흥미로운 부분은 컨테이너가 구성되는 순간까지 그 안에 저장할 수 있는 데이터의 유형이 지정되지 않는다는 것이다. 그 때문에 추상 컨테이너라고 부른다.
추상 컨테이너는 템플릿(template)에 크게 의존한다. 이에 관해서는 21장 이후부터 다룬다. 추상 컨테이너를 사용하려면 템플릿이라는 개념을 조금 이해하기만 하면 된다. C++에서 템플릿은 사실상 함수나 클래스를 완전하게 구성하는 요리법이다. 이 요리법은 클래스나 함수에서 기능을 최대한 분리해 추상화한다. 템플릿이 처리하는 데이터 유형은 템플릿이 구현되는 순간에 알 수 없기 때문에 데이터 유형은 함수 템플릿이 사용되는 문맥으로부터 추론되거나 클래스 템플릿이 사용될 때 명시적으로 언급된다 (여기에 사용되는 용어는 구체화(instantiated)이다).
옆꺽쇠 괄호 표기법으로 데이터 유형을 명시적으로 언급한다. 예를 들어 아래에서 짝 컨테이너는 (12.2절) 명시적으로 두 개의 데이터 유형을 요구한다. 다음은 int와 string을 포함하는 pair 객체이다.
pair<int, string> myPair;
myPair 객체는 int와 string을 보유하도록 정의된다.
앞으로 추상 컨테이너를 연구할 때 옆꺽쇠 괄호 표기법이 많이 사용된다. 실제로 템플릿에서 이 부분만 이해하면 추상 컨테이너를 사용할 수 있다. 이 표기법을 소개했으므로 템플릿에 관한 더 깊은 연구는 제 21장으로 미루고 이 장에서는 그 사용법에 집중한다.
대부분의 추상 컨테이너는 순차 컨테이너이다. 순차적으로 저장하고 열람할 수 있는 데이터를 담는다. 배열(array)은 고정 크기의 배열을 구현한다. 벡터(vector)는 확장 배열을 구현한다. 리스트(list)는 쉽게 삽입 삭제가 가능한 데이터 구조를 구현한다. 스택(stack)은 FIFO(first in, first out (선입선출))라고도 불리우며 들어온 첫 원소를 가장 먼저 열람한다. 큐(queue)는 FILO(first in, last out (선입후출)) 또는 LIFO(후입선출) 구조이다.
순차 컨테이너 외에도 여러 특별한 컨테이너들이 있다. 페어(pair)는 한 쌍의 값을 저장할 수 있는 기본 컨테이너이다 (유형은 빈 채로 두고 나중에 지정). 예를 들어 두 개의 문자열, 두 개의 정수, 문자열 하나와 배정도 정수, 등등, 페어는 데이터와 자연스럽게 한 쌍이 되는 원소를 돌려준다. 예를 들어 맵(map)은 키와 그 연관 값을 저장하는 추상 컨테이너이다. 이런 맵의 원소가 한 쌍(pair)으로 반환된다.
페어(pair)의 변형으로 복소수(complex) 컨테이너가 있다. 복소수를 정의한 연산을 구현한다.
터플(tuple)은 페어 컨테이너를 일반화하여 유형에 상관없이 데이터를 담을 수 있다 (22.6절).
이 장에 기술된 모든 추상 컨테이너와 더불어 string과 스트림 데이터 유형은 모두 표준 템플릿 라이브러리이다 (제 5장과 6장 참고).
순서없는 컨테이너를 제외하고 모두 다음 기본 연산자 집합을 지원한다.
== 그리고 !=):
true를 돌려준다. 부등 연산자는 그 반대이다.
<, <=, > 그리고 >=): < 연산자는 왼쪽 컨테이너의 원소들이 오른쪽 컨테이너에서 각각 상응하는 원소보다 작다면 true를 돌려준다. 오른쪽이든 왼쪽이든 컨테이너의 나머지 원소들은 무시된다.
container left;
container right;
left = {0, 2, 4};
right = {1, 3}; // left < right
right = {1, 3, 6, 1, 2}; // left < right
대부분의 컨테이너는 최대 크기를 결정하기 위한 멤버 함수(max_size)를 지원한다 (스택 (12.4.11항)과 선점 큐 (12.4.5항) 그리고 큐 (12.4.4항)). 컨테이너는 예외이다.
사실상 거의 모든 함수가 복사 생성을 지원한다. 컨테이너가 복사 생성을 지원하고 컨테이너의 유형이 이동 생성을 지원하면 컨테이너가 임시의 익명 컨테이너로 초기화될 때 그 컨테이너의 데이터 원소에 이동 생성이 자동으로 사용된다.
표준 템플릿 라이브러리에 총칭 알고리즘이 밀접하게 연결되어 있다. 자주 일어나는 작업에 또는 컨테이너 자체로 할 수 있는 것보다 더 복잡한 작업에 이 알고리즘이 사용되기도 한다. 예를 들어 갯수 세기와 원소 채우기 그리고 여과하기 등등이 있다. 총칭 알고리즘과 그 응용법에 관한 개관은 제 19장에 제시한다. 총칭 알고리즘은 반복자에 의존한다. 반복자는 컨테이너에 저장된 데이터를 처리할 시작 지점과 끝 지점을 가리킨다. 추상 컨테이너는 반복자를 기대하는 생성자와 멤버를 지원하고 (string::begin 멤버와 string::end 멤버에 비교하여) 반복자를 돌려주는 멤버를 가진다. 이 장에서 반복자 개념은 더 이상 깊이 조사하지 않는다. 이에 관해서는 제 18장을 참고하라.
https://www.sgi.com/tech/stl/ 사이트에 한 번 방문할 가치가 있다. 추상 컨테이너와 표준 템플릿 라이브러리를 이 책보다 더 광범위하게 다루기 때문이다.
컨테이너는 살아 있는 동안 데이터를 수집하는 경우가 있다. 컨테이너가 영역을 벗어나면 그의 소멸자가 데이터 원소를 파괴하려고 시도한다. 이 시도가 성공하려면 데이터 멤버 자체가 컨테이너 안에 들어 있어야 한다. 컨테이너의 데이터 원소가 포인터라서 동적으로 할당된 메모리를 가리킨다면 이 메모리는 파괴되지 않는다. 그 때문에 메모리 누수가 얼어난다. 이 전략의 중요성은 컨테이너에 저장된 데이터는 컨테이너의 특성으로 간주되어야 한다는 것이다. 컨테이너는 소멸자가 호출될 때 그의 데이터 원소를 파괴할 수 있어야 한다. 그래서 컨테이너는 데이터를 가리키는 포인터를 포함하면 안된다. 또한 컨테이너는 const 데이터를 포함하면 안된다. const 데이터는 컨테이너의 멤버를 사용하지 못하게 막기 때문이다. 예를 들어 할당 연산자를 사용하지 못한다.
std:: 이름공간은 생략하는 것이 보통이다.
pair라면 pair<string, int>를 표현한 것일 수 있다.
Type으로 표기하면 총칭 유형을 나타낸다. Type은 int나 string 등등이 될 수 있다.
object와 container는 논의중에 있는 컨테이너 유형을 가진 객체를 나타낸다.
value는 컨테이너에 저장된 유형의 값을 나타낸다.
n과 같은 한-문자 짜리 식별자라면 부호가 없는 값을 나타낸다.
pos, from, beyond가 있다.
map 같은 컨테이너는 값을 쌍으로 포함하고 있는데, `키'와 `값'이라고 부른다. 그런 컨테이너에 다음 표기 관례를 더 많이 사용한다.
key는 사용자 키-유형의 값을 표시한다.
keyvalue는 특정한 컨테이너에 사용된 `value_type'의 값을 표시한다.
first와 second라고 부르며 그것이 다이다. 페어 컨테이너를 사용하기 전에 <utility> 헤더를 포함해야 한다.
페어 객체를 정의(선언)할 때 옆꺽쇠 표기법으로 데이터 유형을 지정한다 (제 21장). 예를 들어:
pair<string, string> piper("PA28", "PH-ANI");
pair<string, string> cessna("C172", "PH-ANG");
여기에서 페어 유형으로 piper와 cessna 객체를 정의하고 그 안에 두 개의 문자열을 넣는다. 페어 유형의 first 필드와 second 필드로 두 문자열을 모두 열람할 수 있다.
cout << piper.first << '\n' << // 출력 'PA28'
cessna.second << '\n'; // 출력 'PH-ANG'
first 멤버와 second 멤버는 값을 재할당하는 데에도 사용할 수 있다.
cessna.first = "C152";
cessna.second = "PH-ANW";
페어 객체를 완전히 재할당해야 한다면 이름 없는 페어 객체를 오른쪽 피연산자로 할당하면 된다. 익명 변수는 같은 유형의 또다른 값을 (재)할당하기 위한 목적으로만 임시 변수를 정의한다 (이름을 전혀 받지 않는다). 그의 총칭적 형태는 다음과 같다.
type(초기화 리스트)
페어 객체를 사용할 때 단순히 컨테이너 이름 pair를 언급하는 것으로는 유형 지정이 완전하지 않다. 페어 안에 저장된 데이터 유형을 지정하는 것이 더 필요하다. 이를 위하여 (템플릿) 옆꺽쇠 표기법이 다시 사용된다. 예를 들어 cessna 페어 객체의 재할당은 다음과 같이 할 수 있다.
cessna = pair<string, string>("C152", "PH-ANW");
유형 지정이 번잡하다. 그래서 typedef 키워드에 다시 눈이 가게 만든다. 소스에 pair<type1, type2> 절들이 많이 사용될 경우 먼저 해당 절에 이름을 정의한 다음에 그 이름을 사용하면 타자하는 수고를 덜고 가독성도 개선된다. 예를 들어,
typedef pair<string, string> pairStrStr;
cessna = pairStrStr("C152", "PH-ANW");
이를 (그리고 기본 연산(할당과 비교) 집합을) 제외하면 페어에 별다른 기능은 없다. 그렇지만 페어는 앞으로 다룰 맵과 다중맵 그리고 해시맵과 같은 추상 컨테이너들의 핵심 요소이다.
C++는 일반화된 페어 컨테이너도 제공한다. 터플 컨테이너가 바로 그것인데 22.6절에 다룬다.
get_allocator 멤버로 얻을 수 있다. 이 멤버는 컨테이너가 사용하는 배당자의 사본을 돌려준다. 배당자는 다음 멤버를 제공한다.
value_type *address(value_type &object)
object의 주소를 돌려준다.value_type *allocate(size_t count)
컨테이너의value_type유형의 값count개를 담기 위하여 날 메모리를 배당한다.
void construct(value_type *object, Arg &&...args)
배치new를 사용한다.object에 값을 설정하기 위하여object다음에 나오는 인자들을 사용한다.
void destroy(value_type *object)
object의 소멸자를 호출한다 (그러나object자신의 메모리는 해제하지 않는다).
void deallocate(value_type *object, size_t count)
operator delete를 호출해 이전에 배당자가 객체에 배당한 메모리를 삭제한다.size_t max_size()
배당자가 배당할 수 있는 원소의 최대 갯수를 돌려준다.
다음은 문자열 벡터의 배당자를 사용하는 예이다 (벡터에 대한 설명은 아래 12.4.2항을 참고):
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main()
{
vector<string> vs;
auto allocator = vs.get_allocator(); // 배당자를 얻는다.
string *sp = allocator.allocate(3); // 배당한다. 3 개의 문자열 공간 확보
allocator.construct(&sp[0], "hello world"); // 첫번째 문자열을 초기화
allocator.construct(&sp[1], sp[0]); // 복사 생성자를 사용
allocator.construct(&sp[2], 12, '='); // 12개의 = 문자로 이루어진 문자열
cout << sp[0] << '\n' << // 문자열을 보여준다.
sp[1] << '\n' <<
sp[2] << '\n' <<
"could have allocated " << allocator.max_size() << " strings\n";
for (size_t idx = 0; idx != 3; ++idx)
allocator.destroy(sp + idx); // 문자열의 내용을
// 삭제한다.
allocator.deallocate(sp, 3); // 이어서 sp 자체를 삭제한다.
}
<array> 헤더를 포함해야 한다.
std::array를 정의하기 위하여 원소의 데이터 유형과 크기를 명시해야 한다. 데이터 유형은 좌옆꺽쇠 다음에 주어지고 다음에 바로 `array' 컨테이너 이름이 따라온다. 배열의 크기는 데이터 유형을 지정한 다음에 주어진다. 마지막으로 우옆꺽쇠로 배열의 유형을 완료한다. 이와 같은 지정 방법은 컨테이너에 일반적인 관행이다. array 이름과 원소의 유형 그리고 배열의 크기를 조합하여 유형을 정의한다. 결과적으로 array<string, 4>는 array<string, 5>와 유형이 다르게 정의된다. 함수에 명시적으로 array<Type, N> 매개변수가 정의될 경우 N과 M이 같지 않으면 array<Type, M>를 인자로 받지 않을 것이다.
배열의 크기는 0으로 정의할 수 있다 (물론 아무 원소도 저장할 수 없으므로 별 쓸모는 없을 것이다). 배열의 원소는 연속적으로 저장된다. array<Type, N> arr이 정의되었다면 &arr[n] + m == &arr[n + m이다. 0 <= n < N이고 0 <= n + m < N이라고 간주한다.
다음 생성자와 연산자 그리고 멤버 함수를 사용할 수 있다.
N개를 생성한다.
array<string, N> object;
array<double, 4> dArr = {1.2, 2.4};
여기에서 dArr은 4개의 원소가 있는 배열로 정의된다. dArr[0]과 dArr[1]은 각각 1.2와 2.4로 초기화되고 dArr[2]와 dArr[3]는 0으로 초기화된다. 배열의 (그리고 기타 컨테이너들의) 매력적인 특징은 컨테이너가 데이터 원소들을 데이터 유형의 기본 값으로 초기화한다는 것이다. 이 초기화에 데이터 유형의 기본 생성자가 사용된다. 클래스가 아닌 데이터 유형은 값 0이 사용된다. 그래서 array<double, 4> 배열에 명시적으로 초기화된 원소는 제외하고 나머지 원소는 모두 0으로 초기화된다.
iarr[0] = 18과 같은 서술문은 에러를 일으킨다. 배열이 비어 있기 때문이다. operator[]는 배열의 경계를 존중하지 않는다라는 사실을 주의하라. 실행 시간에 배열 값을 점검하고 싶다면 배열의 at 멤버를 사용하라.
array 클래스는 다음 멤버 함수를 제공한다.
Type &at(size_t idx):배열의 첨자 위치idx에 있는 원소를 참조로 돌려준다.idx가 배열 크기를 초과하면std::out_of_range예외가 던져진다.
