C++는 클래스 템플릿을 많이 사용한다. 제 12장에서 클래스 템플릿으로 구현되어 있는 벡터와 스택 그리고 데크 같은 데이터 구조를 다루어 보았다. 클래스 템플릿은 데이터와 거기에 작용할 알고리즘을 서로 완전히 분리한다. 클래스 템플릿 객체를 정의하거나 선언할 때 데이터 유형만 지정하면 특별한 데이터 구조를 특별한 유형의 데이터와 조합하여 사용할 수 있다 (다음과 같이 stack<int> iStack).
이 장은 클래스 템플릿을 생성하고 사용하는 법을 다룬다. 어떻게 보면 클래스 템플릿은 객체 지향 프로그래밍과 경쟁한다 (제 14장). 객체 지향 프로그래밍은 템플릿과 메커니즘이 비슷하다. 다형성으로 알고리즘의 구현을 미룰 수 있다. 알고리즘이 부분적으로만 구현된 바탕 클래스에서 클래스를 파생시킨다. 알고리즘이 작용할 데이터의 실제 정의와 처리는 파생된 클래스를 정의할 때까지 미룬다. 마찬가지로 템플릿으로 알고리즘이 작용할 데이터의 지정을 미룰 수 있다. 이것은 추상 컨테이너에 확실하게 보인다. 데이터 유형은 그대로 두고 거기에 작용할 알고리즘만 완전하게 지정한다.
제 14장에서 본 바와 같이 다형성과 클래스 템플릿의 사용법 사이에 흥미로운 상응 관계가 존재한다. C++ Coding Standards (Addison-Wesley, 2005)에서 서터(Sutter)와 알렉산드레스쿠(Alexandrescu)는 정적 다형성과 동적 다형성을 언급한다. 동적 다형성은 가상 멤버 함수를 재정의할 때 사용하던 것이다. vtable을 사용하여 실제로 호출될 함수는 바탕 클래스의 포인터가 가리키고 있는 객체 유형에 따라 달라진다. 정적 다형성은 템플릿의 문맥에서 만난다. 22.12절에서 동적 다형성과 비교하고 연구한다.
일반적으로 클래스 템플릿이 다형성보다 사용하기가 더 쉽다. int 스택을 만들기 위해 stack<int> istack이라고 쓰는 편이 확실히 더 쉽다. 비슷한 int 스택을 정의하기 위해 객체 지향 프로그래밍을 사용하여 Istack: public stack 클래스를 새로 상속받아 필요한 모든 멤버 함수를 구현하는 것이 더 어려울 것은 불 보듯 뻔하다. 반면에 클래스 템플릿에서는 정의된 객체마다 다른 각각의 유형에 대하여 또다른 완전한 클래스를 다시 구체화해야 한다. 이것은 객체 지향 프로그래밍의 문맥에서 필요하지 않다. 파생 클래스는 바탕 클래스에 이미 존재하는 함수를 복사하는 것이 아니라 그냥 사용하기 때문이다 (22.11절).
이전에 이미 클래스 템플릿을 사용해 보았다. vector<int> vi와 vector<string> vs와 같은 객체들이 많이 사용된다. 이런식으로 템플릿이 정의되고 구체화되는 데이터 유형은 본질적으로 컨테이너이다. 단순히 유형을 정의하거나 생성하는 클래스 템플릿의 유형이 아니라 클래스 템플릿 유형과 그의 템플릿 매개변수의 조합을 강조한다. 그래서 vector<int>는 유형이다. vector<string>도 마찬가지로 유형이다. 그런 유형은 typedef로 아주 잘 표현할 수 있다.
typedef std::vector<int> IntVector;
typedef std::vector<std::string> StringVector;
IntVector vi;
StringVector vs;
그래서 다음과 같은 경우라면
template <typename T>
void fun(T const ¶m);
다음과 같이 할 수 있다.
vector<int> vi;
fun(vi)
그러면 컴파일러는 T == vectr<int>이라고 추론한다.
반면에 다음과 같은 경우라면
template <typename T>
struct Fun
{
Fun(T const ¶m);
};
다음과 같이 할 수 없다.
vector<int> vi;
Fun fun(vi);
심지어 T가 vector<int>와 같더라도 불가능하다.
이렇게 할 수 없기 때문에 결과적으로 make_... 류의 함수가 양산되었다. make_exception_ptr, make_heap, make_shared, make_signed, make_unique, make_unsigned, 등등 그 외에도 한 무더기의 make_... 함수들이 개인 프로그래머의 필요에 맞게 정의되었을 것이다. 어쨌거나, 다음과 같이 하는 편이 훨씬 더 쉽다.
auto lck = make_lock_guard(aMutex);
이렇게 작성하는 것보다는 말이다.
auto lck = lock_guard<std::mutex>{aMutex};
어떤 면에서 좀 과도해 보이기도 하고 에러를 유발할 것 같기도 하다. 따라서 lock_guard의 템플릿 유형을 지정해야 한다. 제공된 함수의 유형을 컴파일러가 추론할 수 있다는 것이 확실하다면 말이다.
위의 관찰 결과로 C++17 표준에 새로운 구문이 추가되었고 컴파일러는 클래스 템플릿의 유형을 추론할 수 있게 되었다. 이 절은 이 새로운 구문을 다룬다. 컴파일러가 클래스 템플릿의 인자를 어떻게 추론하는지 설명한다.
포인터가 정의되어 있지 않는 한, 클래스 템플릿 객체의 템플릿 인자는 컴파일러가 추론할 수 있다. 이 경우 단순 정의(simple definitions)가 사용된다. 다른 방법으로 explicit 유형 변환을 지정해도 된다.
다음부터 출발한다.
template <class ...Types> // 유형 집합
class Deduce
{
public:
Deduce(Types ...params); // 생성자
void fun(); // 멤버 함수
};
다음은 몇 가지 정의이다.
// 추론: 해설:
// --------------------------------
Deduce first{1}; // 1: int -> Deduce<int> first{1}
Deduce second; // no Types -> Deduce<> second;
Deduce &&ref = Deduce<int>{1}; // int -> Deduce<int> &&ref
template <class Type>
Deduce third{static_cast<Type *>(0)};
third 템플릿은 Deduce 객체를 third에 지정된 유형으로부터 생성하는 요리법이다. 포인터의 유형은 그냥 지정된 유형을 가리키는 포인터이다 (그래서 third<int>로 지정하면 int *라는 뜻이다). 이제 third의 인자 유형을 알 수 있으므로 (즉, int *이므로) 컴파일러는 third{0}이 Deduce<int *>라고 추론한다.
이 Deduce<int *> 객체를 사용하여 이름 붙은 Deduce<int *> 객체를 초기화할 수 있다.
auto x = third<int>; // 완전하게 x를 정의: Deduce<int *> x{0}
Deduce 멤버 함수는 익명 객체와 명명 객체에 의해 사용된다.
x.fun(); // OK: 명명 객체가 호출
third<int>.fun(); // OK: 익명 객체가 호출
다음 예제들은 컴파일되지 않는다.
extern Deduce object; // 객체 정의가 아님
Deduce *pointer = 0; // 어떤 유형이든 상관없음
Deduce function(); // 위와 같음.
함수 유형을 사용하거나 활괄호 정의를 사용하여, 객체를 정의할 때 컴파일러는 템플릿 인자를 다음과 같이 추론한다.
Deduce::Deduce 생성자라면 가상 함수는 다음과 같이 만들어진다.
template <class ...Types>
Deduce<Types ...> imaginary(Types ...params);
이 처리과정을 Deduce 클래스에 적용해 보자. Deduce에 부합하는 가상 함수 집합은 모습이 다음과 같다.
// 이미 만남: 부합
template <class ...Types> // Deduce(Types ...params)
Deduce<Types ...> imaginary(Types ...params);
// 복사 생성자: 부합
template <class ...Types> // Deduce(Deduce<Types ...> const &)
Deduce<Types ...> imaginary(Deduce<Types ...> const &other);
// 이동 생성자, 부합
template <class ...Types> // Deduce(Deduce<Types ...> &&)
Deduce<Types ...> imaginary(Deduce<Types ...> &&tmp);
Deduce first{1}를 구성하면 첫 번째 가상 함수가 중복정의 경쟁에서 승리한다. 결과적으로 class ...Types에 대하여 템플릿 인자 추론에 의해 int가 된다. 그러므로 Deduce<int> first{1}가 정의된다.
내포 클래스 템플릿의 이름은 둘레 클래스의 유형에 따라 결정된다. 내포 클래스 템플릿 이름에 둘레 클래스 이름이 수식자로 덧붙는다. 그런 경우 내포 클래스에 템플릿 인자 추론이 사용된다. 그러나 (이름 식별자에 사용되지 않으므로) 둘레 클래스에는 사용되지 않는다. 다음은 예제이다. 내포 클래스 템플릿을 Deduce에 추가한다.
template <class OuterType>
class Outer
{
public:
template <class InnerType>
struct Inner
{
Inner(OuterType);
Inner(OuterType, InnerType);
template <typename ExtraType>
Inner(ExtraType, InnerType);
};
};
// defining:
Outer<int>::Inner inner{2.0, 1};
이 경우에 컴파일러는 다음의 가상 함수를 사용한다.
template <typename InnerType>
Outer<int>::Inner<InnerType> // 복사 생성자
imaginary(Outer<int>::Inner<InnerType> const &);
template <typename InnerType>
Outer<int>::Inner<InnerType> // 이동 생성자
imaginary(Outer<int>::Inner<InnerType> &&);
template <typename InnerType> // 첫 번째 선언된 생성자
Outer<int>::Inner<InnerType> imaginary(int);
template <typename InnerType> // 두 번째 선언된 생성자
Outer<int>::Inner<InnerType> imaginary(int, InnerType);
template <typename InnerType> // 세 번째 선언된 생성자
template <typename ExtraType>
Outer<int>::Inner<InnerType> imaginary(ExtraType, InnerType);
imaginary(2.0, 1) 호출의 템플릿 인자를 추론한 결과 첫 인자는 double 그리고 두 번째 인자는 int라고 추론한다.
중복정의 해결은 마지막 함수를 선호한다. 그래서 ExtraType: double과 InnerType: int가 선택된다. 결론적으로 다음은,
Outer<int>::Inner inner{2.0, 1};
다음과 같이 정의된다.
Outer<int>::Inner<int> Inner{2.0, 1};
template <class T>
struct Class
{
struct Iterator
{
typedef T type;
// ...
};
Class(Type t);
Class(Iterator begin, Iterator end)
{}
template <class Tp>
Class(Tp a, Tp b)
{}
Iterator begin();
Iterator end();
};
Class::Iterator 인자를 두 개 기대하는 Class 생성자를 구현하려면 아마도 다음과 비슷할 것이다.
template <class T>
Class<T>::Class(Iterator begin, Iterator end)
{
while (begin != end)
d_data.push_back(*begin++);
}
여기에서 d_data는 T 값들을 담고 있는 컨테이너이다. Class 객체는 이제 한 쌍의 Class::Iterators로부터 구성할 수 있다.
Class<int> source;
...
Class<int> dest{source.begin(), source.end()};
여기에서 간단한 템플릿 인자 추론 절차는 int 템플릿 인자를 추론하는 데 실패한다.
Class dest{source.begin(), source.end()};
Class::Iterators를 건네어 Class 객체를 초기화하려고 할 때 컴파일러는 제공된 인자 리스트로부터 Class<Class::Iterator::type>에 사용될 유형을 직접적으로 추론할 수 없다. type을 직접적으로 사용할 수 없기 때문이다. 이것을 Class의 두 번째 생성자와 비교해 보면, 다음으로
Class intObject{12};
컴파일러는 가상 함수를 생성할 수 있다.
template <class Type>
Class <Type> imaginary(Type param)
이 경우에 Type는 int임이 분명하고, 그래서 Class<int> 객체가 구성된다.
Class(Iterator, Iterator)에 똑 같이 시도하면 다음과 같을 것이다.
template <class Iterator>
Class<???> f(Iterator, Iterator);
여기에서 Class의 템플릿 인자는 Iterator와 직접적으로 관련이 없다. 컴파일러는 유형을 추론할 수 없고 결론적으로 컴파일은 실패한다.
비슷한 인자를 세 번째 생성자에 적용한다. 그러면 두 개의 Tp 인자를 받는데, 이 인자들은 Class 템플릿 유형에 상관이 없다.
이와 같이 간단한 유형의 경우에 템플릿 인자 추론은 실패한다. 그렇지만 전혀 방법이 없는 것은 아니다. C++17 표준은 명시적인 변환을 도입했다. 명시적인 변환은 명시적으로 지정된 추론 규칙으로 정의된다. 이 규칙은 클래스의 인터페이스 다음에 추가된다.
명시적으로 지정된 추론 규칙은 클래스 템플릿 생성자의 서명을 클래스 템플릿 유형에 연관짓는다. 클래스 템플릿 객체에 템플릿 인자를 지정한다. 템플릿 객체는 그의 서명이 지정된 생성자를 사용하여 생성된다. 명시적으로 지정되는 추론 규칙의 총칭적인 구문 형태는 다음과 같다.
클래스 템플릿 생성자 서명 -> 결과 클래스 유형;
이것을 Class(Iter begin, Iter end)에 적용해 보자. 그의 서명은 다음과 같다.
template <class Iter>
Class(Iter begin, Iter end)
Iter는 유형이름 type을 정의해야 하기 때문에 이제 결과 클래스 유형을 다음과 같이 만들 수 있다.
Class<typename Iter::type>
이 둘을 조합해 명시적으로 지정된 추론 규칙을 만들어 보자 (이 규칙은 Class 인터페이스 다음 줄에 따로 추가된다.).
template <class Iter>
Class(Iter begin, Iter end) -> Class<typename Iter::type>
이 규칙을 Class의 인터페이스에 추가하면 다음 생성자 호출은 성공적으로 컴파일된다.
Class src{12}; // 이미 OK
Class dest1{src.begin(), src.end()};
// begin()과 end()는 Class<int>::Iterator 객체를
// 돌려준다. Class<int>::Iterator::type 유형이름은
// int로 정의된다. 그래서 Class<int> dest1이 정의된다.
struct Double // 다음 생성에 사용된다.
{
typedef double type;
// ... 멤버 나열 ...
};
Class dest2{Double{}, Double{}};
// Double 구조체는
// 유형이름을 double 유형으로 정의한다. 그래서
// Class<double> dest2가 정의된다.
클래스 안에서 단순히 그 이름을 참조하면 컴파일러는 (이전처럼) 클래스 자체를 사용한다. Class 안에서 Class를 참조하면 컴파일러는 Class를 Class<T>라고 간주한다. 그래서 Class 생성자의 선언부와 정의부는 모습이 다음과 같다.
Class(Class const &other); // 선언
template <class T> // 정의
Class<T>::Class(Class const &other)
{ /* ... */ }
기본 유형이 마음에 안 드는 경우가 있다. 그러면 필요한 유형을 명시적으로 지정해야 한다. dup 멤버를 Class에 추가하면 무슨 일이 일어나는지 연구해 보자:
template <typename T>
template <typename Tp>
auto Class<T>::dup(Tp a, Tp b)
{
return Class(a, b); // 아마도 원하는 바가 아닐 것이다.
} // (본문 참고)
여기에서 Class 안에 있기 때문에 컴파일러는 Class<T>가 반환될 것이라고 추론한다. 그러나 앞 절에서 내린 결론에 의하면 Class를 반복자로부터 초기화할 때 Class<typename Tp::type>을 생성해 돌려주어야 한다. 이 목적을 달성하기 위해 요구되는 유형을 명시적으로 지정한다.
template <typename T>
template <typename Tp>
auto Class<T>::dup(Tp a, Tp b)
{ // OK: 명시적으로 Class 유형을 지정한다.
return Class<typename Tp::type>(a, b);
}
이 예제에 보여주는 바와 같이 간단한 (묵시적인) 또는 명시적인 추론 규칙을 사용할 필요가 없다. 추론 규칙은 클래스의 템플릿 인자를 명시적으로 지정하는 것이 과도해 보이는 표준적인 상황에만 사용하면 된다. 템플릿 인자 추론은 클래스 템플릿을 사용할 때 객체를 간단하게 생성하기 위하여 추가되었다. 그러나 결론적으로 이 추론 규칙을 사용할 필요가 없다. 언제든지 명시적으로 템플릿 인자를 지정할 수 있기 때문이다.
우리의 새 클래스는 환형 큐를 구현한다. 환형 큐 안의 원소는 max_size로 갯수가 고정된다. 새 원소는 뒤에 삽입된다. 머리와 꼬리 원소에만 접근할 수 있다. 머리 원소만 환형 큐로부터 제거할 수 있다. n 개의 원소가 추가되면 다음 원소가 큐의 첫 위치에 (물리적으로) 다시 삽입된다. 환형 큐는 max_size 개의 원소를 보유할 때까지 삽입할 수 있다. 환형 큐에 원소가 하나라도 들어 있으면 원소를 제거할 수 있다. 빈 환형 큐로부터 원소를 제거하거나 포화 상태의 환형 큐에 원소를 더 추가하면 예외가 일어난다. 다른 생성자 외에도 환형 큐는 max_size 개의 원소에 대하여 자신의 객체를 초기화하는 생성자를 제공해야 한다. 이 생성자는 max_size개의 원소에 대하여 메모리를 준비해야 한다. 그러나 그런 원소들의 기본 생성자를 호출하면 안된다 (배치 new연산자의 사용법 참고). 환형 큐는 이동 생성자와 더불어 값 의미구조를 제공해야 한다.
위의 기술에서 환형 큐에 사용된 실제 데이터 유형은 어디에도 언급되어 있지 않다는 사실에 주목하라. 이것은 우리의 클래스를 클래스 템플릿으로 정의해도 좋다는 확실한 징표이다. 다른 방법이 있다면 먼저 이 클래스를 어떤 구체적인 데이터 유형에 대하여 정의할 수 있다. 그 다음에 클래스를 클래스 템플릿으로 변환할 때 그 데이터 유형을 추상화하면 된다.
클래스 템플릿의 실제 생성 방법은 다음 항에 논의한다. 그 다음 항에 CirQue (환형 큐) 클래스 템플릿을 개발한다.
CirQue (환형 큐)라는 클래스 템플릿을 개발하겠다. 이 클래스 템플릿은 템플릿 유형의 매개변수를 하나 가진다. Data가 그것으로서 환형 큐에 저장된 데이터 유형을 나타낸다. 이 클래스 템플릿의 인터페이스는 대강 다음과 같다.
template<typename Data>
class CirQue
{
// 멤버 선언
};
클래스 템플릿의 정의는 함수 템플릿의 정의처럼 시작한다.
template 키워드로 템플릿 정의 또는 선언을 시작한다.
template 키워드 다음에 온다. 쉼표로 구분된 하나 이상의 원소가 담긴 리스트로서 템플릿 매개변수 리스트라고 부른다. 이 리스트는 다음과 같이 여러 원소를 가질 수 있다.
typename Type1, typename Type2, typename Type3
클래스 템플릿에 템플릿 유형의 매개변수가 여럿 선언되어 있다면 클래스 템플릿을 정의할 때 지정하는 템플릿 유형 인자 리스트와 순서대로 일치한다. 예를 들어:
template <typename Type1, typename Type2, typename Type3>
class MultiTypes
{
...
