 참조로 돌려준다. 이것은 싱글턴 객체에게 기대하는 행위에 어긋난다.
이런 종류의 문제는 상호배제가 해결해 줄 수 있다 (20.3절). 그러나 약간의 부담과 비효율성이 있다. 상호배제는 Singleton::instance를 호출할 때마다 내부를 들여야 보아야 하기 때문이다.
변수가 동적으로 초기화되어야 한다면 그리고 그 초기화는 한 번만 일어나야 한다면 std::once_flag 유형과 std::call_once 함수를 사용해야 한다.
call_once 함수는 두 개 또는 세 개의 인자를 기대한다.
once_flag 변수로서 실제 초기 상태를 추적 관리한다. call_once 함수는 once_flag가 초기화가 이미 일어났다고 가리키면 그냥 돌아온다.
call_once의 세 번째 인자로 제공해야 한다.
싱글턴의 instance 함수를 쓰레드에 안전하게 구현하는 것은 이제 쉽게 설계할 수 있다 (간결하게 클래스 안에 구현함):
class Singleton
{
static std::once_flag s_once;
static Singleton *s_singleton;
...
public:
static Singleton *instance()
{
std::call_once(s_once, []{s_singleton = new Singleton;} );
return s_singleton;
}
...
};
그렇지만 심지어 멀티-쓰레드 프로그램에 대해서조차 데이터를 초기화하는 방법이 더 있다.
constexpr 키워드로 선언되어 있다고 가정하자 (8.1.4.1목). 상수 초기화의 요구 조건을 만족한다. 이 경우, 이 생성자를 이용하여 초기화한 정적 객체는 정적 초기화 과정으로 어떤 코드도 실행되기 전에 먼저 초기화되는 것을 보장한다. 이것은 std::mutex에서 사용한다. 전역 상호배제를 초기화할 때 경쟁 조건의 가능성을 제거하기 때문이다.
#include <iostream>
struct Cons
{
Cons()
{
std::cout << "Cons called\n";
}
};
void called(char const *time)
{
std::cout << time << "time called() activated\n";
static Cons cons;
}
int main()
{
std::cout << "Pre-1\n";
called("first");
called("second");
std::cout << "Pre-2\n";
Cons cons;
}
/*
출력:
Pre-1
firsttime called() activated
Cons called
secondtime called() activated
Pre-2
Cons called
*/
이 특징은 또다른 쓰레드가 여전히 그 정적 데이터를 초기화하고 있다면 쓰레드를 자동으로 기다리도록 만든다. 비-정적 데이터는 문제를 일으키지 않는다. 비-정적 지역 변수들은 쓰레드가 실행되는 문맥 안에서만 존재하기 때문이다.
std::shared_mutex 유형을 정의한다. <shared_mutex> 헤더를 포함하면 사용할 수 있다.
std::shared_mutex는 공유 상호배제 유형이다. 이 유형은 timed_mutex 유형처럼 행위하며 선택적으로 아래에 기술하는 특징이 있다.
shared_mutex 클래스는 비-재귀적 상호배제를 제공한다. 소유권을 공유하는 의미구조가 shared_ptr 유형과 비슷하다. shared_mutex를 사용하는 프로그램은 다음과 같은 경우에 정의되어 있지 않다.
shared_mutex 객체를 파괴해 버릴 경우;
shared_mutex의 소유권을 획득하려고 시도할 경우;
shared_mutex를 소유하고 있는 쓰레드가 종료해 버릴 경우.
공유 상호배제 유형은 공유 잠금 소유권 모드를 제공한다. 여러 쓰레드가 동시에 shared_mutex 유형의 객체의 공유 잠금 소유권을 확보할 수 있다. 그러나 동일한 shared_mutex 객체에 대하여 또다른 쓰레드가 배타적인 잠금을 보유하고 있는 동안에는 어떤 쓰레드도 공유 잠금을 가질 수 없다. 그 반대의 경우도 마찬가지다.
shared_mutex 유형은 다음 멤버를 제공한다.
void lock_shared():
상호배제의 공유 소유권을 호출 쓰레드가 획득할 때까지 호출 쓰레드를 정지시킨다. 현재 쓰레드가 이미 잠금을 소유하고 있거나 상호배제를 잠그도록 허용하지 않거나 또는 상호배제가 이미 잠겨 있고 블로킹이 불가능하면 예외가 던져진다.
void unlock_shared():
호출 쓰레드가 보유한 상호배제에 대한 공유 잠금을 해제한다. 현재 쓰레드가 아직 잠금을 소유하고 있지 않으면 아무 일도 일어나지 않는다.
bool try_lock_shared():
현재 쓰레드는 블로킹 없이 상호배제의 공유 소유권을 획득하려고 시도한다. 공유 소유권이 없으면 아무 효과도 없고try_lock_shared는 즉시 반환된다. 공유 소유권 잠금을 얻었으면true를 돌려주고 그렇지 않으면false를 돌려준다. 구현은 잠금 획득에 실패할 수도 있다. 다른 쓰레드가 전혀 소유하고 있지 않아도 말이다. 맨 처음의 호출 쓰레드는 아직 상호배제를 소유하지 못할 수 있다.
bool try_lock_shared_for(rel_time):
rel_time으로 지정된 상대 시간 안에 호출 쓰레드에 대해서 공유 잠금 소유권을 얻으려고 시도한다.rel_time에 지정된 시간이rel_time.zero()이하이면 블로킹 없이 소유권을 얻으려고 시도한다. 마치try_lock_shared()를 호출한 것과 같다. 지정된 시간 안에 상호배제 객체의 공유 소유권을 획득한 경우에만 돌아올 것이다. 공유 소유권 잠금을 얻으면true를 돌려주고 그렇지 않으면false를 돌려준다. 처음에 호출 쓰레드는 상호배제를 소유하지 못할 수도 있다.
bool try_lock_shared_until(abs_time):
abs_time시간 동안 호출 쓰레드에 대하여 공유 잠금 소유권을 얻으려고 시도한다. 지정된abs_time시간이 이미 경과했으면 블로킹 없이 소유권을 획득하려고 시도한다. 마치try_lock_shared()를 호출한 것과 같다. 공유 소유권 잠금을 얻으면true를 돌려준다. 그렇지 않으면false를 돌려준다. 맨 처음 호출 쓰레드는 아직 상호배제를 소유하지 못할 수도 있다.
<mutex> 헤더를 포함해야 한다.
쓰레드가 데이터를 공유할 때마다 그리고 하나의 쓰레드라도 그 데이터를 변경하려고 할 때마다 상호배제를 사용하여 쓰레드가 같은 데이터를 동기적으로 사용하지 못하도록 막아야 한다.
잠금은 보통 조치가 끝날 때 해제된다. 명시적으로 unlock 함수를 호출하기를 요구한다. 때문에 이전에 join 멤버에서 보았던 문제와 비슷한 문제가 초래된다.
잠금과 풀기를 간단하게 하기 위하여 두 개의 상호배제 포장 클래스를 사용할 수 있다.
std::lock_guard:
이 클래스의 객체는 기본적인 풀기-보장을 제공한다. 소멸자는 상호배제의 unlock 멤버를 호출한다.
std::unique_lock:
이 클래스의 객체는 더 넓은 인터페이스를 제공한다. 명시적으로 상호배제를 풀고 잠글 수 있다. 소멸자는 lock_guard가 제공하는 풀기-보장을 그대로 유지한다.
lock_guard 클래스는 제한적이지만 유용한 인터페이스를 제공한다.
lock_guard<Mutex>(Mutex &mutex):
lock_guard객체를 정의할 때 상호배제 유형이 지정된다 (예를 들어,std::mutex, std::timed_mutex, std::shared_mutex). 그리고 지시된 유형의 상호배제가 인자로 제공된다.lock_guard객체가 잠금을 소유할 때까지 생성은 정지된다.lock_guard의 소멸자는 자동으로 상호배제 잠금을 풀어준다.
lock_guard<Mutex>(Mutex &mutex, std::adopt_lock_t):
이 생성자는 상호배제의 제어를 호출 쓰레드로부터lock_guard로 이전한다. 상호배제 잠금은 다시lock_guard소멸자에 의하여 해제된다. 생성 시간에 상호배제는 이미 호출 쓰레드가 소유하고 있어야 한다. 다음은 사용하는 방법을 보여준다.1: void threadAction(std::mutex &mut, int &sharedInt) 2: { 3: std::lock_guard<std::mutex> lg{mut, std::adopt_lock_t()}; 4: // sharedInt를 가지고 일을 한다. 5: }
- 줄 1에서
threadAction은 상호배제를 참조로 받는다. 상호배제가 잠금을 소유하고 있다고 간주한다.- 줄 3에서 제어는
lock_guard로 이전된다. 명시적으로lock_guard객체를 사용하고 있지는 않지만 객체는 함수가 끝나기 전에 컴파일러가 익명의 객체를 파괴하지 못하도록 정의되어야 한다.- 함수가 끝나면 줄 5에서
lock_guard의 소멸자가 상호배제의 잠금을 풀어준다.
mutex_type:
생성자와 소멸자 외에도,lock_guard<Mutex>유형은mutex_type유형도 정의한다.lock_guard의 생성자에 건네는Mutex유형의 동의어이다.
다음은 멀티 쓰레드 프로그램의 간단한 예이다. lock_guard를 사용하면 cout에 삽입되는 정보가 섞이지 않도록 방지된다.
bool oneLine(istream &in, mutex &mut, int nr)
{
lock_guard<mutex> lg(mut);
string line;
if (not getline(in, line))
return false;
cout << nr << ": " << line << endl;
return true;
}
void io(istream &in, mutex &mut, int nr)
{
while (oneLine(in, mut, nr))
this_thread::yield();
}
int main(int argc, char **argv)
{
ifstream in(argv[1]);
mutex ioMutex;
thread t1(io, ref(in), ref(ioMutex), 1);
thread t2(io, ref(in), ref(ioMutex), 2);
thread t3(io, ref(in), ref(ioMutex), 3);
t1.join();
t2.join();
t3.join();
}
lock_guard와 마찬가지로 std::unique_lock 클래스의 실체를 정의할 때 상호배제-유형을 지정해야 한다. unique_lock 클래스는 기본적인 lock_guard 클래스 템플릿보다 훨씬 더 정교하다. 인터페이스에 복사 생성자나 중복정의 할당 연산자는 정의되어 있지 않지만 이동 생성자와 이동 할당 생성자는 정의되어 있다. 다음 unique_lock의 인터페이스 개관에서 Mutex는 unique_lock을 정의할 때 지정되는 상호배제-유형을 참조한다.
unique_lock() noexcept:
기본 생성자는 아직mutex실체에 연관되어 있지 않다. 먼저mutex를 할당해야 (이동-할당 사용) 무엇이든 유용한 일을 할 수 있다.
explicit unique_lock(Mutex &mutex):
기존의Mutex객체로unique_lock를 초기화한다. 그리고mutex.lock()를 호출한다.
unique_lock(Mutex &mutex, defer_lock_t) noexcept:
그러나mutex.lock()를 호출하지 않는다.defer_lock_t객체를 생성자의 두 번째 인자로 건네어 직접 호출하라. 예를 들어,unique_lock<mutex> ul(mutexObj, defer_lock_t())
unique_lock(Mutex &mutex, try_to_lock_t) noexcept:
기존의Mutex객체로unique_lock를 초기화한다. 그리고mutex.try_lock()를 호출한다. 상호배제를 잠글 수 없으면 생성자는 정지되지 않는다.
unique_lock(Mutex &mutex, adopt_lock_t) noexcept:
기존의Mutex객체로unique_lock를 초기화한다. 그리고 현재 쓰레드가 이미 상호배제를 잠갔다고 간주한다.
unique_lock(Mutex &mutex, chrono::duration<Rep, Period> const &relTime) noexcept:
이 생성자는mutex.try_lock_for(relTime)를 호출하여Mutex객체의 소유권을 얻으려고 시도한다. 그러므로 지정된 상호배제 유형은 이 멤버를 지원해야 한다 (예를 들어std::timed_mutex). 다음과 같이 호출할 수 있다.std::unique_lock<std::timed_mutex> ulock(timedMutex, std::chrono::seconds(5));
unique_lock(Mutex &mutex, chrono::time_point<Clock, Duration> const
&absTime) noexcept:이 생성자는mutex.try_lock_until(absTime)를 호출하여Mutex객체의 소유권을 얻으려고 시도한다. 그러므로 지정된 상호배제 유형은 이 멤버를 지원해야 한다 (예를 들어std::timed_mutex). 이 생성자는 다음과 같이 호출할 수 있다.std::unique_lock<std::timed_mutex> ulock( timedMutex, std::chrono::system_clock::now() + std::chrono::seconds(5) );
void lock():
unique_lock이 관리하는 상호배제의 소유권을 얻을 때까지 현재 쓰레드를 정지시킨다. 상호배제가 현재 관리되지 않고 있으면system_error예외가 던져진다.
Mutex *mutex() const noexcept:
unique_lock안에 저장된 상호배제 객체를 포인터로 돌려준다 (상호배제가 현재unique_lock객체에 연관되어 있지 않으면nullptr객체가 반환된다.).
explicit operator bool() const noexcept:
unique_lock가 잠긴 상호배제를 소유하고 있으면true를 돌려준다. 그렇지 않으면false를 돌려준다.
unique_lock& operator=(unique_lock &&tmp) noexcept:
왼쪽 피연산자가 잠금을 소유하면 그의 상호배제의unlock멤버를 호출할 것이다. 그 다음에tmp의 상태는 왼쪽 피연산자로 이전된다.
bool owns_lock() const noexcept:
unique_lock이 상호배제를 소유하면true를 돌려준다. 그렇지 않으면false를 돌려준다.
Mutex *release() noexcept:
unique_lock 객체에 연관된 상호배제 객체를 포인터로 돌려준다. 연관 관계는 폐기한다.void swap(unique_lock& other) noexcept:
현재unique_lock과other의 상태를 서로 교환한다.
bool try_lock():
unique_lock와 연관된 상호배제의 소유권을 얻으려고 시도한다. 성공하면true를 돌려주고 그렇지 않으면false를 돌려준다. 현재 상호배제가unique_lock객체에 전혀 연관되어 있지 않으면system_error예외가 던져진다.
bool try_lock_for(chrono::duration<Rep, Period> const &relTime):
이 멤버 함수는 상호배제의try_lock_for(relTime)멤버를 호출하여unique_lock객체가 관리하는Mutex객체의 소유권을 얻으려고 시도한다. 그러므로 지정된 상호배제 유형은 이 멤버를 지원해야 한다 (예를 들어,std::timed_mutex);
bool try_lock_until(chrono::time_point<Clock, Duration> const &absTime):
이 멤버 함수는 상호배제의mutex.try_lock_until(absTime)멤버를 호출하여unique_lock객체가 관리하는Mutex객체의 소유권을 얻으려고 시도한다. 그러므로 지정된 상호배제 유형은 이 멤버를 지원해야 한다 (예를 들어std::timed_mutex);
void unlock():
상호배제의 소유권을 해제한다. 즉, 상호배제의 잠금 횟수를 줄인다.unique_lock객체가 상호배제를 소유하고 있지 않으면system_error예외가 던져진다.
std::lock_guard와 std::unique_lock 클래스의 멤버들 말고도 std::lock과 std::try_lock 멤버가 있다. 이 함수들은 교착(deadlocks)을 방지하는 데 사용하며 이것이 다음 항의 주제이다.
std::lock 함수와 std::try_lock 함수를 정의한다. 교착 상태를 방지하는 데 사용할 수 있다.