Type &back():배열의 마지막 원소를 참조로 돌려준다. 배열이 비어 있지 않을 때만 이 멤버를 사용해야 한다.
array::iterator begin():배열의 첫 번째 원소를 가리키는 반복자를 돌려준다. 배열이 비어 있으면 end를 돌려준다.
array::const_iterator cbegin():배열의 첫 번째 원소를 가리키는 상수 반복자를 돌려준다. 배열이 비어 있으면 cend를 돌려준다.
array::const_iterator cend():배열의 마지막 원소를 바로 지난 곳을 가리키는 상수 반복자를 돌려준다.
array::const_reverse_iterator crbegin():배열의 마지막 원소를 가리키는 상수 역방향 반복자를 돌려준다. 배열이 비어 있으면 crend를 돌려준다.
array::const_reverse_iterator crend():배열의 첫 번째 원소 바로 전 위치를 가리키는 상수 역방향 반복자를 돌려준다.
value_type *data():배열의 첫 번째 원소를 포인터로 돌려준다. 상수 배열이라면 value_type const *를 돌려준다.
bool empty():배열에 원소가 없으면 true를 돌려준다.
array::iterator end():배열의 마지막 위치를 지난 곳을 가리키는 반복자를 돌려준다.
void fill(Type const &item):배열의 모든 원소를 item의 사본으로 채운다
Type &front():배열의 첫 번째 원소를 참조로 돌려준다. 배열이 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
array::reverse_iterator rbegin():배열의 마지막 원소를 가리키는 반복자를 돌려준다.
array::reverse_iterator rend():배열의 첫 번째 원소 바로 앞을 가리키는 반복자를 돌려준다.
constexpr size_t size():배열에 포함된 원소의 갯수를 돌려준다.
void swap(<array<Type, N> &other):현재 배열과 상대 배열의 내용을 서로 교체한다. 상대 배열의 유형과 크기는 swap을 호출하는 객체의 데이터 유형과 크기가 같아야 한다 .
size를 사용할 수 있다.).
<vector> 헤더를 포함해야 한다.
다음 생성자와 연산자 그리고 멤버 함수를 사용할 수 있다.
vector<string> object;
vector<string> object(5, string("Hello")); // 5 개의 Hello로 초기화한다.
vector<string> container(10); // 10 개의 빈 문자열로 초기화한다.
vector<string> names = {"george", "frank", "tony", "karel"};
vector<string> 벡터를 초기화하려면 다음과 같이 생성하면 된다.
extern vector<string> container; vector<string> object(&container[5], &container[11]);
여기에서 눈여겨볼 것은 두 번째 반복자가 가리키는 마지막 원소(&container[11])가 object에 저장되어 있지 않다라는 것이다. 이것은 반복자의 사용법을 간단하게 보여주는 예이다. 사용된 값의 범위는 첫 번째 값에서 시작하여 두 번째 반복자가 참조하는 원소 미만까지이다. 마지막 참조 원소는 포함되지 않는다. 이에 대한 표준 표기법은 [begin, end)이다. (역주: 시작 첨자는 처리하고 싶은 인덱스를 지정하고 끝 첨자는 처리를 하고 싶지 않은 인덱스를 지정한다고 생각하면 편하다.)
ivect[0] = 18과 같은 서술문은 에러를 일으킨다. 벡터는 자동으로 확대되지 않기 때문이다. 그리고 operator[]는 벡터 경계를 존중하지 않는다. 이 경우 벡터는 먼저 크기가 바뀌어야 한다. 아니면 ivect.push_back(18)를 사용해야 한다 (아래 참고). 실행 시간에 배열의 경계를 점검할 필요가 있다면 벡터의 at 멤버를 사용하면 된다.
void assign(...):새 값을 벡터에 할당한다.
assign(iterator begin, iterator end)[begin, end) 범위에 있는 값들을 벡터에 할당한다.
assign(size_type n, value_type const &val)n 개의 val 사본을 할당한다.
assign(initializer_list<value_type> values)
Type &at(size_t idx):첨자 위치idx에 있는 벡터의 원소를 참조로 돌려준다.idx가 벡터의 크기를 초과하면std::out_of_range예외가 일어난다.
Type &back():벡터의 마지막 원소를 참조로 돌려준다. 벡터가 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
vector::iterator begin():벡터의 첫 번째 원소를 가리키는 반복자를 돌려준다. 벡터가 비어 있으면 end를 돌려준다.
size_t capacity():메모리가 할당되어 있는 원소의 갯수. 최소한 size 값만큼은 돌려준다.
vector::const_iterator cbegin():벡터의 첫 번째 원소를 가리키는 상수 반복자를 돌려준다. 벡터가 비어 있으면 cend를 돌려준다.
vector::const_iterator cend():벡터의 마지막 원소 바로 뒤를 가리키는 상수 반복자를 돌려준다.
void clear():벡터의 원소를 모두 삭제한다.
vector::const_reverse_iterator crbegin():벡터의 마지막 원소를 가리키는 상수 역방향 반복자를 돌려준다. 벡터가 비어 있으면 crend를 돌려준다.
vector::const_reverse_iterator crend():벡터의 첫 번째 원소 바로 앞을 가리키는 상수 역방향 반복자를 돌려준다.
value_type *data():벡터의 첫 번째 데이터 원소를 포인터로 돌려준다.
iterator emplace(const_iterator position, Args &&...args):position뒤에 지정된 인자들로부터value_type객체를 생성한다. 새로 생성된 원소는position에 삽입된다. 기존의 객체가 컨테이너의 값 유형이기를 기대하는 복사 생성이나 이동 생성 또는 할당을 사용하는 (그리고 주어진 인자를 컨테이너 안에 삽입하는)insert와 다르게emplace는 인자를 사용하여 컨테이너의 의도한 위치에 직접적으로 객체를 생성한다. 복사 생성이나 이동 생성 또는 할당을 전혀 요구하지 않는다.
void emplace_back(Args &&...args): 인자들로부터 value_type 객체를 생성한다. 새로 생성된 원소는 벡터의 마지막 원소 뒤에 추가된다.
bool empty():벡터에 원소가 없으면 true를 돌려준다.
vector::iterator end():벡터의 마지막 원소 뒤를 가리키는 반복자를 돌려준다.
vector::iterator erase():지정된 범위의 원소를 벡터로부터 삭제한다.
erase(pos)pos가 가리키는 원소를 삭제한다. 반복자 ++pos가 반환된다.
erase(first, beyond)[first, beyond) 범위의 원소를 모두 삭제한다. beyond를 돌려준다.
Type &front():벡터의 첫 번째 원소를 참조로 돌려준다. 벡터가 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
allocator_type get_allocator() const: vector 객체에 사용된 배당자 객체의 사본을 돌려준다.
... insert():특정 위치부터 시작하여 원소들을 삽입할 수 있다. 반환 값은 호출된 insert()의 버전에 따라 다르다.
vector::iterator insert(pos)Type인 기본 값을 pos 위치에 삽입한다. pos가 반환된다.
vector::iterator insert(pos, value)value를 pos에 삽입한다. pos가 반환된다.
void insert(pos, first, beyond)[first, beyond) 범위에 삽입한다.
void insert(pos, n, value)value를 값으로 가진 n 개의 원소들을 pos 위치에 삽입한다.
size_t max_size(): vector가 가질 수 있는 원소의 최대 갯수를 돌려준다.
void pop_back():벡터로부터 마지막 원소를 제거한다. 빈 벡터이면 아무 일도 일어나지 않는다.
void push_back(value):벡터의 끝에 value를 추가한다.
vector::reverse_iterator rbegin():이 멤버는 벡터에서 마지막 원소를 가리키는 반복자를 돌려준다.
vector::reverse_iterator rend():벡터에서 첫 번째 원소 앞을 가리키는 반복자를 돌려준다.
void reserve(size_t request):요청(request)이 가용능력(capacity) 보다 작거나 같으면 이 호출은 아무 효과도 없다. 그렇지 않으면 요청에 따라 메모리를 더 배당한다. 호출이 성공적이면capacity는 최소한request의 값을 돌려준다. 그렇지 않으면capacity는 바뀌지 않는다. 어느 경우이든size의 반환 값은 바뀌지 않는다. 접근가능한 원소의 갯수를 실제로 바꾸려면resize같은 함수를 호출해야 한다.
void resize():현재 벡터에 저장된 원소의 갯수를 바꿀 수 있다.
resize(n, value)를 사용하여 벡터의 크기를 n으로 바꿀 수 있다. value는 선택적이다. 벡터가 확대되고 value가 제공되지 않으면 추가 원소들은 사용된 데이터 유형의 기본 값으로 초기화된다. 그렇지 않으면 value를 사용하여 나머지 원소들을 초기화한다.
void shrink_to_fit():선택적으로 벡터가 할당한 메모리의 양을 현재 크기로 축소한다. 구현자는 이 요청을 무시해도 좋다. 아니면 자유롭게 최적화해도 된다. `딱 맞게 축소' 연산을 보장하려면 다음 상용구를 사용할 수 있다.vector<Type>(vectorObject).swap(vectorObject)
size_t size():벡터에 있는 원소의 갯수를 돌려준다.
void swap():데이터 유형이 같은 두 벡터를 서로 바꾼다. 예제:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v1(7);
vector<int> v2(10);
v1.swap(v2);
cout << v1.size() << " " << v2.size() << '\n';
}
/*
출력:
10 7
*/
<list> 헤더를 포함해야 한다.
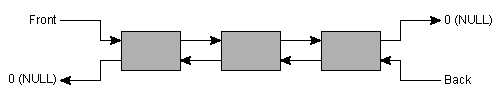
리스트의 구조를 그림 8에 보여준다.
세심하게 지적하면 그림 8에 주어진 표현이 실제 리스트 구현에 반드시 사용되는 것은 아니다. 예를 들어, 다음의 작은 프로그램을 연구해 보자:
int main()
{
list<int> l;
cout << "size: " << l.size() << ", first element: " <<
l.front() << '\n';
}
이 프로그램을 실행하면 실제로 다음과 같이 출력된다.
size: 0, first element: 0
심지어 제일 앞 원소에 값을 할당할 수도 있다. 이 경우 구현자는 리스트에 숨은 원소를 하나 제공하기로 결정했다. 이 리스트는 알고 보면 환형 리스트이다. 그림 8의 0-포인터를 대신하여 숨은 원소가 종료 원소로 기여한다. 지적하였듯이 이것은 세부적인 것이다. 0-포인터로 끝나는 데이터 구조로서의 리스트의 개념적 표기법에 영향을 주지 않는다. 리스트 구조는 다양하게 구현이 가능하다는 사실은 이미 잘 알려져 있다는 것도 주목하라 (참고 Aho, A.V., Hopcroft J.E. and Ullman, J.D., (1983)
Data Structures and Algorithms (Addison-Wesley)).
리스트와 벡터는 둘 다 얼마나 많은 갯수의 원소를 저장해야 하는지 아직 알지 못하는 상황에 적절한 데이터 구조이다. 그렇지만 적절한 데이터 구조를 선택할 때 몇 가지 따라야 할 규칙이 있다.
vector<int> frequencies(256)가 선택해야 할 데이터 구조이다. 받은 문자의 값을 frequencies 빈도 벡터에 대한 첨자로 사용할 수 있기 때문이다.
리스트와 벡터 사이의 선택에 관련된 또다른 고려 사항도 역시 좀 생각해 보아야 한다. 벡터가 동적으로 자랄 수는 있지만 동적인 성장은 데이터의 복사를 요구한다. 확실히 수 백만 개의 방대한 데이터 구조는 빠른 컴퓨터일지라도 시간을 몹시 많이 소모한다. 반면에 리스트에 있는 방대한 갯수의 원소는 관련 없는 데이터의 복사를 요구하지 않는다. 리스트에 새 원소를 삽입하는 것은 포인터만 약간 처리해 주면 충분하다. 그림 9에 이것을 보여준다. 두 번째와 세 번째 원소 사이에 원소가 새로 삽입된다. 원소가 네 개 있는 리스트를 새로 생성한다.
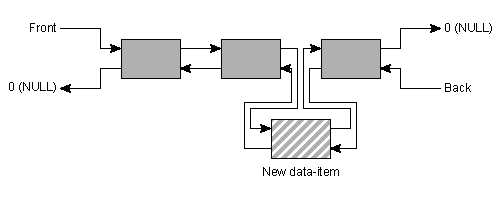
리스트 컨테이너는 다음 생성자와 연산자 그리고 멤버 함수를 제공한다.
list<string> object;
벡터와 마찬가지로 빈 리스트의 원소를 참조하는 것은 에러이다.
list<string> object(5, string("Hello")); // 5 개의 Hello로 초기화된다.
list<string> container(10); // 10 개의 빈 문자열로 초기화된다.
vector<string>의 5번부터 10번 미만까지 리스트를 초기화하려면 다음과 같이 생성할 수 있다.
extern vector<string> container; list<string> object(&container[5], &container[11]);
void assign(...):
새로 내용을 리스트에 할당한다.
assign(iterator begin, iterator end)[begin, end) 범위의 값들을 리스트에 할당한다.
assign(size_type n, value_type const &val)n 개의 val 사본을 리스트에 할당한다.
Type &back():리스트의 마지막 원소를 참조로 돌려준다. 리스트가 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
list::iterator begin():리스트의 첫 원소를 가리키는 반복자를 돌려준다. 리스트가 비어 있으면 end를 돌려준다.
void clear():리스트로부터 모든 원소를 삭제한다.
bool empty():리스트에 원소가 없으면 true를 돌려준다.
list::iterator end():리스트의 마지막 원소 다음을 가리키는 반복자를 돌려준다.
list::iterator erase():리스트에서 특정 범위의 원소들을 삭제한다.
erase(pos)pos가 가리키는 원소를 삭제한다. 반복자 ++pos가 반환된다.
erase(first, beyond)[first, beyond) 범위로 지정된 원소들을 삭제한다. beyond가 반환된다.
Type &front():리스트의 첫 원소를 참조로 돌려준다. 리스트가 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
allocator_type get_allocator() const: list object. 객체에 사용된 배당자 객체의 사본을 돌려준다.