};
MultiTypes<int, double, std::string> multiType;
// Type1은 int, Type2는 double, Type3은 std::string이다.
CirQue에 대하여 Data가 그 형식적 (유형) 이름이다. 함수 템플릿 매개변수 리스트에 사용된 형식 유형과 똑같다.
CirQue 클래스 템플릿을 정의했으면 모든 종류의 환형 큐를 생성하는 데 사용할 수 있다. 그의 생성자 중 하나가 size_t 인자를 기대한다. 환형 큐에 저장할 수 있는 원소의 최대 갯수를 이 인자에 넘기기 때문에 환형 큐는 다음과 같이 정의할 수 있다.
CirQue<int> cqi(10); // 최대 10 개의 정수
CirQue<std::string> cqstr(30); // 최대 30 개의 문자열
이 장의 서두에서 지적했듯이 클래스 템플릿의 이름과 구체화될 데이터 유형을 조합하여 데이터 유형을 정의한다. 또 std::vector를 정의하는 것과 CirQue를 정의하는 것 사이의 유사성을 눈여겨보라.
std::map 컨테이너처럼 클래스 템플릿은 여러 템플릿 유형 매개변수로 정의할 수 있다.
CirQue로 돌아가자. CirQue는 max_size개의 Data 원소를 저장할 수 있어야 한다. 이 원소들은 처음에는 날 메모리를 가리키겠지만 결국 Data *d_data 포인터로 지정된 메모리에 저장된다. 새 원소는 CirQue의 뒤쪽에 추가된다. Data *d_back 포인터는 다음 원소가 저장될 위치를 가리킨다. 마찬가지로 Data *d_front 포인터는 첫 원소의 위치를 가리킨다. 두 개의 size_t 데이터 멤버를 사용하면 CirQue가 넘치지 않도록 관제할 수 있다. d_size는 현재 CirQue에 저장된 원소의 갯수를 나타내고 d_maxSize는 CirQue가 담을 수 있는 원소의 최대 갯수를 나타낸다. 그리하여 CirQue의 데이터 멤버는 다음과 같다.
size_t d_size;
size_t d_maxSize;
Data *d_data;
Data *d_front;
Data *d_back;
클래스 템플릿은 비-유형 매개변수를 정의할 수도 있다. 함수 템플릿 비-유형 매개변수처럼 (정수형) 상수가 되어야 한다. 그의 값은 구체화 시간에 이미 알려져 있어야 한다.
함수 템플릿 비-유형 매개변수와 다르게 클래스 템플릿 비-유형 매개변수의 값은 컴파일러가 클래스 템플릿 멤버에 건넨 인자를 사용하여 추론하지 않는다.
CirQue 클래스 템플릿의 설계를 확장한다고 가정해 보자. 두 번째 (비-유형) size_t Size 매개변수를 정의해 보자. 우리의 의도는 생성자에서 이 Size 매개변수를 사용하는 것이다. Size 개의 Data유형의 원소로 구성된 배열 매개변수를 정의하고자 한다.
CirQue 클래스 템플릿은 이제 다음과 같이 된다 (적절한 생성자만 보여줌).
template <typename Data, size_t Size>
class CirQue
{
// ... 데이터 멤버들
public:
CirQue(Data const (&arr)[Size]);
...
};
template <typename Data, size_t Size>
CirQue<Data, Size>::CirQue(Data const (&arr)[Size])
:
d_maxSize(Size),
d_size(0),
d_data(operator new(Size * sizeof(Data))),
d_front(d_data),
d_back(d_data),
{
std::copy(arr, arr + Size, back_inserter(*this));
}
안타깝게도 이 설정은 우리의 필요를 만족시키지 못한다. 템플릿 비-유형 매개변수의 값들을 컴파일러가 추론해 주지 않기 때문이다. 컴파일러에게 다음 main 함수를 컴파일하라고 요구하면 템플릿 매개변수의 실제 갯수와 요구한 갯수가 서로 일치하지 않는다고 보고한다.
int main()
{
int arr[30];
CirQue<int> ap(arr);
}
/*
컴파일러가 에러를 보고한다.
In function `int main()':
error: wrong number of template arguments (1, should be 2)
error: provided for `template<class Data, size_t Size>
class CirQue'
*/
Size를 기본 값을 가진 비-유형 매개변수로 정의해도 역시 작동하지 않는다. 컴파일러는 언제나 그 값을 명시적으로 지정하지 않는 한, 기본값을 사용한다. 또다른 값을 필요로 하지 않는 한, Size는 0일 것이라고 짐작하고서 우리는 템플릿의 매개변수 유형 리스트에 size_t Size = 0를 지정하고 싶은 유혹에 빠진다. 그렇게 하면 위의 main 함수에 정의된 arr 배열의 실제 크기와 기본 값 0이 서로 일치하지 않게 된다. 컴파일러는 기본값을 사용하므로 다음과 같이 보고한다.
In instantiation of `CirQue<int, 0>':
...
error: creating array with size zero (`0')
그래서 클래스 템플릿은 비-유형 매개변수를 사용해도 좋지만 그 클래스의 객체를 정의할 때는 언제나 유형 매개변수처럼 지정해야 한다. 비-유형 매개변수에 대하여 기본 값을 지정할 수 있다. 그러면 컴파일러는 비-유형 매개변수가 지정되어 있지 않을 경우에 그 기본 값을 사용한다.
(유형이든 비-유형이든) 기본 템플릿 매개변수 값은 템플릿 멤버 함수를 정의할 때 지정하지 않아도 된다. 일반적으로 함수 템플릿의 정의는 (그리하여 클래스 템플릿의 멤버 함수는) 기본 템플릿 (비) 유형 인자를 줄 수 없다. 기본 템플릿 인자를 클래스 템플릿 멤버에 사용해야 한다면 클래스 인터페이스에 지정해야 한다.
함수 템플릿의 비-유형 매개변수와 마찬가지로 클래스 템플릿의 비-유형 매개변수에 대한 기본 인자 값도 상수로만 지정할 수 있다.
const 포인터로 정의된 비-유형 매개변수와 함께 사용할 수 있다.
int를 호출하면 short를 사용할 수 있고 double을 호출하면 long을 사용할 수 있다).
size_t 매개변수를 지정하면 int도 역시 사용할 수 있다.
const 수식자를 사용하여 정의된 변수들은 사용할 수 있다. 값이 절대로 바뀌지 않기 때문이다.
지금까지 배열을 인자로 받는 CirQue 클래스의 생성자를 정의하려고 시도해 왔다. 비록 지금까지의 시도는 모두 실패했지만 아직 선택이 남아 있다. 다음 항에 목적을 달성해 줄 방법을 설명한다.
대조적으로 함수 템플릿을 사용할 때 실제 템플릿 매개변수는 함수를 호출할 때 사용된 인자들로부터 추론된다. 이 덕분에 우리의 문제를 해결해 줄 뒷문이 활짝 열린다. 생성자 자체가 함수 템플릿으로 변환되면 (자신만의 템플릿 헤더를 가지므로) 컴파일러는 비-유형 매개변수의 값을 추론할 수 있을 것이다. 그리고 클래스 템플릿 비-유형 매개변수를 사용하여 그것을 더 이상 명시적으로 지정할 필요가 없다.
그 자체로 템플릿인 클래스 템플릿의 멤버는 (함수 또는 내포 클래스) 멤버 템플릿이라고 부른다.
멤버 템플릿은 다른 템플릿처럼 정의된다. 자신만의 템플릿 헤더가 있다.
이전의 CirQue(Data const (&array)[Size]) 생성자를 멤버 템플릿으로 변환할 때 클래스 템플릿의 Data 유형 매개변수는 여전히 사용할 수 있다. 그러나 멤버 템플릿에 자신만의 비-유형 매개변수를 제공해야 한다. 클래스 인터페이스 선언은 다음과 같다 (부분적으로만 보여줌):
template <typename Data>
class CirQue
{
public:
template <size_t Size>
explicit CirQue(Data const (&arr)[Size]);
};
그의 구현은 다음과 같이 된다.
template <typename Data>
template <size_t Size>
CirQue<Data>::CirQue(Data const (&arr)[Size])
:
d_size(0),
d_maxSize(Size),
d_data(static_cast<Data *>(operator new(sizeof(arr)))),
d_front(d_data),
d_back(d_data)
{
std::copy(arr, arr + Size, back_inserter(*this));
}
이 구현은 STL의 copy 알고리즘과 back_inserter 어댑터를 사용하여 배열의 원소들을 CirQue에 삽입한다. back_inserter를 사용하려면 CirQue는 (공개) typedef 두 개를 정의해야 한다 (18.2.2항):
typedef Data value_type;
typedef value_type const &const_reference;
멤버 템플릿은 다음의 특징이 있다.
template 헤더 두 개를 사용해야 한다. 클래스 템플릿의 template 헤더를 먼저 지정한 후에 멤버 템플릿의 템플릿 헤더가 그 뒤에 따라 온다.
CirQue 객체를 생성하는 데 프로그램이 사용할 수 있다. 예와 같이 객체를 생성할 때 클래스 템플릿에 대하여 데이터 유형을 지정해야 한다. 배열 int array[30]으로부터 CirQue 객체를 생성하기 위하여 다음과 같이 정의한다.
CirQue<int> object(array);
CirQue 클래스의 멤버로 정의된다. 형식 템플릿 매개변수 유형인 Data에 대하여 구체화된다.
namespace SomeName
{
template <typename Type, ...> // 클래스 템플릿 정의
class ClassName
{
...
};
template <typename Type, ...> // 비-인라인 멤버 정의(들)
ClassName<Type, ...>::member(...)
{
...
}
} // 이름공간을 닫는다.
문제가 일어날 가능성은 여전히 남아 있다. 위의 멤버 템플릿 외에도 CirQue<Data>::CirQue(Data const *data)를 정의했다. 어떤 프로토콜을 정의해서 생성자가 CirQue 객체에 저장해야 할 원소의 갯수를 결정하도록 허용할 수 있다 (여기에서는 더 이상 다듬지 않는다). 다음과 같이 정의하면
CirQue<int> object(array);
이제 컴파일러가 사용하는 것은 멤버 템플릿이 아니라 바로 이 후자의 생성자이다.
컴파일러는 이 후자의 생성자를 선택한다. CirQue 클래스의 생성자가 멤버 템플릿보다 더 특정화된 버전이기 때문이다 (21.14절). 이런 문제는 CirQue(Data const *data) 생성자를 멤버 템플릿 안에 정의해 넣고 또 두 개의 매개변수를 사용하는 생성자를 정의하면 해결할 수 있다. 두 번째 매개변수에 복사할 원소의 갯수를 정의한다.
앞의 생성자를 (즉, 멤버 템플릿을) 사용할 때 Data2 템플릿 유형 매개변수를 정의해야 한다. 여기에서 `Data'는 사용할 수 없다. 멤버 템플릿의 템플릿 매개변수는 자신의 클래스의 템플릿 매개변수를 가리기 때문이다. Data 대신에 Data2를 사용하면 이 미묘한 상황이 처리된다. 생성자 CirQue(Data2 const *)의 다음 선언이 CirQue의 헤더 파일에 나타날 수 있다.
template <typename Data>
class CirQue
{
template <typename Data2>
explicit CirQue(Data2 const *data);
}
다음은 두 개의 생성자가 두 개의 CirQue 객체를 정의한 코드에서 선택되는 방식이다.
int main()
{
int array[30];
int *iPtr = array;
CirQue<int> ac(array); // CirQue(Data const (&arr)[Size]) 호출
CirQue<int> acPtr(iPtr); // CirQue(Data2 const *) 호출
}
CirQue의 디자인과 생성 방법을 살펴볼 시간이다.
CirQue 클래스는 다양한 멤버 함수가 있다. 클래스 템플릿 멤버를 생성할 때 일반적인 디자인 원칙을 지켜야 한다. 클래스 템플릿 유형 매개변수는 Type보다는 Type const &로 정의하는 것이 좋다. 방대한 데이터 구조를 불필요하게 복사하는 것을 막기 위해서이다. 템플릿 클래스 생성자는 생성자의 몸체 안에서 멤버 할당이 아니라 멤버 초기화를 사용해야 한다. 멤버 함수 정의는 인-클래스로 제공하지 않는 것이 더 좋다. 클래스 인터페이스 아래에 배치하는 것이 좋다. 클래스 템플릿 멤버 함수는 함수 템플릿이기 때문에 그 정의는 클래스 인터페이스가 있는 헤더 파일에 배치해야 한다. inline 속성을 주어도 된다.
CirQue는 여러 생성자와 (공개) 멤버가 있다. 모든 정의는 클래스 인터페이스 아래에 배치했다.
다음은 그 생성자와 소멸자이다.
explicit CirQue(size_t maxSize = 0):이 생성자는CirQue가max_size Data개의 원소를 저장할 수 있도록 초기화한다. 생성자의 매개변수가 기본 인자 값으로 주어지기 때문에 이 생성자는 또한 기본 생성자로 사용할 수도 있다. 그래서CirQue의 벡터를 정의할 수 있다. 이 생성자는Cirque객체의d_data멤버를 날 메모리 블록으로 초기화하고d_front와d_back은d_data로 초기화된다. 클래스 멤버 함수는 자체로 함수 템플릿이므로 클래스 템플릿 인터페이스 밖의 구현은 반드시 클래스 템플릿의 템플릿 헤더로 시작해야 한다. 다음은CirQue(size_t)생성자를 구현한 것이다.template<typename Data> CirQue<Data>::CirQue(size_t maxSize) : d_size(0), d_maxSize(maxSize), d_data( maxSize == 0 ? 0 : static_cast<Data *>( operator new(maxSize * sizeof(Data))) ), d_front(d_data), d_back(d_data) {}
CirQue(CirQue<Data> const &other):이 복사 생성자는 별다른 특징이 없다.inc비밀 멤버를 사용하여d_back을 증가시키고 (아래 참고) 그리고 배치new를 사용하여other의Data원소들을 현재 객체에 복사한다. 복사 생성자의 구현은 눈에 보이는 그대로이다.template<typename Data> CirQue<Data>::CirQue(CirQue<Data> const &other) : d_size(other.d_size), d_maxSize(other.d_maxSize), d_data( d_maxSize == 0 ? 0 : static_cast<Data *>( operator new(d_maxSize * sizeof(Data))) ), d_front(d_data + (other.d_front - other.d_data)) { Data const *src = other.d_front; d_back = d_front; for (size_t count = 0; count != d_size; ++count) { new(d_back) Data(*src); d_back = inc(d_back); if (++src == other.d_data + d_maxSize) src = other.d_data; } }
CirQue(CirQue<Data> &&tmp):이동 생성자는 그저 현재 객체의d_data포인터를 0으로 초기화하고 임시 객체와 현재 객체를 교환한다 (아래swap멤버 참고).CirQue의 소멸자는d_data를 들여다보고 0이면 즉시 돌아온다. 다음은 그 구현이다.template<typename Data> CirQue<Data>::CirQue(CirQue<Data> &&tmp) : d_data(0) { swap(tmp); }
CirQue(CirQue(Data const (&arr)[Size])):이 생성자는 멤버 템플릿으로 선언된다.Size비-유형 매개변수를 제공한다.Size데이터 원소들을 위한 공간을 할당하고arr의 내용을 새로 배당된 메모리에 복사한다. 다음은 그 구현이다.template <typename Data> template <size_t Size> CirQue<Data>::CirQue(Data const (&arr)[Size]) : d_size(0), d_maxSize(Size), d_data(static_cast<Data *>(operator new(sizeof(arr)))), d_front(d_data), d_back(d_data) { std::copy(arr, arr + Size, back_inserter(*this)); }
CirQue(CirQue(Data const *data, size_t size)):이 생성자는 앞의 생성자와 아주 흡사하게 행위하지만 첫 번째Data원소를 가리키는 포인터와 복사할 원소의 갯수를 나타내는size_t가 제공된다. 이 생성자의 멤버 템플릿의 변형은 현재 설계에서 제외되었다. 이 생성자의 구현은 이전 생성자와 아주 비슷하므로 독자 여러분에게 연습문제로 남긴다.
~CirQue():소멸자는d_data멤버를 조사한다. 0이면 아무 것도 할당되어 있지 않다는 뜻이고 소멸자는 즉시 돌아온다. 이것은 두 가지 상황에 일어날 수 있다. 환형 큐에 원소가 하나도 없거나 정보를 임시 객체로부터 얻은 경우인데, 임시 객체의 이동 연산으로 인하여d_data멤버가 0으로 설정된다. 그렇지 않으면 소멸자를 명시적으로 호출함으로써 그 다음에 그 원소의 날 메모리를 공용 풀에 돌려줌으로써d_size개의 원소들은 파괴된다. 다음은 그 구현이다.template<typename Data> CirQue<Data>::~CirQue() { if (d_data == 0) return; for (; d_size--; ) { d_front->~Data(); d_front = inc(d_front); } operator delete(d_data); }
다음은 Cirque의 멤버이다.
CirQue &operator=(CirQue<Data> const &other):복사 할당 연산자는 표준적인 구현이다.template<typename Data> CirQue<Data> &CirQue<Data>::operator=(CirQue<Data> const &rhs) { CirQue<Data> tmp(rhs); swap(tmp); return *this; }
CirQue &operator=(CirQue<Data> &&tmp):이동 할당 연산자 역시 표준 구현이다. 그의 구현은 그냥swap를 호출할 뿐이기 때문에 인라인 함수 템플릿으로 정의한다.template<typename Data> inline CirQue<Data> &CirQue<Data>::operator=(CirQue<Data> &&tmp) { swap(tmp); return *this; }
void pop_front():CirQue로부터d_front가 가리키는 원소를 제거한다.CirQue가 비어 있으면 예외를 던진다. 예외는CirQue<Data>::EMPTY값으로 던져지는데, 이 값은enum CirQue<Data>::Exception에 의하여 정의된다 (push_back참고). 구현은 눈에 보이는 그대로이다. 제거될 원소의 소멸자를 명시적으로 호출한다.template<typename Data> void CirQue<Data>::pop_front() { if (d_size == 0) throw EMPTY; d_front->~Data(); d_front = inc(d_front); --d_size; }
void push_back(Data const &object):또다른 원소를CirQue에 추가한다.CirQue가 차 있으면CirQue<Data>::FULL예외를 던진다.CirQue가 던질 수 있는 예외는Exception열거체에 정의되어 있다.enum Exception { EMPTY, FULL };
object의 사본이CirQue의 날 메모리에 할당된다. 배치new를 사용한다. 그리고d_size가 증가한다.template<typename Data> void CirQue<Data>::push_back(Data const &object) { if (d_size == d_maxSize) throw FULL; new (d_back) Data(object); d_back = inc(d_back); ++d_size; }
void swap(CirQue<Data> &other):현재CirQue객체를 또다른CirQue<Data>객체와 교환한다.template<typename Data> void CirQue<Data>::swap(CirQue<Data> &other) { char tmp[sizeof(CirQue<Data>)]; memcpy(tmp, &other, sizeof(CirQue<Data>)); memcpy(&other, this, sizeof(CirQue<Data>)); memcpy(this, tmp, sizeof(CirQue<Data>)); }
Data &back():d_back이 가리키는 원소를 참조로 돌려준다 (CirQue가 비어 있으면 결과는 정의되어 있지 않다).template<typename Data> inline Data &CirQue<Data>::back() { return d_back == d_data ? d_data[d_maxSize - 1] : d_back[-1]; }
Data &front():d_front가 가리키는 원소를 참조로 돌려준다 (CirQue가 비어 있으면 결과는 정의되어 있지 않다).template<typename Data> inline Data &CirQue<Data>::front() { return *d_front; }
bool empty() const:CirQue가 비어 있으면true를 돌려준다.template<typename Data> inline bool CirQue<Data>::empty() const { return d_size == 0; }
bool full() const:CirQue가 차 있으면true를 돌려준다.template<typename Data> inline bool CirQue<Data>::full() const { return d_size == d_maxSize; }
size_t size() const:현재CirQue에 저장된 원소의 갯수를 돌려준다.template<typename Data> inline size_t CirQue<Data>::size() const { return d_size; }
size_t maxSize() const:CirQue에 저장할 수 있는 원소의 최대 갯수를 돌려준다.template<typename Data> inline size_t CirQue<Data>::maxSize() const { return d_maxSize; }
마지막으로, 클래스는 비밀 멤버 하나가 있다. inc가 그것인데 순환적으로 증가하는 포인터를 CirQue의 날 메모리 안으로 돌려준다.
template<typename Data>
Data *CirQue<Data>::inc(Data *ptr)
{
++ptr;
return ptr == d_data + d_maxSize ? d_data : ptr;
}
템플릿의 이런 특징을 다듬어서 각 정의마다 따로따로 별도의 함수 템플릿 정의 파일 안에 저장할 수 있다. 그러면 실제로 필요한 함수 템플릿의 정의만 포함하면 될 것이다. 그렇지만 그런 식으로 처리하는 경우는 거의 없다. 대신에 클래스 템플릿을 정의하는 보통의 방법은 인터페이스를 정의하고 나머지 함수 템플릿을 클래스 템플릿의 인터페이스 바로 아래에 정의하는 것이다 (일부 함수는 인라인으로 정의한다).