이 함수들을 사용하기 전에 <mutex> 헤더를 포함해야 한다.
다음 개관에서 L1 &l1, ...는 잠글 수 있는 유형의 여러 객체를 참조한다는 뜻이다.
void std::lock(L1 &l1, ...):
함수가 돌아오면 모든 li 객체에 대하여 잠금을 획득한다. 하나의 객체라도 잠금을 얻을 수 없으면 지금까지 얻은 잠금을 모조리 해제한다. 잠금을 얻을 수 없었던 그 객체가 예외를 던질지라도 말이다.
int std::try_lock(L1 &l1, ...):
이 함수는 잠금가능 객체의 try_lock 멤버를 호출한다. 모두 잠금을 얻을 수 있으면 -1이 반환된다. 그렇지 않으면 잠글 수 없는 첫 인자의 인덱스가 반환된다 (0-기반). 그리고 이전에 얻은 잠금을 모두 해제한다.
다음의 작은 다중-쓰레드 프로그램을 연구해 보자. 쓰레드들은 상호배제를 사용하여 cout과 int value 값에 독점적인 접근 권한을 얻는다. 그렇지만 fun1은 먼저 cout을 잠그고 (줄 7) 그 다음 value를 잠근다 (줄 10); fun2는 먼저 value를 잠그고 (줄 16) 그 다음에 cout을 잠근다 (줄 19). fun1이 cout을 잠구었다면 fun2는 fun1이 놓아줄 때까지 그 잠금을 얻을 수 없는 것은 확실하다. 불행하게도 fun2는 value를 잠구었다. 그리고 함수들은 반환될 때에만 그들의 잠금을 풀어줄 것이다. 그러나 value의 정보에 접근하기 위해 fun1은 value에 대하여 잠금을 얻었어야 한다. 그러나 그것은 불가능하다. fun2가 이미 value를 잠구었기 때문이다. 쓰레드는 어느 쪽도 서로 양보하지 않으면서 서로를 기다린다.
1: int value;
2: mutex valueMutex;
3: mutex coutMutex;
4:
5: void fun1()
6: {
7: lock_guard<mutex> lg1(coutMutex);
8: cout << "fun 1 locks cout\n";
9:
10: lock_guard<mutex> lg2(valueMutex);
11: cout << "fun 1 locks value\n";
12: }
13:
14: void fun2()
15: {
16: lock_guard<mutex> lg1(valueMutex);
17: cerr << "fun 2 locks value\n";
18:
19: lock_guard<mutex> lg2(coutMutex);
20: cout << "fun 2 locks cout\n";
21: }
22:
23: int main()
24: {
25: thread t1(fun1);
26: fun2();
27: t1.join();
28: }
교착상태를 피하는 좋은 요리법은 내포된 (여러) 상호배제 잠금 호출을 방지하는 것이다. 그러나 여러 상호배제를 사용해야 한다면 언제나 같은 순서로 잠금을 얻어야 한다. 손수 직접 할게 아니라 되도록이면 std::lock과 std::try_lock를 사용해서 여러 상호배제 잠금을 얻어야 한다. 이 함수들은 여러 인자를 받는다. 잠금이 가능한 유형이어야 한다. 예를 들어 lock_guard이나 unique_lock 심지어 평범한 mutex도 된다. 이전의 교착 프로그램은 std::lock을 호출하도록 변경해 두 개의 상호배제를 잠그도록 할 수 있다. 다음 예제에서 하나의 상호배제도 작동하겠지만 수정된 프로그램은 이제 이전 프로그램과 가능하면 비슷하게 보일 것이다. 줄 10과 21에서 unique_lock 인자의 순서가 어떻게 사용되었는지 눈여겨보라: std::lock이나 std::try_lock을 사용할 때 인자를 꼭 같은 순서로 사용할 필요는 없다.
1: int value;
2: mutex valueMutex;
3: mutex coutMutex;
4:
5: void fun1()
6: {
7: unique_lock<mutex> lg1(coutMutex, defer_lock);
8: unique_lock<mutex> lg2(valueMutex, defer_lock);
9:
10: lock(lg1, lg2);
11:
12: cout << "fun 1 locks cout\n";
13: cout << "fun 1 locks value\n";
14: }
15:
16: void fun2()
17: {
18: unique_lock<mutex> lg1(coutMutex, defer_lock);
19: unique_lock<mutex> lg2(valueMutex, defer_lock);
20:
21: lock(lg2, lg1);
22:
23: cout << "fun 2 locks cout\n";
24: cout << "fun 2 locks value\n";
25: }
26:
27: int main()
28: {
29: thread t1(fun1);
30: thread t2(fun2);
31: t1.join();
32: t2.join();
33: }
std::shared_lock 유형을 정의한다. <shared_mutex> 헤더를 포함하면 사용할 수 있다.
std::shared_lock 유형의 객체는 영역 안에서 잠금 객체의 공유 소유권을 제어한다. 잠금이 가능한 객체의 공유 소유권은 생성 시간에 얻을 수 있다. 일단 얻으면 그 이후로 또다른 shared_lock 객체에 이전할 수 있다. shared_lock 유형의 객체는 복사할 수 없다. 그러나 이동 생성과 할당을 지원한다.
상호배제를 가리키는 포인터가 (즉, pm이) 0-아닌 값을 가진 경우 프로그램의 행위는 정의되어 있지 않다. 그리고 pm이 가리키는 잠금이 가능한 객체는 shared_lock 객체의 나머지 생애 동안 존재하지 않는다. 지원되는 상호배제 유형은 반드시 shared_mutex이거나 또는 특징이 같은 유형이어야 한다.
shared_lock 유형은 다음과 같은 생성자와 소멸자 그리고 연산자를 지원한다.
shared_lock() noexcept:
기본 생성자는shared_lock을 생성한다. 어느 쓰레드에도 속해 있지 않고,pm == 0이다.
explicit shared_lock(mutex_type &mut):
이 생성자는 상호배제를 잠근다.mut.lock_shared()를 호출한다. 호출 쓰레드는 아직 잠금을 소유하지 못할 수도 있다. 다음pm == &mut생성 후에, 잠금은 현재 쓰레드가 소유한다.
shared_lock(mutex_type &mut, defer_lock_t) noexcept:
이 생성자는pm을&mut에 할당한다. 그러나 호출 쓰레드는 잠금을 소유하지 않는다.
shared_lock(mutex_type &mut, try_to_lock_t):
이 생성자는 상호배제를 잠그려고 시도한다.mut.try_lock_shared()를 호출한다. 호출 쓰레드는 미처 잠금을 소유하지 못할 수도 있다. 다음pm == &mut생성 후에, 현재 쓰레드가 잠금을 소유하고 있는지 여부는try_lock_shared;의 반환 값에 따라 달라진다.
shared_lock(mutex_type &mut, adopt_lock_t):
호출 쓰레드가 상호배제의 소유권을 공유한다면 이 생성자를 호출할 수 있다. 다음 pm == &mut 생성 후에, 잠금은 현재 쓰레드가 소유한다.
shared_lock(mutex_type &mut, chrono::time_point<Clock, Duration> const &abs_time):
이 생성자는 멤버 템플릿이다.Clock와Duration는 시계와 절대 시간을 지정하는 유형이다 (20.1절). 호출 쓰레드가 아직 상호배제를 소유하지 못했으면 호출할 수 있다.mut.try_lock_shared_until(abs_time)를 호출한다. 다음pm == &mut생성 후에, 잠금을 현재 쓰레드가 소유했는지 여부는try_lock_shared_until;의 반환 값에 따라 달라진다.
shared_lock(mutex_type &mut, chrono::duration<Rep, Period> const &rel_time):
이 생성자는 멤버 템플릿이다.Clock과Period는 시계와 상대 시간을 지정하는 유형이다 (20.1절). 호출 쓰레드가 아직 상호배제를 소유하지 못하면 호출할 수 있다.mut.try_lock_shared_for(abs_time)를 호출한다. 다음pm == &mut생성 후에, 현재 쓰레드의 잠금 소유여부는try_lock_shared_for;의 반환 값에 따라 달라진다.
shared_lock(shared_lock &&tmp) noexcept:
이동 생성자는tmp의 정보를 새로 생성된shared_lock으로 이전한다. 다음tmp.pm == 0생성후에tmp는 더 이상 잠금을 소유하지 않는다.
~shared_lock():
잠금을 현재 쓰레드가 소유하고 있으면, pm->unlock_shared()이 호출된다.
shared_lock &operator=(shared_lock &&tmp) noexcept
이동 할당 연산자는pm->unlock_shared를 호출 한 다음,tmp의 정보를 현재shared_lock객체로 이전한다. 다음tmp.pm == 0생성 후에,tmp는 더 이상 잠금을 소유하지 않는다.
explicit operator bool () const noexcept:
shared_lock 객체가 잠금을 소유하고 있는지 없는지 그 여부를 돌려준다.다음 멤버를 제공한다.
void lock():
pm->lock_shared()을 호출한다. 그 다음에 현재 쓰레드는 공유 잠금을 소유한다. 그렇지 않고pm == 0이거나 현재 쓰레드가 이미 잠금을 소유하고 있으면lock_shared으로부터 예외가 던져질 수 있다.
mutex_type *mutex() const noexcept:
pm을 돌려준다.mutex_type *release() noexcept:
pm의 이전 값을 돌려준다. 이 값은 이 멤버를 호출한 후 0이다. 또한, 현재 객체는 더 이상 잠금을 소유하지 않는다.void swap(shared_lock &other) noexcept:
현재 객체와othershared_lock객체의 데이터 멤버들을 교환한다. 또 함수 템플릿인swap자유 멤버도 있다. 두 개의shared_lock<Mutex>객체를 교환한다. 여기에서Mutex는 실체화된 공유 잠금 객체의 상호배제 유형을 나타낸다.void swap(shared_lock<Mutex> &one, shared_lock<Mutex> &two) noexcept;
bool try_lock():
pm->try_lock_shared()를 호출한다. 이 호출의 반환 값을 돌려준다. 그렇지 않고pm == 0이거나 현재 쓰레드가 이미 잠금을 소유하고 있으면try_lock_shared으로부터 예외가 던져질 수 있다.
bool try_lock_for(const chrono::duration<Rep, Period rel_time):
멤버 템플릿이다.Clock과Period는 시계와 상대 시간을 지정하는 유형이다 (20.1절).mut.try_lock_shared_for(abs_time)를 호출한다. 호출 후 잠금은 현재 쓰레드가 소유할 수도 못할 수도 있다.try_lock_shared_until의 반환 값에 따라 달라진다. 그렇지 않고pm == 0이거나 현재 쓰레드가 이미 잠금을 소유하고 있으면try_lock_shared_for으로부터 예외가 던져질 수 있다.
bool try_lock_until(const chrono::time_point<Clock, Duration>& abs_time):
멤버 템플릿이다.Clock과Duration은 시계와 절대 시간을 지정하는 유형이다 (20.1절).mut.try_lock_shared_until(abs_time)를 호출하여 그 반환 값을 돌려준다. 호출 후, 잠금은 현재 쓰레드가 소유할 수도 못할 수도 있다.try_lock_shared_until의 반환 값에 따라 달라진다. 그렇지 않고pm == 0이거나 현재 쓰레드가 이미 잠금을 소유하고 있으면try_lock_shared_until으로부터 예외가 던져질 수 있다
void unlock():
공유 상호배제 잠금을 푼다. 소유권을 해제한다. 공유 상호배제를 현재 쓰레드가 소유하고 있지 않으면 예외를 던진다.
조건 변수를 사용하기 전에 <condition_variable> 헤더를 포함해야 한다.
논의를 시작하기 위하여 고전적인 생산자-소비자 시나리오를 생각해 보자. 생산자는 소비자가 소비할 물품을 생산한다. 생산자는 창고가 가득찰 때까지 일정 갯수의 물품을 생산한다. 고객은 생산자가 생산한 물품의 수량을 넘어서서 소비할 수 없다.
어느 시점에 생산자의 창고는 가득 찬다. 생산자는 고객이 적어도 어느 정도는 소비해 줄 때까지 기다려야 한다. 그래야 생산자의 창고에 여유가 생긴다. 비슷하게, 소비자는 생산자가 적어도 어느 정도의 물품을 생산할 때까지는 소비할 수 없다.
상호배제 (데이터 잠금)만을 사용하여 이 시나리오를 구현하는 것은 별로 좋은 선택이 아니다. 단순히 상호배제만 사용하면 프로그램은 폴링을 사용하는 시나리오를 구현해야 한다. 프로세스는 끊임없이 상호배제 잠금을 (재)획득하고 어떤 조치를 수행할 수 있는지 결정한 뒤에 잠금을 해제해야 한다. 프로세스가 할 일도 없는데 상호배제의 잠금을 획득하고 풀어주느라 바쁠 뿐인 경우가 많다. 폴링을 하게 되면 쓰레드는 어쩔 수 없이 상호배제를 잠글 수 있을 때가지 기다려야 한다. 그대로 계속 진행할 수 있음에도 말이다. 폴링의 간격을 줄이는 방법이 있겠지만, 그것 역시 마음에 드는 선택은 아니다. 그렇게 하면 상호배제 처리에 관련된 부담이 증가하기 때문이다. 이것을 `바쁜 기다림(busy waiting)'이라고 부른다.
조건 변수를 사용하면 폴링을 방지할 수 있다. 조건 변수를 사용하여 쓰레드는 기다리는 쓰레드에게 무언가 하고 있음을 고지할 수 있다. 이런 식으로 쓰레드는 데이터 값(상태)을 동기화할 수 있다.
데이터 값은 여러 쓰레드에 의하여 변경될 수 있으므로 여전히 상호배제를 사용할 필요가 있다. 그러나 데이터 접근을 통제하는 경우에만 사용하면 된다. 게다가, 조건 변수로 특정 값을 획득할 때까지 미리 설정된 시간이 지나거나 또는 미리 정의된 시점에 도달하기까지 상호배제의 소유권을 놓아줄 수 있다.
조건 변수를 사용하는 쓰레드의 원형 설정은 다음과 같다.
상호배제를 잠근다.
필요한 조건을 아직 얻지 못한 동안 (즉, 거짓이면):
고지받을 때까지 기다린다.
(이것은 자동으로 상호배제의 잠금을 풀어준다.)
일단 상호배제의 잠금을 재획득하였다면, 그리고
필요한 조건을 얻었다면:
그 데이터를 처리한다.
상호배제의 잠금을 풀어준다.
상호배제를 잠근다.
필요한 조건을 아직 얻지 못하고 있다면:
필요한 조건을 얻기 위해 뭔가 일을 한다.
대기중인 쓰레드에게 (필요한 조건을 얻었다고) 고지한다.
상호배제의 잠금을 풀어준다.