... insert():리스트에 원소들을 삽입한다. 반환 값은 호출된 insert 버전에 따라 다르다.
list::iterator insert(pos)Type 유형의 기본 값을 pos 위치에 삽입한다. pos가 반환된다.
list::iterator insert(pos, value)value를 pos 위치에 삽입한다. pos가 반환된다.
void insert(pos, first, beyond)[first, beyond) 범위의 원소들을 pos 위치에 삽입한다.
void insert(pos, n, value)value인 n 개의 원소들을 pos 위치에 삽입한다.
size_t max_size():
리스트가 수용할 수 있는 원소의 최대 갯수를 돌려준다.
void merge(list<Type> other):
이 멤버 함수는 현재 리스트와 대상 리스트가 정렬되어 있다고 간주한다 (아래sort멤버 참고). 그 가정에 근거하여other의 원소를 현재 리스트 안으로 삽입한다. 변경된 리스트는 여전히 정렬된 채로 유지된다. 두 리스트 모두 정렬되어 있지 않으면 결과 리스트는 `가능하면' 정렬되어 두 리스트에 있는 원소들에 새로 순서를 부여한다.list<Type>::merge는Type::operator<를 사용하여 리스트의 데이터를 정렬한다. 그러므로 해당 연산자가 반드시 필요하다. 다음 예제는merge멤버의 사용법을 보여준다. `object' 리스트는 정렬되어 있지 않다. 그래서 결과 리스트는 '가능하면' 정렬된다.#include <iostream> #include <string> #include <list> using namespace std; void showlist(list<string> &target) { for ( list<string>::iterator from = target.begin(); from != target.end(); ++from ) cout << *from << " "; cout << '\n'; } int main() { list<string> first; list<string> second; first.push_back(string("alpha")); first.push_back(string("bravo")); first.push_back(string("golf")); first.push_back(string("quebec")); second.push_back(string("oscar")); second.push_back(string("mike")); second.push_back(string("november")); second.push_back(string("zulu")); first.merge(second); showlist(first); } /* 출력: alpha bravo golf oscar mike november quebec zulu */미묘한 점은 리스트 자체가 인자로 사용되면
merge가 리스트를 변경하지 않는다는 것이다.object.merge(object)는 `object' 리스트를 변경하지 않는다.
void pop_back():리스트로부터 마지막 원소를 제거한다. 리스트가 비어 있으면 아무 일도 일어나지 않는다.
void pop_front():리스트로부터 첫 번째 원소를 제거한다. 리스트가 비어 있으면 아무 일도 일어나지 않는다.
void push_back(value):리스트의 마지막 원소 뒤에 value를 추가한다.
void push_front(value):리스트의 첫 원소 앞에 value를 추가한다.
list::reverse_iterator rbegin():리스트의 마지막 원소를 가리키는 반복자를 돌려준다.
void remove(value):리스트로부터value가 나타나면 모두 제거한다. 다음 예제는 두 개의 `Hello' 문자열을object리스트로부터 제거한다.#include <iostream> #include <string> #include <list> using namespace std; int main() { list<string> object; object.push_back(string("Hello")); object.push_back(string("World")); object.push_back(string("Hello")); object.push_back(string("World")); object.remove(string("Hello")); while (object.size()) { cout << object.front() << '\n'; object.pop_front(); } } /* 출력: World World */
void remove_if(Predicate pred):pred진위 함수나 함수 객체가true를 돌려주면 그 원소를 리스트로부터 제거한다. 리스트에 저장된 각 객체에 진위 함수가pred(*iter)으로 호출된다. 여기에서iter는remove_if가 내부적으로 사용한 반복자를 나타낸다.pred함수를 사용할 때 그의 원형은bool pred(value_type const &object)가 되어야 한다.list::reverse_iterator rend():이 멤버 함수는 리스트의 첫 번째 원소 앞을 가리키는 반복자를 돌려준다.void resize():현재 리스트에 저장된 원소의 갯수를 변경한다.
resize(n, value)를 사용하여 리스트의 크기를n크기로 바꿀 수 있다.value는 선택적이다. 리스트가 확대되면 나머지 원소들은 사용된 데이터 유형의 기본 값으로 초기화된다. 그렇지 않으면value를 사용하여 나머지 원소들을 초기화한다.
void reverse():리스트의 원소 순서를 뒤집는다. 원소back은front가 되고front는 그 반대로back이 된다.size_t size():리스트에 있는 원소의 갯수를 돌려준다.void sort():리스트를 정렬한다. 이미 정렬되어 있다면 그의 사용법은 아래에unique멤버를 기술할 때 함께 기술한다.list<Type>::sort는Type::operator<를 사용하여 리스트의 데이터를 정렬한다. 그러므로 해당 연산자를 사용할 수 있어야 한다.void splice(pos, object):splice멤버를 사용하는 객체의 반복자pos위치부터 삽입을 시작하여object의 내용을 현재 리스트로 전송한다.splice가 끝나고 나면object는 비어있다. 예를 들어:#include <iostream> #include <string> #include <list> using namespace std; int main() { list<string> object; object.push_front(string("Hello")); object.push_back(string("World")); list<string> argument(object); object.splice(++object.begin(), argument); cout << "Object contains " << object.size() << " elements, " << "Argument contains " << argument.size() << " elements,\n"; while (object.size()) { cout << object.front() << '\n'; object.pop_front(); } } /* 출력: Object contains 4 elements, Argument contains 0 elements, Hello Hello World World */다른 형태로
argument다음에 인자가 더 따라올 수 있다. 다음에argument의 반복자가 따라오면 이 반복자는 꼬아 이을 첫 번째 원소를 나타낸다. 또는 두 개의 반복자begin과end가 따라오면 이 범위는argument의 반복자[begin, end)범위를 뜻하고 이 범위를object안에 꼬아 잇는다.void swap():데이터 유형이 같은 두 리스트를 서로 교체한다.void unique():정렬된 리스트에 작동하여 이 멤버 함수는 인접한 원소가 서로 같으면 리스트로부터 모두 제거한다.list<Type>::unique는Type::operator==를 사용하여 데이터 원소가 같은지 식별한다. 그러므로 해당 연산자를 사용할 수 있어야 한다. 다음은 중복 단어들을 리스트로부터 모두 제거하는 예이다.#include <iostream> #include <string> #include <list> using namespace std; // merge() 예제 참조 void showlist(list<string> &target) { for ( list<string>::iterator from = target.begin(); from != target.end(); ++from ) cout << *from << " "; cout << '\n'; } int main() { string array[] = { "charlie", "alpha", "bravo", "alpha" }; list<string> target ( array, array + sizeof(array) / sizeof(string) ); cout << "처음 시작:\n"; showlist(target); target.sort(); cout << "sort()가 끝난 후:\n"; showlist(target); target.unique(); cout << "unique()가 끝난후:\n"; showlist(target); } /* 출력: 처음 시작: charlie alpha bravo alpha sort()가 끝난 후: alpha alpha bravo charlie unique()가 끝난 후: alpha bravo charlie */
<queue> 헤더를 포함해야 한다.
큐는 그림 11에 묘사되어 있다.
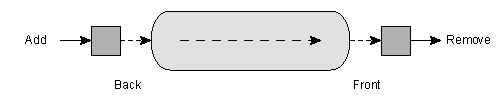
큐 컨테이너에 다음 생성자와 연산자 그리고 멤버 함수를 사용할 수 있다.
queue<string> object;
벡터와 마찬가지로 빈 큐에 원소를 참조하는 것은 에러이다.
Type &back():
큐의 마지막 원소를 참조로 돌려준다. 큐가 비어 있지 않을 경우에만 이 멤버 함수를 사용해야 한다.
bool empty():큐에 원소가 없으면 true를 돌려준다.
Type &front():큐의 첫 원소를 참조로 돌려준다. 큐가 비어 있지 않을 경우에만 이 멤버를 호출해야 한다.
void pop():맨 앞에 있는 원소를 제거한다. 원소는 이 멤버로 반환되지 않는다는 것을 주의하라. 비어 있는 큐에 이 멤버를 호출하면 아무 일도 일어나지 않는다.Type유형의 값 말고 (참고front) 왜pop이 아무것도 돌려주지 않는지 궁금할 것 같다 (void). 한 가지 이유는 좋은 소프트웨어 설계의 원리에 있다. 함수는 하나의 일만 수행해야 한다. 제거 작업과 제거된 원소를 돌려주는 것을 결합하는 것은 이 원칙에 어긋난다. 게다가 이 원칙을 포기하면pop의 구현은 언제나 결함이 생긴다. 다음pop멤버의 원형적 구현을 연구해 보자. 방금 꺼낸 값을 돌려주도록 설계되었다.Type queue::pop() { Type ret(front()); erase_front(); return ret; }예와 같이 꼬리에 독을 품고 있다. 큐는Type의 행위를 통제하지 않기 때문에 마지막 서술문은 예외를 던질 가능성이 있다 (return ret). 그 때 쯤이면 큐의 맨앞 원소는 이미 큐로부터 제거되어 없을 것이다. 그래서 저멀리 사라진다. 그리하여pop멤버를 돌려주는Type는 강력 보장을 제공할 수 없다. 결론적으로pop은 이전의front원소를 돌려주면 안된다. 이 때문에 먼저front를 사용하여 큐의 맨 앞의 원소를 얻은 다음에pop을 사용하여 제거해야 한다.
void push(value): 이 멤버는 value를 큐의 뒤에 추가한다.
size_t size():큐에 있는 원소의 갯수를 돌려준다.
<queue> 헤더를 먼저 포함해야 한다.
선점 큐는 큐와 동일하다. 단, 우선 순위 규칙에 따라 데이터 원소를 삽입하는 것을 허용한다. 실-세계의 선점 큐는 공항 터미널에서 볼 수 있다. 승객들은 줄을 서서 탑승 수속 차례가 오기를 기다린다. 그러나 탑승에 지각한 승객들은 그 큐에 끼어 들어 가도록 허용한다. 그들은 다른 승객보다 더 높은 우선 순위를 받는다.
선점 큐는 자신에게 저장된 유형의 operator<를 사용하여 데이터 원소의 우선 순위를 결정한다. 값이 작을 수록 우선 순위가 그 만큼 더 낮다. 그래서 선점 큐를 사용하여 값들이 도착하는 대로 정렬할 수 있다. 다음은 그런 선점 큐를 적용한 프로그램의 예이다. cin으로부터 단어들을 읽고 단어 리스트를 정렬하여 cout에 쓴다.
#include <iostream>
#include <string>
#include <queue>
using namespace std;
int main()
{
priority_queue<string> q;
string word;
while (cin >> word)
q.push(word);
while (q.size())
{
cout << q.top() << '\n';
q.pop();
}
}
불행하게도 단어는 순서가 반대이다. 아래의 < 연산자 때문에 ASCII-연속열에서 나중에 나타나는 단어가 먼저 선점 큐에 나타난다. 이 문제를 해결하는 한 가지 방법은 string 데이터 유형의 둘레에 포장 클래스를 정의해 string의 operator< 연산자를 뒤집는 것이다. 다음은 수정된 프로그램이다.
#include <iostream>
#include <string>
#include <queue>
class Text
{
std::string d_s;
public:
Text(std::string const &str)
:
d_s(str)
{}
operator std::string const &() const
{
return d_s;
}
bool operator<(Text const &right) const
{
return d_s > right.d_s;
}
};
using namespace std;
int main()
{
priority_queue<Text> q;
string word;
while (cin >> word)
q.push(word);
while (q.size())
{
word = q.top();
cout << word << '\n';
q.pop();
}
}
다른 방법도 같은 효과가 있다. 선점 큐의 내용을 벡터에 저장하면 거기에서 원소들을 역순으로 읽을 수 있다.
선점 큐 컨테이너에 다음 생성자와 연산자 멤버 함수를 사용할 수 있다.
priority_queue<string> object;
벡터처럼 비어 있는 선점 큐에 원소를 참조하는 것은 에러이다.
bool empty():선점 큐에 원소가 없으면 true를 돌려준다.
void pop():선점 큐의 맨 위에 있는 원소를 제거한다. 제거된 원소는 이 멤버로 반환되지 않는다는 것을 주의하라. 빈 선점 큐에 이 멤버를 호출하면 아무 일도 일어나지 않는다. 왜pop의 반환 유형이void인지에 관한 연구는 12.4.4항을 참고하라.
void push(value):선점 큐의 적절한 위치에 value를 삽입한다.
size_t size():선점 큐에 있는 원소의 갯수를 돌려준다.
Type &top():선점 큐의 첫 원소를 참조로 돌려준다. 선점 큐가 비어 있지 않을 경우에만 이 멤버 함수를 사용해야 한다.
<deque>를 포함해야 한다.
데크는 큐와 비슷하다. 단, 읽기와 쓰기가 양끝에서 모두 허용된다. 실제로 데크 유형은 큐에 비해 기능을 더 많이 지원한다. 사용 가능한 멤버 함수를 개관한 다음에 이를 보여준다. 데크는 벡터와 그 벡터의 양끝에서 작동하는 두 개의 큐를 조합한 것이다. 무작위로 원소의 삽입과 삭제가 벡터의 한쪽 끝 또는 양쪽 끝에서 빈번히 일어나는 상황이라면 데크의 사용을 고려해야 한다.
데크에 다음의 생성자와 연산자 그리고 멤버 함수를 사용할 수 있다.
deque<string> object;
벡터처럼 비어 있는 데크에 원소를 참조하는 것은 에러이다.
deque<string> object(5, string("Hello")), // 5 개의 Hello로 초기화
deque<string> container(10); // 10 개의 빈 문자열로 초기화
vector<string>의 데크를 원소 5부터 11 미만까지 초기화하려면 다음과 같이 생성할 수 있다.
extern vector<string> container; deque<string> object(&container[5], &container[11]);
void assign(...):
새로 내용을 데크에 할당한다.
assign(iterator begin, iterator end)[begin, end) 범위에 있는 값들을 데크에 할당한다.
assign(size_type n, value_type const &val)n 개의 val 사본을 데크에 할당한다.
Type &at(size_t idx):
idx첨자 위치에 있는 데크의 원소를 참조로 돌려준다.idx가 데크의 크기를 벗어나면std::out_of_range예외가 던져진다.
Type &back():데크의 마지막 원소를 참조로 돌려준다. 데크가 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
deque::iterator begin():데크의 첫 원소를 가리키는 반복자를 돌려준다.
deque::const_iterator cbegin(): 데크의 첫 원소를 가리키는 상수 반복자를 돌려준다. 데크가 비어 있으면 cend를 돌려준다.
deque::const_iterator cend(): 데크의 마지막 원소 바로 다음 위치를 가리키는 상수 반복자를 돌려준다.
void clear():데크의 모든 원소를 삭제한다.
deque::const_reverse_iterator crbegin(): 데크의 마지막 원소를 가리키는 상수 역방향 반복자를 돌려준다. 데크가 비어 있으면 crend를 돌려준다.
deque::const_reverse_iterator crend(): 데크의 첫 원소 바로 전 위치를 가리키는 상수 역방향 반복자를 돌려준다.
iterator emplace(const_iterator position, Args &&...args)
position다음에 지정된 인자들로부터value_type객체를 생성한다. 새로 생성된 원소는position위치에 삽입된다.
void emplace_back(Args &&...args)
멤버의 인자들로부터 value_type 객체를 생성한다. 새로 생성된 원소는 데크의 마지막 원소 뒤에 삽입된다.
void emplace_front(Args &&...args)
멤버의 인자들로부터 value_type 객체를 생성한다. 새로 생성된 원소는 데크의 첫 원소 앞에 삽입된다.
bool empty(): 데크에 원소가 없으면 true를 돌려준다.
deque::iterator end():데크의 마지막 원소 다음을 가리키는 반복자를 돌려준다.
deque::iterator erase():데크로부터 특정 범위의 원소를 삭제할 수 있다.
erase(pos)pos가 가리키는 원소를 삭제한다. 반복자 ++pos가 반환된다.
erase(first, beyond)[first, beyond) 범위로 나타낸 원소들을 삭제한다. beyond가 반환된다.
Type &front():데크의 첫 원소를 참조로 돌려준다. 데크가 비어 있지 않을 경우에만 이 멤버를 사용해야 한다.
allocator_type get_allocator() const:데크 객체에 의하여 사용된 배당자 객체를 돌려준다.
... insert():원소들을 특정 위치부터 삽입한다. 반환 값은 호출된 insert 버전에 따라 다르다.
size_t max_size():
데크가 포함할 수 있는 원소의 최대 갯수를 돌려준다.
void pop_back():
데크로부터 마지막 원소를 제거한다. 데크가 비어 있으면 아무 일도 일어나지 않는다.
void pop_front():
데크로부터 첫 원소를 제거한다. 데크가 비어 있으면 아무 일도 일어나지 않는다.
void push_back(value):
데크의 끝에 value를 추가한다.
void push_front(value):
데크의 첫 원소 앞에 value를 추가한다.
deque::reverse_iterator rbegin():데크의 마지막 원소를 가리키는 반복자를 돌려준다.
deque::reverse_iterator rend():이 멤버는 데크의 첫 원소 앞을 가리키는 반복자를 돌려준다.
void resize():현재 데크에 저장된 원소의 갯수를 변경한다.
void shrink_to_fit():데크가 할당한 메모리의 양을 현재 크기로 축소한다. 그러나 선택적이므로 구현자는 이를 그냥 무시해도 되고 그렇지 않으면 이 요청을 최적화해도 된다. `크기에 맞게 줄이기' 연산을 보장하기 위하여 다음 상용구를 사용할 수 있다:
deque<Type>(dequeObject).swap(dequeObject)
size_t size():데크의 원소 갯수를 돌려준다.
void swap(argument):데이터 유형이 같은 두 개의 데크를 서로 교체한다.