이제 CirQue 클래스를 정의했으므로 사용할 수 있다. 클래스를 사용하려면 특정 데이터 유형으로 객체를 구체화해야 한다. 다음 예제에서는 std::string 유형에 대하여 구체화한다.
#include "cirque.h"
#include <iostream>
#include <string>
using namespace std;
int main()
{
CirQue<string> ci(4);
ci.push_back("1");
ci.push_back("2");
cout << ci.size() << ' ' << ci.front() << ' ' << ci.back() << '\n';
ci.push_back("3");
ci.pop_front();
ci.push_back("4");
ci.pop_front();
ci.push_back("5");
cout << ci.size() << ' ' << ci.front() << ' ' << ci.back() << '\n';
CirQue<string> copy(ci);
copy.pop_front();
cout << copy.size() << ' ' << copy.front() << ' ' << copy.back() << '\n';
int arr[] = {1, 3, 5, 7, 9};
CirQue<int> ca(arr);
cout << ca.size() << ' ' << ca.front() << ' ' << ca.back() << '\n';
// int *ap = arr;
// CirQue<int> cap(ap);
}
이 프로그램은 다음과 같이 출력한다.
2 1 2
3 3 5
2 4 5
5 1 9
기본 인자를 정의할 때 명심해야 할 것은 클래스의 객체에 많은 경우 적절해야 한다는 것이다. 예를 들어 CirQue 클래스 템플릿에 대하여 템플릿 유형 매개변수 리스트를 바꿀 수 있었다. int를 기본 유형으로 지정할 수 있다.
template <typename Data = int>
기본 인자를 지정할 수 있더라도 여전히 컴파일러에게 객체 정의가 템플릿을 참조한다고 알려야 한다. 기본 템플릿 인자를 사용하여 클래스 템플릿 객체를 초기화할 때 유형 지정은 생략할 수 있지만 옆꺽쇠는 반드시 유지해야 한다. CirQue 클래스에 대하여 기본 유형이 있다고 가정하면 그 클래스의 객체는 다음과 같이 정의할 수 있다.
CirQue<> intCirQue(10);
템플릿 맴버를 정의할 때 기본 템플릿 매개변수는 지정할 수 없다. 그래서 push_back 멤버의 정의는 언제나 똑같이 template 키워드로 시작해야 한다.
template <typename Data>
클래스 템플릿이 여러 템플릿 매개변수를 사용할 때 모두 다 기본 인자를 부여할 수 있다. 기본 함수 인자처럼 일단 기본 값을 사용하면 나머지 모든 템플릿 매개변수도 역시 기본 값을 사용해야 한다. 템플릿 유형 지정 리스트는 쉼표로 시작하지 않아도 되며 연속적으로 쉼표를 여러 개 포함하지 않아도 된다.
template <typename Data>
class CirQue;
클래스 템플릿을 선언할 때 기본 템플릿 인자를 지정할 수도 있다. 그렇지만 기본 템플릿 인자는 클래스 템플릿의 선언과 정의에 둘 다 지정할 수는 없다. 제일 규칙으로서 기본 템플릿 인자는 선언에서는 생략하라. 클래스 템플릿 선언은 객체를 생성할 때 절대로 사용되지 않기 때문이다. 가끔 전방 참조로만 사용될 뿐이다. 이것은 평범한 클래스의 멤버 함수에 대한 기본 매개변수 값 지정과 다르다는 사실에 주목하라. 매개변수의 기본 값은 언제나 멤버 함수를 클래스 인터페이스에 선언할 때 지정된다.
다른 상황으로 템플릿이 사용중일 때 초기화되는 경우가 있다. 초기화가 많이 일어나면 (즉, 서로 다른 많은 소스에 있다면) 이 때문에 컴파일 속도가 상당히 떨어질 수 있다. 다행스럽게도 C++에서 프로그래머는 템플릿이 구체화되지 못하도록 막을 수 있다. extern template 구문을 사용하면 된다. 예를 들어:
extern template class std::vector<int>;
클래스 템플릿을 선언하면 번역 단위에서 사용할 수 있다. 예를 들어 다음 함수는 적절하게 컴파일된다.
#include <vector>
#include <iostream>
using namespace std;
extern template class vector<int>;
void vectorUser()
{
vector<int> vi;
cout << vi.size() << '\n';
}
그러나 주의하라:
vector 헤더를 포함할 필요가 있다. 그러나 extern template 선언 덕분에, 사용된 멤버들 어느 것도 현재 컴파일 단위에 대하여 구체화되지 않을 것이다.
extern template 선언으로 그룹지어 선언되어 있다. 이 사실은 명시적으로 사용된 멤버 뿐만 아니라 숨은 멤버들에게도 적용된다 (복사 생성자, 이동 생성자, 변환 연산자, 승격 하는 동안에 호출되는 생성자들, 등등): 모두 다 컴파일러는 다른 곳에 구체화되어 있다고 가정한다.
독립 프로그램에서 필요한 멤버의 정의를 늦추고 해결하지 못한 외부 참조에 관하여 링커가 불평하기를 기다릴 수도 있다. 그 다음에 이것들을 사용하여 일련의 구체화 선언을 하고 그 다음에 이 선언들을 프로그램에 링크하여 링커를 만족시킨다. 그렇지만 그렇게 간단한 일은 아니다. 왜냐하면 클래스 인터페이스에 멤버를 선언한 방식과 구체화 선언이 엄격하게 일치해야 하기 때문이다. 더 쉬운 접근법은 구체화 소스 파일을 정의하는 것이다. 프로그램에 사용되는 모든 편의기능을 한 함수 안에서 실제로 구체화한다. 그리고 이 함수는 프로그램이 절대로 호출하지 않는다. 다음 구체화 함수를 main이 담긴 소스 파일에 추가하면 필요한 모든 멤버들도 역시 초기화된다고 확신할 수 있다. 다음은 그 방법을 보여주는 예이다.
#include <vector>
#include <iostream>
extern void vectorUser();
int main()
{
vectorUser();
}
// 이 부분은 절대로 호출되지 않는다.
// 선언된 템플릿에 요구되는 모든 특징들 역시 확실하게 구체화하기 위하여 추가한 것이다.
namespace
{
void instantiator()
{
std::vector<int> vi;
vi.size();
}
}
std::vector<int>에 대하여 선언하면):
template class std::vector<int>;그렇지만 이것을 소스 파일에 추가하면 클래스가 완전하게 구체화된다. 즉, 모든 멤버가 이제 구체화되어 버린다. 이것이 원하는 바는 아닐 것이다. 불필요하게 최종 실행 파일의 크기가 커질 수 있기 때문이다.
// 컴파일러는 vector<int>의 요구된 멤버가
// 다른 곳에 이미 구체화되어 있다고 간주한다.
extern template class std::vector<int>;
int main()
{
std::vector<int> vi(5); // 생성자와 operator[] 연산자는
++vi[0]; // 구체화되지 않는다.
}
template <typename Type>
class TheClass
{
static int s_objectCounter;
};
Type을 다르게 지정할 때마다 TheClass<Type>::s_objectCounter 하나만 있게 된다. 다음 객체 정의는 하나의 정적 변수만 구체화한다. 변수는 두 객체 사이에 공유된다.
TheClass<int> theClassOne;
TheClass<int> theClassTwo;
클래스 인터페이스에 정적 멤버를 언급한다고 해서 그것이 곧 이 멤버들이 실제로 정의된다는 뜻은 아니다. 그냥 선언만 되었을 뿐이기 때문에 따로 정의해야 한다. 클래스 템플릿의 정적 멤버도 마찬가지이다. 정적 멤버의 정의는 템플릿 인터페이스 바로 다음에 (즉, 바로 아래에) 제공된다. 예를 들어 s_objectCounter 정적 멤버의 정의는 다음과 같이 클래스 인터페이스 바로 아래에 위치한다.
template <typename Type> // 인터페이스 다음에
int TheClass<Type>::s_objectCounter = 0; // 정의가 온다.
여기에서 s_objectCounter는 유형이 int이다. 그러므로 Type 템플릿 유형 매개변수에 따라 달라지지 않는다. 동일한 Type에 대하여 여러 개의 s_objectCounter를 구체화해도 문제를 일으키지 않는다. 링커가 최종 프로그램에서 단 하나의 객체만 남겨두고 모든 것을 제거할 것이기 때문이다 (21.5절).
클래스 자체의 객체들을 포인터로 요구하는 리스트-류의 생성자에서 정적 변수를 정의할 때 Type 템플릿 유형 매개변수를 사용해야 한다. 예를 들어:
template <typename Type>
class TheClass
{
static TheClass *s_objectPtr;
};
template <typename Type>
TheClass<Type> *TheClass<Type>::s_objectPtr = 0;
언제나 그렇듯이 정의는 정의의 시작에서 거꾸로 변수 이름부터 읽을 수 있다. TheClass<Type> 클래스의 s_objectPtr는 TheClass<Type>의 객체를 가리키는 포인터이다.
템플릿 유형 매개변수 유형의 정적 변수를 정의할 때, 물론 최초 값에 0을 주면 안된다. 기본 생성자가 (예를 들어 Type()) 보통 더 적절하다. 예를 들어:
template <typename Type> // s_type의 정의
Type TheClass<Type>::s_type = Type();
typename 키워드는 템플릿 유형 매개변수를 나타내는 데 사용되었다. 그렇지만 또한 템플릿 안의 코드를 명확하게 하는 데에도 사용할 수 있다. 다음 함수 템플릿을 연구해 보자:
template <typename Type>
Type function(Type t)
{
Type::Ambiguous *ptr;
return t + *ptr;
}
이 코드를 컴파일러가 처리할 때 다음과 같은 에러 메시지로 불평한다 - 언뜻 보면 당황스럽다- :
4: error: 'ptr' was not declared in this scope
4: 에러: 'ptr'이 이 영역에 선언되어 있지 않습니다.
이 에러 메시지는 당황스럽다. 클래스 템플릿 Type 안에 정의된 Ambiguous 유형을 포인터로 선언하는 것이 프로그래머의 의도였기 때문이다. 그러나 컴파일러는 Type::Ambiguous를 마주하고서 그 서술문을 다른 방식으로 이해할 수도 있다. 분명히 컴파일러는 Type의 진짜 성질을 알아 보기 위해 Type 자체를 들여다 볼 수 없다. Type이 템플릿 유형이기 때문이다. 이 때문에 Type의 실제 정의는 아직 사용할 수 없다.
컴파일러는 두 가지 가능성을 마주한다. Type::Ambiguous가 아직 미지의 템플릿 Type의 정적 멤버이거나 아니면 Type의 부유형(subtype)이거나 둘 중에 하나다. 표준에 의하면 컴파일러는 전자를 가정해야 하기 때문에 다음 서술문은
Type::Ambiguous *ptr;
Type::Ambiguous 정적 멤버와 (지금은 선언이 안 된) ptr 객체를 곱하는 것으로 이해한다. 에러 메시지의 원인은 이제 명백하다. 이 문맥에서 ptr을 모르기 때문이다.
한 식별자가 템플릿 유형 매개변수의 부유형을 참조하는 코드를 명확하게 하려면 typename 키워드를 사용해야 한다. 따라서 위의 코드는 다음과 같이 변경된다.
template <typename Type>
Type function(Type t)
{
typename Type::Ambiguous *ptr;
return t + *ptr;
}
클래스는 부유형(subtypes)을 상당히 자주 정의한다. 그런 부유형이 템플릿 정의 안에 템플릿 유형 매개변수의 부유형으로 나타날 때 typename 키워드를 사용하여 부유형임을알려 주어야 한다. 예를 들어 Handler 클래스 템플릿은 typename Container를 템플릿 유형 매개변수로 정의한다. 또 컨테이너의 begin 멤버가 돌려주는 반복자를 저장하는 데이터 멤버도 정의한다. 게다가 Handler는 begin 멤버를 지원하는 컨테이너를 받는 생성자를 제공한다. 그러면 Handler의 클래스 인터페이스는 다음과 같이 보일 수 있다.
template <typename Container>
class Handler
{
Container::const_iterator d_it;
public:
Handler(Container const &container)
:
d_it(container.begin())
{}
};
이 클래스를 설계할 때 무엇을 염두에 두었는가?
typename Container는 반복자를 지원하는 컨테이너를 대표한다.
begin 멤버를 지원해야 한다. d_it(container.begin()) 초기화는 확실히 템플릿 유형 매개변수에 따라 달라진다. 그래서 기본적인 구문의 정확성에 대해서만 점검한다.
const_iterator를 지원해야 한다. Container 클래스에 정의되어 있다.
typename 키워드가 요구되는 상황을 연구해 보자. 이것이 생략되고 Handler 클래스가 구체화되면 컴파일러는 특이한 컴파일 에러를 일으킨다.
#include "handler.h"
#include <vector>
using namespace std;
int main()
{
vector<int> vi;
Handler<vector<int> > ph(vi);
}
/*
에러 보고:
handler.h:4: error: syntax error before `;' token
*/
분명히 다음 줄은
Container::const_iterator d_it;
Handler 클래스에서 문제를 야기한다. 부유형이 아니라 정적 멤버로 컴파일러가 이해하기 때문이다. 문제는 typename 키워드를 사용하면 해결된다.
template <typename Container>
class Handler
{
typename Container::const_iterator d_it;
...
};
다음의 Handler의 생성자 구현을 사용하여 main을 컴파일해 보면 마주하는 에러 메시지는 흥미로운 사실을 보여준다. 컴파일러는 실제로 X::a가 X 클래스의 멤버 a라고 간주한다.
Handler(Container const &container)
:
d_it(container.begin())
{
size_t x = Container::ios_end;
}
/*
에러 보고:
error: `ios_end' is not a member of type `std::vector<int,
std::allocator<int> >'
*/
이 절의 서두에 소개했던 함수 템플릿이 Type 값이 아니라 Type::Ambiguous를 돌려준다면 이제 무슨 일이 일어나는지 연구해 보자. 다시, 템플릿 유형의 부유형을 참조하고 typename 키워드를 사용해야 한다.
template <typename Type>
typename Type::Ambiguous function(Type t)
{
return t.ambiguous();
}
반환 유형 지정에 typename을 사용하는 것은 23.1.1절에서 더 깊이 다룬다.
typename 키워드는 typedef 안에 내장할 수 있다. 흔히 그렇듯이 이렇게 하면 다른 곳에 나타나는 선언과 정의의 복잡성이 줄어든다. 다음 예제에서 Iterator 유형은 Container 템플릿 유형의 부유형으로 정의된다. 이제 typename 키워드를 사용하지 않아도 Iterator를 사용할 수 있다.
template <typename Container>
class Handler
{
typedef typename Container::const_iterator Iterator;
Iterator d_it;
...
};
CirQue 클래스는 다양한 유형에 사용할 수 있다. 공통적인 특징은 d_data 멤버로 쉽게 가리킬 수 있다는 것이다. 그러나 언제나 이것이 보기만큼 쉬운 것은 아니다. Data가 vector<int>라면 어떻게 되는가? 그런 데이터 유형에는 순수한 CirQue 구현을 사용할 수 없다. 특정화를 고려할 수 있다. 상속도 함께 고려할 수 있다. 종종 클래스 템플릿으로부터 파생된 클래스는 쉽게 설계할 수 있다. 비호환 데이터 구조를 인자로 받는 것 말고는 원래 클래스 템플릿과 동일하다. 특정화보다 상속으로 개발하는 것으로부터 얻는 장점은 명백하다. 상속받은 클래스는 바탕 클래스의 멤버들을 상속받기 때문이다. 반면에 특정화는 아무것도 상속받지 않는다. 원래 클래스 템플릿에 정의된 모든 멤버는 클래스 템플릿의 특정화에서 다시 구현해야 한다.
여기에서 고려하는 특정화는 진짜 특정화이다. 특정화에 사용된 데이터 멤버와 표현이 원래의 CirQue 클래스 템플릿과 크게 다르기 때문이다. 그러므로 원래 클래스 템플릿에 정의된 모든 멤버는 특정화의 데이터 조직에 맞게 변경해야 한다.
함수 템플릿 특정화처럼 클래스 템플릿 특정화는 template 헤더로 시작하고 다음에 템플릿 매개변수 리스트가 올 수도 있다. 템플릿 매개변수는 직접적으로 초기화된다. 템플릿 매개변수가 직접적으로 특정화되더라도 매개변수 리스트는 여전히 비어 있다. (예를 들어 CirQue의 템플릿 유형 매개변수 Data는 char * 데이터에 대하여 특정화된다). 그러나 유형에 상관없이 데이터를 저장한 벡터에 대하여, 다시 말해, vector<Data>에 대하여 특정화할 때 템플릿 매개변수 리스트는 typename Data를 보여주어도 된다. 이 때문에 다음의 원칙이 도출된다.
템플릿 특정화는 템플릿 인자 리스트 다음에 함수나 클래스 템플릿의 이름으로 인지된다. 빈 템플릿 매개변수 리스트로 인지되지 않는다. 클래스 템플릿 특정화는 비어 있지 않은 템플릿 매개변수 리스트를 가질 수 있다. 그렇다면 부분적 클래스 템플릿 특정화가 정의된다.