이 규약은 최초의 미묘한 동기화 요구 조건을 감춘다. 아직 대기 상태에 들어가지 못했다면 소비자는 생산자의 고지를 놓칠 것이다. 그래서 대기중인 (소비자) 쓰레드는 고지 (생산자) 쓰레드가 시작하기 전에 먼저 시작해야 한다. 일단 쓰레드가 시작하면 조건 변수의 멤버들이 호출되는 순서에 관하여 더 이상 어떤 가정도 할 수 없다 (notify_one, notify_all, wait, wait_for, 그리고 wait_until).
조건 변수는 두 가지 형태가 있다. std::condition_variable 클래스의 객체는 unique_lock<mutex> 유형의 객체와 조합하여 사용된다. 이 특정한 조합을 최적화할 수 있기 때문에 condition_variable 클래스를 사용하는 것이 일반적으로 적용가능한 std::condition_variable_any 클래스를 사용하는 것보다 약간 더 효율적이다. 이 클래스는 (사용자가 공급한) 잠금 유형과 함께 사용된다.
조건 변수 클래스는 wait, wait_for, wait_until, notify_one 그리고 notify_all 같은 멤버를 제공한다 (다음 두 항에 더 자세하게 다룸). 모두 병행적으로 호출할 수 있다. 고지 멤버들은 언제나 원자적으로 실행된다. wait 멤버의 실행은 세 개의 원자 부분으로 구성된다.
wait 호출 다음에도 처리는 계속된다.
wait-멤버로부터 돌아오면 이전에 대기중인 쓰레드는 상호배제의 잠금을 다시 획득한다.
조건 변수 클래스 말고도 다음 자유 함수와 열거 유형을 제공한다.
void std::notify_all_at_thread_exit(condition_variable &cond,
unique_lock<mutex> lockObject):
현재 쓰레드가 끝나면cond상태를 기다리는 다른 모든 쓰레드에 고지된다.notify_all_at_thread_exit함수를 호출한 후에 되도록이면 빨리 쓰레드를 종료하는 것이 좋은 관행이다 .대기중인 쓰레드는 자신이 기다리는 쓰레드가 실제로 끝났는지 확인해야 한다. 이것은 보통 다음과 같이 실현할 수있다. 먼저
lockObject에 대하여 잠금을 얻고, 이어서 기다리고 있는 조건이 참인지 확인하고notify_all_at_thread_exit을 호출하기 전에 잠금을 얻지 않았는지 다시 확인하면 된다.
cv_status: std::cv_status 열거체는 조건 변수 클래스의 여러 멤버 함수에 의하여 사용된다 (20.5.1항과 20.5.2 항 참조):
namespace std
{
enum class cv_status
{
no_timeout,
timeout
};
}
std::condition_variable 클래스는 그저 기본 생성자를 제공할 뿐이다. 복사 생성자도 없고 중복정의 할당 연산자도 없다.
condition_variable 클래스를 사용하기 전에 <condition_variable> 헤더를 포함해야 한다.
이 클래스의 소멸자는 condition_variable를 파괴하는 쓰레드 때문에 다른 어떤 쓰레드도 정지되지 않도록 요구한다. 그래서 condition_variable 객체의 생애가 끝나기 전에 기다리는 모든 쓰레드에게 이 사실을 고지해야 한다. condition_variable의 생애가 끝나기 전에 notify_all을 호출하면 (아래 참고) 고지된 쓰레드 중 하나가 상호배제를 획득할 수 있다. condition_variable의 쓰레드가 mutex 변수에 대한 잠금을 풀어주기 때문이다.
다음 멤버의 설명에서 Predicate 유형은 제공된 인자를 함수처럼 호출할 수 있다. 인자가 없고 bool 유형을 돌려주는 함수처럼 말이다. 또한, 다른 멤버 함수도 자주 참조된다. 아래에 언급된 모든 멤버 함수들은 같은 조건 변수 객체를 사용하여 호출된다고 묵시적으로 간주된다.
condition_variable 클래스는 여러 wait 멤버를 제공한다. 이 멤버들은 또다른 쓰레드가 고지할 때까지 (또는 일정한 대기 시간 동안) 쓰레드를 정지시킨다. 그렇지만, wait 멤버는 잠금을 다시 획득하지 못했는데도 거짓으로 실행 정지가 풀릴 수 있다. 그러므로 wait 멤버로부터 돌아오면 쓰레드는 획득한 조건이 실제로 참인지 확인해야 한다. 그렇지 않다면 다시 wait를 호출하는 것이 적절하다. 다음 의사 코드는 이 전략을 보여준다.
while (conditionNotTrue())
condVariable.wait(&uniqueLock);
condition_variable 클래스의 멤버는 다음과 같다.
void notify_one() noexcept:
다른 쓰레드에 의하여 호출된 wait 멤버 하나가 반환된다. 어느 멤버가 실제로 반환될 지는 예측할 수 없다.
void notify_all() noexcept:
다른 쓰레드에 의하여 호출된 모든 wait 멤버들은 대기 상태를 해제한다. 물론 그 중에 하나만 연이어서 조건 변수의 잠금 객체를 다시 얻는다.
void wait(unique_lock<mutex>& uniqueLock):
wait를 호출하기 전에 현재 쓰레드는uniqueLock의 잠금을 획득했어야 한다.wait를 호출하면 그 잠금을 해제한다. 그리고 현재 쓰레드는 또다른 쓰레드로부터 고지를 받아 그 잠금을 다시 얻을 때까지 정지된다.
멤버 템플릿이다.template <typename Predicate>헤더를 사용한다. 이 템플릿의 유형은 자동으로 함수의 인자 유형으로부터 파생되고 명시적으로 지정할 필요가 없다.wait를 호출하기 전에 현재 쓰레드는uniqueLock의 잠금을 획득하고 있어야 한다. `pred'가false를 돌려주는 한,wait(lock)이 호출된다.
cv_status wait_for(unique_lock<mutex> &uniqueLock, std::chrono::duration<Rep, Period> const &relTime):
이 멤버는 멤버 템플릿으로 정의되어 있다.template <typename Rep, typename Period>헤더를 사용한다. 템플릿 유형은 자동으로 함수의 인자로부터 파생되며 명시적으로 지정할 필요가 없다. 예를 들어 최대 5초 동안 기다리려면wait_for를 다음과 같이 호출하면 된다.cond.wait_for(&unique_lock, std::chrono::seconds(5));이 멤버는 고지될 때 또는relTime에 지정된 시간이 경과할 때 반환된다.시간 제한 때문이라면
std::cv_status::timeout이 반환되고 그렇지 않으면std::cv_status::no_timeout이 반환된다.
wait_for가 반환되면 쓰레드는 필요한 데이터 조건이 충족되었는지 확인해야 한다.
bool wait_for(unique_lock<mutex> &uniqueLock, chrono::duration<Rep, Period> const &relTime, Predicate pred):
이 멤버는 멤버 템플릿으로 정의되어 있다.template <typename Rep, typename Period, typename Predicate>헤더를 사용한다. 템플릿 유형은 자동으로 함수의 인자로부터 파생되며 명시적으로 지정할 필요가 없다.
pred가 false를 돌려주는 한, 이전의wait_for멤버 함수가 호출된다. 이전의 멤버가cv_status::timeout을 돌려주면pred가 돌아온다. 그렇지 않으면true가 반환된다.
cv_status wait_until(unique_lock<mutex>& uniqueLock, chrono::time_point<Clock, Duration> const &absTime):
이 멤버는 멤버 템플릿으로 정의되어 있다.template <typename Clock, typename Duration>헤더를 사용한다. 템플릿 유형은 자동으로 함수의 인자로부터 파생되며 명시적으로 지정할 필요가 없다. 현재 시간부터 5분 동안 기다리려면wait_until을 다음과 같이 호출하면 된다.cond.wait_until(&unique_lock, chrono::system_clock::now() + std::chrono::minutes(5));이 함수는 이전에 기술한wait_for(unique_lock<mutex> &uniqueLock, chrono::duration<Rep, Period> const &relTime)멤버와 똑같이 행위한다. 그러나 상대 시점이 아니라 절대 시점을 사용한다.이 멤버는 고지를 받거나
relTime에 지정된 시간을 넘어설 때 반환된다. 시간 제한 때문이라면std::cv_status::timeout이 반환되고 그렇지 않으면std::cv_status::no_timeout이 반환된다.
bool wait_until(unique_lock<mutex> &lock, chrono::time_point<Clock, Duration> const &absTime, Predicate pred):
이 멤버는 멤버 템플릿으로 정의되어 있다. 템플릿 헤더로template <typename Clock, typename Duration, typename Predicate>을 사용한다. 템플릿 유형은 자동으로 함수의 인자로부터 파생되며 명시적으로 지정할 필요가 없다.
pred가false를 돌려주는 한, 이전의wait_until멤버가 호출된다. 이전의 멤버가cv_status::timeout을 돌려주면pred가 돌아온다. 그렇지 않으면true가 반환된다.
true인지 확인해야 한다.
condition_variable 클래스와 다르게 std::condition_variable_any 클래스는 unique_lock<mutex>는 물론이고 (사용자가 공급한) 잠금 유형과 함께 사용할 수 있다.
condition_variable_any 클래스를 사용하기 전에 <condition_variable> 헤더를 포함해야 한다.
condition_variable_any 클래스가 제공하는 기능은 condition_variable 클래스가 제공하는 기능과 동일하다. 그렇지만 condition_variable_any 클래스가 사용하는 잠금-유형은 미리 정의되어 있지 않다. 그러므로 condition_variable_any 클래스는 객체가 사용할 잠금-유형을 지정하기를 요구한다.
아래에 보여주는 인터페이스에서 이 잠금-유형은 Lock으로 참조된다. condition_variable_any 클래스의 멤버는 대부분 템플릿으로 정의되어 있다. Lock 유형을 매개변수 중 하나로 정의한다. 이 잠금-유형의 요구조건은 unique_lock과 동일하다. 그리고 사용자-정의 구현은 적어도 unique_lock이 제공하는 인터페이스와 의미구조를 제공해야 한다.
이 항은 condition_variable_any 클래스의 인터페이스만 보여준다. 인터페이스는 멤버가 condition_variable 클래스와 같기 때문에 (상응하는 멤버에 unique_lock 클래스 말고도 어떤 잠금-유형이든 건넬 수 있으므로), 클래스 멤버의 의미구조를 설명한 것은 이전 항을 참고하라
condition_variable 클래스처럼 condition_variable_any 클래스는 기본 생성자만 제공한다. 복사 생성자도 없고 중복정의 할당 연산자도 없다.
또, condition_variable 클래스처럼 이 클래스의 소멸자는 현재 쓰레드에 의하여 어떤 쓰레드도 정지되지 않도록 요구한다. 이 덕분에 (기다리는) 다른 모든 쓰레드에 손쉽게 고지된다. 그렇지만 그런 쓰레드는 wait 호출에 지정된 잠금에 대하여 연이어서 정지된다.
Lock말고도, Clock, Duration, Period, Predicate 그리고 Rep 유형은 템플릿이다. 이전 항에 언급한 이름붙은 유형과 동일하게 정의된다.
MyMutex는 사용자 정의 상호배제 유형이고 MyLock는 사용자 정의 잠금 유형이라고 간주하면 (잠금-유형에 관하여 더 자세한 것은 20.4절 참고), condition_variable_any 객체를 정의해 다음과 같이 사용할 수 있다.
MyMutex mut;
MyLock<MyMutex> ul(mut);
condition_variable_any cva;
cva.wait(ul);
다음은 condition_variable_any 클래스의 멤버이다.
void notify_one() noexcept;
void notify_all() noexcept;
void wait(Lock& lock);
void wait(Lock& lock, Predicate pred);
cv_status wait_until(Lock& lock, const
chrono::time_point<Clock, Duration>& absTime);
bool wait_until(Lock& lock, const chrono::time_point<Clock, Duration>&
absTime, Predicate pred);
cv_status wait_for(Lock& lock, const chrono::duration<Rep,
Period>& relTime);
bool wait_for(Lock& lock, const chrono::duration<Rep, Period>&
relTime,) Predicate pred;
소비자 회돌이:
- 물품에 창고에 들어올 때까지 기다린다.
들어오면 저장된 물품의 갯수를 줄인다.
- 창고에서 물품을 제거한다.
- 저장 능력의 갯수를 늘린다.
- 가져온 물품으로 일을 한다.
생산자 회돌이:
- 다음 물품을 생산한다.
- 물품을 저장할 공간이 생길 때까지 기다린다.
그러면 저장 능력의 갯수를 줄인다.
- 물품을 창고에 저장한다.
- 저장된 물품의 갯수를 늘린다.
(물품의 갯수를 등록하고 저장 능력을 등록하는) 두 개의 저장 관리 작업을 소비자 아니면 생산자가 수행한다는 것이 중요하다. 소비자에게 `기다림'이란 다음과 같은 뜻이다.
Semaphore 클래스에 구현된다. wait 멤버와 notify_all 멤버를 제공한다. 세마포어에 관한 더 광범위한 논의는 다음을 참고하라:
Tanenbaum, A.S. and Austin, T. (2013)
Structured Computer Organization, Pearson Prentice-Hall.
d_available 데이터 멤버는 실제 갯수를 담고 있다. mutex d_mutex로 보호된다. 그리고 condition_variable d_condition은 다음과 같이 정의된다.
mutable std::mutex d_mutex;
std::condition_variable d_condition;
size_t d_available;
대기중인 프로세스는 wait 멤버 함수로 구현한다.
1: void Semaphore::wait()
2: {
3: std::unique_lock<std::mutex> lk(d_mutex); // 잠금 획득
4: while (d_available == 0)
5: d_condition.wait(lk); // 내부적으로 잠금 해제
6: // 그리고 기다린다. 끝날 때
7: // 다시 잠금을 획득한다.
8: --d_available; // 잠금을 줄인다. 사용이 가능해짐
9: } // 잠금이 해제됨
5번 줄에서 d_condition.wait는 잠금을 해제한다. 고지를 받을 때까지 기다린다. 돌아오기 바로 전에 잠금을 다시 얻는다. 결론적으로 wait의 코드는 언제나 d_available을 완전히 배타적으로 제어한다.
기다리는 쓰레드에게 고지하면 어떻게 되는가? 이것은 notify_all 멤버의 4 번과 5 번 줄에서 처리된다.
1: void Semaphore::notify_all()
2: {
3: std::lock_guard<std::mutex> lk(d_mutex); // 잠금 획득
4: if (d_available++ == 0)
5: d_condition.notify_all(); // notify_one을 사용하여
6: // 다른 쓰레드 하나에게 고지함
7: } // 잠금이 해제됨
4 번 줄에서 d_available는 언제나 증가한다. 후위 증가를 사용하여 동시에 0인지 테스트할 수 있다. 처음에 0이었다면 d_available는 이제 1이다. d_available 변수가 0을 초과하기를 기다리던 쓰레드는 이제 실행을 계속할 수 있다. 대기중인 쓰레드에게 d_condition.notify_one을 호출하여 고지한다. 여러 쓰레드가 대기중인 상황이라면 `notify_all'을 사용할 수도 있다.