<map> 헤더를 포함해야 한다.
맵은 키/값 쌍으로 채워진다. 컨테이너가 받을 수 있는 유형이면 다 된다. 유형은 키와 값에 모두 연관되어 있기 때문에 옆꺽쇠 안에 유형을 두 개 지정해야 한다. 페어 컨테이너에 지정했던 것과 비슷하다 (12.2절). 첫 유형은 키의 유형을 나타낸다. 두 번째 유형은 값의 유형을 나타낸다. 키 유형이 string이고 값 유형이 double인 맵이라면 다음과 같이 정의할 수 있다.
map<string, double> object;
연관된 정보에 키를 사용하여 접근할 수 있다. 그 정보를 값이라고 부른다. 예를 들어 전화번호부는 이름을 키로 사용하고 전화 번호와 다른 정보들은 (우편 번호, 주소, 직업 등등) 값으로 사용한다. 맵의 키를 정렬하기 때문에 키의 operator<를 지정해야 한다. 그리고 사용할 수 있어야 의미가 있다. 일반적으로 포인터를 키로 사용하는 것은 나쁜 생각이다. 포인터를 정렬하는 것과 포인터가 가리키는 값을 정렬하는 것은 서로 다르기 때문이다. 키 유형과 값 유형 말고도 세 번째 유형에 비교 클래스를 정의한다. 기본으로 비교 클래스는 std::less<KeyType이다 (18.1.2항). 키 유형의 operator<를 사용하여 두 개의 키 값을 비교한다. 그러므로 KeyType 키 유형과 ValueType 값 유형에 대한 맵의 정의는 다음과 같다.
map<KeyType, ValueType, std::less<KeyType>>
맵에 대한 두 개의 기본 연산은 키/값 조합을 저장하는 것과 주어진 키로 값을 열람하는 것이다. 키를 첨자로 사용하는 첨자 연산자는 둘 모두에 사용할 수 있다. 첨자 연산자를 lvalue로 사용하면 표현식의 rvalue가 맵에 삽입된다. rvalue로 사용되면 키의 연관 값이 열람된다. 각 키는 맵에 한 번만 저장할 수 있다. 같은 키를 다시 입력하면 새 값이 이전에 저장된 값을 대신한다. 저장된 값은 사라진다.
특정한 키/값 조합은 묵시적으로 또는 명시적으로 맵에 삽입된다. 명시적으로 삽입하려면 키/값 쌍을 먼저 생성해야 한다. 이를 위해 맵마다 value_type이 정의되어 있다. 이를 이용하여 맵에 저장이 가능한 값을 생성할 수 있다. map<string, int>에 대한 값은 다음과 같이 생성할 수 있다.
map<string, int>::value_type siValue("Hello", 1);
value_type은 map<string, int>과 연관된다. 키의 유형은 string이고 값의 유형은 int이다. 이름없는 value_type 객체도 자주 사용된다. 예를 들어,
map<string, int>::value_type("Hello", 1);
map<string, int>::value_type(...) 줄을 계속 사용하는 대신에 typedef를 사용하면 타자하는 수고를 덜고 가독성도 개선할 수 있다.
typedef map<string, int>::value_type StringIntValue
typedef 키워드를 사용한 결과 map<string, int>에 대한 값은 이제 다음과 같이 생성할 수 있다.
StringIntValue("Hello", 1);
다른 형태로서 페어를 사용하여 맵에 사용된 키/값 조합을 나타낼 수 있다.
pair<string, int>("Hello", 1);
map<string, int> object;
맵에 저장된 값 자체가 컨테이너일 수 있다는 사실을 눈여겨보라. 다음은 값이 페어인 맵을 정의한다. 맵 컨테이너 안에 페어 컨테이너가 들어있다.
map<string, pair<string, string>> object;
두 개의 닫는 옆꺽쇠를 연속적으로 사용한 것에 주목하라. 그래야 모호성이 생기지 않는다. 표현식에서 이항 연산자로서 사용되는 것과 구문적으로 문맥이 다르기 때문이다.
value_type을 가리키거나 아니면 평범한 페어 객체를 가리킨다. 페어가 사용되면 first 원소는 키의 유형을 나타내고 second 원소는 값의 유형을 나타낸다. 예를 들어:
pair<string, int> pa[] =
{
pair<string,int>("one", 1),
pair<string,int>("two", 2),
pair<string,int>("three", 3),
};
map<string, int> object(&pa[0], &pa[3]);
이 예제에서 pair<string, int> 대신에 map<string, int>::value_type로 작성해도 된다.
begin이 맵을 생성하는 데 사용된 첫 번째 반복자를 나타내고 end가 두 번째 반복자를 나타내면 [begin, end)을 사용하여 맵을 초기화할 것이다. 직관에 어긋나기는 하지만 맵 생성자는 새로운 키만 받아 들인다. pa의 마지막 원소가 "one", 3이라면 오직 "one", 1 원소와 "two", 2 원소 두 개만 맵 컨테이너에 들어간다. "one", 3 원소는 조용하게 무시될 것이다.
맵은 반복자가 가리키는 데이터 사본을 따로 받는다. 이를 다음 예제에 보여준다.
#include <iostream>
#include <map>
using namespace std;
class MyClass
{
public:
MyClass()
{
cout << "MyClass constructor\n";
}
MyClass(MyClass const &other)
{
cout << "MyClass copy constructor\n";
}
~MyClass()
{
cout << "MyClass destructor\n";
}
};
int main()
{
pair<string, MyClass> pairs[] =
{
pair<string, MyClass>("one", MyClass())
};
cout << "pairs constructed\n";
map<string, MyClass> mapsm(&pairs[0], &pairs[1]);
cout << "mapsm constructed\n";
}
/*
출력:
MyClass constructor
MyClass copy constructor
MyClass destructor
pairs constructed
MyClass copy constructor
MyClass copy constructor
MyClass destructor
mapsm constructed
MyClass destructor
MyClass destructor
*/
이 프로그램의 출력을 추적하면 다음과 같은 사실을 볼 수 있다. 먼저, pairs 배열의 이름없는 원소를 초기화하기 위해 MyClass의 객체가 호출된다. 그 다음, 이 객체는 복사 생성자에 의해 pairs 배열의 첫 원소로 복사된다. 다음으로, 원래의 원소는 더 이상 필요하지 않고 파괴된다. 그 시점에 pairs 배열이 생성되어 있다. 그 이후부터 맵은 임시 페어 객체를 생성한다. 임시의 페어 객체는 맵 원소를 생성한 후에 파괴된다. 결국 프로그램이 끝날 때 맵에 저장된 페어 원소도 역시 파괴된다.
첨자 연산자를 사용하면 맵의 원소를 따로따로 열람하거나 재할당할 수 있다. 첨자 연산자의 인자를 키라고 부른다.
주어진 키가 맵에 없으면 새 데이터 원소가 자동으로 맵에 추가된다. 기본 값 또는 기본 생성자를 사용하여 그 새 원소의 값 부분을 초기화한다. 첨자 연산자가 rvalue로 사용되면 이 기본 값이 반환된다.
맵에 새로 원소를 초기화하거나 또다른 원소를 재할당할 때 오른쪽 할당 연산자의 유형은 맵의 값 부분의 유형과 같아야 한다 (아니면 승격이 가능해야 한다). 예를 들어 맵에서 "two" 원소의 값을 추가하거나 변경하려면 다음 서술문을 사용할 수 있다.
mapsm["two"] = MyClass();
mapped_type &at(key_type const &key):key와 연관된 맵의mapped_type를 참조로 돌려준다. 키가 맵에 저장되어 있지 않으면std::out_of_range예외가 일어난다.
map::iterator begin():맵의 첫 원소를 가리키는 반복자를 돌려준다.
map::const_iterator cbegin():맵의 첫 원소를 가리키는 상수 반복자를 돌려준다. 맵이 비어 있으면 cend를 돌려준다.
map::const_iterator cend():맵의 마지막 원소 바로 다음 위치를 가리키는 상수 반복자를 돌려준다.
void clear():맵으로부터 모든 원소를 삭제한다.
size_t count(key):주어진 키가 맵에 있으면 1을 돌려준다. 그렇지 않으면 0을 돌려준다.
map::reverse_iterator crbegin() const:맵의 마지막 원소를 가리키는 반복자를 돌려준다.
map::reverse_iterator crend():맵의 첫 원소 전 위치를 가리키는 반복자를 돌려준다.
pair<iterator, bool> emplace(Args &&...args):emplace의 인자로value_type의 객체를 생성한다. 맵에 이미 같은key_type값을 사용하는 객체가 들어 있으면std::pair가 반환된다. 안에 같은key_type값을 사용하는 객체를 가리키는 반복자와 더불어false값이 들어 있다.key_type값이 발견되지 않으면 새로 생성된 객체가 맵에 삽입되고 반환된std::pair안에는 새로 삽입된value_type을 가리키는 반복자와 더불어true값이 담겨 있다.
iterator emplace_hint(const_iterator position, Args &&...args):
value_type객체를 인자로부터 생성한다. 새로 생성된 원소는 맵에 삽입된다. 단, (args위치에) 주어진 키가 이미 존재하는 경우는 제외한다. 첫 삽입 위치를 찾기 위하여position을 힌트로 사용하여 구현할 수도 있다. 반환된iterator는 주어진 키를 사용하는value_type을 가리킨다. 이미 존재하는value_type을 참조할 수도 있고 새로 추가된value_type을 참조할 수도 있다. 기존의value_type은 교체되지 않는다. 새 값이 추가되면emplace_hint가 돌아올 때 컨테이너의 크기가 증가한다.
bool empty():맵에 원소가 없으면 true를 돌려준다.
map::iterator end():맵의 마지막 원소 다음 위치를 가리키는 반복자를 돌려준다.
pair<map::iterator, map::iterator> equal_range(key):이 멤버는 한 쌍의 반복자를 돌려준다. 각각lower_bound와upper_bound멤버 함수의 반환 값이다. 아래에 소개한다. 이 멤버의 사용법은upper_bound멤버 함수를 연구하면서 제시하겠다.
... erase():맵으로부터 특정 원소 또는 특정 범위의 원소들을 삭제한다.
bool erase(key)key의 원소를 맵으로부터 삭제한다. 값이 삭제되면 true가 반환된다. 주어진 key를 사용하는 원소가 맵에 없으면 false가 반환된다.
void erase(pos)pos가 가리키는 원소를 삭제한다.
void erase(first, beyond)[first, beyond) 범위의 모든 원소들을 삭제한다.
map::iterator find(key):주어진 키의 원소를 가리키는 반복자를 돌려준다. 해당 원소가 없으면end가 반환된다. 다음 예제는find멤버 함수의 사용법을 보여준다.
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<string, int> object;
object["one"] = 1;
map<string, int>::iterator it = object.find("one");
cout << "`one' " <<
(it == object.end() ? "not " : "") << "found\n";
it = object.find("three");
cout << "`three' " <<
(it == object.end() ? "not " : "") << "found\n";
}
/*
출력:
`one' found
`three' not found
*/
allocator_type get_allocator() const:맵 객체가 사용한 배당자 객체의 사본을 돌려준다.
... insert():원소들을 맵에 삽입한다. 그렇지만 기존의 키와 연관된 값들은 새 값으로 교체되지 않는다. 반환 값은 호출된 insert의 버전마다 다르다.
pair<map::iterator, bool> insert(keyvalue)value_type을 새로 삽입한다. 반환 값은 pair<map::iterator, bool>이다. 반환된 bool 필드가 true이면 keyvalue가 맵에 삽입된 것이다. 값이 false이면 keyvalue에 지정된 키가 이미 맵에 있는 것이다. 그래서 keyvalue는 맵에 삽입되지 않았다는 뜻이다. 두 경우 모두 map::iterator 필드는 keyvalue에 지정된 key를 가진 데이터 원소를 가리킨다. 이 변형 insert의 사용법을 다음 예제에 보여준다.
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main()
{
pair<string, int> pa[] =
{
pair<string,int>("one", 10),
pair<string,int>("two", 20),
pair<string,int>("three", 30),
};
map<string, int> object(&pa[0], &pa[3]);
// {four, 40} 그리고 `true' 반환
pair<map<string, int>::iterator, bool>
ret = object.insert
(
map<string, int>::value_type
("four", 40)
);
cout << boolalpha;
cout << ret.first->first << " " <<
ret.first->second << " " <<
ret.second << " " << object["four"] << '\n';
// {four, 40} 그리고 `false' 반환
ret = object.insert
(
map<string, int>::value_type
("four", 0)
);
cout << ret.first->first << " " <<
ret.first->second << " " <<
ret.second << " " << object["four"] << '\n';
}
/*
출력:
four 40 true 40
four 40 false 40
*/
다음과 같이 약간 특이한 생성에 주목하자
cout << ret.first->first << " " << ret.first->second << ...