완벽하게 특정화된 클래스는 다음의 특징이 있다.
template <> 헤더로 시작하지 않을 수도 있다. 그렇지 않다면 멤버 함수의 헤더와 함께 즉시 시작해야 한다.
CirQue 클래스의 예이다. vector<int>에 대하여 특정화되었다. 특정화된 클래스의 모든 멤버가 선언된다. 그러나 그의 멤버 중에 비-간이 구현만 제공된다. 특정화된 클래스는 생성자에 건넨 vector의 사본을 사용한다. 그리고 vector 데이터 멤버를 사용하여 환형 큐를 구현한다.
#ifndef INCLUDED_CIRQUEVECTOR_H_
#define INCLUDED_CIRQUEVECTOR_H_
#include <vector>
#include "cirque.h"
template<>
class CirQue<std::vector<int>>
{
typedef std::vector<int> IntVect;
IntVect d_data;
size_t d_size;
typedef IntVect::iterator iterator;
iterator d_front;
iterator d_back;
public:
typedef int value_type;
typedef value_type const &const_reference;
enum Exception
{
EMPTY,
FULL
};
CirQue();
CirQue(IntVect const &iv);
CirQue(CirQue<IntVect> const &other);
CirQue &operator=(CirQue<IntVect> const &other);
int &back();
int &front();
bool empty() const;
bool full() const;
size_t maxSize() const;
size_t size() const;
void pop_front();
void push_back(int const &object);
void swap(CirQue<IntVect> &other);
private:
iterator inc(iterator const &iter);
};
CirQue<std::vector<int>>::CirQue()
:
d_size(0)
{}
CirQue<std::vector<int>>::CirQue(IntVect const &iv)
:
d_data(iv),
d_size(iv.size()),
d_front(d_data.begin()),
d_back(d_data.begin())
{}
CirQue<std::vector<int>>::CirQue(CirQue<IntVect> const &other)
:
d_data(other.d_data),
d_size(other.d_size),
d_front(d_data.begin() + (other.d_front - other.d_data.begin())),
d_back(d_data.begin() + (other.d_back - other.d_data.begin()))
{}
CirQue<std::vector<int>> &CirQue<std::vector<int>>::operator=(
CirQue<IntVect> const &rhs)
{
CirQue<IntVect> tmp(rhs);
swap(tmp);
}
void CirQue<std::vector<int>>::swap(CirQue<IntVect> &other)
{
char tmp[sizeof(CirQue<IntVect>)];
memcpy(tmp, &other, sizeof(CirQue<IntVect>));
memcpy(&other, this, sizeof(CirQue<IntVect>));
memcpy(this, tmp, sizeof(CirQue<IntVect>));
}
void CirQue<std::vector<int>>::pop_front()
{
if (d_size == 0)
throw EMPTY;
d_front = inc(d_front);
--d_size;
}
void CirQue<std::vector<int>>::push_back(int const &object)
{
if (d_size == d_data.size())
throw FULL;
*d_back = object;
d_back = inc(d_back);
++d_size;
}
inline int &CirQue<std::vector<int>>::back()
{
return d_back == d_data.begin() ? d_data.back() : d_back[-1];
}
inline int &CirQue<std::vector<int>>::front()
{
return *d_front;
}
CirQue<std::vector<int>>::iterator CirQue<std::vector<int>>::inc(
CirQue<std::vector<int>>::iterator const &iter)
{
iterator tmp(iter + 1);
tmp = tmp == d_data.end() ? d_data.begin() : tmp;
return tmp;
}
#endif
다음 예제는 특정화된 CirQue 클래스를 사용하는 법을 보여준다.
static int iv[] = {1, 2, 3, 4, 5};
int main()
{
vector<int> vi(iv, iv + 5);
CirQue<vector<int>> ci(vi);
cout << ci.size() << ' ' << ci.front() << ' ' << ci.back() << '\n';
ci.pop_front();
ci.pop_front();
CirQue<vector<int>> cp;
cp = ci;
cout << cp.size() << ' ' << cp.front() << ' ' << cp.back() << '\n';
cp.push_back(6);
cout << cp.size() << ' ' << cp.front() << ' ' << cp.back() << '\n';
}
/*
출력:
5 1 5
3 3 5
4 3 6
*/
부분적 특정화로 템플릿 유형 매개변수의 일부에 구체적인 값이 주어진다. 클래스 템플릿을 특정화하되 특정화로 처리되는 데이터 유형을 매개변수화하고자 할 때 클래스 템플릿을 부분적으로 특정화하는 것도 가능하다.
부분적 클래스 템플릿 특정화를 후자처럼 사용하는 예제를 연구하기 위하여 이전 절에서 개발된 CirQue<vector<int>> 클래스를 살펴 보자. CirQue<vector<int>>를 설계할 때 얼마나 많은 특정화를 구현해야 하는지 의문이 들 것이다. 하나는 vector<int>에 대해, vector<string>에 대하여 하나, 또 vector<double>에 대하여 하나씩 다 구현해야 하는가? CirQue<vector<...>> 클래스에 사용된 vector가 처리하는 데이터 유형이 int처럼 행위하는 한, (즉, 클래스의 값-유형이라면) 그 대답은 전혀 그럴 필요가 없다는 것이다. 각각의 새 데이터 유형에 대하여 모두 다 특정화하는 대신에 데이터 유형 자체를 매개변수화할 수 있다. 결과적으로 부분적 특정화가 된다.
template <typename Data>
class CirQue<std::vector<Data>>
{
...
};
위의 클래스는 특정화이다. 템플릿 인자 리스트가 CirQue 클래스 이름에 추가되기 때문이다. 그러나 클래스 템플릿 자체에 템플릿 매개변수 리스트가 비어 있지 않기 때문에 실제로는 부분적 특정화로 인식한다. 한 가지 특징이 있다. (클래스 템플릿의 인터페이스 바로 다음에) 부분적 특정화의 클래스 템플릿 멤버 함수의 구현과 완전한 특정화의 멤버 함수의 구현을 구별한다. 부분적으로 특정화된 클래스 템플릿 멤버 함수의 구현은 템플릿 헤더를 받는다. 완전히 특정화된 클래스 템플릿 멤버를 구현할 때는 템플릿 헤더가 사용되지 않는다.
CirQue에 대하여 부분적으로 특정화하는 것은 어렵지 않으며 독자 여러분에게 연습 문제로 남긴다 (힌트: 이전 절의 CirQue<vector<int>> 특정화에서 그냥 int를 Data로 바꾸면 된다.). iterator 유형 앞에 typename을 배치하는 것을 잊지 마라 (22.2.1절에서 연구했듯이 typedef typename DataVect::iterator iterator처럼 하면 된다.).
다음 예제에서는 클래스 템플릿 비-유형 템플릿 매개변수를 특정화하는 것에 집중하겠다. 이 부분적 특정화는 이제 선형 대수학의 한 분야인 행렬 대수학에 정의된 간단한 개념들을 사용하여 설명한다.
행렬은 숫자로 채워진 행과 열의 테이블로 여겨진다. 그러므로 템플릿에 이용할 수 있다는 생각이 들 것이다. 숫자들은 평범한 double 값이지만 복소수도 될 수 있다. 그렇다면 복소수 컨테이너가 유용할 것이다 (12.5절). 그러므로 DataType 클래스 템플릿에 템플릿 유형 매개변수가 주어진다. 행렬이 생성될 때 지정된다. double 값을 사용하는 간단한 행렬은 다음과 같다.
1 0 0 정방 행렬,
0 1 0 (3 x 3 행렬).
0 0 1
1.2 0 0 0 장방 행열
0.5 3.5 18 23 (2 x 4 행렬).
1 2 4 8 한 행 행렬
(1 x 4 행렬),
4 원소의 `행 벡터'라고도 한다.
(열 벡터도 비슷하게 정의됨)
행렬에 다양한 연산을 정의한다. 예를 들어 더하거나 빼고 또는 곱할 수 있다. 여기에서 이런 연산에 초점을 두지는 않겠다. 대신에 간단한 연산에 집중한다. 주변합계와 합계를 계산하는 데만 집중하겠다.
주변합계란 행 원소들의 합 또는 열 원소들의 합이다. 이 두 종류의 주변합계는 각각 행 주변합계와 열 주변합계라고 한다.
Rows 원소의 (열) 벡터에 상응하는 원소에 넣는다.
Columns의 (행) 벡터에 상응하는 원소에 넣는다.
-------------------------------------
row
matrix marginals
---------
1 2 3 6
4 5 6 15
---------
column 5 7 9 21 (sum)
marginals
-------------------------------------
행렬은 정의가 잘 된 행과 열의 갯수로 (행렬의 차원으로) 구성되는데 행렬이 사용될 때 변경되지 않기 때문에 그 값들을 템플릿 비-유형 매개변수로 지정하는 것을 고려해 볼 수 있다. 대다수의 클래스에 DataType = double이 사용될 것이다. 그러므로 double을 템플릿의 기본 유형 인자로 선택할 수 있다. 합리적인 기본값이므로 DataType 템플릿 유형 매개변수가 템플릿 유형 매개변수 리스트 맨 마지막에 사용된다.
Matrix 템플릿 클래스는 다음과 같이 탄생한다.
template <size_t Rows, size_t Columns, typename DataType = double>
class Matrix
...
이제 무엇을 제공하고 싶은가?
Rows' 행의 배열로 정의할 수 있다. 각 행마다 DataType 유형의 `Columns' 원소들을 담는다. 포인터가 아니라 배열이 될 수 있다. 왜냐하면 행렬의 차원이 미리 알려져 있기 때문이다. Columns 원소들의 벡터(행)과 Row 원소들의 벡터(열)이 자주 사용되므로 typedef를 사용하여 나타낼 수 있다. 그리하여 클래스 인터페이스의 맨 앞 구역에 다음이 포함된다.
typedef Matrix<1, Columns, DataType> MatrixRow;
typedef Matrix<Rows, 1, DataType> MatrixColumn;
MatrixRow d_matrix[Rows];
template <size_t Rows, size_t Columns, typename DataType>
Matrix<Rows, Columns, DataType>::Matrix()
{
std::fill(d_matrix, d_matrix + Rows, MatrixRow());
}
template <size_t Rows, size_t Columns, typename DataType>
Matrix<Rows, Columns, DataType>::Matrix(std::istream &str)
{
for (size_t row = 0; row < Rows; row++)
for (size_t col = 0; col < Columns; col++)
str >> d_matrix[row][col];
}
operator[] 멤버는 (그리고 그의 const 변형은) 첫 번째 인덱스만 다룰 뿐이다. MatrixRow를 참조로 완벽하게 돌려준다. MatrixRow 안의 원소들을 열람하는 법은 잠시 후에 다룬다. 예제를 간단하게 유지하기 위하여 배열 경계 점검은 구현하지 않았다.
template <size_t Rows, size_t Columns, typename DataType>
Matrix<1, Columns, DataType>
&Matrix<Rows, Columns, DataType>::operator[](size_t idx)
{
return d_matrix[idx];
}
Matrix안의 모든 원소들의 총계를 계산하는 것이 흥미롭다. MatrixColumn 유형을 행열의 행 주변합계를 담은 유형으로 정의하고 MatrixRow 유형을 행렬의 열 주변합계를 담은 유형으로 정의하겠다.
행렬의 모든 원소들의 총계도 있다. 행렬의 총계는 그 자체로 1 x 1 행렬로 간주할 수 있는 숫자이다.
주변합계는 특별한 형태의 행렬로 간주할 수 있다. 이 주변합계를 표현하기 위하여 부분적 특정화를 생성할 수 있다. 클래스 템플릿 MatrixRow 객체와 MatrixColumn 객체를 정의할 수 있다. 그리고 부분적 특정화를 생성하여 1 x 1 행렬을 처리한다. 이런 부분적 특정화는 주변합계와 행열의 총계를 계산하는 데 사용된다.
이런 특정화 자체에 집중하기 전에 먼저 주변합계와 행렬 총계를 구해 줄 멤버를 구현한다.
template <size_t Rows, size_t Columns, typename DataType>
Matrix<1, Columns, DataType>
Matrix<Rows, Columns, DataType>::columnMarginals() const
{
return MatrixRow(*this);
}
template <size_t Rows, size_t Columns, typename DataType>
Matrix<Rows, 1, DataType>
Matrix<Rows, Columns, DataType>::rowMarginals() const
{
return MatrixColumn(*this);
}
template <size_t Rows, size_t Columns, typename DataType>
DataType Matrix<Rows, Columns, DataType>::sum() const
{
return rowMarginals().sum();
}
Matrix 한 행을 정의한다. 주로 열 주변합계의 생성에 사용된다.
DataType = double). 기본 값이 이미 총칭 클래스 템플릿 정의에 지정되어 있기 때문이다. 특정화는 총칭 클래스 템플릿의 정의를 따라야 한다. 그렇지 않으면 컴파일러가 어떤 클래스를 특정화할지 모르겠다고 불평할 것이다. 템플릿 헤더 다음에 클래스의 인터페이스가 시작된다. 클래스 템플릿 (부분적) 특정화이다. 그래서 클래스 이름 다음에 반드시 템플릿 인자 리스트가 따라와서 부분적 특정화에 사용된 템플릿 인자를 지정해야 한다. 인자들은 템플릿의 매개변수들에 대하여 명시적으로 값이나 유형을 지정한다. 나머지 유형들은 그냥 클래스 템플릿 부분적 특정화의 템플릿 매개변수 리스트로부터 복사된다. 예를 들어 MatrixRow 특정화는 총칭 클래스 템플릿의 Rows 비-유형 매개변수에 대하여 1을 지정한다 (한 행을 다루고 있기 때문이다). Columns와 DataType 모두 지정된 그대로이다. 그러므로 MatrixRow의 부분 특정화는 다음과 같이 시작한다.
template <size_t Columns, typename DataType> // 기본 값 허용 불가
class Matrix<1, Columns, DataType>
MatrixRow는 한 행의 데이터를 보유한다. 그래서 유형이 DataType인 Columns 값들을 저장하는 데이터 멤버가 필요하다. Columns는 상수 값이기 때문에 d_row 데이터 멤버를 배열로 정의할 수 있다.
DataType d_column[Columns];
DataType의 기본 생성자를 사용하여 MatrixRow의 데이터 멤버를 초기화할 뿐이다.
template <size_t Columns, typename DataType>
Matrix<1, Columns, DataType>::Matrix()
{
std::fill(d_column, d_column + Columns, DataType());
}
총칭 Matrix 객체의 열 주변합계로 MatrixRow 객체를 초기화하는 또다른 생성자가 필요하다. 그러려면 생성자에 특정화가 안된 Matrix 매개변수를 제공해야 한다.
여기에서 제일 규칙은 매개변수의 일반적 본성을 유지할 수 있도록 멤버 템플릿을 정의하는 것이다. 총칭 Matrix 템플릿은 세 개의 템플릿 매개변수를 요구한다. 이 중 두개는 이미 템플릿 특정화로 제공된다. 세 번째 매개변수는 멤버 템플릿의 템플릿 헤더에 언급된다. 이 매개변수는 총칭 행열의 행 갯수를 참조하므로 그냥 Rows라고 부른다.
다음은 두 번째 생성자의 구현이다. MatrixRow의 데이터를 총칭 Matrix 객체의 열 주변합계로 초기화한다.
template <size_t Columns, typename DataType>
template <size_t Rows>
Matrix<1, Columns, DataType>::Matrix(
Matrix<Rows, Columns, DataType> const &matrix)
{
std::fill(d_column, d_column + Columns, DataType());
for (size_t col = 0; col < Columns; col++)
for (size_t row = 0; row < Rows; row++)
d_column[col] += matrix[row][col];
}
생성자의 매개변수는 Matrix 템플릿을 참조한다. 추가된 Row 템플릿 매개변수는 물론이고 부분 특정화의 템플릿 매개변수들도 사용한다.
MatrixRow의 데이터 원소에 접근하려면 중복정의 operator[]()가 유용하다. 다시, 비-const 변형처럼 const 변형을 구현할 수 있다. 다음은 그 구현이다.
template <size_t Columns, typename DataType>
DataType &Matrix<1, Columns, DataType>::operator[](size_t idx)
{
return d_column[idx];
}
Matrix 클래스와 한 행을 부분적으로 특정화해 정의했으므로 컴파일러는 Matrix가 Row = 1을 사용하도록 정의되어 있을 때마다 행의 특정화를 선택한다. 예를 들어:
Matrix<4, 6> matrix; // 총칭 Matrix 템플릿이 사용됨
Matrix<1, 6> row; // 부분적 특정화가 사용됨
MatrixColumn에 대한 부분적 특정화도 비슷하게 생성된다. 중요한 것들을 간추려 보자 (완전한 Matrix 클래스 템플릿 정의는 그의 특정화와 더불어 cplusplus.yo.zip 압축 파일 안의 yo/classtemplates/examples/matrix.h에 있다 (SourceForge)):
template <size_t Rows, typename DataType>
class Matrix<Rows, 1, DataType>
MatrixRow 생성자들과 거의 비슷하게 구현된다. 그 구현은 연습 문제로 독자 여러분에게 남긴다 (matrix.h 참고).
sum 멤버는 MatrixColumn 벡터 원소들의 총계를 계산하기 위하여 정의된다. accumulate 총칭 알고리즘을 사용하면 간단하게 구현된다.
template <size_t Rows, typename DataType>
DataType Matrix<Rows, 1, DataType>::sum()
{
return std::accumulate(d_row, d_row + Rows, DataType());
}
Matrix<1, 1> cell;
MatrixRow인가 아니면 MatrixColumn 특정화인가? 그 대답은 둘 다 '아니오'이다.
모호하다. 정확하게 행과 열 모두 (다른) 템플릿 부분적 특정화에 사용할 수 있기 때문이다. 그런 Matrix가 실제로 필요하면 또다른 특정화 템플릿을 설계해야 한다.
이 템플릿 특정화는 Matrix 원소의 총계를 얻는 데 유용할 수 있기 때문에 여기에서도 다룬다.
DataType 유형만 지정한다. 클래스 정의는 두 개의 고정 값을 지정한다. 하나는 행의 갯수에 그리고 또 하나는 열의 갯수에 지정한다.
template <typename DataType>
class Matrix<1, 1, DataType>
Matrix 유형을 기대하는 생성자를 멤버 템플릿으로 다시 구현한다. 예를 들어:
template <typename DataType>
template <size_t Rows, size_t Columns>
Matrix<1, 1, DataType>::Matrix(
Matrix<Rows, Columns, DataType> const &matrix)
:
d_cell(matrix.rowMarginals().sum())
{}
template <typename DataType>
template <size_t Rows>
Matrix<1, 1, DataType>::Matrix(Matrix<Rows, 1, DataType> const &matrix)
:
d_cell(matrix.sum())
{}
Matrix<1, 1>은 기본적으로 DataType 값을 감싼 포장자이므로 후자의 값에 접근할 멤버가 필요하다. 유형 변환 연산자가 유용할 수 있지만 그 변환 연산자를 컴파일러가 사용하지 않을 경우를 대비해 그 값을 얻을 get 멤버를 정의했다. 컴파일러에게 선택권을 줄 때 이런 일이 일어난다 (11.3절). 다음은 접근자이다 (const 변형은 생략한다).
template <typename DataType>
Matrix<1, 1, DataType>::operator DataType &()
{
return d_cell;
}
template <typename DataType>
DataType &Matrix<1, 1, DataType>::get()
{
return d_cell;
}
마지막으로 아래에 보여주는 main 함수는 Matrix 클래스 템플릿과 그의 부분적 특정화를 어떻게 사용할 수 있는지 보여준다.