세마포어의 생성자는 최초의 값으로 semaphore 데이터 멤버를 기대한다. 이 Semaphore 클래스의 편의기능을 사용하면 이제 멀티-쓰레드로 고전적인 소비자-생산자 패러다임을 구현할 수 있다 (생산자-소비자 프로그램을 보다 더 정교하게 구현한 예제는 yo/threading/examples/events.cc 파일에 있다. 소스 디렉토리에서 찾아 보자):
Semaphore available(10);
Semaphore filled(0);
std::queue itemQueue;
void consumer()
{
while (true)
{
filled.wait();
// 상호배제(mutex)로 소비자 큐를 잠금
size_t item = itemQueue.front();
itemQueue.pop();
available.notify_all();
process(item); // 여기에 구현 안됨
}
}
void producer()
{
size_t item = 0;
while (true)
{
++item;
available.wait();
// 상호배제(mutex)로 소비자 큐를 잠금
itemQueue.push(item);
filled.notify_all();
}
}
int main()
{
thread consume(consumer);
thread produce(producer);
consume.join();
produce.join();
}
<atomic> 헤더를 포함해야 한다.
쓰레드끼리 데이터를 공유할 때 보통은 상호배제를 사용하여 데이터 부패를 방지한다. 단순히 int를 증가시키기 위해 이 전략을 사용하면 코드는 아래와 같이 사용된다.
{
lock_guard<mutex> lk(intVarMutex);
++intVar;
}
위의 복합 서술문은 lock_guard의 생애를 제한한다. 그래서 intVar는 아주 잠깐 동안만 잠긴다.
이 전략은 복잡하지 않다. 그러나 결국 단 하나의 단순한 변수조차도 사용할 때마다 lock_guard를 정의해야 하고 간단한 변수마다 그에 맞게 상호배제를 정의해야 한다. 이것은 귀찮고 짜증나는 일이다.
C++는 원자 데이터 유형이라는 탈출구를 제공한다. 원자 데이터 유형은 모든 기본 유형에 대하여 사용할 수 있고, 또한 (평범한) 사용자 정의 유형에도 사용할 수 있다. 평범한 유형으로는 모든 스칼라 유형과 평범한 유형의 배열 원소들이 있으며 그리고 생성자와 복사 생성자 그리고 소멸자가 모두 기본 구현인 클래스가 있다 (23.6.2항). 그리고 그들의 비-정적 데이터 멤버 자체도 평범한 유형이다.
포인터 유형을 비롯하여 모든 내장 유형에 대하여 std::atomic<Type> 클래스 템플릿을 사용할 수 있다. 예를 들어 std::atomic<bool>는 원자 bool 유형을 정의한다. 많은 유형에 대하여 대안으로 약간 더 짧은 유형 이름을 사용할 수 있다. 예를 들어 std::atomic<unsigned short> 대신에 std::atomic_ushort 유형을 사용할 수 있다. 대안 이름의 완전한 목록은 atomic 헤더를 참고하라.
Trivial이 사용자가 정의한 평범한 유형이라면 std::atomic<Trivial>은 Trivial을 원자 유형으로 변형해 정의한다. 원자 유형은 다중 쓰레드의 접근을 동기화하기 위해 별도의 상호배제를 요구하지 않는다.
std::atomic<Type> 클래스 객체는 직접적으로 서로 복사하거나 할당할 수 없다. 그렇지만 Type 유형의 값으로 초기화가 가능하다. Type 유형의 값은 직접적으로 std::atomic<Type> 객체에 할당할 수 있다. 게다가 atomic<Type> 유형은 Type 값을 돌려주는 변환 연산자를 제공하기 때문에 atomic<Type> 객체는 static_cast를 사용하여 또다른 atomic<Type> 객체에 할당하거나 이 객체로 초기화할 수 있다.
atomic<int> a1 = 5;
atomic<int> a2(static_cast<int>(a1));
std::atomic<Type> 클래스는 여러 공개 멤버를 제공한다. atomic<Type> 객체에 작동하는 자유 함수도 사용할 수 있다.
std::memory_order 열거형에 다음 심볼 상수들이 정의되어 있다. 원자 연산의 순서를 제약한다.
memory_order_acq_rel: 읽어서-변경하고-쓰는 연산이다. memory_order_acquire와 memory_order_release를 조합해 사용한다.
memory_order_acquire: 획득 연산이다. 같은 메모리 위치에 썼던 해제 연산과 동기화된다.
memory_order_consume: 관련 메모리 위치에 대한 소비 연산이다.
memory_order_relaxed: 연산 순서에 제약이 없다.
memory_order_release: 해제 연산이다. 같은 위치에 대하여 획득 연산과 동기화된다.
memory_order_sec_cst: 모든 연산에 대하여 기본 메모리 순서를 지정한다. 메모리 저장은 memory_order_release를 사용하고 메모리 적재는 memory_order_acquire를 사용하며 그리고 읽어서-변경하고-쓰기는 memory_order_acq_rel를 사용한다.
atomic<Type>이 제공하는 중복정의 연산자에 대하여 메모리 순서는 지정할 수 없다. 그렇지 않으면 대부분의 atomic 멤버 함수에 마지막 인자로 memory_order를 줄 수도 있다. 이것을 사용할 수 없는 경우는 함수의 설명에 명시적으로 언급한다.
다음은 표준 std::atomic<Type> 멤버 함수들이다.
bool compare_exchange_strong(Type ¤tValue, Type newValue) noexcept:
원자 객체의 값을newValue와 비트별로 비교한다. 같으면true가 반환된다. 그리고newValue는 원자 객체에 저장된다. 같지 않으면false가 반환된다. 그리고 그 객체의 현재 값은currentValue에 저장된다.
bool compare_exchange_weak(Type &oldValue, Type newValue) noexcept:
원자 객체의 값을 비트별로newValue에 비교한다. 같으면true가 반환된다. 그리고newValue는 원자 객체에 저장된다. 같지 않으면 또는newValue를 원자적으로 현재 객체에 할당할 수 없으면false가 반환된다. 그리고 객체의 현재 값은currentValue에 저장된다.
Type exchange(Type newValue) noexcept:
객체의 현재 값을 돌려준다. 그리고 newValue는 현재 객체에 할당된다.
bool is_lock_free() const noexept:
잠금 없이 현재 객체에 대한 연산을 수행할 수 있으면true를 돌려준다. 그렇지 않으면false를 돌려준다. 이 멤버는memory_order매개변수가 없다.
Type load() const noexcept:
객체의 값을 돌려준다.
operator Type() const noexcept:
객체의 값을 돌려준다.
void store(Type newValue) noexcept:
NewValue를 현재 객체에 할당한다. 표준 할당 연산자를 사용할 수도 있음을 주목하라.
위의 멤버 말고도 정수형 원자 유형 `Integral' 클래스도 역시 다음의 멤버 함수를 제공한다 (본질적으로 모든 내장 정수 유형의 원자적 변형이다):
Integral fetch_add(Integral value) noexcept:
Value를 현재 객체의 값에 더한다. 그리고 호출하는 순간의 객체의 값을 돌려준다.Integral fetch_sub(Integral value) noexcept:
Value를 객체의 값으로부터 뺀다. 그리고 호출하는 순간의 객체의 값을 돌려준다.Integral fetch_and(Integral mask) noexcept:
bit-and 연산자를 객체의 값에 적용하고 마스크 처리한다. 결과 값을 현재 객체에 할당한다. 호출하는 순간의 객체의 값을 돌려준다.Integral fetch_|=(Integral mask) noexcept:
bit-or 연산자를 객체의 값에 적용하고 마스크 처리한다. 결과 값을 현재 객체에 할당한다. 호출하는 순간의 객체의 값을 돌려준다.
Integral fetch_^=(Integral mask) noexcept:
bit-xor 연산자를 객체의 값에 적용하고 마스크 처리한다. 결과 값을 현재 객체에 할당한다. 호출하는 순간의 객체의 값을 돌려준다.
Integral operator++() noexcept:
전위 증가 연산자로서 객체의 새 값을 돌려준다.
Integral operator++(int) noexcept:
후위 증가 연산자로서 증가시키기 전에 객체의 값을 돌려준다.
Integral operator--() noexcept:
전위 감소 연산자로서 객체의 새 값을 돌려준다.
Integral operator--(int) noexcept:
후위 감소 연산자로서 감소시키기 전에 객체의 값을 돌려준다.
Integral operator+=(Integral value) noexcept:
Value를 객체의 현재 값에 추가한다. 객체의 새 값을 돌려준다.Integral operator-=(Integral value) noexcept:
Value를 현재 객체의 값으로부터 뺀다. 객체의 새 값을 돌려준다.Integral operator&=(Integral mask) noexcept:
bit-and 연산자를 객체의 현재 값에 적용하고 마스크 처리한다. 결과 값을 현재 객체에 할당한다. 객체의 새 값을 돌려준다.Integral operator|=(Integral mask) noexcept:
bit-or 연산자를 객체의 현재 값에 적용하고 마스크 처리한다. 결과 값을 현재 객체에 할당한다. 객체의 새 값을 돌려준다.
Integral operator^=(Integral mask) noexcept:
bit-xor 연산자를 객체의 현재 값에 적용하고 마스크 처리한다. 결과 값을 현재 객체에 할당한다. 객체의 새 값을 돌려준다.
이름이 _explicit으로 끝나는 자유 함수가 있다. _explicit 함수는 추가 매개변수로 `memory_order order'를 정의한다. 이것은 _explicit 함수가 아니면 사용할 수 없다 (예를 들어, atomic_load(atomic<Type> *ptr) 그리고 atomic_load_explicit(atomic<Type>*ptr, memory_order order))
다음은 모든 원자 유형에 사용할 수 있는 자유 함수이다.
bool std::atomic_compare_exchange_strong(_explicit)(std::atomic<Type> *ptr, Type *oldValue, Type newValue) noexept:
ptr->compare_exchange_strong(*oldValue, newValue)를 돌려준다.bool std::atomic_compare_exchange_weak(_explicit)(std::atomic<Type> *ptr, Type *oldValue, Type newValue) noexept:
ptr->compare_exchange_weak(*oldValue, newValue)를 돌려준다.Type std::atomic_exchange(_explicit)(std::atomic<Type> *ptr, Type newValue) noexept:
ptr->exchange(newValue)를 돌려준다.
void std::atomic_init(std::atomic<Type> *ptr, Type init) noexept:
init을*ptr에 비-원자적으로 저장한다.ptr이 가리키는 객체는 기본으로 생성해야 한다. 뿐만 아니라 어떤 멤버 함수도 거기에 호출되어 있으면 안된다. 이 함수는memory_order매개변수가 있다.
bool std::atomic_is_lock_free(std::atomic<Type> const *ptr) noexept:
ptr->is_lock_free()을 돌려준다. 이 함수는memory_order매개변수가 없다.
Type std::atomic_load(_explicit)(std::atomic<Type> *ptr) noexept:
ptr->load()을 돌려준다.void std::atomic_store(_explicit)(std::atomic<Type> *ptr, Type value) noexept:
ptr->store(value)를 호출한다.
위에 언급한 자유 함수 외에도 atomic<Integral> 유형은 다음의 자유 멤버 함수도 제공한다.
Integral std::atomic_fetch_add(_explicit)(std::atomic<Integral> *ptr, Integral value) noexcept:
ptr->fetch_add(value)을 돌려준다.Integral std::atomic_fetch_sub(_explicit)(std::atomic<Integral> *ptr, Integral value) noexcept:
ptr->fetch_sub(value)를 돌려준다.Integral std::atomic_fetch_and(_explicit)(std::atomic<Integral> *ptr, Integral mask) noexcept:
ptr->fetch_and(value)를 돌려준다.Integral std::atomic_fetch_or(_explicit)(std::atomic<Integral> *ptr, Integral mask) noexcept:
ptr->fetch_or(value)를 돌려준다.Integral std::atomic_fetch_xor(_explicit)(std::atomic<Integral> *ptr, Integral mask) noexcept:
ptr->fetch_xor(mask)를 돌려준다.n개의 원소를 가진 배열이 있다면 다음과 같이 작동한다.
이 알고리즘을 멀티-쓰레드 알고리즘으로 손쉽게 변환할 수 있는 듯 보인다.
void quicksort(Iterator begin, Iterator end)
{
if (end - begin < 2) // 원소가 2 미만이면
return; // 작업 완료
Iter pivot = partition(begin, end); // 축 원소를 가리키는
// 반복자를 결정한다.
thread lhs(quicksort, begin, pivot); // 왼쪽 부-배열에서
// 쓰레드를 시작한다.
thread rhs(quicksort, pivot + 1, end); // 그리고 오른쪽 부-배열에서
// 쓰레드를 시작한다.
lhs.join();
rhs.join(); // 작업 끝
}
불행하게도 이 접근법은 좀 큰 배열에 대해서는 작동하지 않는다. 운영 체제가 준비해 준 것보다 더 많은 쓰레드가 시작되는 쓰레드 과잉생성(overpopulation)이라는 현상 때문이다. 그런 경우 자원이 잠시 부족함이라는 예외가 던져진다. 그리고 프로그램은 끝난다.
쓰레드 과잉 문제는 작업자 풀을 사용하면 피할 수 있다. 여기에서 각 `작업자'는 쓰레드이다. 이 경우 (부)배열 하나를 처리할 책임이 있다. 그러나 내포된 호출은 책임지지 않는다. 작업자 풀은 일정관리자(scheduler)가 제어한다. 부-배열을 정렬하라는 요청을 받아 과업이 없는 다음 작업자에게 건넨다.
이 절에서 개발된 예제 프로그램의 핵심 데이터 구조는 std::pairs 큐이다. 이 큐는 정렬될 배열의 반복자들을 담고 있다 (그림 23). 프로그램 소스는 이 책의 yo/threading/examples/multisort 디렉토리에 있다. 두 개의 큐가 사용된다. 하나는 과업-큐로서 이 큐는 구분해야 할 부문자열의 반복자들을 받는다. 새 쓰레드를 (위의 예제에서 lhs와 rhs 쓰레드를) 곧바로 기동하는 대신에 정렬될 범위를 과업-큐에 밀어 넣는다. 다른 큐는 작업-큐이다. 원소들은 과업-큐로부터 작업-큐로 이동된다. 거기에서 작업 쓰레드에 의하여 처리된다.
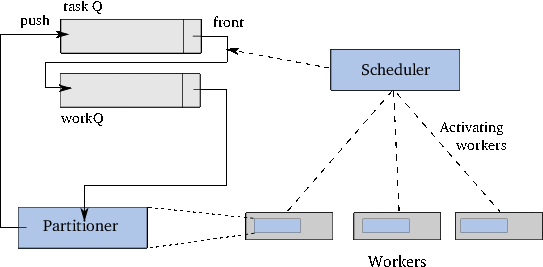
프로그램의 main 함수는 작업반을 가동하고 데이터를 읽고 begin과 end 반복자 사이의 배열을 과업 큐에 밀어 넣는다. 그리고 일정관리자를 기동시킨다. 일정관리자가 끝나면 정렬된 배열을 화면에 보여준다.
int main()
{
workForce(); // 작업자 쓰레드를 기동한다.
readData(); // 데이터를 vector<int> g_data 안에 읽어 들인다.
g_taskQ.push( // 메인 작업을 준비한다.
Pair(g_data.begin(), g_data.end())
);
scheduler(); // g_data를 정렬한다.
display(); // 정렬된 원소들을 보여준다.