`ret'는 insert 멤버 함수가 돌려주는 페어와 같다는 것에 주목하라. `first' 필드는 map<string, int> 안을 가리키는 포인터이다. 그래서 map<string, int>::value_type를 가리키는 포인터로 간주할 수 있다. 이 값의 유형 자체가 또 `first' 필드와 `second' 필드가 있는 쌍이다. 결론적으로 `ret.first->first'는 키이고 (string) `ret.first->second'는 값이다 (int).
map::iterator insert(pos, keyvalue)map::value_type을 맵에 삽입할 수도 있다. pos는 무시된다. 삽입된 원소를 가리키는 반복자가 반환된다.
void insert(first, beyond)[first, beyond) 범위의 원소들을 삽입한다 (map::value_type)
key_compare key_comp():키를 비교하기 위해 맵이 사용한 객체의 사본을 돌려준다.map<KeyType, ValueType>::key_compare유형은 맵 컨테이너에 의하여 정의된다.key_compare의 매개변수는 유형이KeyType const &이다. 비교 함수는 첫 번째 키 인자가 두 번째 키 인자보다 먼저 와야 한다면true를 돌려준다. 키와 값을 비교하려면value_comp를 사용하라. 아래에 나열한다.
map::iterator lower_bound(key):key가 지정된key보다 작거나 같은 첫 번째keyvalue원소를 가리키는 반복자를 돌려준다. 그런 원소가 존재하지 않으면end를 돌려준다.
size_t max_size():맵이 수용할 수 있는 원소의 최대 갯수를 돌려준다.
map::reverse_iterator rbegin():맵의 마지막 원소를 가리키는 반복자를 돌려준다.
map::reverse_iterator rend():맵의 첫 원소 앞을 가리키는 반복자를 돌려준다.
size_t size():맵에 있는 원소의 갯수를 돌려준다.
void swap(argument):키/값 유형이 동일한 두 개의 맵을 서로 바꾼다.
map::iterator upper_bound(key):지정된key를 초과하는key를 가진 첫 번째keyvalue원소를 가리키는 반복자를 돌려준다. 그런 원소가 존재하지 않으면end를 돌려준다. 다음 예제는equal_range와lower_bound그리고upper_bound멤버 함수의 사용법을 보여준다.#include <iostream> #include <map> using namespace std; int main() { pair<string, int> pa[] = { pair<string,int>("one", 10), pair<string,int>("two", 20), pair<string,int>("three", 30), }; map<string, int> object(&pa[0], &pa[3]); map<string, int>::iterator it; if ((it = object.lower_bound("tw")) != object.end()) cout << "lower-bound `tw' is available, it is: " << it->first << '\n'; if (object.lower_bound("twoo") == object.end()) cout << "lower-bound `twoo' not available" << '\n'; cout << "lower-bound two: " << object.lower_bound("two")->first << " is available\n"; if ((it = object.upper_bound("tw")) != object.end()) cout << "upper-bound `tw' is available, it is: " << it->first << '\n'; if (object.upper_bound("twoo") == object.end()) cout << "upper-bound `twoo' not available" << '\n'; if (object.upper_bound("two") == object.end()) cout << "upper-bound `two' not available" << '\n'; pair < map<string, int>::iterator, map<string, int>::iterator > p = object.equal_range("two"); cout << "equal range: `first' points to " << p.first->first << ", `second' is " << ( p.second == object.end() ? "not available" : p.second->first ) << '\n'; } /* 출력: lower-bound `tw' is available, it is: two lower-bound `twoo' not available lower-bound two: two is available upper-bound `tw' is available, it is: two upper-bound `twoo' not available upper-bound `two' not available equal range: `first' points to two, `second' is not available */
value_compare value_comp():맵이 키를 비교하기 위해 사용한 객체의 사본을 돌려준다.map<KeyType, ValueType>::value_compare유형은 맵 컨테이너에 의하여 정의된다.value_compare의 매개변수는 유형이value_type const &이다. 비교 함수는 첫 키 인자가 두 번째 키 인자보다 먼저 와야 한다면true를 돌려준다. 이 멤버에 건네진value_type객체의Value_Type원소들은 반환된 함수에 의하여 사용되지 않는다.
begin과 end 반복자를 사용해야 한다.
다음 예제는 간단한 표를 만드는 법을 보여 준다. 맵에 있는 모든 키와 값을 나열해 보여 준다.
#include <iostream>
#include <iomanip>
#include <map>
using namespace std;
int main()
{
pair<string, int>
pa[] =
{
pair<string,int>("one", 10),
pair<string,int>("two", 20),
pair<string,int>("three", 30),
};
map<string, int>
object(&pa[0], &pa[3]);
for
(
map<string, int>::iterator it = object.begin();
it != object.end();
++it
)
cout << setw(5) << it->first.c_str() <<
setw(5) << it->second << '\n';
}
/*
출력:
one 10
three 30
two 20
*/
<map> 헤더를 포함해야 한다.
맵과 다중맵 사이의 큰 차이는 다중맵은 같은 키로 여러 값을 지원하는데 반해 맵은 값이 하나라는 것이다. 다중맵은 여러 값을 받아 동일한 키에 연관짓는다.
맵과 다중맵은 생성자가 같고 멤버 함수가 같다. 단, 첨자 연산자는 멀티맵에 지원되지 않는다. 당연하다. 여러 개체가 같은 키에 허용되면 object[key]에 대하여 어느 값을 반환해야 할 것인가?
다중맵 멤버 함수의 개관은 12.4.7항을 참고하라. 그렇지만 어떤 멤버 함수는 다중맵 컨테이너의 문맥에서 사용될 때 또 눈여겨볼 만하다. 이런 멤버들을 아래에 기술한다.
size_t map::count(key):key에 연관된 원소의 갯수를 돌려준다.... erase():맵으로부터 원소를 삭제한다.
size_t erase(key) 주어진 key를 가진 모든 원소를 삭제한다. 삭제된 원소의 갯수가 반환된다.
void erase(pos) pos가 가리키는 원소를 삭제한다. 다른 원소들은 키가 같아도 삭제되지 않는다.
void erase(first, beyond) 반복자 [first, beyond) 범위의 모든 원소를 삭제한다.
pair<multimap::iterator, multimap::iterator> equal_range(key):반복자 한 쌍을 돌려준다. 각각lower_bound와upper_bound의 반환 값이다. 이 함수는 다중맵에서key가 같은 모든 원소들을 간단하게 결정한다. 사용법은 이 절의 말미에 보여준다.
multimap::iterator find(key):이 멤버는 키가key인 첫 값을 가리키는 반복자를 돌려준다. 해당 원소가 있으면end를 돌려준다. 반복자는 증가하면서 같은key를 가진 모든 원소를 방문할 수 있다.end를 만나거나 반복자의first멤버가key와 더 이상 같지 않을 때까지 방문한다.
multimap::iterator insert():이 멤버 함수는 실패하는 법이 거의 없다. 그래서 multimap::iterator을 돌려준다. pair<multimap::iterator, bool>는 맵 컨테이너가 돌려준다. 반환된 반복자는 새로 추가된 원소를 가리킨다.
lower_bound 함수와 upper_bound 함수는 맵과 다중맵 컨테이너를 똑같이 다룬다. 그러나 다중맵에서의 연산에 좀 더 주의를 기울여야 한다. 다음 예제는 다중맵에 적용된 lower_bound와 upper_bound 그리고 equal_range를 보여준다.
#include <iostream>
#include <map>
using namespace std;
int main()
{
pair<string, int> pa[] =
{
pair<string,int>("alpha", 1),
pair<string,int>("bravo", 2),
pair<string,int>("charley", 3),
pair<string,int>("bravo", 6), // unordered `bravo' values
pair<string,int>("delta", 5),
pair<string,int>("bravo", 4),
};
multimap<string, int> object(&pa[0], &pa[6]);
typedef multimap<string, int>::iterator msiIterator;
msiIterator it = object.lower_bound("brava");
cout << "Lower bound for `brava': " <<
it->first << ", " << it->second << '\n';
it = object.upper_bound("bravu");
cout << "Upper bound for `bravu': " <<
it->first << ", " << it->second << '\n';
pair<msiIterator, msiIterator>
itPair = object.equal_range("bravo");
cout << "Equal range for `bravo':\n";
for (it = itPair.first; it != itPair.second; ++it)
cout << it->first << ", " << it->second << '\n';
cout << "Upper bound: " << it->first << ", " << it->second << '\n';
cout << "Equal range for `brav':\n";
itPair = object.equal_range("brav");
for (it = itPair.first; it != itPair.second; ++it)
cout << it->first << ", " << it->second << '\n';
cout << "Upper bound: " << it->first << ", " << it->second << '\n';
}
/*
출력:
Lower bound for `brava': bravo, 2
Upper bound for `bravu': charley, 3
Equal range for `bravo':
bravo, 2
bravo, 6
bravo, 4
Upper bound: charley, 3
Equal range for `brav':
Upper bound: bravo, 2
*/
특히 다음 특징에 주목하라:
lower_bound와 upper_bound는 키가 존재하지 않으면 주어진 키 다음의 키를 가진 첫 원소를 똑 같이 돌려준다.
multimap에서 키는 정렬되어 있지만 키가 같은 값들은 정렬되어 있지 않다. 열람 순서는 입력된 순서와 같다.
<set> 헤더를 포함해야 한다.
집합에 담긴 값들은 모두 서로 다르다 (유형은 컨테이너에서 받아 들일 수 있어야 함). 각 값들은 한 번만 저장된다.
구체적인 값은 명시적으로 만들 수 있다. 집합 컨테이너마다 value_type을 정의한다. 이 유형으로 값을 생성해 집합에 넣을 수 있다. set<string>에 대한 값은 다음과 같이 생성할 수 있다.
set<string>::value_type setValue("Hello");
std::map 컨테이너처럼 std::set도 값을 비교할 클래스를 선언하는 세 번째 매개변수가 있다. ValueType 값 유형에 대하여 집합의 유형 정의는 다음과 같다.
set<ValueType, std::less<ValueType>>
value_type은 set<string>과 연관되어 있다. 익명의 value_type 객체도 자주 사용된다. 예를 들어,
set<string>::value_type("Hello");
반복적으로 set<string>::value_type(...) 줄을 사용하는 대신에 typedef를 사용하면 타자하는 수고를 줄일 수 있고 가독성도 개선된다.
typedef set<string>::value_type StringSetValue
이 typedef 키워드를 사용하면 set<string>에 대한 값들은 다음과 같이 생성할 수 있다.
StringSetValue("Hello");
대안으로, 집합 유형의 값은 즉시 사용이 가능하다. 그 경우에 유형이 Type인 값은 묵시적으로 set<Type>::value_type으로 변환된다.
집합 컨테이너에 다음 생성자와 연산자 그리고 멤버 함수를 사용할 수 있다.
set<int> object;
int intarr[] = {1, 2, 3, 4, 5};
set<int> object(&intarr[0], &intarr[5]);
집합의 모든 값들은 서로 반드시 달라야 한다는 것에 주의하라. 집합을 생성할 때 같은 값을 반복적으로 저장하는 것은 불가능하다. 같은 값이 반복적으로 나타나더라도 첫 번째 나타난 값만 집합 안으로 삽입된다. 나머지 값들은 조용하게 무시된다.
맵처럼 집합은 데이터 사본을 따로 받는다.
set::iterator begin(): 집합의 첫 번째 원소를 가리키는 반복자를 돌려준다. 집합이 비어 있으면 end가 반환된다.
void clear():집합으로부터 모든 원소를 삭제한다.
size_t count(key):건넨 키가 집합 안에 있으면 1을 돌려준다. 그렇지 않으면 0을 돌려준다.
bool empty():원소가 들어 있지 않으면 true를 돌려준다.
set::iterator end():집합의 마지막 원소 다음 위치를 가리키는 반복자를 돌려준다.
pair<set::iterator, set::iterator> equal_range(key):이 멤버는 한 쌍의 반복자를 돌려준다. 각각lower_bound와upper_bound멤버 함수의 반환 값이다. 아래에 소개한다.
... erase():집합으로부터 특정한 원소 또는 특정 범위의 원소를 삭제한다.
bool erase(value)value 값의 원소를 집합 컨테이너로부터 삭제한다. 그 값이 삭제되면 true가 반환된다. `value' 원소가 없으면 false가 반환된다.
void erase(pos)pos가 가리키는 원소를 삭제한다.
void erase(first, beyond)[first, beyond) 범위의 원소를 삭제한다.
set::iterator find(value):주어진 값의 원소를 가리키는 반복자를 돌려준다. 원소를 사용할 수 없으면 end가 반환된다.
allocator_type get_allocator() const:집합 객체가 사용한 배당자 객체의 사본을 돌려준다.
... insert(): 집합 컨테이너 안으로 원소를 삽입한다. 원소가 이미 있으면 기존의 원소는 그대로 두고 삽입은 무시된다. 반환 값은 호출된 insert 버전에 따라 다르다.
pair<set::iterator, bool> insert(keyvalue)set::value_type을 집합에 삽입한다. 반환 값은 pair<set::iterator, bool>이다. 반환된 bool 필드가 true이면 value 값이 집합에 삽입된 것이다. false 값이면 지정된 원소가 이미 집합에 있다는 뜻이고 그래서 제공된 value 값은 집합에 삽입되지 않는다. 두 경우 모두 set::iterator 필드는 집합에서 지정된 value 값을 가진 데이터 원소를 가리킨다.
set::iterator insert(pos, keyvalue)set::value_type를 집합에 삽입할 수도 있다. pos는 무시된다. 그리고 삽입된 원소를 가리키는 반복자를 돌려준다.
void insert(first, beyond)[first, beyond) 범위가 가리키는 (set::value_type) 원소들을 집합에 삽입한다.
key_compare key_comp():집합이 키를 비교하기 위해 사용한 객체의 사본을 돌려준다.
set<ValueType>::key_compare유형은 집합 컨테이너가 정의하고key_compare의 매개변수는 유형이ValueType const &이다. 첫 인자가 두 번째 인자보다 먼저 와야 한다면 비교 함수는true를 돌려준다.
set::iterator lower_bound(key):
지정된key보다 키가 더 작거나 같은 첫 번째keyvalue원소를 가리키는 반복자를 돌려준다. 그런 원소가 없으면end를 돌려준다.
size_t max_size():집합이 수용할 수 있는 원소의 최대 갯수를 돌려준다.
set::reverse_iterator rbegin():집합의 마지막 원소를 가리키는 반복자를 돌려준다.
set::reverse_iterator rend:집합의 첫 원소 앞을 가리키는 반복자를 돌려준다.
size_t size():집합에 있는 원소의 갯수를 돌려준다.
void swap(argument):데이터 유형이 같은 두 집합을 서로 바꾼다 (argument는 교체할 집합).
set::iterator upper_bound(key):지정된key보다 키가 더 큰 첫 번째keyvalue원소를 가리키는 반복자를 돌려준다. 그런 원소가 없으면end를 돌려준다.
value_compare value_comp():키를 비교하기 위해 집합이 사용한 객체의 사본을 돌려준다.
set<ValueType>::value_compare유형이 집합 컨테이너에 의하여 정의되고value_compare의 매개변수는 유형이ValueType const &이다. 비교 함수는 첫 인자가 두 번째 인자보다 먼저 정렬되어 있으면true를 돌려준다. 연산은key_comp가 돌려주는key_compare객체의 연산과 동일하다.
<set> 헤더를 포함해야 한다.
집합과 다중집합 사이의 큰 차이는 다중집합이 같은 값을 여러 개 받는 반면에 집합은 값을 하나만 받는다는 것이다.
집합과 다중집합은 생성자와 멤버 함수가 같다. 12.4.9항에 다중집합 멤버 함수를 개관하다. 그렇지만 어떤 멤버 함수는 집합 컨테이너의 멤버 함수와 약간 다르게 행위한다. 그런 멤버를 아래에 기술한다.
size_t count(value):다중집합에서 주어진 value와 연관된 원소의 갯수를 돌려준다.
... erase():다중집합으로부터 원소를 삭제한다.
size_t erase(value)value인 원소를 모두 삭제한다. 삭제된 원소의 갯수가 반환된다.
void erase(pos)pos가 가리키는 원소를 삭제한다. 다른 원소들은 값이 같더라도 삭제되지 않는다.
void erase(first, beyond)[first, beyond) 범위의 원소를 모두 삭제한다.
pair<multiset::iterator, multiset::iterator> equal_range(value):
한 쌍의 반복자를 돌려준다. 각각lower_bound와upper_bound의 반환 값이다. 아래에 소개한다. 이 함수는 다중집합에서 값이 같은 모든 원소들을 결정한다.
multiset::iterator find(value):지정된 값을 가지는 첫 번째 원소를 가리키는 반복자를 돌려준다. 해당 원소가 없다면end가 반환된다. 반복자는 증가하면서 주어진value를 값으로 가지는 모든 원소를 방문할 수 있다. 반복자가 더 이상 `value'를 가리키지 않을 때까지 다시 말해,end를 만날 때까지 계속된다.