#include <iostream>
#include "matrix.h"
using namespace std;
int main(int argc, char **argv)
{
Matrix<3, 2> matrix(cin);
Matrix<1, 2> colMargins(matrix);
cout << "Column marginals:\n";
cout << colMargins[0] << " " << colMargins[1] << '\n';
Matrix<3, 1> rowMargins(matrix);
cout << "Row marginals:\n";
for (size_t idx = 0; idx < 3; idx++)
cout << rowMargins[idx] << '\n';
cout << "Sum total: " << Matrix<1, 1>(matrix) << '\n';
}
/*
다음을 입력해 얻은 출력: 1 2 3 4 5 6
Column marginals:
9 12
Row marginals:
3
7
11
Sum total: 21
*/
가변 템플릿은 함수 템플릿과 클래스 템플릿에 대하여 정의된다. 가변 템플릿으로 갯수와 유형에 상관없이 인자를 지정할 수 있다.
가변 템플릿이 도입됨으로써 많은 중복정의 템플릿을 정의할 필요가 없어졌고 유형에 안전한 가변 함수를 생성할 수 있게 되었다.
C는 물론이고 C++도 가변 함수를 지원한다. 그러나 C++에 가변 함수를 사용하는 것은 권장하지 않는다. 가변 함수는 유형에 안전하지 않기로 악명이 높기 때문이다. C-스타일의 가변 함수로 지금까지 적절하게 처리할 수 없었던 객체들을 처리할 때 C++는 가변 함수 템플릿을 사용할 수 있다.
가변 템플릿의 템플릿 헤더는 typename ...Params의 구문을 사용한다 (Params는 형식 이름이다). Variadic 가변 클래스 템플릿은 다음과 같이 정의할 수 있다.
template<typename ...Params> class Variadic;
클래스 템플릿의 정의를 사용할 수 있다고 가정하면 이 템플릿은 가변 갯수의 템플릿 인자로 구체화할 수 있다. 예를 들어:
class Variadic<
int,
std::vector<int>,
std::map<std::string, std::vector<int>>
> v1;
가변 템플릿의 템플릿 인자는 비어 있을 수도 있다. 예를 들어:
class Variadic<> empty;
이것이 바람직하지 않다고 생각한다면 매개변수 갯수를 하나 이상 고정하여 방지할 수 있다. 예를 들어:
template<typename First, typename ...Rest>
class tuple;
유형에 안전하지 않기로 악명 높은 예는 C의 printf 함수이다. 가변 함수 템플릿으로 구현하면 유형에 안전한 함수로 탈바꿈한다. 또한 자동으로 확장되어 C++로 정의할 수 있는 유형이면 무엇이든 받아 들인다. 다음은 가변 함수 템플릿 printcpp의 한 구현이다.
template<typename ...Params>
void printcpp(std::string const &strFormat, Params ...parameters);
선언에 사용된 생략기호(...)는 두 가지 목적으로 기여한다.
sizeof 연산자를 새로 요청하여 결정한다.
template<typename ...Params>
struct StructName
{
enum: size_t { s_size = sizeof ...(Params) };
};
// StructName<int, char>::s_size - 2로 초기화된다.
가변 함수의 부분적 특정화를 정의함으로써, 명시적으로 추가 템플릿 유형 매개변수를 정의하면 매개변수 팩의 첫 템플릿 인자를 이렇게 추가된 (첫) 유형 매개변수에 짝지을 수 있다. 그런 가변 함수 템플릿의 설정 단계는 다음과 같다 (이전 항 printcpp 참고):
printcpp 함수는 형식화 문자열을 적어도 하나는 받는다. 그 형식화 문자열 다음에 가변 갯수의 추가 인자를 지정할 수 있다.
First에 일치한다. 나머지 인자의 유형은 템플릿 함수의 두 번째 템플릿 매개변수에 묶인다. 이것이 매개변수 팩(parameter pack)이다.
First 매개변수에 일치한다. 이렇게 재귀 호출의 매개변수 팩의 크기를 줄여 가면 결국 재귀는 멈추게 된다.
중복정의 비-템플릿 함수는 나머지 형식화 문자열을 인쇄한다. 내친 김에 남은 형식 지정도 연구해 보자.
void printcpp(string const &format)
{
size_t left = 0;
size_t right = 0;
while (true)
{
if ((right = format.find('%', right)) == string::npos)
break;
if (format.find("%%", right) != right)
throw std::runtime_error(
"printcpp: missing arguments");
++right;
cout << format.substr(left, right - left);
left = ++right;
}
cout << format.substr(left);
}
다음은 가변 함수 템플릿의 구현이다.
template<typename First, typename ...Params>
void printcpp(std::string const &format, First value, Params ...params)
{
size_t left = 0;
size_t right = 0;
while (true)
{
if ((right = format.find('%', right)) == string::npos) // 1
throw std::runtime_error("printcpp: too many arguments");
if (format.find("%%", right) != right) // 2
break;
++right;
cout << format.substr(left, right - left);
left = ++right;
}
cout << format.substr(left, right - left) << value;
printcpp(format.substr(right + 1), params...);
}
%를 찾는다. 없으면 그 함수는 남은 인자로 호출되고 예외를 던진다.
%%를 만나지 않았는지 검증한다. %가 한 개라면 while-회돌이가 끝나고, % 다음부터 value까지의 형식화 문자열은 cout에 삽입된다. 그리고 재귀 호출은 나머지 형식화 문자열과 더불어 나머지 매개변수 팩을 받는다.
%%를 보았다면 형식화 문자열은 두 번째 %까지 삽입된다. 이는 무시된다. 그리고 형식화 문자열의 처리는 %%를 넘어 계속된다.
printcpp 중복정의 함수를 호출하지 않는다.
C의 printf 함수와 다르게 printcpp는 %와 %%만 형식 지정자로 인식한다. 위의 구현은 필드 너비를 인지하지 못한다. 물론 %c나 %x같은 지정자는 필요하지 않다. ostream의 삽입 연산자가 삽입되는 인자의 유형을 알고 있기 때문이다. 형식 지정자를 확장하여 필드 너비 등등을 printcpp 구현이 인지하도록 만드는 일은 독자 여러분에게 숙제로 남긴다. 다음은 printcpp를 어떻게 호출하는지 보여준다.
printcpp("Hello % with %%main%% called with % args"
" and a string showing %\n",
"world", argc, string("A String"));
string의 insert 멤버를 연구해 보자. String::insert는 여러 중복정의 구현이 있다. (부분적이든 전체적이든) 텍스트를 삽입하는데 사용할 수 있는데 텍스트를 string이나 char const * 인자로 제공한다. 지정한 횟수만큼 문자 하나를 삽입할 수 있고; 반복자를 사용하면 삽입될 문자의 범위를 지정할 수 있다. 등등. string은 다섯 가지나 되는 중복정의 insert 멤버가 있다.
Inserter라는 클래스가 있고 정보를 모든 종류의 객체에 삽입하는 데 사용할 수 있다고 가정하자. 그런 클래스는 string 데이터 멤버를 가질 수 있고 그 안에 정보를 삽입할 수 있다. Inserter의 인터페이스는 부분적으로만 string의 인터페이스를 복사하면 이를 실현할 수 있다. string::insert의 인터페이스만 복제하면 된다. 인터페이스를 복제하는 멤버는 (데이터 멤버 실체의 멤버 함수를 적절하게 호출하는) 서술문 하나만 있는 경우가 대부분이다. 이런 이유로 종종 인라인으로 구현된다. 포장 함수는 부합하는 데이터 멤버 실체의 멤버 함수에 매개변수를 그저 전달할 뿐이다.
또다른 예는 공장 함수에서 볼 수 있다. 돌려줄 객체의 생성자에 매개변수를 건네는 경우가 자주 있다.
C++는 매개변수 전달을 단순하게 일반화했다. rvalue 참조와 가변 템플릿을 통하여 완벽한 전달을 구현한다. 완벽한 전달로 함수에 건네지는 인자를 내포 함수에 완벽하게 전달할 수 있다. 전달은 완벽하다. 인자가 유형에 안전하게 전달되기 때문이다. 완벽한 전달을 사용하기 위해, 내포 함수는 유형과 갯수에서 전달 매개변수에 부합하도록 매개변수 리스트를 정의해야 한다.
완벽한 전달은 쉽게 구현된다.
Params &&...params).
std::forward는 전달 함수의 인자를 내포 함수에 전송하는 데 사용된다. 유형과 갯수를 추적 관리한다. forward를 사용하기 전에 먼저 <utility> 헤더를 포함해야 한다.
std::forward<Params>(params)....
다음 예제는 완벽한 전달을 사용하여 Inserter::insert 멤버 하나를 구현한다. 다섯 개의 중복정의 string::insert 멤버를 호출할 수 있다. 실제로 호출되는 insert 함수는 이제 단순히 Inserter::insert에 건넨 인자의 갯수와 유형에 따라 달라진다.
class Inserter
{
std::string d_str; // 어쨌거나 초기화 됨
public:
// 생성자 구현 안됨,
// 그러나 아래 참고
Inserter();
Inserter(std::string const &str);
Inserter(Inserter const &other);
Inserter(Inserter &&other);
template<typename ...Params>
void insert(Params &&...params)
{
d_str.insert(std::forward<Params>(params)...);
}
};
Inserter를 돌려주는 공장 함수도 완벽한 전달을 사용하여 쉽게 구현할 수 있다. 네 가지 중복정의 공장 함수를 정의하지 않아도 이제 하나면 충분하다. 생성할 클래스 객체를 템플릿 유형 매개변수에 지정하여 공장 함수에 추가로 건네면 완벽하게 일반 공장 함수로 변신한다.
template <typename Class, typename ...Params>
Class factory(Params &&...params)
{
return Class(std::forward<Params>(params)...);
}
다음은 그의 사용법을 보여주는 몇 가지 예이다.
Inserter inserter(factory<Inserter>("hello"));
string delimiter(factory<string>(10, '='));
Inserter copy(factory<Inserter>(inserter));
std::forward 함수는 표준 라이브러리에 있다. 전혀 마법을 부리지 않는다. 그저 params를 이름 없는 객체로 돌려줄 뿐이다. 마치 std::move처럼 행위한다. 객체로부터 이름을 제거한 다음에 익명 객체로 돌려준다. 언팩 연산자는 forward의 사용과 전혀 관련이 없다. 그저 컴파일러에게 forward를 순서대로 각 인자에 적용하라고 알릴 뿐이다. 그리하여 가변 함수에 사용되는 C의 생략 연산자와 비슷하게 행위한다.
완벽한 전달은 21.4.5절에 소개했다. 템플릿 함수가 Type &¶m를 정의하고 있고 Type이 템플릿 유형 매개변수일 경우에 이 함수를 Tp & 유형을 인자로 하여 호출하면 Type &&를 Tp &로 변환한다. 그렇지 않으면 Type을 Tp에 묶고 param은 Tp &¶m으로 정의한다. 결과적으로 lvalue 인자는 lvalue-유형에 묶이고 (Tp &) rvalue 인자는 rvalue-유형에 묶인다 (Tp &&).
std::forward 함수는 호출된 함수나 객체에 인자와 유형을 그저 건넬 뿐이다. 다음은 그의 간략한 구현이다.
typedef <type T>
T &&forward(T &&a)
{
return a;
}
lvalue나 lvalue 참조를 가지고 forward를 호출할 때 T &&는 lvalue 참조로 변신하기 때문에 그리고 rvalue 참조를 가지고 forward를 호출하면 여전히 rvalue 참조이기 때문에 그리고 또 forward는 std::move처럼 forward에 인자로 건넨 변수의 이름을 없애 버리기 때문에 인자 값이 전달되면서도 그와 함께 그의 유형도 함수의 매개변수로부터 호출된 함수의 인자에 전달된다.
이것을 완벽한 전달이라고 부른다. `바깥' 함수를 (예를 들어 factory 함수를) 호출할 때 사용된 인자의 유형이 정확하게 내포 함수의 인자에 (예를 들어 Class 생성자의 인자에) 부합할 경우에만 내포 함수를 호출할 수 있기 때문이다. 그러므로 완벽한 전달은 유형에 안전함을 실현하는 도구이다.
forward를 아름답게 개선할 수 있다. forward의 사용자는 함수 템플릿 매개변수 유형 추론 과정의 결과로 컴파일러가 추론한 유형에 기대지 말고 사용할 유형을 직접 지정해야 한다. 이것은 작은 구조체 템플릿의 도움으로 실현된다.
template <typename T>
struct identity
{
typedef T type;
};
이 구조체는 단순히 identity::type를 T로 선언할 뿐이다. 그러나 구조체이기 때문에 명시적으로 지정해야 한다. 함수의 인자 자체로는 결정할 수 없다. 그러므로 위의 forward 구현을 좀 더 세심하게 변경하면 다음과 같이 된다 (typename의 사용법에 관한 설명은 22.2.1항을 참고):
typedef <type T>
T &&forward(typename identity<T>::type &&arg)
{
return arg;
}
이제 forward는 명시적으로 arg의 유형을 지정한다. 다음과 같이:
std::forward<Params>(params)
std::forward 함수와 rvalue 참조 지정을 사용하는 것은 매개변수 팩의 문맥에만 한정되지 않는다. 템플릿 유형 매개변수에 대하여 rvalue 참조를 특별하게 처리하기 때문에 (21.4.5항) 함수에 개별적으로 매개변수들을 전달하는 데에도 유용하게 사용할 수 있다. 다음은 함수에 건넨 인자를 템플릿으로부터 함수에 어떻게 전달하는 지 보여주는 예제이다. 이 함수는 그 자체가 (미지정된) 함수를 가리키는 포인터로서 템플릿에 건네진다.
template<typename Fun, typename ArgType>
void caller(Fun fun, ArgType &&arg)
{
fun(std::forward<ArgType>(arg));
}
이제 caller를 통하여 display(ostream &out) 함수와 increment(int &x) 함수를 호출할 수 있다. 예를 들어:
caller(display, cout);
int x = 0;
caller(increment, x);
언팩 연산자는 바탕 클래스의 갯수에 상관없이 상속받아 템플릿 클래스를 정의하는 데에도 사용할 수 있다. 다음은 그 사용법이다.
template <typename ...BaseClasses>
class Combi: public BaseClasses... // 바탕 클래스로부터 상속받는다.
{
public:
// 바탕 클래스 객체를
// 완벽한 전달을 사용하여
// 생성자에 지정한다.
Combi(BaseClasses &&...baseClasses)
:
BaseClasses(baseClasses)... // 바탕 클래스
{} // 각각에 대하여
}; // 초기화자를 사용한다.
이렇게 하면 다른 클래스들의 특징을 모두 조합한 클래스를 정의할 수 있다. Combi 클래스를 A와 B 그리고 C 클래스로부터 상속받았다면 Combi는 A와 B 그리고 C와 "is-a" 관계이다. 물론 가상 소멸자를 주어야 한다. Combi 객체는 바탕 클래스 유형의 객체에 대한 참조 또는 포인터를 기대하는 함수에 건넬 수 있다. 다음은 Combi를 클래스로 정의하는 예이다. 이 클래스는 복소수 벡터와 문자열 그리고 한 쌍의 정수와 배정도수로부터 파생된다 (연속열을 활괄호로 초기화한다. 이 연속열은 Combi 유형에 지정된 일련의 유형에 일치한다):
typedef Combi<
vector<complex<double>>, string, pair<int, double>
> MultiTypes;
MultiTypes mt = {{3.5, 4}, "mt", {1950, 1.72}};
똑같은 생성 방법을 사용하여 터플(tuple)과 같은 가변 유형 리스트를 지원하는 템플릿 데이터 멤버를 정의할 수도 있다 (22.6절). 그런 클래스는 다음 줄을 따라서 설계할 수 있다.
template <typename ...Types>
struct Multi
{
std::tuple<Types...> d_tup; // Types 유형에 대하여 터플을 정의한다.
Multi(Types ...types)
: // Multi의 인자로부터
d_tup(std::forward<Types>(types)...) // d_tup를 초기화한다.
{}
};
매개변수 팩을 전달할 때 생략기호는 중요하다. 생략기호가 없으면 컴파일러는 에러로 간주한다. 다음 struct 정의에서 프로그래머의 의도는 내포된 객체의 생성에 매개변수 팩을 건네는 것이었지만 템플릿 매개변수를 지정하는 동안 생략기호를 빼먹었다. 결과적으로 다음과 같이 parameter packs not expanded with `...' (매개변수 팩은 `...'이 없으면 확장 불가함)이라는 에러 메시지가 야기된다.
template <int size, typename ...List>
struct Call
{
Call(List &&...list)
{
Call<size - 1, List &&> call(std::forward<List>(list)...);
}
};
call 객체를 위와 같이 정의하는 대신에 다음과 같이 정의해야 한다.
Call<size - 1, List &&...> call(std::forward<List>(list)...);
enum 값 result가 정의된다. 이것을 함수가 돌려준다. 만약 정수 값을 전혀 지정하지 않으면 0을 돌려준다.
template <int ... Ints>
int forwarder()
{
return computer<Ints ...>::result; // Ints를 전달한다.
}
template <> // Ints를 제공하지 않으면 특정화한다.
int forwarder<>()
{
return 0;
}
// 다음과 같이 사용한다.
cout << forwarder<1, 2, 3>() << ' ' << forwarder<>() << '\n';
sizeof 연산자를 가변 비-유형 매개변수에도 사용할 수 있다. 예를 들어 forwarder<1, 2, 3>()이 첫 번째 함수 템플릿에 적용되면 sizeof...(Ints)는 3을 돌려줄 것이다.
가변 비-유형 매개변수는 가변 기호상수 연산자를 정의하는 데 사용된다. 이에 관해서는 23.3절에 소개한다.
not1과 not2 부인자를 다루었다. 언제나 bind 함수와 조합하여 이 부인자들을 사용할 수 있는 것은 아니다. 그 사용법은 제한이 있다. 인자가 하나 또는 두 개일 경우에만 사용할 수 있다. 앞으로 C++17 표준에서는 이 두 부인자는 비추천되거나 아니면 좀더 총칭적인 부인자가 추가될 가능성이 매우 높다. 그를 위하여 not_fn이라는 이름이 선택된 듯 하다.
이 항에서는 not_fn 부인자의 뼈대 구현을 살펴 보겠다.
먼저 어떻게 not_fn를 사용할 수 있는지 살펴 보자. 부인자를 논의할 때 다음 두 서술문에서 두 번째는 컴파일되지 않음을 지적했다.
count_if(vs.begin(), vs.end(),
bind(not2(greater_equal<string>()), _1, reftext));
count_if(vs.begin(), vs.end(),
not1(bind(greater_equal<string>()), _1, reftext));
여기에서 다른 방법을 개발해 보겠다. 위의 서술문에서 not1과 not2 대신에 not_fn을 사용한다.
count_if(vs.begin(), vs.end(), // 1
bind(not_fn(greater_equal<string>()), _1, reftext));
count_if(vs.begin(), vs.end(), // 2
not_fn(bind(greater_equal<string>()), _1, reftext));
서술문 1에서 not_fn에 greater_equal<string>() 함수객체를 건넨다. 서술문 2에서 not_fn에 bind가 돌려주는 함수객체를 건넨다. not_fn을 템플릿 함수로 정의하면 컴파일러는 인자의 유형을 결정할 수 있다. 그래서 not_fn은 그냥 typename Fun 템플릿 유형 매개변수만 있으면 된다.