}
작업반(workforce)은 한 무더기의 분리된 쓰레드로 구성된다. 쓰레드마다 작업자를 대표하며, void worker 함수에 구현되어 있다. 작업자 쓰레드는 갯수가 고정되어 있기 때문에 과잉 생성은 일어나지 않는다. 배열이 정렬되고 프로그램이 끝나면 분리된 이 쓰레드들도 그와 함께 끝난다.
for (size_t idx = 0; idx != g_sizeofWorkforce; ++idx)
thread(worker).detach();
정렬할 부-배열이 있는 한, 일정관리자는 계속된다. 이 경우 과업 큐의 맨 앞(front) 원소는 작업 큐로 이동한다. 이러면 작업자의 큐 크기가 줄어들고 다음 작업자를 위해 할당을 준비한다. 이제 일정관리자는 작업자가 준비될 때까지 기다린다. 작업자가 준비되면 대기중인 할당 작업중 하나가 고지되고 일정관리자는 다음 과업을 기다린다.
void scheduler()
{
while (newTask())
{
g_workQ.rawPushFront(g_taskQ);
g_workforce.wait(); // 작업자가 준비될 때까지 기다린다.
g_worker.notify_all(); // 작업자 활성화
}
}
newTask 함수는 과업 큐가 비어 있는지만 점검한다. 그렇다면 그리고 현재 부-배열을 정렬하느라 바쁜 작업자가 하나도 없다면 배열의 정렬이 완료된 것이다. 그리고 newTask는 false를 돌려줄 수 있다. 과업 큐가 비어 있지만 작업자는 여전히 바쁘다면 부-배열의 새 차원을 작업자가 과업 큐에 배치하고 있다는 뜻이다. 작업자가 활성화되어 있으면 Semaphore g_workforce의 크기는 작업량보다 작거나 같아야 한다.
bool wip()
{
return g_workforce.size() != g_sizeofWorkforce;
}
bool newTask()
{
bool done;
unique_lock<mutex> lk(g_taskMutex);
while ((done = g_taskQ.empty()) && wip())
g_taskCondition.wait(lk);
return not done;
}
분리된 작업 쓰레드는 각자 계속 회돌이를 수행한다. 회돌이에서 일정관리자의 고지를 기다린다. 고지를 받으면 작업 큐로부터 과업을 할당받는다. 그리고 작업에 지정된 부-배열을 분할한다. 분할 작업으로 인해 새 과업이 시작될 수도 있다. 이 일이 끝나면 작업자는 작업을 완수한 것이다. 작업 능력을 증가시키며 일정관리자에게 모든 과업이 수행되었는지 확인하라고 고지한다.
void worker()
{
while (true)
{
g_worker.wait(); // 조치를 기다린다.
partition(g_workQ.popFront());
g_workforce.notify_all();
lock_guard<mutex> lk(g_taskMutex);
g_taskCondition.notify_one();
}
}
두 원소보다 작은 부-배열은 더 나눌 필요가 없다. 더 큰 부-배열은 모두 첫 원소에 상대적으로 분할된다. std::partition 총칭 알고리즘이 이 일에 딱 맞춤이다. 그러나 축 자체가 분할할 배열의 원소이면 축의 최종 위치는 결정할 수 없다. 최종 위치는 축과 같은 일련의 원소중 어디에서든 발견된다. 그렇지만 필요한 두개의 부-배열은 쉽게 생성할 수 있다.
std::partition를 호출한다. 배열의 나머지 원소들을 분할한다. 적어도 배열의 첫 원소보다 큰 일련의 원소들 중 첫 원소를 가리키는 mid를 돌려준다.
mid - 1이 가리키는 원소들과 바꾼다.
array.begin()에서 mid - 1까지 (축보다 작은 원소들), 그리고 mid부터 array.end()까지 (적어도 축보다 큰 원소들).
void partition(Pair const &range)
{
if (range.second - range.first < 2)
return;
auto rhsBegin = partition(range.first + 1, range.second,
bind2nd(less<int>(), *range.first));
auto lhsEnd = rhsBegin - 1;
swap(*range.first, *lhsEnd);
pushTask(range.first, lhsEnd);
pushTask(rhsBegin, range.second);
}
그런 공유 상태를 담고 있는 객체를 비동기 반환 객체라고 부른다. 그렇지만 멀티 쓰레드의 성격 때문에 쓰레드는 비동기 반환 객체의 결과를 너무 이르게 요청할 수도 있다. 그러면 요청 쓰레드는 멈추어서 결과를 기다린다. 비동기 반환 객체는 wait와 get 멤버를 제공한다. 각각 결과를 받을 때까지 기다려서 비동기 결과를 생산한다. 결과를 사용할 수 있음을 알려주는 문구는 `공유 상태가 준비되었음'이다.
공유 상태는 비동기 제공자가 준비한다. 비동기 제공자는 그냥 결과를 공유 상태에 제공하는 객체 또는 함수이다. 공유 상태를 준비한다는 것은 비동기 제공자가
wait와 같이 정지되어 있는 멤버를 반환한다.
공유 상태가 준비되면 안에 값이나 객체 또는 예외가 담겨 있어서 객체들이 접근하여 열람할 수 있다. 공유 상태가 준비되기를 기다리는 동안에 공유 상태에 저장될 값이나 예외가 계산된다. 여러 쓰레드가 같은 공유 상태에 접근하려고 할 때 동기화 메커니즘을 사용하여 접근-충돌을 방지해야 한다 (예를 들어, 상호배제. 20.3절).
공유 상태를 참조로 보유한 비동기 반환 객체나 비동기 제공자의 갯수를 추적 유지하기 위하여 공유 상태는 참조 횟수 세기를 사용한다. 이 반환 객체와 제공자는 공유 상태를 참조로 풀 수 있다 (`공유 상태를 놓아준다.). 이런 일은 반환 객체나 제공자가 공유 상태에 대한 마지막 참조를 가지고 있고 그 공유 상태가 파괴될 때 일어난다.
반면에 비동기 제공자는 공유 상태를 포기할 수도 있다. 그 경우 제공자는 연속적으로
std::future_error 유형의 예외 객체와 std::broken_promise 에러 조건을 자신의 공유 상태에 저장한다.
std::future 클래스는 비동기 반환 객체이다 (다음 절 참조). std::async (20.11절) 함수 가족과 std::packaged_task 클래스의 객체들 (20.12절) 그리고 std::promise로 만들 수 있다 (20.13절).
join 멤버를 호출한 쓰레드는 부-쓰레드가 끝날 때까지 기다려야 할 수도 있다.
기다리는 것은 달갑지 않은 일이다. 마냥 기다리는 대신에 쓰레드는 다른 일을 할 수도 있다. 미래의 어느 시점에 부-쓰레드가 돌려주는 결과를 받아보는 편이 낫다.
사실, 쓰레드 사이에 데이터를 교환하는 것은 결코 쉽지 않다. 공유 변수와 잠금 그리고 상호배제를 사용해야 데이터 부패를 막을 수 있기 때문이다. 잠금을 사용하고 기다리기보다 비동기적인 과업을 시작할 수 있으면 좋을 것이다. 그러면 미래의 어느 시점에 결과가 필요할 때 그 시작 쓰레드는 (또는 다른 쓰레드들도) 결과를 모을 수 있다. 데이터 잠금이나 대기 시간에 관하여 걱정할 필요가 없이 말이다. 이와 같은 상황에 C++는 std::future 클래스를 제공한다.
std::future 클래스를 사용하기 전에 <future> 헤더를 포함해야 한다.
std::future 클래스 템플릿의 객체는 비동기적으로 실행된 과업들이 생산한 결과들을 담는다. std::future 클래스는 클래스 템플릿이다. 템플릿 유형은 비동기적으로 실행된 과업이 돌려준 결과의 유형을 지정한다. 이 유형은 void일 수 있다.
반면에 비동기적으로 실행된 과업은 예외를 던질 수 있다 (작업 포기). 그 경우에 future 객체는 반환 값을 (즉, 비동기적으로 실행된 과업이 돌려준 값을) 요구할 때 그 예외를 받아서 다시 되던진다.
이 절은 future 클래스 템플릿의 멤버들을 기술한다. future 객체는 보통 std::async 공장 함수가 돌려주는 익명의 future 객체를 통하여 초기화된다. 또는 std::packaged_task 그리고 std::promise 클래스의 get_future 멤버를 통하여 초기화된다 (다음 절에 소개함). std::future 객체를 사용하는 예제는 다음 절에 보여준다.
강력 유형의 std::future_status 열거체의 값을 돌려주는 future의 멤버가 있다. 이 열거체는 세 개의 심볼 상수 future_status::ready와 future_status::timeout 그리고 future_status::deferred를 정의한다.
에러 조건은 std::future_error 예외를 통하여 반환된다. 이 에러 조건은 강력 유형의 std::future_errc 열거체의 값으로 나타낸다 (다음 절에 다룸).
future 클래스 자체는 다음 생성자를 제공한다.
future():
기본 생성자이다. 공유 결과를 참조하지 않는future객체를 생성한다.valid멤버는false를 돌려준다.
future(future &&tmp) noexcept:
이동 생성자를 사용할 수 있다.valid멤버는 이동 생성자를 호출하기 전에tmp.valid()가 돌려 주었을 값을 돌려준다. 이동 생성자를 호출한 후에tmp.valid()는false를 돌려준다.
future 클래스는 복사 생성자나 중복정의 할당 연산자가 없다.
다음은 std::future 클래스의 멤버들이다.
future &operator=(future &&tmp):
이동 할당 연산자는tmp객체로부터 정보를 얻는다. 이 다음에tmp.valid()는false를 돌려준다.
std::shared_future<ResultType> share() &&:
std::shared_future<ResultType>을 돌려준다 (20.10절). 이 함수를 호출한 후에future의valid멤버는false를 돌려준다.
ResultType get():
먼저wait함수가 호출된다 (아래 참고).wait함수가 돌아오면 연관된 비동기 과업이 돌려준 결과가 반환된다.future<Type>를 지정하면Type이 이동 할당을 지원할 경우 반환 값은 이동된 공유 값이다. 그렇지 않으면 사본이 반환된다.future<Type &>를 지정하면Type &이 반환되고future<void>를 지정하면 아무 것도 반환되지 않는다. 그 공유 값이 예외이면 반환되지 않고 예외를 던진다. 이 멤버를 호출한 후에future객체의valid멤버는false를 돌려준다.
bool valid() const:
valid가 호출된 (future) 객체가 비동기 과업이 반환한 객체를 참조하면true를 돌려준다.valid가false를 돌려주면future객체가 존재하는 것이다. 그러나valid는 물론이고 그의 소멸자와 이동 생성자도 안전하게 호출할 수 있다.valid가false를 돌려주는 동안에 다른 멤버들을 호출하면std::future_error예외가 던져진다. 값은future_errc::no_state이다.
void wait() const:
쓰레드는 연관된 비동기 과업이 생산한 결과를 사용할 수 있을 때까지 정지된다.
std::future_status wait_for(chrono::duration<Rep, Period> const &rel_time) const:
이 멤버 템플릿은 템플릿 유형Rep와Period를 실제로 지정된 지속시간으로부터 파생시킨다 (20.1.2항). 결과에 지연된 함수가 들어 있다면 아무 일도 일어나지 않는다. 그렇지 않으면wait_for는 결과를 사용할 수 있을 때까지 또는rel_time에 지정된 시간이 경과할 때까지 정지된다. 가능한 반환 값들은 다음과 같다.
future_status::deferred: 결과에 지연 함수가 포함되어 있을 경우;future_status::ready: 결과를 사용할 수 있을 경우;future_status::timeoutrel_time: 지정된 시간이 경과했기 때문에 함수가 반환될 경우.
future_status wait_until(chrono::time_point<Clock, Duration> const &abs_time) const:
이 멤버 템플릿은 템플릿 유형Clock과Duration을 실제로 지정된abs_time으로부터 파생시킨다 (20.1.4항). 결과에 지연된 함수가 들어 있으면 아무 일도 일어나지 않는다. 그렇지 않으면wait_until은 결과를 사용할 수 있을 때까지 또는abs_time에 지정된 시점이 만료할 때까지 정지된다. 가능한 반환 값들은 다음과 같다.
future_status::deferred: 결과에 지연된 함수가 들어 있는 경우;future_status::ready: 결과를 사용할 수 있을 경우;future_status::timeoutabs_time: 지정된 시간이 경과했기 때문에 함수가 반환된 경우.
std::future<ResultType> 클래스는 다음 친구들을 선언한다.
std::promise<ResultType>
(20.13절), 그리고
template<typename Function, typename... Args>
std::future<typename result_of<Function(Args...)>::type>
std::async(std::launch, Function &&fun, Args &&...args);
(20.11절).
std::future 클래스의 멤버는 std::future_error 예외를 던져서 에러를 돌려줄 수 있다. 이 에러 조건들은 강력 유형의 std::future_errc 열거체의 값들로 나타낸다. 다음 심볼 상수들을 정의하고 있다.
broken_promise
future객체를 돌려 받았는데 그의 값이promise나packaged_task에 의하여 할당되지 않았다면broken_promise를 던진다. 예를 들어promise<int>클래스의 객체는get_future멤버가 돌려주는future<int>객체의 값을 설정해야 한다 (20.13절). 그러나 그렇게 하지 않으면 다음 프로그램에 보여 주듯이broken_promise예외가 던져진다.1: std::future<int> fun() 2: { 3: return std::promise<int>().get_future(); 4: } 5: 6: int main() 7: try 8: { 9: fun().get(); 10: } 11: catch (std::exception const &exc) 12: { 13: std::cerr << exc.what() << '\n'; 14: }3 번 줄에서
promise객체가 생성된다. 그러나 그의 값은 절대로 설정되지 않는다. 결과적으로 값을 생산해야 할 `약속을 깬 셈이다':main이 그 값을 열람하려고 시도하면 (줄 9)std::futue_error예외가 던져진다. 그 안에future_errc::broken_promise값이 담겨 있다
future_already_retrieved
(결국) 준비가 되어 있어야 할promise객체나packaged_task객체로부터future객체를 열람하려는 여러 시도가 있으면future_already_retrieved(`이미future가 열람되었음') 예외가 던져진다. 예를 들어:1: int main() 2: { 3: std::promise<int> promise; 4: promise.get_future(); 5: promise.get_future(); 6: }줄 3에서
std::promise객체를 정의했지만 그저 정의되어 있을 뿐이라는 사실을 주목하라: 어떤 값도 아직future에 할당되어 있지 않다. 그럼에도, 여전히 유효한 객체이다. 다시 말해 시간이 지나면 결국future는 준비가 될 것이다. 그리고future의get멤버는 값을 생산해야 한다. 그러므로 줄 4는 성공하지만 줄 5는 `이미future가 열람되었음' 예외가 던져진다.
promise_already_satisfied
promise객체에 값을 할당하려는 여러 시도가 있을 때 던져진다. 값이나exception_ptr를promise객체의future에 할당하는 일은 한 번만 일어날 수 있다. 예를 들어:1: int main() 2: { 3: std::promise<int> promise; 4: promise.set_value(15); 5: promise.set_value(155); 6: }
no_state
future객체의 (valid) 멤버 함수가 호출될 때false를 돌려주면no_state예외가 던져진다. 이런 일은 기본 생성된future객체의 멤버를 호출할 때 일어난다.promise나packaged_task유형의 객체의async공장 함수나get_future멤버가 돌려주는future객체에는no_state를 던지지 않는다. 다음은 예제이다.1: int main() 2: { 3: std::future<int> fut; 4: fut.get(); 5: }
std::future_error 클래스는 std::exception 클래스로부터 파생된다. 그리고 char const *what() const 말고도 std::error_code const &code() const 멤버도 제공한다. 이 멤버는 던져진 예외에 연관된 std::error_code 객체를 돌려준다.
std::async를) 활성화할 때 비동기적으로 호출된 함수의 반환 값은 활성 쓰레드에서 std::future 객체를 통하여 사용할 수 있다. future 객체는 또다른 쓰레드가 사용할 수 없다. 이것이 필요하면 future 객체를 std::shared_future 객체로 변환해야 한다 (이 장의 마지막 절 참조).
std::shared_future 클래스를 사용하기 전에 <future> 헤더를 포함해야 한다.
shared_future 객체를 사용할 수 있으면 그의 get 멤버를 반복적으로 호출하여 원래의 future 객체의 결과를 열람할 수 있다 (아래 참고). 다음 작은 예제에 이것을 보여준다.