... insert():이 멤버 함수는 실패가 거의 없다. 그리고 pair<multiset::iterator, bool>이 아니라 multiset::iterator를 집합 컨테이너와 함께 돌려준다. 반환된 반복자는 새로 추가된 원소를 가리킨다.
lower_bound 함수와 upper_bound 함수는 집합과 다중집합 컨테이너를 똑같이 다루지만 다중집합에서의 연산은 좀 더 눈여겨볼 가치가 있다. 다중집합 컨테이너에서 lower_bound와 upper_bound는 키가 존재하지 않으면 결과가 같다. 둘 다 주어진 키를 넘어선 키를 가지는 첫 원소를 돌려준다.
다음은 다중집합의 다양한 멤버 함수의 사용 방법이다.
#include <iostream>
#include <set>
using namespace std;
int main()
{
string
sa[] =
{
"alpha",
"echo",
"hotel",
"mike",
"romeo"
};
multiset<string>
object(&sa[0], &sa[5]);
object.insert("echo");
object.insert("echo");
multiset<string>::iterator
it = object.find("echo");
for (; it != object.end(); ++it)
cout << *it << " ";
cout << '\n';
cout << "Multiset::equal_range(+NOTRANS(ë)ch\")\n";
pair
<
multiset<string>::iterator,
multiset<string>::iterator
>
itpair = object.equal_range("ech");
if (itpair.first != object.end())
cout << "lower_bound() points at " << *itpair.first << '\n';
for (; itpair.first != itpair.second; ++itpair.first)
cout << *itpair.first << " ";
cout << '\n' <<
object.count("ech") << " occurrences of 'ech'" << '\n';
cout << "Multiset::equal_range(+NOTRANS(ë)cho\")\n";
itpair = object.equal_range("echo");
for (; itpair.first != itpair.second; ++itpair.first)
cout << *itpair.first << " ";
cout << '\n' <<
object.count("echo") << " occurrences of 'echo'" << '\n';
cout << "Multiset::equal_range(+NOTRANS(ë)choo\")\n";
itpair = object.equal_range("echoo");
for (; itpair.first != itpair.second; ++itpair.first)
cout << *itpair.first << " ";
cout << '\n' <<
object.count("echoo") << " occurrences of 'echoo'" << '\n';
}
/*
출력:
echo echo echo hotel mike romeo
Multiset::equal_range("ech")
lower_bound() points at echo
0 occurrences of 'ech'
Multiset::equal_range("echo")
echo echo echo
3 occurrences of 'echo'
Multiset::equal_range("echoo")
0 occurrences of 'echoo'
*/
<stack> 헤더를 포함해야 한다.
스택은 먼저 들어온 것이 나중에 나가는 (FILO 또는 LIFO) 데이터 구조이다. 맨 먼저 스택에 들어온 원소가 맨 나중에 나가기 때문이다. 스택은 데이터를 임시로 사용해야 할 때 아주 유용한 데이터 구조이다. 예를 들어 프로그램은 함수의 지역 변수를 저장하기 위해 스택을 유지 관리한다. 이 변수들의 생애는 해당 함수가 살아 있는 동안만 생존한다. 반면에 전역 변수나 정적 지역 변수는 프로그램이 살아 있는 동안 같이 생존한다. 또다른 예는 후위 표기법(RPN(Reverse Polish Notation))을 사용하는 계산기에서 볼 수 있다. 피연산자들은 스택에 보관되고 반면에 연산자는 피연산자를 스택에서 꺼내 작업하고 그 결과를 다시 스택에 넣는다.
스택의 사용 예로서 그림 12를 연구해 보자. 표현식 (3 + 4) * 2를 평가하는 동안 스택의 내용을 보여준다. RPN으로 이 표현식은 3 4 + 2 *이 되고 그림 12는 입력으로부터 각 토큰을 (즉, 피연산자와 연산자) 읽은 후의 스택의 내용을 보여준다. 각 피연산자는 실제로 스택에 들어가 있는 반면에 각 연산자는 스택의 내용을 변경하고 있음을 눈여겨보자.
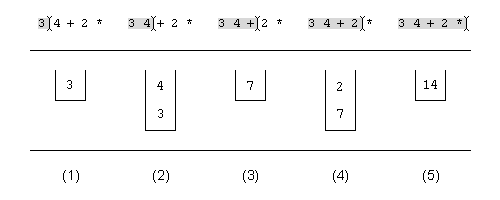
3 4 + 2 *를 평가하는 동안의 스택의 내용
3)는 이제 스택의 바닥에 있다. 다음, 3 단계에서 + 연산자를 읽는다. 이 연산자는 피 연산자 두 개를 꺼내어 (그래서 이 순간 스택은 비어 있다), 합을 계산한다. 그리고 그 결과 값(7)을 스택에 넣는다. 다음, 4 단계에서 숫자 2를 읽는다. 다시 의무적으로 스택에 넣어진다. 마지막으로 5 단계에서 마지막 연산자 *를 읽는다. 이 연산자는 값 2와 7을 스택에서 꺼내어 그 곱을 계산한다. 그리고 결과를 다시 스택에 넣는다. 이 결과(14)를 꺼내어 화면에 보여줄 수 있다.
그림 12를 보면 스택의 한 곳(top)에서만 원소를 넣고 꺼낼 수 있다는 것을 알 수 있다. 이 최상위 원소는 스택에서 유일하게 볼 수 있는 원소이다. 직접적으로 접근하고 변경할 수 있다.
이런 형태의 스택을 염두에 두고 무엇을 할 수 있는지 알아 보자. 스택에 다음 생성자와 연산자 그리고 멤버 함수를 사용할 수 있다.
stack<string> object;
bool empty():이 멤버는 스택 컨테이너에 원소가 없으면 true를 돌려준다.
void pop():스택 상단의 원소를 제거한다. 꺼내어진 원소는 이 멤버로 반환되지 않는다는 사실을 주의하라. 왜pop의 반환 유형이void인지에 관한 연구는 12.4.4항을 참고하라. 스택이 비어 있을 경우pop이 호출되지 않도록 확인하는 것은 스택 사용자의 책임이다. 빈 스택에pop을 호출하면 음수의 크기가 되어 내부 관리가 깨져 버린다 (그 자체로 아주 방대한 스택 크기를 보여준다.size_t를 돌려주는size멤버와push등등의 기타 멤버 때문이다. 물론, 설계가 잘 되어 있는 알고리즘이라면 빈 스택으로부터 원소를 꺼내라는 요구는 일어나지 않는다. 아마도 이 때문에 스택 컨테이너를 이런식으로 구현했을 것이다.).
void push(value):value를 스택 상단에 넣는다. 다른 원소들은 눈에 보이지 않게 된다.size_t size():이 멤버는 스택에 있는 원소의 갯수를 돌려준다.
Type &top():이 멤버는 (유일하게 보이는) 스택의 최상단 원소를 참조로 돌려 준다. 스택이 비어 있지 않을 경우에만 이 멤버를 사용하는 것은 프로그래머의 책임이다.
무순 맵이나 무순 다중맵 컨테이너를 사용하기 전에 헤더 파일 <unordered_map>를 포함해야 한다.
무순 맵 클래스는 연관 배열을 구현한다. 그 안에 원소들이 해싱 체계에 맞추어 저장된다. 언급한 바와 같이 맵은 정렬된 데이터 구조이다. 맵의 키들은 키의 데이터 유형의 operator<를 사용하여 정렬된다. 일반적으로 이것은 데이터를 저장하거나 열람하기에 가장 빠른 방법은 아니다. 정렬된 리스트가 정렬되지 않은 리스트보다 더 편안하게 보인다는 장점은 있다. 그렇지만 좀 빠르게 데이터를 저장하고 열람하려면 해싱을 사용하는 편이 더 좋다.
해싱은 해시 함수를 사용하여 키로부터 (부호없는) 숫자를 계산한다. 이 숫자는 그 다음부터 키와 값을 저장한 테이블에 첨자로 사용된다. 이 숫자를 버킷 번호(bucket number)라고 부른다. 키의 열람은 주어진 키의 해시 값을 계산하는 것 만큼이나 간단하다. 계산된 첨자 위치를 테이블에서 들여다 보기만 하면 된다. 키가 존재하면 테이블에 값이 저장되어 있는 것이다. 계산된 버킷 위치에서 그 값을 열람할 수 있다. 존재하지 않으면 키는 현재 컨테이너에 저장되어 있지 않은 것이다.
계산된 첨자 위치를 이미 다른 원소가 차지하고 있으면 충돌이 일어난다. 이런 상황에 추상 컨테이너는 해결책이 있다. 무순 맵이 사용하는 간단한 해결책은 선형 사슬(linear chaining)을 사용하는 것이다. 이 방법은 충돌하는 테이블 원소들을 연결 리스트에 저장한다.
해시(hash)라는 용어보다 무순 맵이라는 용어를 사용한다. C++ 이전에 개발된 해시 테이블과의 이름 충돌을 피하기 위해서이다.
해싱 방법 때문에 속도면에서 무순 맵이 맵보다 훨씬 더 효율적이다. 무순 집합과 무순 다중맵 그리고 무순 다중집합에 대해서도 비슷하게 결론을 내릴 수 있다.
unordered_map::key_type이 됨),
unordered_map::mapped_type이 됨),
unordered_map::hasher가 됨)
unordered_map::key_equal이 됨).
무순 맵 컨테이너의 총칭적 정의는 다음과 같다.
std::unordered_map <KeyType, ValueType, hash type, predicate type,
allocator type>
KeyType이 std::string이거나 내장 유형이면 해시 유형과 진위 유형에 기본 유형을 사용할 수 있다. 실제로 배당자 유형은 지정되지 않는다. 기본 배당자면 충분하기 때문이다. 이 경우 무순 맵 객체는 다음과 같이 단순히 키 유형과 값 유형으로 정의할 수 있다.
std::unordered_map<std::string, ValueType> hash(size_t size = implSize);
여기에서 implSize는 컨테이너의 최초 기본 크기이다. 구현자가 지정한다. 맵의 크기는 필요하면 무순 맵에 의하여 자동으로 늘어난다. 이 경우 컨테이너는 모든 원소를 다시 해시 처리한다. 실제로 구현자가 제공한 기본 size 인자면 충분하다.
KeyType은 주로 텍스트로 구성된다. 그래서 std::string KeyType을 사용하는 무순 맵이 주로 사용된다. 평범한 char const * key_type를 사용하지 않도록 주의하라. 다른 위치에 저장된 같은 C-문자열을 가리키는 두 개의 char const * 값은 서로 다른 키로 간주된다. 텍스트의 내용이 아니라 포인터 값으로 비교하기 때문이다. 다음은 char const * KeyType의 사용법을 보여 준다. 예제에서 months를 생성할 때 아무 인자도 지정하지 않았음을 눈여겨보라. 기본 값과 기본 생성자를 사용할 수 있기 때문이다.
#include <unordered_map>
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
struct EqualCp
{
bool operator()(char const *l, char const *r) const
{
return strcmp(l, r) == 0;
}
};
struct HashCp
{
size_t operator()(char const *str) const
{
return std::hash<std::string>()(str);
}
};
int main()
{
unordered_map<char const *, int, HashCp, EqualCp> months;
// 아니면 명시적으로:
unordered_map<char const *, int, HashCp, EqualCp>
monthsTwo(61, HashCp(), EqualCp());
months["april"] = 30;
months["november"] = 31;
string apr("april"); // 문자열은 같지만, 포인터가 다름
cout << "april -> " << months["april"] << '\n' <<
"april -> " << months[apr.c_str()] << '\n';
}
/* 출력
april -> 30
april -> 30
*/
다른 KeyType을 사용해야 한다면 무순 맵의 생성자는 키 값으로부터 해시 값을 계산할 해시 생성자 객체(에 대한 상수 참조)를 요구한다. 그리고 두 개의 unordered_map::key_type 객체가 동일할 경우 true를 돌려줄 진위 함수 객체를 요구한다. 상등성을 테스트하는 equal_to 총칭 알고리즘이 존재한다 (제 19장). 키의 데이터 유형이 상등 연산자를 지원하면 이 테스트들을 사용할 수 있다. 대안으로, 중복정의 operator== 또는 특정화된 함수 객체를 생성할 수 있다. 두 개의 키가 같으면 true를 돌려주고 그렇지 않으면 false를 돌려주도록 할 수 있다.
생성자
무순 맵은 다음 생성자를 지원한다.
explicit unordered_map(size_type n = implSize,
hasher const &hf = hasher(),
key_equal const &eql = key_equal(),
allocator_type const &alloc = allocator_type()):unordered_map(const_iterator begin,
const_iterator end,
size_type n = implSize, hasher const &hf = hasher(),
key_equal const &eql = key_equal(),
allocator_type const &alloc = allocator_type()):unordered_map::value_type const 객체의 범위를 지정하는 두 개의 반복자를 기대한다.
unordered_map(initializer_list<value_type> initList,
size_type n = implSize, hasher const &hf = hasher(),
key_equal const &eql = key_equal(),
allocator_type const &alloc = allocator_type()):unordered_map::value_type 값의 initializer_list를 기대한다.
다음 예제는 무순 맵을 사용하는 프로그램을 보여준다. 월별 이름과 월별 날짜가 들어 있다. 첨자 연산자를 사용하여 월별 날짜를 화면에 보여준다 (여기에 사용된 진위 함수는 equal_to<string> 총칭 알고리즘이다. 컴파일러가 무순 맵 생성자의 네 번째 인자로 기본으로 제공한다.):
#include <unordered_map>
#include <iostream>
#include <string>
using namespace std;
int main()
{
unordered_map<string, int> months;
months["january"] = 31;
months["february"] = 28;
months["march"] = 31;
months["april"] = 30;
months["may"] = 31;
months["june"] = 30;
months["july"] = 31;
months["august"] = 31;
months["september"] = 30;
months["october"] = 31;
months["november"] = 30;
months["december"] = 31;
cout << "september -> " << months["september"] << '\n' <<
"april -> " << months["april"] << '\n' <<
"june -> " << months["june"] << '\n' <<
"november -> " << months["november"] << '\n';
}
/*
출력:
september -> 30
april -> 30
june -> 30
november -> 30
*/
KeyType의 값과 연관된 ValueType이 상수 참조로 반환된다. 아직 사용할 수 없으면 그 키는 무순 맵에 추가되고 기본 ValueType 값이 반환된다. 그리고 operator==를 지원한다.