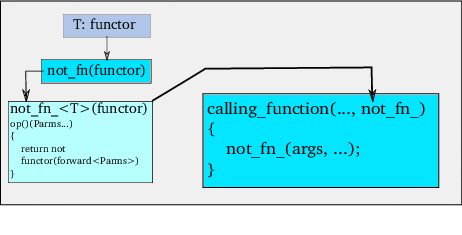
not_fn의 함수 호출 연산자가 사용될 때 받은 인자의 유형과 갯수가 다를 수 있다 (서술문 1에서 bind의 함수 호출 연산자로부터 두 개의 인자를 받고 서술문 2에서 count_if로부터 인자를 하나 받는다). 이번에는 그 인자들은 not_fn에 건넸던 함수객체의 함수 호출 연산자로 전송되어야 한다. 이 상황을 요약하면 (그림 26):
greater_equal를 호출해야 하지만 그의 반환 값은 뒤집어야 한다.
not_fn 함수 템플릿에 건네진다. 컴파일러는 그의 유형을 결정한다. 이 유형을 사용하여 not_fn_ 클래스 템플릿을 생성한다. 이 템플릿은 not_fn이 돌려준다.
not_fn_ 객체는 자체로 함수객체이다. 그의 operator() 멤버는 완벽하게 인자를 원래 1단계와 2단계에 지정된 함수에 전송한다. 그리고 원래 함수의 반환 값을 부인하여 돌려준다.
not_fn_ 객체를 받고 그의 operator()를 적절한 인자와 함께 호출한다.
2 단계에서 not_fn이 사용된다. 다음과 같이 정의되어 있다.
template <typename Fun>
not_fn_<Fun> not_fn(Fun const &fun)
{
return not_fn_<Fun>(fun);
}
이 함수는 호출할 함수객체로 초기화하여 not_fn_ 함수객체를 돌려준다 (예를 들어 greater_equal<string>() 또는 bind가 돌려주는 함수객체).
또한 2 단계에서 not_fn_의 생성자가 언급된다. 1 단계에 언급된 함수를 참조로 절약한다.
template <typename Fun>
struct not_fn_
{
Fun const &d_fun;
not_fn_(Fun const &fun)
:
d_fun(fun)
{}
...
};
3 단계에서 not_fn_의 함수 호출 연산자가 사용된다. 그의 인자를 1 단계의 함수에 완벽하게 전달한다. 거기에 d_fun 데이터 멤버를 통하여 접근할 수 있다. 함수 호출 연산자는 d_fun의 반환 값을 부인하여 돌려준다.
template <typename ... ParTypes>
bool operator()(ParTypes && ...types)
{
return not d_fun(std::forward<ParTypes>(types)...);
}
다음 예제는 not_fn을 어떻게 사용할 수 있는지 보여준다. equal_to<string>()를 사용하여 두 가지 방법으로 문자열 벡터에서 "b"와 같지 않은 원소의 갯수를 센다. 프로그램은 두 가지 방식의 출력을 보여준다.
1: int main()
2: {
3: vector<string> vs {"a", "a", "b"};
4: string reftext {"b"};
5:
6: cout <<
7: count_if(vs.begin(), vs.end(),
8: bind(not_fn(equal_to<string>()), _1, reftext)) << '\n' <<
9: count_if(vs.begin(), vs.end(),
10: not_fn(bind(equal_to<string>(), _1, reftext))) << '\n';
11: }
(arg1 + arg2 + ...처럼) 인자를 조합하기 위해 이항 연산자를 사용하는 경우가 자주 있다. 그런 상황에 전통적인 가변 템플릿을 사용하여 인자를 조합하는 대신에 접기 표현식(folding expression)을 사용할 수 있다.
(할당과 반영 할당 그리고 쉼표 연산자를 비롯하여) 이항 연산자는 모두 접기 표현식에 사용이 가능하다.
(... op expr)
여기에서 op는 접기 표현식에 사용되는 이항 연산자이다. 그리고 expr은 함수 매개변수의 관점에서 만든 표현식으로서 가변 갯수의 인자를 나타낸다. 다음은 그 예이다.
template <typename ReturnType, typename ...Params>
ReturnType sum(Params ...params)
{
return (... + params);
}
평범하게 가변 인자를 지정하는 것보다 좀 더 정교한 표현식이 사용되면 괄호로 둘러 분명하게 표식을 붙여야 한다.
return (... + (2 * params));
단항 접기 표현식에서 매개변수 팩의 유형에 부합하는 함수의 인자는 모두 지정된 연산자를 사용하여 조합된다. 예를 들어,
sum<int>(1, 2, 3);
6을 돌려준다.
ostream에 삽입하거나 또는 변수나 객체를 초기화할 때). 또, 인자의 유형이 반드시 동일해야 할 필요는 없다. 유일한 요구조건은 완전하게 확장된 표현식이 (예제에서는 1 + 2 + 3 표현식이) 유효하기만 하면 된다.
params 식별자를 서로 바꾼다.
(expr op ...)
단항 좌 접기와 단항 우 접기를 합하여 이른바 단항 접기(unary folds)라고 부른다.
(expr1 op ... op expr2)
여기에서 expr1은 가변 인자를 대표하는 식별자이다. 아니면 expr2가 그 식별자이어야 한다. 그 반대쪽은 유효한 표현식이면 된다 (단항 접기처럼 두 표현식 모두 확실하게 경계를 정해 주어야 한다). 그리고 두 연산자 모두 동일해야 한다.
이항 연산자가 중복정의되어 있다면 가능하면 적용된다. 물론 std::ostream 객체에 정의된 operator<<가 유명한 예이다. operator<<에 정의된 이항 접기는 쉬프트를 수행할 뿐만 아니라, 일련의 인자를 cout에 삽입하는 데에도 사용된다.
template <class ...Pack>
ostream &out2(ostream &out, Pack &&...args)
{
return (out << ... << args);
};
다음은 또다른 흥미로운 예제이다. 쉼표 연산자에 접기 표현식을 사용한다.
verb(
template <class ...Pack>
void call(Pack &&...args)
{
... , args());
};
이 단항 접기는 인자를 순서대로 호출한다. 인자는 함수 주소나 함수객체 또는 람다 함수가 될 수 있다. 가변 매개변수 리스트를 정의할 때 rvalue 참조를 사용한 것을 눈여겨보자. 덕분에 call에 건네어지는 함수객체를 복사하지 않아도 된다. struct Functor가 함수객체를 정의하고 void function()이 정의되어 있다고 간주하자. 그러면 다음과 같이 call을 호출할 수 있다.
Functor functor;
call(functor, function, functor,
[]()
{
// ...
}
);
마지막으로 잊지 말고 괄호를 접기 표현식에 두르자. 꼭 필요하다!
<tuple> 헤더를 포함해야 한다.
페어 컨테이너는 기능에 제한이 있고 멤버도 두 개만 지원한다. 반면에 터플은 기능이 더 많고 유형에 제한없이 데이터를 담을 수 있다. 그 점에서 터플을 C의 구조체에 대한 `템플릿'의 응답으로 보아도 좋다.
터플의 총칭적 선언(정의)은 가변 템플릿 표기법을 사용한다.
template <class ...Types>
class tuple;
다음은 그의 사용법의 예이다.
typedef std::tuple<int, double &, std::string, char const *> tuple_idsc;
double pi = 3.14;
tuple_idsc idsc(59, pi, "hello", "fixed");
// 필드에 접근:
std::get<2>(idsc) = "hello world";
std::get<idx>(tupleObject) 함수 템플릿은 tupleObject 터플의 idx번째 (0기반)를 참조로 돌려준다. 인덱스는 함수 템플릿의 비-유형 템플릿 인자로 지정된다.
C++14 표준은 유형-기반의 터플 주소 지정도 지원한다. 터플에 유형은 한 번만 정의되어야 한다. 같은 유형을 반복적으로 정의하면 모호하기 때문에 그 유형을 참조하지 못한다. 다음 예제는 위의 예제의 원소를 유형으로 참조하는 법을 보여준다.
get<int>(idsc) // 59
get<double &>(idsc) // 3.14
get<string>(idsc) // "hello"s
get<char const *>(idsc) // "fixed"
터플은 초기 값을 지정하지 않아도 생성할 수 있다. 원시 유형은 0으로 초기화된다. 클래스 유형 필드는 기본 생성자로 초기화된다. 그러나 터플의 생성에는 성공하지만 사용에는 실패하는 경우도 있음을 주의하라. 다음을 생각해 보자.
tuple<int &> empty;
cout << get<0>(empty);
여기에서 empty 터플을 사용할 수 없다. 그의 int & 필드가 미정의 참조이기 때문이다. 그렇지만 empty 터플의 생성에는 성공한다.
유형 리스트가 동일하면 터플은 서로 할당할 수 있다. 구성 유형이 지원하면 복사 생성자도 사용할 수 있다. 오른쪽 유형이 왼쪽 유형에 부합하여 변환될 수 있으면 또는 왼쪽 유형을 오른쪽 유형으로부터 생성할 수 있다면 복사 생성과 할당도 사용할 수 있다. 터플은 갯수와 유형이 부합하면 관계형 연산자를 사용하여 비교할 수 있다. 구성 유형이 비교를 지원하기만 하면 된다. 이 점에서 터플은 페어를 닮았다.
터플은 다음 정적 원소를 컴파일 시간에 초기화해 준다.
std::tuple_size<Tuple>::value
Tuple에 정의된 유형의 갯수를 돌려준다. 예를 들어:cout << tuple_size<tuple_idsc>::value << '\n'; // 4를 출력
std::tuple_element<idx, Tuple>::type
Tuple의idx원소의 유형을 돌려준다. 예를 들어:
tuple_element<2, tuple_idsc>::type text; // std::string 텍스트를 정의한다.
언팩 연산자를 사용하면 생성자의 인자를 터플 데이터 멤버에 전달할 수 있다. 가변 템플릿으로 정의된 Wrapper 클래스를 연구해 보자.
template <typename ...Params>
class Wrapper
{
...
public:
Wrapper(Params &&...params);
};
이 클래스에 터플 데이터 멤버를 줄 수 있다. 완벽한 전달을 사용하여 Wrapper 클래스의 객체를 초기화할 때 사용되는 유형과 값으로 이 데이터 멤버를 초기화해야 한다. 클래스를 템플릿 유형으로부터 상속받는 방식과 비슷하게 그의 유형과 생성자 인자를 터플 데이터 멤버에 전달할 수 있다 (22.5.3항).
template <typename ...Params>
class Wrapper
{
std::tuple<Params...> d_tuple; // 포장자 자체에 사용된 것과
// 같은 유형
public:
Wrapper(Params &&...params)
: // 포장자의 인자로
// d_tuple을 초기화한다.
d_tuple(std::forward<Params>(params)...)
{}
};
operator()) 정의한 매개변수의 유형을 추상화할 수 있다. 함수 호출 연산자 자체를 멤버 템플릿으로 정의하면 된다. 예를 들어,
template <typename Class>
class Filter
{
Class obj;
public:
template <typename Param>
Param operator()(Param const ¶m) const
{
return obj(param);
}
};
Filter 템플릿 클래스는 Class를 둘러 싼 포장자이다. 자신의 함수 호출 연산자를 통하여 Class의 함수 호출 연산자를 여과한다. 위의 예제에서는 Class의 함수 호출 연산자의 값이 그냥 그대로 전달될 뿐이지만 다른 조작도 물론 가능하다.
물론 Filter의 템플릿 유형 인자로 지정된 유형은 여러 함수 호출 연산자를 가질 수 있다.
struct Math
{
int operator()(int x);
double operator()(double x);
};
Math 객체는 이제 Filter<Math> fm을 사용하여 걸러낼 수 있다. 실제 인자 유형에 따라 Math의 첫 번째 또는 두 번째 함수 호출 연산자를 호출한다. fm(5)라면 int-버전이 호출되고 fm(12.5)라면 double-버전이 호출된다.
그렇지만 함수 호출 연산자에 반환 값과 인자가 유형이 서로 다르면 이 전략은 작동하지 않는다. 이 때문에 다음 Convert 클래스는 Filter와 함께 사용할 수 없다.
struct Convert
{
double operator()(int x); // int를 double로 변환
std::string operator()(double x); // double을 string으로 변환
};
이 문제는 std::result_of<Functor(Typelist)> 클래스 템플릿으로 성공적으로 해결할 수 있다. std::result_of를 사용하기 전에 <functional> 헤더를 포함해야 한다.
result_of 클래스 템플릿은 typedef (type)를 제공하는데 Functor<TypeList>이 돌려주는 유형을 대표한다. 다음과 같이 사용하면 Filter의 구현을 개선할 수 있다.
template <typename Class>
class Filter
{
Class obj;
public:
template <typename Arg>
typename std::result_of<Class(Arg)>::type
operator()(Arg const &arg) const
{
return obj(arg);
}
};
이 정의를 사용하면 Filter<Convert> fc를 생성할 수 있다. 이제 fc(5)은 double을 돌려주고 fc(4.5)는 std::string을 돌려준다.
Convert 클래스는 그의 함수 호출 연산자와 반환 유형 사이의 관계를 정의해야 한다. (표준 템플릿 라이브러리에 있는 함수들 같이) 미리 정의된 함수객체는 이미 그렇게 하지만 사용자가 정의하는 함수객체는 이를 명시적으로 지정해야 한다.
함수객체가 하나의 함수 호출 연산자만 정의하면 typedef로 반환 유형을 정의할 수 있다. 위의 Convert 클래스가 두 함수 호출 연산자 중 첫 번째만 정의한다면 typedef는 클래스의 공개 구역에 다음과 같이 지정해야 한다.
typedef double type;
여러 함수 호출자를 정의하면 각각 자신의 서명과 반환 유형이 있어서 그 사이의 연관 관계를 모두 클래스의 공개 구역에 다음과 같이 설정한다.
struct result를 다음과 같이 정의한다.
template <typename Signature> struct result;
struct result의 특정화를 정의한다. Convert의 첫 함수 호출 연산자는 다음을 생성하고,
template <typename Class>
struct result<Class(int)>
{
typedef double type;
};
Convert의 두 번째 함수 호출자는 다음을 생성한다.
template <typename Class>
struct result<Class(double)>
{
typedef std::string type;
};
int와 double로 호출되고 size_t를 돌려주면 다음과 같이 된다.
template <typename Class>
struct result<Class(int, double)>
{
typedef size_t type;
};
기본 템플릿 매개변수 값을 지정할 때 템플릿 매개변수 유형도 지정된다. 물론 값을 지정하지 않더라도 컴파일러가 기본 유형을 부여한다 (22.4절을 보면 템플릿의 DataType 매개변수에 대하여 double이 기본 유형으로 사용된다.). 템플릿 매개변수의 실제 값이나 유형은 절대로 인자로부터 추론되지 않는다. 함수 템플릿 매개변수로부터 추론된다. 그래서 원소가 복합-값으로 구성된 Matrix를 정의하려면 다음 구문을 사용한다.
Matrix<3, 5, std::complex> complexMatrix;
Matrix 클래스 템플릿은 기본 데이터 유형을 사용하기 때문에 원소가 double-값으로 구성된 행열은 다음과 같이 정의할 수 있다.
Matrix<3, 5> doubleMatrix;
클래스 템플릿 객체는 extern 키워드를 사용하여 선언할 수 있다.
예를 들어 complexMatrix 행렬은 다음과 같이 선언하라.
extern Matrix<3, 5, std::complex> complexMatrix;
클래스 템플릿 선언만으로도 충분히 반환 값이나 클래스 템플릿 유형의 매개변수를 컴파일할 수 있다. 예를 들어 다음 소스 파일은 컴파일러가 아직 Matrix 클래스 템플릿의 정의를 보지 못했더라도 컴파일된다. 총칭 클래스와 (부분적) 특정화는 선언에 전혀 문제가 없다. 클래스 템플릿 객체나 참조 또는 매개변수를 기대하거나 돌려주는 함수는 자동으로 함수 템플릿 자체가 된다. 이것은 함수에 건네지는 다양한 실제 인자에 맞게 함수를 컴파일러가 재단하기 위해 필요하다.
#include <cstddef>
template <size_t Rows, size_t Columns, typename DataType = double>
class Matrix;
template <size_t Columns, typename DataType>
class Matrix<1, Columns, DataType>;
Matrix<1, 12> *function(Matrix<2, 18, size_t> &mat);
클래스 템플릿을 사용할 때 컴파일러는 먼저 그 구현을 보아야 한다. 그래서 컴파일러는 템플릿을 구체화할 때 템플릿 멤버 함수를 알고 있어야 한다. 이것은 클래스 템플릿 객체를 정의할 때 템플릿 클래스의 모든 멤버가 구체화되어 있어야 한다거나 보여져야 한다는 뜻은 아니다. 컴파일러는 실제로 사용되는 멤버들만 구체화한다.
이것을 다음의 간단한 Demo 클래스로 보여준다. 두 개의 생성자와 두 개의 멤버를 가졌다. main 함수에서 생성자를 하나 사용하고 멤버를 하나만 호출할 때 결과 오브젝트 파일의 크기와 실행 프로그램의 크기를 눈여겨보라. 다음으로 클래스 정의가 변경된다. 사용되지 않는 생성자와 멤버는 주석 처리된다. 또다시 프로그램을 컴파일하고 링크한다. 이제 이 두 번째 크기가 앞의 크기와 같음을 주목하라.
사용된 멤버만 구체화된다는 것을 시연할 다른 방법이 있다. nm 프로그램을 사용할 수 있다. 오브젝트 파일의 심볼 내용을 보여준다. nm 프로그램을 사용하면 같은 결과에 도달할 것이다. 즉, 실제로 사용된 템플릿 멤버 함수만 구체화된다.
다음은 Demo 클래스 템플릿이다. 앞의 작은 실험에 사용했었다. main 함수에서 첫 번째 생성자와 첫 번째 멤버 함수만 호출되며 그래서 이 멤버들만 구체화된다.
#include <iostream>
template <typename Type>
class Demo
{
Type d_data;
public:
Demo();
Demo(Type const &value);
void member1();
void member2(Type const &value);
};
template <typename Type>
Demo<Type>::Demo()
:
d_data(Type())
{}
template <typename Type>
void Demo<Type>::member1()
{
d_data += d_data;
}
// 두 번째 컴파일하기 전에
// 다음 멤버를 주석 처리해야 한다.
template <typename Type>
Demo<Type>::Demo(Type const &value)
:
d_data(value)
{}
template <typename Type>
void Demo<Type>::member2(Type const &value)
{
d_data += value;
}
int main()
{
Demo<int> demo;
demo.member1();
}
코드가 템플릿 매개변수에 의존하는지 않는지 그 여부는 템플릿을 정의할 때 컴파일러가 검증한다. 클래스 템플릿 안의 멤버 함수가 qsort 함수를 사용하면 qsort는 템플릿 매개변수에 의존하지 않는다. 결과적으로 컴파일러는 qsort 함수 호출을 만날 때 qsort를 이미 알고 있어야 한다. 실제로 이것은 <cstdlib> 헤더를 컴파일러가 먼저 읽어야 그 클래스 템플릿 정의를 컴파일할 수 있다는 뜻이다.