1: int main()
2: {
3: std::promise<int> promise;
4: promise.set_value(15);
5:
6: auto fut = promise.get_future();
7: auto shared1 = fut.share();
8:
9: std::cerr << "Result: " << shared1.get() << '\n';
10: << "Result: " << shared1.get() << '\n';
11: << "Valid: " << fut.valid() << '\n';
12:
13: auto shared2 = fut.share();
14:
15: std::cerr << "Result: " << shared2.get() << '\n';
16: << "Result: " << shared2.get() << '\n';
17: }
줄 9와 줄 10에서 promise의 결과를 두 번 열람한다. 그러나 줄 7에서 shared_future를 얻었기 때문에 원래의 future 객체는 더 이상 연관된 공유 상태가 없다. 그러므로 shared_future를 얻으려는 또다른 시도가 있으면 (줄 13), 연관된 상태 없음(no associated state) 예외가 던져진다. 그리고 프로그램은 끝난다.
그렇지만 shared_future 객체의 여러 사본은 (서로 다른 쓰레드 사이에) 공존할 수 있다. shared_future 객체의 여러 사본이 존재할 때 연관된 비동기 과업의 결과는 시간이 지나면 정확하게 같은 시간에 준비가 된다.
future 클래스와 shared_future 클래스 사이의 관계는 unique_ptr 클래스와 shared_ptr 클래스 사이의 관계를 닮았다. 독점 포인터는 한 개의 실체만 데이터를 가리킨다. 반면에 공유 포인터는 많은 실체가 각각 같은 데이터를 가리킬 수 있다.
소멸자나 이동-할당 연산자 또는 valid 말고 valid() == false인 경우에 대하여 shared_future 객체의 멤버를 호출한 효과는 정의되어 있지 않다.
shared_future 클래스는 다음 생성자를 지원한다.
shared_future() noexcept
빈shared_future객체를 생성한다. 공유 결과를 참조하지 않는다. 이 생성자를 사용한 후에 객체의valid멤버는false를 돌려준다.
shared_future(shared_future const &other)
shared_future객체가 생성된다. (있다면)other와 같은 결과를 참조한다. 이 생성자를 사용한 후, 이 객체의valid멤버는other.valid()와 같은 값을 돌려준다.
shared_future(shared_future<Result> &&tmp) noexcept
shared_future 객체를 이동 생성한다. 이 객체는 원래tmp가 참조했던 결과들을 (있다면) 참조한다. 이 생성자를 사용한 후에valid멤버는 생성자를 요청하기 전에tmp.valid()가 돌려주는 값과 같은 값을 돌려준다. 그리고tmp.valid()는false를 돌려준다.
shared_future(future<Result> &&tmp) noexcept
shared_future 객체를 이동 생성한다. 이 객체는 원래tmp가 참조한 결과를 (있다면) 참조한다. 이 생성자를 사용한 후에 이 객체의valid멤버는 생성자를 호출하기 전에 반환된tmp.valid()와 같은 값을 돌려준다. 그리고tmp.valid()는false를 돌려준다.
이 클래스의 소멸자는 호출된 shared_future 객체를 파괴한다. 소멸자가 호출된 그 객체가 마지막 shared_future 객체라면 그리고 std::promise나 std::packaged_task가 현재 객체에 연관된 결과와 전혀 상관이 없다면 그 결과도 역시 소멸한다.
다음은 std::shared_future 클래스의 멤버이다.
shared_future& operator=(shared_future &&tmp):
이동 할당 연산자는 현재 객체의 공유 결과를 해제한다. 그리고tmp의 결과를 현재 객체에 이동 할당한다. 이동 할당 연산자를 호출한 후에 현재 객체의valid멤버는 이동 할당 연산자를 요청하기 전에tmp.valid()가 돌려주는 값과 같은 값을 돌려준다.tmp.valid()는false를 돌려준다.
shared_future& operator=(shared_future const &rhs):
할당 연산자는 현재 객체의 공유 결과를 해제한다. 그리고rhs의 결과는 현재 객체와 공유한다. 할당 연산자를 호출한 후에 현재 객체의valid멤버는tmp.valid()와 같은 값을 돌려준다.
Result const &shared_future::get() const:
(shared_future<Result &>와shared_future<void>에 대하여 특정화를 사용할 수도 있다.) 이 멤버는 공유 결과를 사용할 수 있을 때까지 기다린다. 그리고 이어서Result const &를 돌려준다.Results에 저장된 데이터에get을 통하여 접근하는 것은 동기화가 되어 있지 않음에 주목하라.Result의 데이터에 접근할 때 경쟁 조건을 피하는 것은 프로그래머의 책임이다.Result에 예외가 포함되어 있으면get이 호출될 때 그 예외를 던진다.
bool valid() const:
현재 객체가 공유 결과를 참조하면 true를 돌려준다.
void wait() const:
공유 결과를 사용할 수 있을 때까지 (즉, 연관된 비동기 과업이 결과를 생산할 때까지) 정지된다.
future_status wait_for(const chrono::duration<Rep, Period>& rel_time) const:
(템플릿 유형Rep와Period는 실제로 지정된rel_time으로부터 컴파일러가 파생시킨다.) 공유 결과에 지연된 함수가 들어 있으면 아무 일도 일어나지 않는다 (20.11절). 그렇지 않으면wait_for는 연관된 비동기 과업이 결과를 생산할 때까지 또는rel_time에 지정된 상대 시간이 경과할 때까지 정지된다.
future_status::deferred: 공유 결과에 지연된 함수가 들어 있을 경우;future_status::ready: 공유 결과를 사용할 수 있을 경우;future_status::timeout: 지정된rel_time시간이 만료했기 때문에 함수가 돌아올 경우;
future_status wait_until(const chrono::time_point<Clock, Duration>&
abs_time) const:(템플릿 유형Clock과Duration은 실제로 지정된abs_time으로부터 컴파일러가 파생시킨다.) 공유 결과에 지연된 함수가 들어 있으면 아무 일도 일어나지 않는다. 그렇지 않으면wait_until함수는 공유 결과를 사용할 수 있을 때까지 또는abs_time지정된 시간이 경과할 때까지 정지된다. 가능한 반환 값은 다음과 같다.
future_status::deferred: 공유 결과에 지연된 함수가 들어 있을 경우;future_status::ready: 공유 결과를 사용할 수 있을 경우;future_status::timeoutabs_time: 지정된 시간이 경과했기 때문에 함수가 돌아올 경우.
std::async 함수 템플릿을 다룬다. async는 비동기 작업을 시작하는 데 사용된다. 호출 쓰레드에 값을 (또는 void를) 돌려준다. 이 기능은 std::thread 클래스만 사용해서는 실현하기 어렵다.
async 함수를 사용하기 전에 <future> 헤더를 포함해야 한다.
std::thread 클래스의 편의기능을 사용하여 쓰레드를 시작하기 전에 최초의 기동 쓰레드는 어느 시점에 공통적으로 join 메쏘드를 호출한다. 그 시점에 그 기동 쓰레드는 완료되어 있어야 한다. 그렇지 않으면 실행은 join이 돌아올 때까지 정지된다. 이 과정이 보통 합리적이기는 하지만 언제나 그런 것은 아니다. 그 쓰레드를 구현한 함수가 값을 돌려줄 수도 있고, 또는 예외를 던질 수도 있다.
그런 경우 join을 사용할 수 없다. 예외가 쓰레드를 떠나면 프로그램이 끝나기 때문이다. 다음은 예제이다.
1: void thrower()
2: {
3: throw std::exception();
4: }
5:
6: int main()
7: try
8: {
9: std::thread subThread(thrower);
10: }
11: catch (...)
12: {
13: std::cerr << "Caught exception\n";
14: }
3번 줄에서 thrower는 예외를 던지고 쓰레드를 떠난다. 이 예외는 main의 try-블록에서 잡지 못한다. 다른 쓰레드에 정의되어 있기 때문이다. 결과적으로 프로그램은 종료한다.
std::async를 사용하면 이 시나리오는 일어나지 않는다. async는 새로 비동기 과업을 시작할 수 있다. async가 돌려주는 std::future 객체로부터 활성 쓰레드는 비동기 과업을 구현한 함수의 반환 값이나 또는 그 함수를 떠나는 예외를 열람할 수 있다. 기본적으로, async는 std::thread를 사용하여 쓰레드가 시작하는 방식과 비슷하게 호출된다. 거기에 함수를 건네고 선택적으로 그 함수에게 전달될 인자를 건넨다.
비동기 과업을 구현한 함수를 첫 인자로 건넬 수는 있지만 async의 첫 인자는 강력 유형의 std::launch 열거체의 값이 될 수도 있다.
enum class launch
{
async,
deferred
};
launch::async를 건네면 비동기 과업이 즉시 시작한다. launch::deferred를 건네면 비동기 과업이 지연된다. std::launch를 지정하지 않으면 기본 값 launch::async | launch::deferred가 사용되고 자유롭게 구현을 허용하며 결과적으로 보통 비동기 과업의 실행이 지연된다.
그래서 다음은 다시 첫 번째 예제이다. 이 번에는 async를 사용하여 부-쓰레드를 시작한다.
1: bool fun()
2: {
3: return std::cerr << " hello from fun\n";
4: }
5: int exceptionalFun()
6: {
7: throw std::exception();
8: }
9:
10: int main()
11: try
12: {
13: auto fut1 = std::async(std::launch::async, fun);
14: auto fut2 = std::async(std::launch::async, exceptionalFun);
15:
16: std::cerr << "fun returned " << std::boolalpha << fut1.get() << '\n';
17: std::cerr << "exceptionalFun did not return " << fut2.get() << '\n';
18: }
19: catch (...)
20: {
21: std::cerr << "caught exception thrown by exceptionalFun\n";
22: }
이제 쓰레드들은 즉시 시작한다. 그러나 결과를 13번 줄 근처에서 사용할 수 있음에도, 던져진 예외는 프로그램을 끝내지 않는다. 첫 쓰레드의 반환 값은 16번 줄에서 사용할 수 있다. 두 번째 쓰레드가 던진 예외는 그냥 메인의 try-블록에서 나포된다 (줄 19).
함수 템플릿 async는 여러 중복정의 버전이 있다.
std::future을 돌려준다. 이 안에 함수의 반환 값이나 예외가 들어 있다.
template <typename Function, class ...Args>
std::future<
typename std::result_of< Function(Args ...) >::type
> std::async(Function &&fun, Args &&...args);
bit_or 연산자를 사용하여) std::launch 열거체의 값을 조합한 것일 수도 있다.
template <class Function, class ...Args>
std::future<typename std::result_of<Function(Args ...)>::type>
std::async(std::launch policy, Function &&fun, Args &&...args);
std::launch 값을 지정하면 두 번째 인자도 그 멤버 함수의 주소가 될 수 있다. 그 경우 (필수적인) 세 번째 인자는 그 멤버 함수의 클래스의 객체이다. 또는 객체를 가리키는 포인터이다. 나머지 인자는 그 멤버 함수에 건네진다 (아래 논평도 참고).
async를 호출할 때 std::launch를 제외하고 모든 인자는 참조나 포인터 또는 이동-생성 객체이어야 한다.
async 함수 템플릿에 건네면 쓰레드-기동자에게 전송할 인자의 사본을 복사 생성한다.
async 함수 템플릿에 건네면 쓰레드 기동자에게 전송하기 위해 이동 생성한다.
future 클래스의 get 멤버가 호출되기 전에 실제로는 시작하지 않을 수도 있기 때문이다.)
기본 async 호출이 사용하는 기본 std::launch::deferred | std::launch::async 인자 때문에 async에 건넨 함수가 즉시 시작하지 않을 가능성이 매우 높다. launch::deferred 정책 덕분에 구현자는 프로그램이 명시적으로 함수의 결과를 요구할 때까지 실행을 연기할 수 있다. 다음 프로그램을 연구해 보자:
1: void fun()
2: {
3: std::cerr << " hello from fun\n";
4: }
5:
6: std::future<void> asyncCall(char const *label)
7: {
8: std::cerr << label << " async call starts\n";
9: auto ret = std::async(fun);
10: std::cerr << label << " async call ends\n";
11: return ret;
12: }
13:
14: int main()
15: {
16: asyncCall("First");
17: asyncCall("Second");
18: }
async가 9번 줄에서 호출되지만 fun 함수의 출력은 보이지 않는다. (기본 값으로) lauch::deferred가 사용되기 때문이다. 시스템은 요청이 있을 때까지 fun의 실행을 연기한다. 그러나 이런 일은 일어나지 않는다. async가 돌려주는 future 객체는 wait 멤버가 있다. wait 멤버가 반환되면 공유 상태를 사용할 수 있다. 다시 말해, fun 함수는 종료되어 있어야 한다. 다음은 9번 줄 다음에 ret.wait() 줄을 삽입하면 일어나는 일이다.
First async call starts
hello from fun
First async call ends
Second async call starts
hello from fun
Second async call ends
실제로 fun 함수의 평가는 결과가 필요한 시점에 요청할 수 있다. 심지어 asyncCall 함수를 호출한 후에도 요청할 수 있다. 다음 예제에 보여준다.
1: int main()
2: {
3: auto ret1 = asyncCall("First");
4: auto ret2 = asyncCall("Second");
5:
6: ret1.get();
7: ret2.get();
8: }
ret1과 ret2 std::future 객체가 생성된다. 그러나 fun 함수는 아직 평가되지 않는다. 평가는 6번 줄과 7번 줄에서 일어난다. 다음이 그 출력 결과이다.