무순 맵은 다음의 멤버 함수를 지원한다 (key_type, value_type 등등. 무순 맵에 정의된 유형들을 참고하라):
mapped_type &at(key_type const &key):key와 연관된 무순 맵의mapped_type를 참조로 돌려준다. 키가 무순 맵에 저장되어 있지 않으면std::out_of_range예외가 던져진다.
unordered_map::iterator begin(): 무순 맵의 첫 원소를 가리키는 반복자를 돌려준다. 비어 있으면 end를 돌려준다.
size_t bucket(key_type const &key):key가 저장된 인덱스 위치를 돌려준다.key가 아직 저장되어 있지 않으면bucket은 첨자 위치를 돌려주기 전에 먼저value_type(key, Value())를 추가한다.
size_t bucket_count():컨테이너에 사용된 슬롯의 갯수를 돌려준다. 각 슬롯마다 한가지 (충돌이 있으면 더 많은) value_type의 객체들이 담겨 있을 수 있다.
size_t bucket_size(size_t index):버킷 위치index에 저장된value_type객체의 갯수를 돌려준다.
unordered_map::const_iterator cbegin():무순 맵의 첫 원소를 가리키는 상수 반복자를 돌려준다. 비어 있으면 cend를 돌려준다.
unordered_map::const_iterator cend():무순 맵의 마지막 원소 바로 다음 위치를 가리키는 상수 반복자를 돌려준다.
void clear():무순 맵의 원소를 모두 삭제한다.
size_t count(key_type const &key):key_typekey을 사용하는value_type객체가 무순 맵에 저장된 횟수를 돌려준다 (이것은 1 또는 0이다).
pair<iterator, bool> emplace(Args &&...args):value_type객체를emplace의 인자로부터 생성한다. 이미 무순 맵 안에key_type값이 같은 객체가 있으면std::pair가 반환된다. 이 반복자는key_type값이 같은 객체와false값을 가리킨다. 그런key_type값이 없으면 새로 생성된 객체가 무순 맵에 삽입되고, 반환된std::pair안에 반복자는 새로 삽입된value_type과 함께true값을 가리킨다.
iterator emplace_hint(const_iterator position, Args &&...args):
value_type객체를 인자로부터 생성한다. 새로 생성된 원소는 무순 맵에 삽입된다. 단, (args에) 주어진 키가 아직 존재하지 않아야 한다. 구현은 삽입 위치를 찾기 위해position을 힌트로 사용할 수도 안 할 수도 있다. 반환된iterator는 주어진 키를 사용하는value_type을 가리킨다. 이미 존재하는value_type또는 새로 추가된value_type을 참조할 수 있다. 기존의value_type은 교체되지 않는다. 값이 새로 추가되면emplace_hint가 돌아올 때 컨테이너의 크기가 증가한다.
bool empty(): 원소가 없으면 true를 돌려준다.
unordered_map::iterator end():마지막 원소 바로 다음을 가리키는 반복자를 돌려준다.
pair<iterator, iterator> equal_range(key):이 멤버는 key와 같은 키를 가진 원소들의 범위를 정의한 반복자 한 쌍을 돌려준다. 무순 맵에서 이 범위는 기껏해야 최대 하나의 원소만 포함한다.
unordered_map::iterator erase():특정 범위의 원소들을 삭제한다.
erase(pos)pos가 가리키는 원소를 삭제한다. 반복자 ++pos가 반환된다.
erase(first, beyond)[first, beyond) 범위로 지정된 원소들을 삭제한다. beyond를 돌려준다.
iterator find(key): 주어진 키를 가진 원소를 가리키는 반복자를 돌려준다. 원소가 없으면 end가 반환된다.
allocator_type get_allocator() const:무순 맵 객체가 사용한 배당자 객체의 사본을 돌려준다.
hasher hash_function() const:무순 맵 객체가 사용한 해시 함수 객체의 사본을 돌려준다.
... insert():
특정 위치부터 원소들을 삽입할 수 있다. 주어진 키가 이미 사용중이면 삽입되지 않는다. 반환 값은 호출된insert()버전에 따라 다르다.pair<iterator, bool>이 반환되면 페어의 첫 멤버는 반복자이다. 이 반복자는value_type유형의 키와 같은 키를 가진 원소를 가리킨다.value가 실제로 삽입되었다면 페어의 두 번째 멤버는true이다. 그렇지 않으면false이다.
pair<iterator, bool> insert(value_type const &value)value를 삽입하려고 시도한다.
pair<iterator, bool> insert(value_type &&tmp)value_type의 이동 생성자를 사용하여 value를 삽입하려고 시도한다.
pair<iterator, bool> insert(const_iterator hint, value_type const &value)value를 삽입하려고 시도한다. value를 삽입할 때 hint를 시작 위치로 사용할 수 있다.
pair<iterator, bool> insert(const_iterator hint, value_type &&tmp)value_type의 이동 생성자를 사용하여 value를 삽입한다. value를 삽입할 때 hint를 시작 위치로 사용할 수 있다.
void insert(first, beyond)[first, beyond) 범위에 원소들을 삽입하려고 시도한다.
void insert(initializer_list <value_type> iniList)iniList의 원소들을 컨테이너에 삽입하려고 시도한다.
hasher key_eq() const: 무순 맵 객체가 사용한 key_equal 함수 객체의 사본을 돌려준다.
float load_factor() const:컨테이너의 현재 하중계수를 즉, size / bucket_count를 돌려준다.
size_t max_bucket_count():무순 맵이 수용할 수 있는 최대 버킷 갯수를 돌려준다.
float max_load_factor() const:load_factor와 동일하다.void max_load_factor(float max):현재의 최대 하중계수를max로 바꾼다. 하중 계수가max에 도달하면 컨테이너는bucket_count를 확장한다. 그리고 원소들을 다시 해시 처리한다. 컨테이너의 기본 최대 하중계수는 1.0이다
size_t max_size():무순 맵이 수용할 수 있는 원소의 최대 갯수를 돌려준다.
void rehash(size_t size):size가 현재 버킷 갯수를 초과하면 버킷 갯수가size로 증가하고 다음 원소들을 다시 해시 처리한다.
void reserve(size_t request):request가 현재 버킷 갯수보다 작거나 같으면 이 호출은 아무 효과가 없다. 그렇지 않으면 버킷 갯수가 적어도request의 갯수만큼 증가하고 원소들을 다시 해시 처리한다.
size_t size():원소의 갯수를 돌려준다.
void swap(unordered_map &other):현재 무순 맵과 대상 무순 맵의 내용을 서로 바꾼다.
무순 다중맵 컨테이너는 operator[]도 없고 at 멤버도 없다.
상응하는 무순 맵 멤버와 다르게 행위하는 멤버를 아래에 모두 기술한다.
at
지원하지 않는다
size_t count(key_type const &key):key_typekey를 사용하는value_type객체가 무순 맵에 저장된 횟수를 돌려준다. 이 멤버는key가 무순 다중맵에 있는지 검증한다.
iterator emplace(Args &&...args):인자로부터value_type객체를 생성한다. 반환된iterator는 새로 삽입된value_type을 가리킨다.
iterator emplace_hint(const_iterator position, Args &&...args):value_type객체를 인자로부터 생성한다. 새로 생성된 원소는 무순 다중맵에 삽입된다. 첫 삽입 위치를 찾기 위하여position을 힌트로 사용하여 구현할 수도 있다. 반환된iterator는 주어진 키를 사용하는value_type을 가리킨다.
pair<iterator, iterator> equal_range(key):이 멤버는 키가 key와 같은 원소의 범위를 정의한 한 쌍의 반복자를 돌려준다.
iterator find(key):주어진 키를 가진 원소를 가리키는 반복자를 돌려준다. 그런 원소가 없으면 end를 돌려준다.
... insert():
특정 위치부터 원소를 삽입할 수 있다. 반환 값은 호출된insert()버전에 따라 다르다. 반환된iterator는 삽입된 원소를 가리킨다.
iterator insert(value_type const &value)value를 삽입한다.
iterator insert(value_type &&tmp)value_type의 이동 생성자를 사용하여 value를 삽입한다.
iterator insert(const_iterator hint, value_type const &value)value를 삽입한다. value를 삽입할 때 hint를 시작 위치로 사용할 수도 있다.
iterator insert(const_iterator hint, value_type &&tmp)value_type의 이동 생성자를 사용하여 value를 삽입한다. value를 삽입할 때 hint를 시작 위치로 사용할 수도 있다.
void insert(first, beyond)[first, beyond) 범위에 원소를 삽입한다.
void insert(initializer_list <value_type> iniList)iniList의 원소들을 삽입한다.
map 컨테이너처럼 원소들을 정렬한다. 정렬이 요점이 아니라면 빠른 찾기는 해시 기반의 집합 또는 다중-집합이 더 좋을 수 있다. C++는 무순 집합과 무순 다중집합이라는 해시-기반의 집합과 다중-집합을 제공한다.
이 해시 기반의 집합 컨테이너를 사용하기 전에 <unordered_set> 헤더를 포함해야 한다.
무순 집합에 저장된 원소들은 변경할 수 없다. 그러나 컨테이너로부터 삽입과 삭제는 가능하다. 무순 맵과 다르게 무순 집합은 ValueType을 사용하지 않는다. 집합은 단순히 원소들을 저장할 뿐이다. 저장된 원소 자체가 키이다.
무순 집합은 무순 맵과 생성자가 같다. 그러나 집합의 value_type은 자신의 key_type과 동일하다.
무순 집합 유형을 정의할 때 네 개의 템플릿 인자를 지정해야 한다.
unordered_set::key_type)
unordered_set::hasher)
unordered_set::key_equal).
무순 집합 컨테이너의 총칭적 정의는 다음과 같다.
std::unordered_set <KeyType, hash type, predicate type, allocator type>
KeyType이 std::string이거나 내장 유형이면 해시 유형과 진위 유형에 기본 유형을 사용할 수 있다. 실제로 배당자 유형은 지정되지 않는다. 기본 배당자로 충분하기 때문이다. 이 경우 무순 집합 객체는 다음과 같이 단순히 키 유형과 값 유형으로 지정하여 정의할 수 있다.
std::unordered_set<std::string> rawSet(size_t size = implSize);
여기에서 implSize는 컨테이너의 기본 초기 크기이다. 구현자가 지정한다. 집합의 크기는 필요하면 자동으로 확대된다. 그 경우 컨테이너는 모든 원소를 다시 해시 처리한다. 실제로 구현자가 제공하는 기본 size 인자면 충분하다.
무순 집합는 다음 생성자를 지원한다.
explicit unordered_set(size_type n = implSize,
hasher const &hf = hasher(),
key_equal const &eql = key_equal(),
allocator_type const &alloc = allocator_type()):unordered_set(const_iterator begin,
const_iterator end,
size_type n = implSize, hasher const &hf = hasher(),
key_equal const &eql = key_equal(),
allocator_type const &alloc = allocator_type()):unordered_set::value_type const 객체의 범위를 지정하는 두 개의 반복자를 기대한다.
unordered_set(initializer_list<value_type> initList,
size_type n = implSize, hasher const &hf = hasher(),
key_equal const &eql = key_equal(),
allocator_type const &alloc = allocator_type()):unordered_set::value_type 값의 initializer_list를 기대한다.
무순 집합은 첨자 연산자를 지원하지 않는다. at 멤버도 지원하지 않는다. 그것 말고는 무순 맵과 멤버가 똑같다. 아래에 무순 맵의 멤버와 다르게 행위하는 멤버들을 연구한다. 나머지 멤버에 대한 설명은 12.4.12.2목을 참고하라.
iterator emplace(Args &&...args):value_type의 객체를args인자로부터 생성한다. 유일하면 집합에 추가된다.value_type을 가리키는 반복자를 돌려준다.
iterator emplace_hint(const_iterator position, Args &&...args):
value_type객체를 인자로부터 생성한다. 새로 생성된 객체가 유일하면 무순 집합에 삽입된다. 삽입 위치를 찾기 위해position을 힌트(hint)로 사용하여 구현할 수도 있다. 반환된iterator는value_type을 가리킨다.
unordered_set::iterator erase():unordered_set에서 특정 범위의 원소를 삭제한다.
erase(key_type const &key)key를 삭제한다. 다음 원소를 가리키는 반복자를 돌려준다.
erase(pos)pos가 가리키는 원소를 삭제한다. 반복자 ++pos이 반환된다.
erase(first, beyond)[first, beyond) 범위의 원소들을 삭제한다. beyond를 돌려준다.
아래는 상응하는 무순 집합 멤버와 다르게 행위하는 멤버를 모두 기술한다.
size_t count(key_type const &key):무순 집합에 저장된value_type객체 중에서key_typekey를 사용하는 객체의 갯수를 돌려준다. 이 멤버는 주로key가 무순 다중집합에 있는지 검증한다.
iterator emplace(Args &&...args):args인자로부터value_type객체를 생성한다. 반환된iterator는 새로 삽입된value_type을 가리킨다.
iterator emplace_hint(const_iterator position, Args &&...args):인자로부터value_type객체를 생성한다. 새로 생성된 인자는 무순 다중집합에 삽입된다. 삽입 지점을 찾기 위해position을 힌트로 사용하여 구현할 수도 있다. 반환된iterator는 주어진 키를 사용하는value_type를 가리킨다.
pair<iterator, iterator> equal_range(key): key와 키가 같은 원소들의 범위를 정의한 한 쌍의 반복자를 돌려준다.
terator find(key):주어진 키를 가진 원소를 가리키는 반복자를 돌려준다. 그런 키가 없으면 end가 반환된다.
... insert():
특정 위치부터 원소들을 삽입할 수 있다. 반환 값은 호출된insert()버전에 따라 다르다. 반환된iterator는 삽입된 원소를 가리킨다.
iterator insert(value_type const &value)value를 삽입한다.
iterator insert(value_type &&tmp)value_type의 이동 생성자를 사용하여 value를 삽입한다.
iterator insert(const_iterator hint, value_type const &value)value를 삽입한다. value를 삽입할 때 hint를 시작 위치로 사용할 수 있다.
iterator insert(const_iterator hint, value_type &&tmp)value_type의 이동 생성자를 사용하여 value를 삽입한다. value를 삽입할 때 hint를 시작 지점으로 사용할 수 있다.
void insert(first, beyond)[first, beyond) 범위에 원소들을 삽입한다.
void insert(initializer_list <value_type> iniList)iniList의 원소들을 컨테이너에 삽입한다.
C++14 표준에 의하면 찾기 키 유형을 마음대로 사용할 수 있다. 비교 연산자가 그 유형을 컨테이너의 키 유형과 비교할 수만 있으면 된다. 그리하여 char const * 키를 사용하여 map<std::string, ValueType>에서 값을 찾을 수 있다 (또는 std::string에 대하여 operator< 중복정의할 수 있다면 유형을 가리지 않는다). 이것을 이른바 이질적인 찾기라고 부른다.
연관 컨테이너에 제공된 비교 함수가 허용하기만 하면 이질적인 찾기가 가능하다. 이를 위해 표준 라이브러리에 std::less와 std::greater 클래스가 추가되었다.
complex 컨테이너는 표준 복소수 연산을 정의한다. complex 컨테이너를 사용하려면 먼저 <complex> 헤더를 포함해야 한다.
복소수의 실수부와 허수부는 컨테이너의 데이터 유형으로 지정된다. 예를 들어:
complex<double>
complex<int>
complex<float>
복소수의 실수부와 허수부는 데이터 유형이 같다는 것을 눈여겨보라.
복소수 객체를 초기화할 때 (또는 할당할 때) 허수부는 초기화나 할당에서 생략해도 된다. 그 결과로 값은 0이 된다. 기본 값으로 두 부분 모두 0이다.
아래는 사용된 complex 유형이 complex<double>이라고 조용하게 간주된다. 이런 가정하에서 복소수는 다음과 같이 초기화된다.
target: 기본 초기화: 실수부와 허수부 모두 0이다.
target(1): 실수부는 1이고 허수부는 0이다.
target(0, 3.5): 실수부는 0이고 허수부는 3.5이다.
target(source): target은 source 값으로 초기화된다.