반면에 템플릿이 <typename Ret> 템플릿 유형 매개변수를 정의하여 다음과 같이 템플릿 멤버 함수의 반환 유형을 매개변수화한다면:
Ret member();
컴파일러는 다음과 같은 위치에서 member 함수를 만나거나 아니면 member가 속한 클래스를 만날 수도 있다.
member와 같은 멤버 함수의 구문적 정확성을 기본적으로 점검했어야 한다. Ret && *member와 같은 정의나 선언은 받아 들이지 않는다. C++는 rvalue 참조를 포인터로 반환하는 함수를 지원하지 않기 때문이다. 게다가 객체를 구체화하는 데 사용된 실제 유형 이름이 유효한지 점검한다. 이 유형 이름은 객체를 구체화하는 시점에 컴파일러에게 알려져야 한다.
Ret 매개변수를 지정했어야 한다 (또는 추론해야 한다). 그리고 이 시점에서 Ret 템플릿 매개변수에 사용된 member의 서술문은 구문의 정확성을 점검받는다. 예를 들어 다음과 같이 member에 서술문이 들어 있다면
Ret tmp(Ret(), 15);
원칙적으로 구문은 유효하다. 그렇지만 Ret = int이면 이 서술문은 컴파일에 실패한다. int에 두 개의 int 인자를 기대하는 생성자가 없기 때문이다. 컴파일러가 member 클래스의 객체를 초기화할 때는 문제가 되지 않는다. 객체의 구체화 시점에 `member' 함수는 초기화되지 않기 때문이다. 그래서 무효한 int 생성은 탐지되지 못한 채로 그대로 남는다.
보통의 함수처럼 클래스 템플릿은 다른 함수와 클래스를 친구로 선언할 수 있다. 역으로, 보통의 클래스는 템플릿 클래스를 친구로 선언할 수 있다. 여기에서도 친구는 선언 클래스의 기능을 지원하고 도와주는 특별한 함수나 클래스로 생성된다. 클래스 템플릿을 사용할 때 friend 키워드는 보통의 클래스나 템플릿 클래스 유형에 사용할 수 없지만
다음의 경우는 구별해야 한다.
ostream 객체에 대한 삽입 연산자가 한 예이다.
친구 템플릿 매개변수의 실제 값이 친구를 선언한 클래스의 템플릿 매개변수와 같아야 한다면 그 친구는 묶인 친구(bound friend) 클래스 또는묶인 친구 함수 템플릿이라고 부른다. 이 경우 friend 선언을 지정한 템플릿의 템플릿 매개변수는 친구 클래스나 함수의 템플릿 매개변수의 값을 결정한다 (묶는다). 결과적으로, 묶인 친구는 템플릿의 매개변수와 친구의 템플릿 매개변수 사이에 일대일로 상응하게 된다.
이 경우라면 묶이지 않은 친구 클래스나 함수가 선언된다. 친구 클래스 템플릿이나 친구 함수 템플릿의 템플릿 매개변수는 여전히 그대로 지정할 필요가 있으며 친구를 선언한 클래스에 미리 선언된 템플릿 매개변수와 관련이 전혀 없다. 템플릿 매개변수로 지정된 다양한 유형의 데이터 멤버가 클래스 템플릿에 있다면 그리고 그 데이터 멤버에 또다른 클래스가 직접 접근하도록 허용해야 한다면 친구를 지정할 때 현재의 템플릿 인자를 하나하나 모조리 지정하고 싶을 것이다. 묶인 친구를 여럿 지정하기보다 (묶이지 않은) 총칭 친구를 하나만 선언하고 필요할 때만 친구의 실제 템플릿 매개변수를 지정할 수 있다.
구체적인 클래스와 평범한 함수를 친구로 선언할 수 있다. 그러나 클래스의 멤버 함수 하나를 친구로 선언하기 전에 먼저 컴파일러는 그 멤버를 선언한 클래스 인터페이스를 이미 보았어야 한다. 다양한 가능성을 연구해 보자:
function 자체가 템플릿이 아닌 한, 다음과 같은 구문은 C++이 지원하지 않기 때문에
void function(std::vector<Type> &vector)어떻게 그리고 왜 그런 친구를 생성해야 하는지 바로 확실하게 드러나지 않는다. 한 가지 이유는 클래스의 비밀 정적 멤버에 함수가 접근할 수 있도록 허용하기 때문일 것이다. 게다가 그런 함수는 친구로 선언한 클래스의 객체를 구체화할 수 있다. 이렇게 되면 친구 함수는 그런 객체의 비밀 멤버에 직접적으로 접근할 수 있다. 예를 들어:
template <typename Type>
class Storage
{
friend void basic();
static size_t s_time;
std::vector<Type> d_data;
public:
Storage();
};
template <typename Type>
size_t Storage<Type>::s_time = 0;
template <typename Type>
Storage<Type>::Storage()
{}
void basic()
{
Storage<int>::s_time = time(0);
Storage<double> storage;
std::random_shuffle(storage.d_data.begin(), storage.d_data.end());
}
template <typename Type>
class Composer
{
friend class Friend;
std::vector<Type> d_data;
public:
Composer();
};
class Friend
{
Composer<int> d_ints;
public:
Friend(std::istream &input);
};
inline::Friend::Friend(std::istream &input)
{
std::copy(std::istream_iterator<int>(input),
std::istream_iterator<int>(),
back_inserter(d_ints.d_data));
}
Friend::randomizer 멤버가 Composer 클래스의 친구로 선언되어 있다.
template <typename Type>
class Composer;
class Friend
{
Composer<int> *d_ints;
public:
Friend(std::istream &input);
void randomizer();
};
template <typename Type>
class Composer
{
friend void Friend::randomizer();
std::vector<Type> d_data;
public:
Composer(std::istream &input)
{
std::copy(std::istream_iterator<int>(input),
std::istream_iterator<int>(),
back_inserter(d_data));
}
};
inline Friend::Friend(std::istream &input)
:
d_ints(new Composer<int>(input))
{}
inline void Friend::randomizer()
{
std::random_shuffle(d_ints->d_data.begin(), d_ints->d_data.end());
}
이 예제에서 Friend::d_ints는 포인터 멤버이다. Composer<int> 객체가 될 수 없다. 컴파일러가 Friend의 클래스 인터페이스를 읽을 때 Composer의 클래스 인터페이스를 아직 읽지 못했기 때문이다. 이를 무시하고 Composer<int> d_ints 데이터 멤버를 정의하면 다음과 같은 컴파일 에러가 일어난다.
error: field `d_ints' has incomplete type 에러: `d_ints' 필드 유형이 불완전함`유형이 불완전하다'. 이 시점에 컴파일러는
Composer 클래스가 존재한다는 것을 알고는 있지만 아직 Composer의 인터페이스를 읽지 못했기 때문에 d_ints 데이터 멤버가 어느 정도의 크기인지 알지 못한다.
!key1.find(key2)를 돌려주는 전용 함수객체가 아마도 유용할 듯하다. 다음 예제는 operator==를 받아들일 수 있다.
template <typename Key, typename Value>
class Dictionary
{
friend Dictionary<Key, Value>
subset<Key, Value>(Key const &key,
Dictionary<Key, Value> const &dict);
std::map<Key, Value> d_dict;
public:
Dictionary();
};
template <typename Key, typename Value>
Dictionary<Key, Value>
subset(Key const &key, Dictionary<Key, Value> const &dict)
{
Dictionary<Key, Value> ret;
std::remove_copy_if(dict.d_dict.begin(), dict.d_dict.end(),
std::inserter(ret.d_dict, ret.d_dict.begin()),
std::bind2nd(std::equal_to<Key>(), key));
return ret;
}
Iterator 클래스를 Dictionary 클래스의 친구로 선언한다. 그리하여 Iterator는 Dictionary의 비밀 데이터에 접근할 수 있다. 여기에 눈여겨볼 만한 흥미로운 점들이 있다.
template <typename Key, typename Value>
class Iterator;
template <typename Key, typename Value>
class Dictionary
{
friend class Iterator<Key, Value>;
template <typename Key, typename Value>
template <typename Key2, typename Value2>
Iterator<Key2, Value2> Dictionary<Key, Value>::begin()
{
return Iterator<Key, Value>(*this);
}
template <typename Key, typename Value>
template <typename Key2, typename Value2>
Iterator<Key2, Value2> Dictionary<Key, Value>::subset(Key const &key)
{
return Iterator<Key, Value>(*this).subset(key);
}
Dictionary에 대하여 도움 함수일 뿐이므로 안전하게 std::map 데이터 멤버를 정의할 수 있다. 이 멤버는 그 친구 클래스의 생성자가 초기화한다. 그러면 생성자는 Dictionary의 d_dict 사전 데이터 멤버에 접근할 수 있다.
template <typename Key, typename Value>
class Iterator
{
std::map<Key, Value> &d_dict;
public:
Iterator(Dictionary<Key, Value> &dict)
:
d_dict(dict.d_dict)
{}
Iterator의 begin 멤버는 map 반복자를 돌려줄 수 있다. 컴파일러는 맵의 객체가 어떻게 생겼는지 알지 못하기 때문에 map<Key, Value>::iterator는 템플릿 부유형이다. 그래서 그대로 사용할 수 없고 앞에 typename 키워드를 붙여야 사용할 수 있다 (다음 예제에서 begin 함수의 반환 유형을 눈여겨보라):
template <typename Key, typename Value>
typename std::map<Key, Value>::iterator Iterator<Key, Value>::begin()
{
return d_dict.begin();
}
Dictionary만 Iterator를 생성할 수 있다고 결정할 수도 있었다 (어쩌면 개념적으로 Iterator를 Dictionary의 부유형으로 보기 때문일 수도 있다). 이것은 쉽게 달성된다. Iterator의 생성자를 비밀 구역에 정의하고 Dictionary를 Iterator의 친구로 정의하기만 하면 된다. 결론적으로 Dictionary만 Iterator를 생성할 수 있다. 특정한 Dictionary 유형의 생성자를 Iterator의 친구로 선언함으로써 묶인 친구를 선언한다. 이렇게 하면 그 특정한 유형의 Dictionary만 자신이 가진 것과 동일한 템플릿 매개변수를 사용하여 Iterator를 생성할 수 있다는 것을 확신할 수 있다. 다음은 그 방법이다.
template <typename Key, typename Value>
class Iterator
{
friend Dictionary<Key, Value>::Dictionary();
std::map<Key, Value> &d_dict;
Iterator(Dictionary<Key, Value> &dict);
public:
이 예제에서 Dictionary의 생성자는 Iterator의 친구이다. 그 친구는 템플릿 멤버이다. 다른 멤버들도 클래스의 친구로 선언할 수 있다. 그런 경우 그 원형을 사용해야 한다. 또 반환 값의 유형도 지정해야 한다. 다음과 같이
std::vector<Value> sortValues()
Dictionary의 멤버가 있다면 이에 부합하는 묶인 친구 선언은 다음과 같다.
friend std::vector<Value> Dictionary<Key, Value>::sortValues();
operator== 자유 멤버를 사용할 수 있어야 한다면 그래서 ClassTemplate에 대하여 typename Type 템플릿 유형 인자를 요구한다면 그러면 자유 멤버는
template<typename Type>
bool operator==(ClassTemplate<Type> const &lhs,
ClassTemplate<Type> const &rhs);
ClassTemplate의 인터페이스보다 먼저 선언되어 있어야 한다. 그래야 클래스 인터페이스 안에서 operator==를 친구로 선언할 수 있다. operator==를 다음과 같이 특정화된 함수 템플릿으로 지정한다 (다음 <> 함수 이름에 주목하라):
template <typename Type>
class ClassTemplate
{
friend bool operator==<>(ClassTemplate<Type> const &lhs,
ClassTemplate<Type> const &rhs);
...
};
이제 클래스를 선언했으므로 operator==의 구현은 다음과 같다.
마지막으로, 다음 예제를 묶인 친구가 유용한 상황에 원형으로 사용할 수 있다.
template <typename T> // 함수 템플릿
void fun(T *t)
{
t->not_public();
};
template<typename X> // 자유 함수 템플릿
bool operator==(A<X> const &lhs, A<X> const &rhs);
template <typename X> // 클래스 템플릿
class A
{ // fun() 는 A에 묶인 친구로 사용된다.
// X에 대하여 구체화됨. X에 상관 없음
friend void fun<A<X>>(A<X> *);
// 연산자==는 A<X>의 유일한 친구이다.
friend bool operator==<>(A<X> const &lhs, A<X> const &rhs);
int d_data = 10;
public:
A();
private:
void not_public();
};
template <typename X>
A<X>::A()
{
fun(this);
}
template <typename X>
void A<X>::not_public()
{}
template<typename X> // lhs/rhs의 비밀 데이터에 접근 가능
bool operator==(A<X> const &lhs, A<X> const &rhs)
{
return lhs.d_data == rhs.d_data;
}
int main()
{
A<int> a;
fun(&a); // A<int>에 대하어 구체화된다.
}
다음은 안 묶인 친구를 선언하는 구문적 관례이다.
template <typename Iterator, typename Class, typename Data>
Class &ForEach(Iterator begin, Iterator end, Class &object,
void (Class::*member)(Data &));
이 함수 템플릿은 다음 Vector2 클래스 템플릿에 안 묶인 친구로 선언할 수 있다.
template <typename Type>
class Vector2: public std::vector<std::vector<Type> >
{
template <typename Iterator, typename Class, typename Data>
friend Class &ForEach(Iterator begin, Iterator end, Class &object,
void (Class::*member)(Data &));
...
};
함수 템플릿이 어떤 이름공간 안에 정의되어 있으면 이 이름공간도 역시 언급해야 한다. ForEach가 이름공간 FBB에 정의되어 있다고 가정하자. 그의 친구 선언은 다음과 같이 된다.
template <typename Iterator, typename Class, typename Data>
friend Class &FBB::ForEach(Iterator begin, Iterator end, Class &object,
void (Class::*member)(Data &));
다음 예제는 안 묶인 친구의 사용법을 보여준다. Vector2 클래스는 템플릿 유형 매개변수 Type의 원소들의 벡터를 저장한다. process 멤버는 ForEach가 비밀 rows 멤버를 호출하도록 허용한다. rows 멤버는 이번에는 또다른 ForEach가 columns 비밀 멤버를 호출하도록 허용한다. 결론적으로 Vector2는 두 개의 ForEach 객체를 사용한다. 이것은 안 묶인 친구를 사용하라는 확실한 징표이다. Type 클래스 객체는 ostream 객체에 삽입될 수 있다고 간주된다 (ForEach 함수 템플릿의 정의는 cplusplus.yo.zip 압축 파일에서 볼 수 있다. https://github.com/fbb-git/cppannotations 참고). 다음은 그 프로그램이다.
template <typename Type>
class Vector2: public std::vector<std::vector<Type> >
{
typedef typename Vector2<Type>::iterator iterator;
template <typename Iterator, typename Class, typename Data>
friend Class &ForEach(Iterator begin, Iterator end, Class &object,
void (Class::*member)(Data &));
public:
void process();
private:
void rows(std::vector<Type> &row);
void columns(Type &str);
};
template <typename Type>
void Vector2<Type>::process()
{
ForEach<iterator, Vector2<Type>, std::vector<Type> >
(this->begin(), this->end(), *this, &Vector2<Type>::rows);
}
template <typename Type>
void Vector2<Type>::rows(std::vector<Type> &row)
{
ForEach(row.begin(), row.end(), *this,
&Vector2<Type>::columns);
std::cout << '\n';
}
template <typename Type>
void Vector2<Type>::columns(Type &str)
{
std::cout << str << " ";
}
using namespace std;
int main()
{
Vector2<string> c;
c.push_back(vector<string>(3, "Hello"));
c.push_back(vector<string>(2, "World"));
c.process();
}
/*
출력:
Hello Hello Hello
World World
*/
template <typename Type>
class PtrVector
{
template <typename Iterator, typename Class>
friend class Wrapper; // 안 묶인 친구 클래스
};
Wrapper 클래스 템플릿의 모든 멤버는 이제 PtrVector를 Type 매개변수에 대한 실제 유형을 사용하여 구체화한다. 이렇게 하면 Wrapper 객체는 PtrVector의 모든 비밀 멤버에 접근할 수 있다.
PtrVector는 Wrapper::begin을 친구로 선언한다. Wrapper 클래스를 전방 선언한 것에 주목하라:
template <typename Iterator>
class Wrapper;
template <typename Type>
class PtrVector
{
template <typename Iterator> friend
PtrVector<Type> Wrapper<Iterator>::begin(Iterator const &t1);
...
};
friend 키워드가 의미를 가지는 유형이 되어야 할 필요는 없다. 예를 들어 int와 같은 경우라면 친구 선언은 그냥 무시된다.
다음 클래스 템플릿을 연구해 보자. Friend를 친구로 선언한다.
template <typename Friend>
class Class
{
friend Friend;
void msg(); // 비밀 멤버이다. 메시지를 보여준다.
};
이제, 실제 Friend 클래스는 Class의 모든 멤버에 접근할 수 있다.
class Concrete
{
Class<Concrete> d_class;
Class<std::string> d_string;
public:
void msg()
{
d_class.msg(); // OK: 비밀 Class<Concrete>::msg()를 호출한다.
//d_string.msg(); // 컴파일에 실패한다. msg()가 비밀이기 때문이다.
}
};
Class<int> intClass와 같이 선언해도 좋다. 그러나 여기에서 친구 선언은 그냥 무시된다. 어쨌거나 Class<int>의 비밀 멤버에 접근하는 `int 멤버'는 없다.
다음 바탕 클래스를 연구해 보자:
template<typename T>
class Base
{
T const &t;
public:
Base(T const &t);
};
위의 클래스는 다음 Derived 파생 클래스 템플릿에 대하여 바탕 클래스로 사용할 수 있는 클래스 템플릿이다.
template<typename T>
class Derived: public Base<T>
{
public:
Derived(T const &t);
};
template<typename T>
Derived<T>::Derived(T const &t)
:
Base(t)
{}
물론 다른 조합도 가능하다. 바탕 클래스는 템플릿 인자를 지정하면 구체화할 수 있다. 파생 클래스를 평범한 클래스로 변신시킨다 (클래스 객체의 정의도 보여준다):
class Ordinary: public Base<int>
{
public:
Ordinary(int x);
};
inline Ordinary::Ordinary(int x)
:
Base(x)
{}
Ordinary ordinary(5);
이 접근법으로 파생 클래스 템플릿을 생성할 필요 없이 클래스 템플릿에 기능을 더할 수 있다.