First async call starts
First async call ends
Second async call starts
Second async call ends
hello from fun
hello from fun
std::async 함수 템플릿으로 쓰레드를 시작한다. 그의 결과를 호출 쓰레드에서 사용할 수 있게 해준다. 반면에 과업을 (thread) 준비만 할 뿐(package), 과업의 완성은 또다른 쓰레드에 맡겨야 하는 경우가 있다. 이와 같은 시나리오는 std::packaged_task 클래스의 객체를 통하여 실현된다. 이것이 바로 다음 절의 주제이다.
std::packaged_task 클래스 템플릿으로 프로그램은 함수나 함수객체를 `꾸려 넣어(package)' 그 꾸러미를 쓰레드에 건네 더 처리할 수 있다. 처리 쓰레드는 꾸려 넣어진 그 함수를 호출하고 거기에 인자를 (있다면) 건넨다. 함수가 완료되면 packaged_task에 future가 준비되므로 프로그램은 그 결과를 열람하여 쓰레드 사이에 전송할 수 있다.
packaged_task 클래스 템플릿을 사용하기 전에 <future> 헤더를 포함해야 한다.
이 클래스의 인터페이스를 기술하기 전에 먼저, 예제를 하나 살펴 보자. 어떻게 packaged_task를 사용할 수 있는지 알아 보자. packaged_task의 본질을 기억하라. 프로그램의 일부에 또다른 쓰레드가 완료할 과업을 꾸려넣고(packages) 그 프로그램은 어느 시점에서 완료된 과업의 결과를 필요로 한다.
여기에서 무슨 일이 일어나는지 알아 보기 위하여, 먼저 실세계에서 비슷한 예를 살펴 보자. 가끔 필자는 차를 정비소에 맡긴다. 이 경우 `package'는 차에 대한 상세이다. 어떤 식으로 정비할지는 제조사와 차종이 결정한다. 필자의 이웃도 차가 있다. 역시 가끔 정비를 받을 필요가 있다. 이 역시 정비소 입장에서는 `package'가 된다. 적절한 때에 필자와 이웃은 차를 정비소로 가져 간다 (즉, 꾸러미를 또다른 쓰레드에 건넨다.). 정비소는 차를 정비한다 (즉, packaged_task에 저장된 함수들을 호출한다 [하는 일은 차의 종류에 따라 달라진다]). 그리고 그와 연관된 조치를 수행한다 (예를 들어 필자와 이웃의 차가 정비되었음을 등록하거나, 교체 부품을 주문하거나 등등). 그 동안 이웃과 필자는 각자의 일을 한다 (별도의 쓰레드가 실행되고 있는 동안에도 프로그램은 계속된다.). 그러나 날이 저물면 다시 차를 찾아오고 싶다 (즉, packaged_task에 연관된 결과를 얻고 싶다.). 이 예에서 공통된 결과는 지불해야 할 정비소의 청구서이다 (프로그램은 packaged_task의 결과를 얻는다.).
다음은 작은 C++ 프로그램이다. packaged_task의 사용법을 보여준다 (필요한 헤더와 using namespace std 서술문이 이미 지정되어 있다고 가정한다):
1: mutex carDetailsMutex;
2: condition_variable condition;
3: string carDetails;
4: packaged_task<size_t (std::string const &)> serviceTask;
5:
6: size_t volkswagen(string const &type)
7: {
8: cout << "performing maintenance by the book for a " << type << '\n';
9: return type.size() * 75; // 견적
10: }
11:
12: size_t peugeot(string const &type)
13: {
14: cout << "performing quick and dirty maintenance for a " << type << '\n';
15: return type.size() * 50; // 견적
16: }
17:
18: void garage()
19: {
20: while (true)
21: {
22: unique_lock<mutex> lk(carDetailsMutex);
23: while (carDetails.empty())
24: condition.wait(lk);
25:
26: cout << "servicing a " << carDetails << '\n';
27: serviceTask(carDetails);
28: carDetails.clear();
29: }
30: }
31:
32: int main()
33: {
34: thread(garage).detach();
35:
36: while (true)
37: {
38: string car;
39: if (not getline(cin, car) || car.empty())
40: break;
41: {
42: lock_guard<mutex> lk(carDetailsMutex);
43: carDetails = car;
44: }
45: serviceTask = packaged_task<size_t (string const &)>(
46: car[0] == 'v' ? volkswagen : peugeot
47: );
48: auto bill = serviceTask.get_future();
49: condition.notify_one();
50: cout << "Bill for servicing a " << car <<
51: ": EUR " << bill.get() << '\n';
52: }
53: }
packaged_task: serviceTask가 함수(또는 함수객체)로 초기화된다. string을 기대하고 size_t를 돌려준다.
volkswagen과 peugeot는 정비소에 들어오는 차의 유형에 따라 수행할 과업을 나타낸다. 아마도 견적서를 교부할 것이다.
void garage 함수를 정의한다. 정비를 위해 차가 들어 올 때 정비소에서 수행할 조치를 정의한다. 이 조치들은 줄 34부터 따로따로 분리된 쓰레드에 의하여 수행된다. 회돌이 안에서 쓰레드는 carDetailsMutex에 잠금을 얻을 때까지 기다린다. 그리고 carDetails는 이제 더 이상 비어 있지 않다. 이제 줄 27에서 쓰레드는 carDetails를 packaged_task `serviceTask'에 건넨다. 이것 만으로는 packaged_task의 함수를 호출하는 것과 동일하지 않지만 결국 그의 함수는 호출될 것이다. 이 시점에서 packaged_task는 그의 함수의 인자를 받고 마침내 그의 환경구성 함수에 전달될 것이다. 마지막으로 줄 28에서 carDetails를 지우고 다음 요청에 대비한다.
main을 정의한다.
garage를 실행한다.
다음으로 프로그램은 메인 회돌이를 시작한다 (줄 36-52):
packaged_task가 다음으로 생성된다 (줄 45).
future에 저장된 결과를 열람한다. 이 시점에서 future가 준비되어 있지 않을 수 있지만 future 객체 자체는 존재하며 그것이 그냥 청구서로 반환된다.
다음으로 어떤 일이든 일어날 수 있다. 프로그램은 어떤 조치든 수행할 수 있지만 결국 정비소가 생산한 결과를 요청한다.
bill.get()를 호출하여 결과를 얻는다. 이 때까지도 여전히 차가 정비 중이면 청구서는 아직 준비되지 않은 것이다. 그리고 bill.get()은 청구서가 준비될 때까지 정지된다.
이제 packaged_task를 사용하는 프로그램의 예제를 보았으므로 인터페이스를 살펴보자. packaged_task는 클래스 템플릿임을 주목하라. 그의 템플릿 유형의 매개변수는 packaged_task 객체가 수행하는 과업을 구현한 함수나 함수객체의 원형을 지정한다.
생성자와 소멸자:
packaged_task() noexcept:
기본 생성자는 packaged_task 객체를 생성한다. 이 객체는 함수나 공유 상태에 연관되어 있지 않다.
explicit packaged_task(ReturnType(Args...) &&function):
packaged_task는 함수나 함수객체를 생성한다.Args...유형의 인자를 기대하고,ReturnType유형의 값을 돌려준다.packaged_task클래스 템플릿은ReturnType (Args...)을 그의 템플릿 유형의 매개변수로 지정한다. 생성된 객체는 공유 상태와function의 (이동 생성된) 사본을 보유한다. 선택적으로Allocator을 두 번째 템플릿 유형의 매개변수로 지정할 수있다. 이 경우, 첫 두 인자는std::allocator_arg_t, Allocator const &alloc이다.std::allocator_arg_t유형은 생성 선택의 모호성을 없애기 위해 도입된 유형이다. 그리고 그냥std::allocator_arg_t()으로 지정할 수도 있다. 이 생성자는std::bad_alloc예외를 던질 수 있다. 또는function의 이동 생성자나 복사 생성자가 던진 예외를 던질 수 있다.
packaged_task(packaged_task &&tmp) noexcept:
이동 생성자는 기존의 공유 상태를tmp로부터 새로 생성된 객체로 이동시킨다.tmp으로부터 공유 상태를 제거한다.
~packaged_task():객체의 공유 상태를 (있다면) 폐기한다
멤버 함수:
future<ReturnType> get_future():
현재 객체의 공유 상태를 관리하는std::future객체를 돌려준다. 에러가 있으면future_error예외가 던져진다. 그 안에 든 것은주의하자. 객체의 공유 상태를 함께 공유하면 어떤
future_already_retrievedget_future: 현재 객체와 같은 공유 상태를 보유하는packaged_task객체에 이미 호출되었을 경우;no_state: 현재 객체에 공유 상태가 없을 경우.future객체도 이 객체의 과업이 돌려준 결과에 접근할 수 있다.
void make_ready_at_thread_exit(Args... args):
현재 쓰레드에 연관된 쓰레드 저장소의 객체들이 모조리 파괴되는 순간, 현재 쓰레드가 종료할 때 void operator()(Args... args)를 호출한다 (아래 참고).
packaged_task &operator=(packaged_task &&tmp):
이동 할당 연산자는 먼저 현재 객체의 공유 상태를 (있다면) 해제한다. 그 다음에 현재 객체와 tmp를 서로 바꾼다.
void operator()(Args... args):
args인자들은 현재 객체가 저장한 과업에 전송된다. 저장된 과업이 돌아올 때 그의 반환 값은 현재 객체의 공유 상태에 저장된다. 그렇지 않으면 과업이 던진 예외는 모두 객체의 공유 상태에 저장된다. 그 다음에 객체의 공유 상태를 준비한다. 그리고 함수 안에서 객체의 공유 상태가 준비되기를 기다리는 정지되어 있던 쓰레드들이 해제된다. 에러가 있으면future_error예외가 던져진다. 그 안에 든 것은이 멤버를 호출하면
promise_already_satisfied공유 상태가 이미 준비가 되어 있는 경우;no_state현재 객체에 공유 상태가 없는 경우.(shared_)future객체의 멤버 함수를 호출하는 것과 동기화되어packaged_task결과에 접근할 수 있다.
void reset():
공유 상태를 폐기하고 현재 객체를packaged_task(std::move(funct))으로 초기화한다.funct는 객체가 저장한 과업이다. 이 멤버는 다음 예외를 던질 수 있다.
- 새 공유 상태에 대하여 메모리를 할당할 수 없으면
bad_alloc예외를 던진다.- 공유 상태에 저장된 과업의 이동 생성자가 던지는 모든 예외;
- 현재 객체에 공유 상태가 없을 경우
no_state와 함께future_error에러가 일어난다.
void swap(packaged_task &other) noexcept:
현재 객체의 공유 상태와 저장된 과업을 other와 서로 바꾼다.
bool valid() const noexcept:
현재 객체에 공유 상태가 있으면true를 돌려주고 그렇지 않으면false를 돌려준다.
packaged_task 객체에 대하여 작동하는 다음의 비-멤버 (자유) 함수를 사용할 수 있다.
void swap(packaged_task<ReturnType(Args...)> &lhs,
packaged_task<ReturnType(Args...)> &rhs) noexcept
lhs.swap(rhs)와 같이 호출한다std::packaged_task와 std::async 외에도 std::promise 클래스 템플릿을 사용하면 별도의 쓰레드로부터 결과를 얻을 수 있다.
promise 클래스 템플릿을 사용하기 전에 <future> 헤더를 포함해야 한다.
promise 클래스는 또다른 쓰레드로부터 결과들을 얻는 데 유용하다. 동기화를 요구하지 않는다. 다음 프로그램을 연구해 보자:
void compute(int *ret)
{
*ret = 9;
}
int main()
{
int ret = 0;
std::thread(compute2, &ret).detach();
cout << ret << '\n';
}
이 프로그램은 값을 0으로 보여줄 가능성이 높다. 분리된 쓰레드가 작업을 완료할 기회를 갖기도 전에 cout 서술문이 이미 실행되고 있다. 이 예제에서 비-분리 쓰레드를 사용하고 그 쓰레드의 join 멤버를 사용하면 문제는 쉽게 풀린다. 그러나 여러 쓰레드가 사용되면 join을 호출한 횟수만큼 이름있는 쓰레드가 요구된다. 대신에 promise를 사용하는 편이 더 좋을 것이다.
1: void compute1(promise<int> &ref)
2: {
3: ref.set_value(9);
4: }
5:
6: int main()
7: {
8: std::promise<int> p;
9: std::thread(compute, ref(p)).detach();
10:
11: cout << p.get_future().get() << '\n';
12: }
이 예제에도 분리 쓰레드가 사용된다. 그러나 그의 결과는 최종 목적 변수에 직접적으로 할당되는 대신에 미래에 정보를 얻기 위한 참조로 promise 객체에 보관된다. promise 객체 안에 future 객체가 있고 그 안에 계산된 값이 들어 있다. future의 get 멤버는 future가 준비될 때까지 정지된다. 그 시점에 결과를 사용할 수 있다. 그 때까지 분리된 쓰레드는 완료될 수도 미완료일 수도 있다. 이미 작업을 마쳤다면 get은 즉시 반환된다. 그렇지 않으면 약간의 지연이 있을 것이다.
promise는 추가로 동기화 서술문을 사용할 필요없이 멀티 쓰레드 버전의 알고리즘을 구현할 때 유용하다. 예를 들어 행렬 곱셈을 생각해 보자. 결과 곱 행렬의 각 원소는 두 벡터의 내부 곱으로 계산된다. 왼쪽 피연산자의 행과 오른쪽 피연산자의 열의 내부 곱이 결과 행렬의 [row][column]의 원소가 된다. 결과 행렬의 각 원소는 다른 원소와 독립적으로 계산되기 때문에 멀티 쓰레드 구현이 딱맞춤이다. 다음 예제에서 innerProduct (줄 4..11) 함수는 결과를 promise 객체에 남긴다.
1: int m1[2][2] = {{1, 2}, {3, 4}};
2: int m2[2][2] = {{3, 4}, {5, 6}};
3:
4: void innerProduct(promise<int> &ref, int row, int col)
5: {
6: int sum = 0;
7: for (int idx = 0; idx != 2; ++idx)
8: sum += m1[row][idx] * m2[idx][col];
9:
10: ref.set_value(sum);
11: }
12:
13: int main()
14: {
15: promise<int> result[2][2];
16:
17: for (int row = 0; row != 2; ++row)
18: {
19: for (int col = 0; col != 2; ++col)
20: thread(innerProduct, ref(result[row][col]), row, col).detach();
21: }
22:
23: for (int row = 0; row != 2; ++row)
24: {
25: for (int col = 0; col != 2; ++col)
26: cout << setw(3) << result[row][col].get_future().get();
27: cout << '\n';
28: }
29: }
각각의 내부 곱마다 (익명으로 분리된) 별도의 쓰레드에서 계산한다 (줄 17..21). 실행 시간이 허용하자마자 바로 실행된다. 쓰레드들이 일을 마칠 때쯤이면 결과로 나온 내부 곱을 promise 객체 안의 future 객체로 열람할 수 있다. future 객체의 get 멤버는 결과가 실제로 준비될 때까지 정지되며 그 멤버들을 연속으로 호출하기만 하면 결과 행렬을 보여줄 수 있다 (줄 23..28).
그래서 promise로 쓰레드를 사용하여 값을 계산할 수 있다 (예외는 아래 참고). 그러면 미래의 어느 시점에 또다른 쓰레드가 그 값을 모을 수 있다. promise는 여전히 살아 있을 수 있다. 결과적으로 쓰레드와 그 쓰레드를 기동한 프로그램 사이에 더 이상의 동기화는 필요하지 않다. promise 객체에 값이 아니라 예외가 들어 있으면 future 객체의 get 멤버는 저장된 예외를 되던진다.