#include <iostream>
#include <complex>
#include <stack>
using namespace std;
int main()
{
stack<complex<double>>
cstack;
cstack.push(complex<double>(3.14, 2.71));
cstack.push(complex<double>(-3.14, -2.71));
while (cstack.size())
{
cout << cstack.top().real() << ", " <<
cstack.top().imag() << "i" << '\n';
cstack.pop();
}
}
/*
출력:
-3.14, -2.71i
3.14, 2.71i
*/
다음 멤버 함수와 연산자가 복소수에 정의되어 있다 (아래에서 value는 원시의 스칼라 유형이거나 아니면 complex 객체이다):
complex 컨테이너는 다음 연산자도 지원한다.
complex operator+(value):현재의complex컨테이너와value의 합을 돌려준다.
complex operator-(value):현재의complex컨테이너와value의 차를 돌려준다.
complex operator*(value):현재의complex컨테이너와value의 곱을 돌려준다.
complex operator/(value):현재의complex컨테이너를value로 나눈 몫을 돌려준다.
complex operator+=(value):value를 현재의complex컨테이너에 더하고 새 값을 돌려준다.
complex operator-=(value):value를 현재의complex컨테이너로부터 빼고 새 값을 돌려준다.
complex operator*=(value):현재의complex컨테이너를value만큼 곱하고 새 값을 돌려준다
complex operator/=(value):현재의complex컨테이너를value만큼 나누고 새 값을 돌려준다.
Type real():복소수에서 실수부를 돌려준다.
Type imag():복소수에서 허수부를 돌려준다.
complex 컨테이너에 여러 수학 함수를 사용할 수 있다. 예를 들어 abs, arg, conj, cos, cosh, exp, log, norm, polar, pow, sin, sinh 그리고 sqrt가 있다. 이런 모든 함수는 복소수를 인자로 받는 자유 함수이다. 멤버 함수가 아니다. 예를 들어,
abs(complex<double>(3, -5)); pow(target, complex<int>(2, 3));
istream 객체로부터 추출할 수도 있고 ostream 객체 안으로 삽입할 수도 있다. 삽입을 하면 결과는 순서 쌍 (x, y)이며 여기에서 x는 실수부를 나타내고 y는 허수부를 나타낸다. istream 객체로부터 복소수를 추출할 때 같은 형태를 사용할 수도 있다. 그렇지만 더 간단한 형태도 허용한다. 예를 들어 1.2345를 호출할 때 허수부는 0으로 설정된다.
전통적인 공용체는 원시 데이터만 담을 수 있지만 무제한 공용체는 생성자가 정의된 유형의 데이터 필드를 추가할 수 있다. 그런 데이터 필드는 일반적으로 클래스 유형이다. 다음은 무제한 공용체의 한 예이다.
union Union
{
int u_int;
std::string u_string;
};
필드 중 하나에 생성자가 정의되어 있다. 때문에 이 공용체는 무제한 공용체가 된다. 무제한 공용체는 적어도 하나의 필드 유형에는 생성자가 있기 때문에 어떻게 이런 공용체를 생성하고 소멸시킬 것인지가 문제가 된다.
공용체의 int 필드를 바로 전에 또는 유일하게 참조했다면 std::string과 int로 구성된 공용체의 소멸자는 당연히 string의 소멸자를 호출하지 않는다. 마찬가지로 std::string 필드가 사용될 때 그리고 std::string로부터 int 필드로 전환할 때 double 필드에 할당이 일어나기 전에 먼저 std::string의 소멸자가 호출되어야 한다.
컴파일러는 이 문제를 해결하지 못한다. 사실 무제한 공용체에 기본 생성자나 소멸자를 전혀 구현하지 않는다. 위에 보여준 것처럼 무제한 공용체를 정의하려고 시도하면 다음과 같은 에러 메시지를 뱉아낸다.
error: use of deleted function 'Union::Union()'
error: 'Union::Union()' is implicitly deleted because the default
definition would be ill-formed:
error: union member 'Union::u_string' with non-trivial
'std::basic_string<...>::basic_string() ...'
무제한 공용체의 소멸자에 관하여 생각해 보자. u_string의 데이터가 현재 활성 필드이면 확실하게 파괴해야 한다. 그러나 u_int가 현재 활성 필드이면 아무 것도 하지 말아야 한다. 그러나 소멸자가 어떤 필드를 파괴해야 하는지 어떻게 알 것인가? 알지 못한다. 무제한 공용체에 현재 어떤 필드가 활성화되어 있는지 아무 정보도 없기 때문이다.
다음은 이 문제를 해결하는 한 가지 방법이다.
무제한 공용체를 클래스나 구조체 같은 더 큰 거대한 집합체에 내장했다면 그 클래스나 구조체에 꼬리표 데이터 멤버를 줄 수 있다. 그 꼬리표에 현재 활성화된 공용체-필드를 저장한다. 꼬리표를 집합체 안에 열거체 유형으로 정의할 수 있다. 그러면 무제한 공용체를 집합체가 제어할 수 있다. 이런 접근법 아래에서 소멸자는 명시적으로 빈 구현부터 시작한다. 소멸자에게 어느 필드를 파괴할지 알려줄 방법이 없기 때문이다.
Data::Union::~Union()
{};
class Data 집합체 안에 내장한다. 이 집합체에 enum Tag가 제공된다. 공개 구역에 정의되어 있다. 그래서 Data의 사용자는 태그를 요구할 수 있다. Union 자체는 Data 안에서만 사용된다. 그래서 Union은 Data의 비밀 구역에 선언된다. class Data 말고 struct Data를 사용하여 공개 구역에서 시작한다. 그러면 enum Tag 때문에 public: 구역을 지정하는 수고를 하지 않아도 된다.
struct Data
{
enum Tag
{
INT,
STRING
};
private:
union Union
{
int u_int;
std::string u_string;
~Union(); // 아무 조치 없음
// ... 할 일: 멤버 선언
};
Tag d_tag;
Union d_union;
};
Data의 생성자는 int나 string 값을 받는다. 이런 값들을 d_union에 건네려면 다양한 공용체 필드에 Union 생성자가 필요하다. Data 생성자에 일치하면 d_tag도 적절한 값으로 초기화된다.
Data::Union::Union(int value)
:
u_int(value)
{}
Data::Union::Union(std::string const &str)
:
u_string(str)
{}
Data::Data(std::string const &str)
:
d_tag(STRING),
d_union(str)
{}
Data::Data(int value)
:
d_tag(INT),
d_union(value)
{}
Data의 소멸자는 무제한 공용체의 데이터 멤버를 파괴할 책임이 있다. 공용체의 소멸자는 어떤 조치도 수행할 수 없기 때문에 공용체의 적절한 파괴 임무는 Union::destroy 멤버에게 맡긴다. 소멸자가 정의되어 있는 필드들을 파괴한다. d_tag는 현재 사용중인 Union 필드를 저장하고 있기 때문에 Data의 소멸자는 d_tag를 Union::destroy에 건네어 어느 필드를 파괴해야 하는지 알려줄 수 있다.
Union::destroy는 INT 태그에 어떤 조치도 수행할 필요가 없다. 그러나 STRING 태그에 대해서는 u_string이 할당한 메모리를 돌려주어야 한다. 이를 위하여 명시적으로 소멸자가 호출된다. 그러므로 Union::destroy와 Data의 소멸자는 다음과 같이 구현된다.
void Data::Union::destroy(Tag myTag)
{
if (myTag == Tag::STRING)
u_string.~string();
}
Data::~Data()
{
d_union.destroy(d_tag);
}
Union의 복사 생성자와 이동 생성자는 Union의 소멸자와 똑같은 문제를 겪는다. 공용체는 현재 어느 필드가 활성화되어 있는지 알지 못한다. 그러나 Data는 안다. `확장된' 복사 생성자와 이동 생성자를 정의하고 Tag 인자도 받기 때문이다. 이렇게 확장된 생성자는 초기화를 적절하게 수행할 수 있다. Union의 복사 생성자와 이동 생성자는 삭제된다. 그리고 확장된 복사-생성자와 이동 생성자가 선언된다.
Union(Union const &other) = delete;
Union &operator=(Union const &other) = delete;
Union(Union const &other, Tag tag);
Union(Union &&tmp, Tag tag);
잠시 후에 기존의 Union 객체를 사용하여 메모리 블록을 초기화해야 하는 상황을 만나 보겠다. 이 과업은 copy 멤버로 수행할 수 있다. 그 구현이 어렵지 않으며 위의 생성자들도 사용할 수 있다. Union의 비밀 구역에 선언할 수 있다. 위의 생성자들과 매개변수 리스트가 동일하다.
void copy(Union const &other, Tag tag);
void copy(Union &&other, Tag tag);
생성자는 그냥 이런 copy 멤버를 호출하기만 하면 된다.
inline Data::Union::Union(Union const &other, Tag tag)
{
copy(other, tag);
}
inline Data::Union::Union(Union &&tmp, Tag tag)
{
copy(std::move(tmp), tag);
}
흥미롭게도 여기에서 `초기화하기 전에 할당'은 일어나지 않는다. d_union은 어쨌거나 위의 생성자 서술문 블록에 다다를 때까지는 초기화되지 않는다. 그러나 해당 서술문 블록에 도달하는 순간, d_union 메모리는 그저 날 메모리에 불과하다. 이것은 문제가 아니다. copy 멤버는 배치 new를 사용하여 Union의 메모리를 초기화하기 때문이다.
void Data::Union::copy(Union const &other, Tag otag)
{
if (tag == INT)
u_int = other.u_int;
else
new (this) string(other.u_string);
}
void Data::Union::copy(Union &&tmp, Tag tag)
{
if (tag == INT)
u_int = tmp.u_int;
else
new (this) string(std::move(tmp.u_string));
}
Data 객체를 또다른 데이터 객체에 할당하려면 할당 연산자가 필요하다. 할당 연산자의 표준 모습은 다음과 같다.
Class &Class::operator=(Class const &other)
{
Class tmp(other);
swap(*this, tmp);
return *this;
}
이 구현은 예외에 안전하다. `확정 아니면 철회(commit or roll-back)' 보장을 제공한다 (9.6절). 그러나 Data에 적용할 수 있을까?
그것은 Data 객체를 빠르게 교체할 수 있는가 아닌가에 달려 있다 (9.6.1.1목). Union의 필드를 빠르게 교체할 수 있다면 그냥 간단하게 바이트 별로 교환하기만 하면 그걸로 끝이다. 그 경우 Union은 추가로 멤버가 필요없다 (구체적으로 말해 할당 연산자가 필요하지 않다).
그러나 Union의 필드를 빠르게 교체할 수 없다고 가정해 보자. 이 경우 예외에 안전한 할당을 (즉, `확정 아니면 철회'를 보장하는 할당을) 어떻게 구현할 것인가? d_tag 필드는 확실히 문제가 아니다. 그래서 적절하게 할당하는 책임을 Union에 위임한다. Data의 할당 연산자를 다음과 같이 구현한다.
Data &Data::operator=(Data const &rhs)
{
if (d_union.assign(d_tag, rhs.d_union, rhs.d_tag))
d_tag = rhs.d_tag;
return *this;
}
Data &Data::operator=(Data &&tmp)
{
if (d_union.assign(d_tag, std::move(tmp.d_union), tmp.d_tag))
d_tag = tmp.d_tag;
return *this;
}
이제 Union::assign을 구현할 차례이다. 두 Union 모두 다른 필드를 사용하지만 유형이 다른 객체의 교체는 허용한다고 가정하자. 이제 일이 잘못될 가능성이 있다. 왼쪽 공용체는 X 유형을 사용하고 오른쪽 공용체는 Y 유형을 사용하며 그리고 두 유형 모두 할당을 사용한다고 가정해 보자. 먼저 간략하게 표준적인 교체 방법을 살펴보자. 세 단계가 연루되어 있다.
tmp(lhs): 임시 객체를 초기화한다.
lhs = rhs: rhs 객체를 lhs 객체에 할당한다.
rhs = tmp: tmp 객체를 rhs 객체에 할당한다.
swap 자체가 예외를 던지지 않기 때문이다. 어떻게 공용체를 위하여 교체를 구현할 수 있을까? 필드가 알려져 있다고 간주하자 (Tag 값을 Union::swap에 건네면 쉽게 알릴 수 있다):
X tmp(lhs.x): 임시의 X를 초기화한다.
new는 rhs.y로부터 lhs.y를 초기화한다 (대안으로: 배치 new는 기본으로 lhs.y를 초기화한 다음, 표준 lhs.y = rhs.y를 수행한다).
new는 tmp로부터 rhs.x를 초기화한다 (대안으로: 배치 new는 기본으로 rhs.x를 초기화한 다음, 표준 rhs.x = tmp를 수행한다).
C++ 표준의 요구 조건에 의하면 제자리 소멸은 예외를 던지지 않는다. 표준 교체는 할당도 수행하기 때문에 그 부분도 역시 잘 작동할 것이다. 그리고 표준 교체는 복사 생성도 수행하기 때문에 배치 new 연산도 역시 잘 수행될 것이다. 그렇다면 Union에 다음 swap 멤버를 제공해도 된다.
void Data::Union::swap(Tag myTag, Union &other, Tag oTag)
{
Union tmp(*this, myTag); // lhs 저장
destroy(myTag); // lhs 파괴
copy(other, oTag); // rhs 할당
other.destroy(oTag); // rhs 파괴
other.copy(tmp, myTag); // tmp를 통하여 lhs를 저장
}
이제 swap을 사용할 수 있으므로 Data의 할당 연산자를 쉽게 구현할 수 있다.
Data &Data::operator=(Data const &rhs)
{
Data tmp(rhs); // 이동 할당을 위한 tmp(std::move(rhs))
d_union.swap(d_tag, tmp.d_union, tmp.d_tag);
swap(d_tag, tmp.d_tag);
return *this;
}
Union 생성자가 예외를 던지면 어떻게 할까? 이 경우 Data에 '확정 아니면 철회' 할당 연산자를 다음과 같이 제공할 수 있다.
Data &Data::operator=(Data const &rhs)
{
Data tmp(rhs);
// 원래대로 예외를 던지기 전으로 되돌아 온다.
d_union.assign(d_tag, rhs.d_union, rhs.d_tag);
d_tag = rhs.d_tag;
return *this;
}
어떻게 Union::assign을 구현할 것인가? 다음은 assign이 취해야 할 단계이다.
memcpy 연산과 관련된다.
new를 사용하여 다른 객체의 공용체 필드를 현재 객체 안으로 복사한다. 이 때문에 예외가 일어나면:
Union을 복구한다. 그리고 다시 예외를 던진다. 이전의 (유효한) 상태로 되돌아 왔다.
destroy를 호출한다.
Union::assign의 구현이다.
void Data::Union::assign(Tag myTag, Union const &other, Tag otag)
{
char saved[sizeof(Union)];
memcpy(saved, this, sizeof(Union)); // saved <- *this: 날 복사
try
{
copy(other, otag); // *this = other: 예외 가능성
fswap(*this, // *this <-> saved: 교환
*reinterpret_cast<Union *>(saved));
destroy(myTag); // 원래의 *this 파괴
memcpy(this, saved, sizeof(Union)); // 새로운 *this 설치
}
catch (...) // copy가 던졌다.
{
memcpy(this, saved, sizeof(Union)); // 철회: *this 복구
throw;
}
}
소스 배포 디렉토리 yo/containers/examples/unrestricted2.cc에 예제 프로그램을 제공한다. 여기에서 개발한 Data 클래스가 사용된다.