다음은 promise 클래스의 인터페이스이다. promise는 클래스 템플릿이라는 것을 눈여겨보라. 그의 템플릿 유형의 매개변수 ReturnType는 열람할 std::future의 템플릿 유형의 매개변수를 지정한다.
생성자와 소멸자:
promise():
기본 생성자는 공유 상태를 담고 있는promise객체를 생성한다. 공유 상태는get_future로 반환할 수 있지만 (아래 참고) 그future객체가 아직 준비가 안 되어 있을 수 있다.
promise(promise &&tmp) noexcept:
이동 생성자는promise객체를 생성한다.tmp의 공유 상태의 소유권을 새로 생성된 객체에 넘긴다. 객체가 생성된 후에tmp는 더 이상 공유 상태가 없다.
~promise():
객체의 공유 상태가 (있다면) 폐기된다.
멤버 함수:
std::future<ReturnType> get_future():
std::future현재 객체의 공유 상태를 공유하는 객체를 돌려준다. 에러가 있으면future_error예외가 던져진다. 예외 안에는주의하라. 그 객체의 공유 상태를 공유하는
get_future가 현재 객체와 같은 공유 상태를 담고 있는packaged_task객체에 이미 호출되었다면future_already_retrieved예외가 들어 있다.- 현재 객체가 공유 상태가 없다면
no_state예외가 들어 있다.future는 모두 그 객체의 과업이 돌려주는 결과에 접근할 수 있다.
promise &operator=(promise &&rhs) noexcept:
이동 할당 연산자는 먼저 현재 객체의 공유 상태를 (있다면) 풀어 준다. 그 다음에 현재 객체와 tmp를 서로 바꾼다.
void promise<void>::set_value():
아래 마지막에 있는 set_value 멤버의 설명 참고;
void set_value(ReturnType &&value):
아래 마지막에 있는 set_value 멤버의 설명 참고;
void set_value(ReturnType const &value):
다음 멤버 함수의 설명 참고;
void set_value(ReturnType &value):
value인자가 자동으로 공유 상태에 저장된다. 그 다음 그 공유 상태도 준비가 된다. 에러가 있으면future_error예외가 던져진다. 그 안에는다른 방법으로
- 공유 상태가 이미 준비되어 있으면
promise_already_satisfied가 들어 있다.- 현재 객체에 공유 상태가 없다면
no_state가 들어 있다.value의 이동 생성자나 복사 생성자가 던지는 예외는 무엇이든 던질 수 있다.
void set_exception(std::exception_ptr obj):
Exception_ptr obj가 자동으로 공유 상태에 저장된다 (20.13.1항). 공유 상태를 준비한다. 에러가 있으면future_error예외가 더져진다. 예외 안에는
- 공유 상태가 이미 준비되어 있으면
promise_already_satisfied예외가 들어 있다.- 현재 객체에 공유 상태가 없으면
no_state예외가 들어 있다.
void set_exception_at_thread_exit(exception_ptr ptr):
ptr예외 포인터가 공유 상태에 저장된다. 공유 상태가 즉시 준비되지 않는다. 마지막 쓰레드와 연관된 쓰레드 저장소에서만 지속되는 모든 객체들이 파괴되고 현재 쓰레드가 종료할 때 공유 상태가 준비된다. 에러가 있으면future_error예외가 던져진다. 예외 안에는
- 공유 상태가 이미 준비되어 있으면
promise_already_satisfied예외가 들어 있다.- 현재 객체에 공유 상태가 없으면
no_state예외가 들어 있다.
void set_value_at_thread_exit():
아래에서 마지막 set_value_at_thread_exit 멤버의 설명 참고;
void set_value_at_thread_exit(ReturnType &&value):
아래에서 마지막 set_value_at_thread_exit 멤버의 설명 참고;
void set_value_at_thread_exit(ReturnType const &value):
다음 set_value_at_thread_exit 멤버의 설명 참고;
void set_value_at_thread_exit(ReturnType &value):
공유 상태에value를 저장한다. 즉시 공유 상태가 준비되지는 않는다. 마지막 쓰레드와 연관된 쓰레드 저장소에서만 지속되는 모든 객체들이 파괴되고 현재 쓰레드가 종료할 때 공유 상태가 준비된다. 에러가 있으면future_error예외가 던져진다. 예외 안에는
- 공유 상태가 이미 준비되어 있으면
promise_already_satisfied가 들어 있다.- 현재 객체에 공유 상태가 없으면
no_state가 들어 있다.
void swap(promise& other) noexcept:
현재 객체의 공유 상태와 other 객체의 공유 상태를 교환한다.
promise 객체에 작동한다.
void swap(promise<ReturnType> &lhs, promise<ReturnType> &rhs)
noexcept:lhs.swap(rhs)를 호출한다std::promise 클래스의 set_exception 멤버는 인자로 std::exception이 아니라 std::exception_ptr 클래스의 객체를 기대한다. 이 절은 더 자세하게 exception_ptr 클래스를 살펴 본다.
exception_ptr 클래스를 사용하기 전에 <future> 헤더를 포함해야 한다.
exception_ptr의 기본 생성자는 널-포인터로 초기화한다. 다음 코드에서 isNull 변수에 참이 설정된다.
std::exception_ptr obj;
bool isNull = obj == nullptr && obj == 0;
exception_ptr 클래스는 복사 생성자와 이동 생성자를 제공한다. 물론 할당 연산자와 복사 연산자도 제공한다.
두 개의 exception_ptr 객체가 동등한지 비교할 수 있다. 같은 예외를 참조하면 두 객체는 같다. 이동 할당은 오른쪽 피연산자가 참조하는 예외를 왼쪽 피연산자로 전송한다. 그리고 오른쪽 피연산자를 널 포인터로 바꾼다.
exception_ptr 객체가 참조하는 예외를 직접적으로 열람하는 공개 메쏘드는 없다. 그렇지만 exception_ptr 객체를 생성하거나 처리하는 자유 함수가 몇 가지 있다.
std::exception_ptr std::current_exception() noexcept:
현재 처리된 예외를 참조하는exception_ptr객체가 반환된다 (또는 현재 처리된 예외의 사본이 반환된다. 또는 현재 예외가 없으면 기본 생성된exception_ptr객체가 반환된다.). 이 함수는 기본 예외 나포자가 사용될 때 호출할 수도 있다. 예를 들어obj가std::promise객체를 참조하면 다음 코드 조각은 기본 catch 절에서 잡은 예외를obj에 할당한다.... catch (...) { obj.set_exception(std::current_exception()); }current_exception이 참조하는 예외가 반드시std::exception클래스의 객체일 필요는 없다. 어떤 유형의 객체이든 값이든 예외로 던져지면current_exception이exception_ptr로 받는다.exception_ptr객체가 참조하는 예외는 적어도 참조하는 동안은 여전히 유효하다. 연이어서current_exception을 두 번 호출하면 반환된 두 개의exception_ptr객체가 참조하는 예외 객체가 똑같다는 보장은 없다.
std::exception_ptr make_exception_ptr(Type value) noexcept:
이 함수 템플릿은 인자로 건넨 유형의 값으로부터exception_ptr을 생성한다.Type이 반드시std::exception일 필요는 없다. 생성된exception_ptr은std::promise에 할당할 수 있다.promise의future의get멤버가 연이어서 호출되면 (또다른 쓰레드 안에서 호출될 수 있다) 예외가 던져질 것이다. 다음은 몇 가지 예이다. 어떻게 유형이 다른 값을 인자로make_exception_ptr에 건넬 수 있는지, 결국 생성된exception_ptr이obj에 어떻게 할당되는지 보여준다.std::promise유형이 될 것이라고 간주한다.auto ptr = make_exception_ptr(exception()); ptr = make_exception(string("hello world")); ptr = make_exception(12); obj.set_exception(make_exception_ptr(ptr));
void std::rethrow_exception(exception_ptr obj):
obj가 참조하는 예외를 던진다. 주의하라.obj는nullptr일 수 없다.
packaged_task의 사용 방법을 시연한다.
멀티 쓰레드 퀵정렬 예제처럼 작업자 풀이 사용된다. 그렇지만 이 예제에서 작업자는 사실 자신의 과업이 무엇인지 모른다. 현재 예제에서 과업은 우연하게도 동일하지만 다른 작업을 사용해도 된다. 작업자를 업데이트할 필요가 없다.
프로그램은 Task 클래스를 사용한다. 안에 d_command 명령어-상세와 d_task 과업 상세가 들어 있다. 그림 24를 참고하라. 프로그램 소스는 이 책의 yo/threading/examples/multicompile 디렉토리에 있다.
이전과 마찬가지로 main은 먼저 분배된 쓰레드로 작업을 시작한다. 이 다음, 또다시 분배된 쓰레드에 의하여 컴파일 작업이 수행된다. 마침내 컴파일 작업의 결과를 results로 처리한다.
int main()
{
workforce(); // 작업자 쓰레드를 시작한다.
thread(jobs).detach(); // 작업을 시작한다.
results(); // 결과를 처리한다.
}
jobs 쓰레드는 표준 입력스트림으로부터 컴파일할 파일들의 이름을 읽어서 dispatch에 건넨다. 그러면 작업자들이 처리한다. 줄 7과 8은 마지막에 실행되며 빈 입력에 대한 안전판이다. 안전판은 newResult의 기술과 함께 아래에 언급한다.
1: void jobs()
2: {
3: string line;
4: while (getline(cin, line) && dispatch(line))
5: ;
6:
7: g_ready = true;
8: g_resultCond.notify_one();
9: }
다음으로 분배자를 알아보자. 분배자는 빈 줄을 무시한다. 또한 분배자를 호출할 때까지 컴파일이 실패하면 처리를 중단한다 (6-7 줄). 그렇지 않으면 분배자는 또다른 작업자를 기다리며 새로운 과업을 준비해서 작업자에게 처리하라고 고지한다.
bool dispatch(string const &line)
{
if (line.empty())
return true;
if (g_done.load())
return false;
g_workforce.wait();
newTask(line);
g_worker.notify_all();
return true;
}
newTask 함수는 다음 과업을 위해 프로그램을 준비한다. 먼저 Task 객체를 생성한다. Task 객체는 컴파일할 파일의 이름과 packaged_task를 가지고 있다. packaged_task와 연관된 모든 행위를 안에 보유한다. 다음은 그의 (인-클래스) 정의이다.
1: typedef packaged_task<Result (string const &fname)> PackagedTask;
2:
3: class Task
4: {
5: string d_command;
6: PackagedTask d_task;
7:
8: public:
9: Task() = default;
10:
11: Task(string const &command, PackagedTask &&tmp)
12: :
13: d_command(command),
14: d_task(move(tmp))
15: {}
16:
17: void operator()()
18: {
19: d_task(d_command);
20: }
21:
22: shared_future<Result> result()
23: {
24: return d_task.get_future().share();
25: }
26: };
(줄 22-25에서) result가 shared_future를 돌려주는 것을 눈여겨보라. 분배자는 결과를 처리하는 쓰레드와 다른 쓰레드에서 실행되기 때문에 분배자가 만든 future는 결과를 처리하는 함수가 요구한 future 객체들과 공유해야 한다. 그러므로 Task::result가 shared_future를 돌려주는 것이다.
Task 객체가 생성되면 그의 shared_future가 결과 큐에 배치된다. 실제 결과는 이 때까지 사용할 수 없지만 result 함수는 (아래 참고) 무언가 자신의 큐에 삽입되었음을 고지받는다. 또 Task 자체가 과업 큐에 배치된다. 작업자는 그것을 열람할 수 있다.
typedef packaged_task<Result (string const &fname)> PackagedTask;
class Task
{
string d_command;
PackagedTask d_task;
public:
Task() = default;
Task(string const &command, PackagedTask &&tmp)
:
d_command(command),
d_task(move(tmp))
{}
void operator()()
{
d_task(d_command);
}
shared_future<Result> result()
{
return d_task.get_future().share();
}
};
void pushResultQ(shared_future<Result> const &sharedResult)
{
lock_guard<mutex> lk(g_resultQMutex);
g_resultQ.push(sharedResult);
g_ready = true;
g_resultCond.notify_one();
}
작업자에게는 간단한 과업이 주어진다. 다음 과업을 과업 큐의 앞에서 열람한 다음, 그 과업을 수행하는 것이다. 과업 자체에서 무슨 일이 일어나는지는 전혀 상관하지 않는다. 작업자 쓰레드는 결국 프로그램이 종료할 때 끝난다.
void worker()
{
Task task;
while (true)
{
g_worker.wait();
g_taskQ.popFront(task);
task();
g_workforce.notify_all();
}
}
이것으로 과업이 어떻게 처리되는지 설명을 마친다. 과업 자체는 여전히 기술할 게 남아 있다. 현재 예제 프로그램에서 소스 파일이 컴파일되고 있는 중이다. 컴파일 명령어는 CmdFork 객체의 생성자에 건네진다. 이 생성자는 자손 프로세스로 컴파일을 시작한다. 컴파일 결과는 (컴파일러의 종료 코드를 돌려주는) childExit 멤버와 (컴파일러가 생산한 텍스트 출력을 돌려주는) childOutput 멤버를 통하여 열람한다. 컴파일에 실패하면 종료 값은 0이 되지 않는다. 이 경우 더 이상 컴파일 과업이 시작되지 않는다. 줄 11과 12를 참고하라. class CmdFork의 구현은 C++ 주해서의 yo/threading/examples/cmdfork 디렉토리에 있다. 다음은 compile 함수이다.
1: Result compile(string const &line)
2: {
3: string command("/usr/bin/g++ -Wall --std=c++11 -c " + line);
4:
5: CmdFork cmdFork(command);
6: cmdFork.fork();
7:
8: Result ret {cmdFork.childExit() == 0,
9: line + "\n" + cmdFork.childOutput()};
10:
11: if (not ret.ok)
12: g_done = true;
13:
14: return ret;
15: }
results 함수는 결과가 있는 한 계속된다. 결과가 있으면 화면에 표시한다. 컴파일에 실패할 때마다 Result 실체의 d_ok 멤버는 false가 되고 results는 끝난다.
void results()
{
while (newResult())
{
Result const &result = g_resultQ.front().get();
cerr << result.display;
if (not result.ok)
return;
g_resultQ.pop();
}
}
newResult 함수는 results의 while-회돌이를 제어한다. 결과 큐에 결과가 있으면 true를 돌려준다. 파일 이름이 표준 입력 스트림에 나타나지 않거나 결과가 큐에 전혀 배치되지 않으면 newResult는 기다린다. 또 결과 큐에 더 이상 결과가 없을 때에도 기다리지만 적어도 하나의 작업자 쓰레드는 바쁘다. 결과가 큐에 배치될 때마다 그리고 입력 스트림이 처리되면 newResult에 고지된다. 고지 다음에 newResult가 반환된다. 그리고 results는 끝나거나 큐의 맨 앞에 나타나는 결과를 보여준다.
bool newResult()
{
unique_lock<mutex> lk(g_resultQMutex);
while
(
(
g_resultQ.empty()
&&
g_workforce.size() != g_sizeofWorkforce
)
||
not g_ready.load()
)
g_resultCond.wait(lk);
return not g_resultQ.empty();
}