클래스 템플릿 파생은 평범한 클래스 파생과 똑 같은 규칙을 거의 모두 따른다. 클래스 템플릿 파생에서만 볼 수 있는 약간 미묘한 점 때문에 쉽게 혼란을 야기할 수 있다. 예를 들어 템플릿 바탕 클래스의 멤버들이 파생 클래스로부터 호출될 때 this를 사용하는 것과 혼동된다. this를 사용하는 이유는 23.1절에 논의했다. 다음 항은 적절한 클래스 파생에 관하여 초점을 두겠다.
map 클래스는 find_if() 총칭 알고리즘과 조합하여 쉽게 사용할 수 있지만 클래스의 생성을 요구하고 적어도 그 클래스의 함수객체 두 개를 추가로 요구한다 (19.1.16항). 너무 부담스럽다면 클래스 템플릿을 맞춤 기능으로 확장하는 것을 고려해 볼 수 있다.
예를 들어 키보드에 입력되는 명령어를 실행하는 프로그램은 명령어의 약자를 모두 받을 수 있다. 예를 들어 명령어가 list라면 l, li, lis 또는 list로 입력할 수 있다. 다음으로부터 Handler를 상속받고
map<string, void (Handler::*)(string const &cmd)>
process(string const &cmd) 멤버 함수가 실제로 명령어를 처리하도록 정의하기면 하면 프로그램은 다음 main() 함수를 실행할 수 있다.
int main()
{
string line;
Handler cmd;
while (getline(cin, line))
cmd.process(line);
}
Handler 클래스 자체는 std::map으로부터 파생된다. 맵의 값들은 Handler의 멤버 함수를 가리키는 포인터이다. 사용자가 입력한 명령줄을 기대한다. 다음은 Handler의 특징이다.
std::map으로부터 파생되고 명령어-처리 멤버와 연관된 명령어를 키로 기대한다. Handler는 명령어와 그리고 처리 멤버 함수 사이의 연관 관계를 정의하기 위해 그리고 map의 typedef를 사용할 수 있도록 하기 위해 맵을 사용하기 때문에 비밀 파생이 사용된다.
class Handler: private std::map<std::string,
void (Handler::*)(std::string const &cmd)>
s_cmds는 Handler::value_type 값의 배열이다. 그리고 s_cmds_end는 배열의 마지막 원소 다음을 가리키는 상수 포인터이다.
static value_type s_cmds[];
static value_type *const s_cmds_end;
inline Handler::Handler()
:
std::map<std::string,
void (Handler::*)(std::string const &cmd)>
(s_cmds, s_cmds_end)
{}
process 멤버는 맵의 원소를 반복한다. 첫 단어가 명령어 줄에서 명령어의 첫 문자에 일치하면 상응하는 명령어가 실행된다. 그런 명령어가 없으면 에러 메시지를 보여준다.
void Handler::process(std::string const &line)
{
istringstream istr(line);
string cmd;
istr >> cmd;
for (iterator it = begin(); it != end(); it++)
{
if (it->first.find(cmd) == 0)
{
(this->*it->second)(line);
return;
}
}
cout << "Unknown command: " << line << '\n';
}
아래에 보여주는 SortVector 클래스 템플릿은 기존 std::vector 클래스 템플릿으로부터 상속받는다. 그러면 그의 데이터 원소에 포함된 데이터 멤버들의 정렬 순서를 사용하여 그 안의 원소들을 계통적으로 정렬할 수 있다. 이를 달성하려면 한 가지 요구 조건만 충족하면 된다. SortVector의 데이터 유형은 멤버를 비교하는 전용 멤버 함수를 제공해야 한다.
예를 들어 SortVector의 데이터 유형이 MultiData 클래스의 객체라면 MultiData는 비교할 수 있는 데이터 멤버 각각에 대하여 원형이 다음과 같은 멤버 함수를 구현해야 한다.
bool (MultiData::*)(MultiData const &rhv)
그래서 MultiData에 데이터 멤버로 int d_value와 std::string d_text 두 개가 있고 둘 다 계통적 정렬에 사용된다면 MultiData는 다음 두 멤버를 제공해야 한다.
bool intCmp(MultiData const &rhv); // d_value < rhv.d_value를 돌려준다.
bool textCmp(MultiData const &rhv); // d_text < rhv.d_text를 돌려준다.
게다가 편의상 operator<< 연산자와 operator>> 연산자가 MultiData 객체에 대하여 정의되어 있다고 간주한다.
SortVector 클래스 템플릿은 직접적으로 std::vector 템플릿으로부터 파생된다. 우리의 구현은 그 바탕 클래스로부터 모든 멤버를 상속받는다. 또한 두 개의 간단한 생성자를 제공한다.
template <typename Type>
class SortVector: public std::vector<Type>
{
public:
SortVector()
{}
SortVector(Type const *begin, Type const *end)
:
std::vector<Type>(begin, end)
{}
hierarchicSort 멤버는 클래스의 진정한 존재 이유(raison d'être)이다. 계통적 정렬 기준을 정의한다. Type 클래스의 멤버 함수를 가리키는 일련의 포인터의 포인터와 더불어 그 배열의 크기를 나타내는 size_t를 기대한다.
배열의 첫 원소는 Type의 가장 중요한 정렬 기준을 가리킨다. 배열의 마지막 원소는 클래스에서 가장 중요도가 낮은 정렬 기준을 가리킨다. stable_sort 총칭 알고리즘은 명시적으로 계통적 정렬을 지원하도록 설계되었기 때문에 멤버는 이 총칭 알고리즘을 사용하여 SortVector의 원소들을 정렬한다. 중요도가 가장 낮은 기준이 먼저 계통적으로 정렬되어야 한다. 그러므로 hierarchicSort의 구현은 어렵지 않다. 지원 클래스 SortWith를 요구한다. 그의 객체들은 hierarchicSort() 멤버에 건넨 멤버 함수의 주소로 초기화된다.
template <typename Type>
void SortVector<Type>::hierarchicSort(
bool (Type::**arr)(Type const &rhv) const,
size_t n)
{
while (n--)
stable_sort(this->begin(), this->end(), SortWith<Type>(arr[n]));
}
SortWith 클래스는 진위 함수를 포인터로 감싼 단순한 포장 클래스이다. SortVector의 실제 유형에 의존하기 때문에 SortWith 클래스는 클래스 템플릿일 수 있다.
template <typename Type>
class SortWith
{
bool (Type::*d_ptr)(Type const &rhv) const;
SortWith의 생성자는 진위 함수를 포인터로 받는다. 그리고 클래스의 d_ptr 데이터 멤버를 초기화한다.
template <typename Type>
SortWith<Type>::SortWith(bool (Type::*ptr)(Type const &rhv) const)
:
d_ptr(ptr)
{}
이항 진위 함수(operator())의 첫 인자가 결국 두 번째 인자보다 앞에 배치되어야 한다면 true를 돌려주어야 한다.
template <typename Type>
bool SortWith<Type>::operator()(Type const &lhv, Type const &rhv) const
{
return (lhv.*d_ptr)(rhv);
}
main 함수 안에 내장할 수 있는 다음 예제는 한 예를 보여준다.
SortVector 객체가MultiData 객체에 대하여 생성된다. copy 총칭 알고리즘을 사용하여 프로그램의 표준 입력 스트림에 나타나는 정보로부터 SortVector 객체를 채운다. 객체를 초기화했으므로 그의 원소들이 표준 출력 스트림에 보여진다.
SortVector<MultiData> sv;
copy(istream_iterator<MultiData>(cin),
istream_iterator<MultiData>(),
back_inserter(sv));
bool (MultiData::*arr[])(MultiData const &rhv) const =
{
&MultiData::textCmp,
&MultiData::intCmp,
};
sv.hierarchicSort(arr, 2);
MultiData의 멤버 함수를 가리키는 포인터 배열의 두 개의 원소를 서로 바꾼다. 이전 단계를 반복한다.
swap(arr[0], arr[1]);
sv.hierarchicSort(arr, 2);
echo a 1 b 2 a 2 b 1 | a.out
결과는 다음 출력과 같다.
a 1 b 2 a 2 b 1
====
a 1 a 2 b 1 b 2
====
a 1 b 1 a 2 b 2
====
이 접근법은 멤버 함수의 구현이 템플릿 매개변수에 의존하지 않는 모든 클래스 템플릿에 사용할 수 있다. 이 멤버들은 별도의 클래스에 정의한다. 그 다음에 바탕 클래스로 사용하여 클래스 템플릿을 파생시킨다.
이 접근법을 보여주기 위해 아래에 그런 클래스 템플릿을 개발해 보자. 평범한 TableType 클래스로부터 파생된 Table 클래스를 개발해 보겠다. Table 클래스는 어떤 유형의 원소들을 테이블에 보여준다. 테이블은 열의 갯수를 조절할 수 있다. 원소들은 수평으로 보여주거나 (첫 번째 k개의 원소가 첫 번째 행을 점유한다) 아니면 수직으로 보여준다 (첫 번째 r개의 원소가 첫 번째 열을 점유한다).
테이블의 원소들을 보여줄 때 그 원소들은 스트림 안으로 삽입된다. 테이블은 테이블의 표현을 구현한 별도의 클래스(TableType)가 제어한다. 테이블의 원소가 스트림 안으로 삽입되기 때문에 텍스트로 (또는 string으로) 변환하는 것은 Table 안에 구현되지만 문자열 자체의 처리는 TableType에게 맡긴다. 잠시 후에 TableType의 특징을 살펴 보겠다. 먼저 Table의 인터페이스에 집중하자:
Table 클래스는 클래스 템플릿이다. 하나의 템플릿 유형 매개변수만 요구한다. 어떤 데이터 유형을 가리키는 반복자에 대하여 참조하는 Iterator만 있으면 된다.
template <typename Iterator>
class Table: public TableType
{
Table은 데이터 멤버가 전혀 필요 없다. 모든 데이터 조작은 TableType이 수행한다.
Table은 생성자가 두 개이다. 생성자의 앞쪽 매개변수 두 개는 반복자(Iterator)로서 테이블 안에 삽입할 원소들을 방문한다. 생성자는 FillDirection과 더불어 테이블의 열의 갯수를 지정하기를 요구한다. FillDirection은 열거체이며 TableType이 정의하고 값은 HORIZONTAL과 VERTICAL이 있다. Table의 사용자가 머리와 꼬리와 제목 그리고 수직 가름자와 수평 가름자를 제어할 수 있도록 생성자 하나는 TableSupport라는 참조 매개변수가 있다. TableSupport 클래스는 나중에 가상 클래스로 개발한다. 클라이언트가 이 콘트롤을 시험해 보도록 허용한다. 다음은 클래스의 생성자이다.
Table(Iterator const &begin, Iterator const &end,
size_t nColumns, FillDirection direction);
Table(Iterator const &begin, Iterator const &end,
TableSupport &tableSupport,
size_t nColumns, FillDirection direction);
Table의 유일한 공개 멤버 두 개이다. 두 생성자 모두 바탕 클래스 초기화를 사용하여 TableType 바탕 클래스를 초기화하고 난 다음에 그 클래스의 fill 비밀 멤버 함수를 호출하여 데이터를 TableType 바탕 클래스 객체 안에 삽입한다. 다음은 생성자의 구현이다.
template <typename Iterator>
Table<Iterator>::Table(Iterator const &begin, Iterator const &end,
TableSupport &tableSupport,
size_t nColumns, FillDirection direction)
:
TableType(tableSupport, nColumns, direction)
{
fill(begin, end);
}
template <typename Iterator>
Table<Iterator>::Table(Iterator const &begin, Iterator const &end,
size_t nColumns, FillDirection direction)
:
TableType(nColumns, direction)
{
fill(begin, end);
}
fill 멤버는 [begin, end) 범위의 원소를 생성자의 앞 쪽 매개변수 두 개에 정의된 순서대로 방문한다. 잠시 후에 보겠지만 TableType은 보호 std::vector<std::string> d_string 데이터 멤버를 정의한다. 반복자가 가리키는 데이터 유형의 요구 조건 중 하나는 이 데이터 유형이 스트림 안에 삽입이 가능해야 한다는 것이다. 그래서 fill은 ostringstream 객체를 사용하여 그 데이터의 텍스트 표현을 얻는다. 이것이 d_string에 추가된다.
template <typename Iterator>
void Table<Iterator>::fill(Iterator it, Iterator const &end)
{
while (it != end)
{
std::ostringstream str;
str << *it++;
d_string.push_back(str.str());
}
init();
}
이것으로 Table 클래스의 구현을 마친다. 이 클래스 템플릿은 멤버가 세 개이고 그 중에 두 개는 생성자임에 주목하라. 그러므로 대부분의 경우 두 개의 함수 템플릿만 구체화될 것이다. 즉, 생성자와 클래스의 fill 멤버만 구체화된다. 예를 들어 다음은 열이 네 개이고 표준 입력으로부터 추출된 string이 수직으로 채워진 테이블을 정의한다.
Table<istream_iterator<string> >
table(istream_iterator<string>(cin), istream_iterator<string>(),
4, TableType::VERTICAL);
채움-방향은 TableType::VERTICAL으로 지정된다. 또 Table을 사용하여 지정할 수도 있었지만 Table은 클래스 템플릿이기 때문에 그 지정 방식은 약간 더 복잡했을 것이다. 즉, Table<istream_iterator<string> >::VERTICAL과 같이 지정해야 한다.
이제 Table 파생 클래스를 설계했으므로 TableType 클래스에 눈길을 돌려 보자. 다음은 그의 핵심적인 특징이다.
Table의 바탕 클래스와 작동하도록 설계되었다.
d_colWidth는 열당 가장 넓은 원소의 너비를 저장한 벡터이고 d_indexFun는 테이블의 채움 방향에 따라 table[row][column]에 있는 해당 원소를 돌려주는 클래스의 멤버 함수를 가리킨다. TableType은 또한 TableSupport 포인터와 참조를 사용한다. TableSupport 객체를 요구하지 않는 생성자는 TableSupport *를 사용하여 (기본) TableSupport 객체를 할당한 다음, TableSupport &를 그 객체의 별칭으로 사용한다. 다른 생성자는 포인터를 0으로 초기화하고 참조 데이터 멤버를 사용하여 매개변수로 건네어진 TableSupport 객체를 참조한다. 다른 방법으로서 정적 TableSupport 객체를 사용하여 이전 생성자의 참조 데이터 멤버를 초기화할 수도 있었다. 나머지 비밀 데이터 멤버는 그 자체로 설명이 될 것이라 믿는다.
TableSupport *d_tableSupportPtr;
TableSupport &d_tableSupport;
size_t d_maxWidth;
size_t d_nRows;
size_t d_nColumns;
WidthType d_widthType;
std::vector<size_t> d_colWidth;
size_t (TableType::*d_widthFun)
(size_t col) const;
std::string const &(TableType::*d_indexFun)
(size_t row, size_t col) const;
string 객체는 보호 데이터 멤버에 저장된다.
std::vector<std::string> d_string;
TableSupport 객체를 참조로 기대하는 생성자이다.
#include "tabletype.ih"
TableType::TableType(TableSupport &tableSupport, size_t nColumns,
FillDirection direction)
:
d_tableSupportPtr(0),
d_tableSupport(tableSupport),
d_maxWidth(0),
d_nRows(0),
d_nColumns(nColumns),
d_widthType(COLUMNWIDTH),
d_colWidth(nColumns),
d_widthFun(&TableType::columnWidth),
d_indexFun(direction == HORIZONTAL ?
&TableType::hIndex
:
&TableType::vIndex)
{}
d_string이 채워지면 테이블은 Table::fill로 초기화된다. init 보호 멤버는 정확하게 rows x columns에 맞도록 d_string의 크기를 바꾼다. 그리고 열당 원소들의 최대 너비를 결정한다. 눈에 보이는 그대로 구현된다.
#include "tabletype.ih"
void TableType::init()
{
if (!d_string.size()) // 원소가 없다면
return; // 아무 일도 하지 않는다.
d_nRows = (d_string.size() + d_nColumns - 1) / d_nColumns;
d_string.resize(d_nRows * d_nColumns); // 완전한 테이블을 강제한다.
// 열당 최대 너비와
// 최대 열 너비를 결정한다.
for (size_t col = 0; col < d_nColumns; col++)
{
size_t width = 0;
for (size_t row = 0; row < d_nRows; row++)
{
size_t len = stringAt(row, col).length();
if (width < len)
width = len;
}
d_colWidth[col] = width;
if (d_maxWidth < width) // max. 지금까지의 너비(width).
d_maxWidth = width;
}
}
insert 공개 멤버는 operator<< 삽입 연산자가 사용하여 Table을 스트림에 삽입한다. 먼저 TableSupport 객체에 테이블의 크기에 관하여 알린다. 다음으로 테이블을 화면에 보여준다. TableSupport 객체는 머리와 꼬리 그리고 가름자를 쓸 수 있다.
#include "tabletype.ih"
ostream &TableType::insert(ostream &ostr) const
{
if (!d_nRows)
return ostr;
d_tableSupport.setParam(ostr, d_nRows, d_colWidth,
d_widthType == EQUALWIDTH ? d_maxWidth : 0);
for (size_t row = 0; row < d_nRows; row++)
{
d_tableSupport.hline(row);
for (size_t col = 0; col < d_nColumns; col++)
{
size_t colwidth = width(col);
d_tableSupport.vline(col);
ostr << setw(colwidth) << stringAt(row, col);
}
d_tableSupport.vline();
}
d_tableSupport.hline();
return ostr;
}
cplusplus.yo.zip 압축 파일에 TableSupport의 전체 구현이 들어 있다. 이 구현은 yo/classtemplates/examples/table 디렉토리에 있다. 나머지 멤버는 대부분 비밀이다. 그 중에서도 다음 두 멤버는 각각 수평으로 채운 테이블과 수직으로 채운 테이블에 대하여 테이블 원소 [row][column]를 돌려준다.
inline std::string const &TableType::hIndex(size_t row, size_t col) const
{
return d_string[row * d_nColumns + col];
}
inline std::string const &TableType::vIndex(size_t row, size_t col) const
{
return d_string[col * d_nRows + row];
}
TableSupport 지원 클래스는 머리와 꼬리 그리고 제목과 가름자를 보여주는 데 사용된다. 네 개의 가상 멤버가 있어서 그 일을 수행한다 (물론, 가상 생성자이다):
hline(size_t rowIndex): 원소를 rowIndex행에 보여주기 직전에 호출된다.
hline(): 마지막 행을 보여준 후에 바로 호출된다.
vline(size_t colIndex): colIndex 열에 원소를 보여주기 직전에 호출된다.
vline(): 모든 원소를 한 행에 보여준 후에 바로 호출된다.
cplusplus.yo.zip 압축 파일을 참고하시기를 바란다. 안에 Table 클래스와 TableType 그리고 TableSupport의 완전한 구현이 들어 있다. 다음은 사용법을 보여주는 작은 프로그램이다.
/*
table.cc
*/
#include <fstream>
#include <iostream>
#include <string>
#include <iterator>
#include <sstream>
#include "tablesupport/tablesupport.h"
#include "table/table.h"
using namespace std;
using namespace FBB;
int main(int argc, char **argv)
{
size_t nCols = 5;
if (argc > 1)
{
istringstream iss(argv[1]);
iss >> nCols;
}
istream_iterator<string> iter(cin); // 첫 번째 반복자가 상수가 아니다.
Table<istream_iterator<string> >
table(iter, istream_iterator<string>(), nCols,
argc == 2 ? TableType::VERTICAL : TableType::HORIZONTAL);
cout << table << '\n';
}
/*
생성된 출력 예제:
After: echo a b c d e f g h i j | demo 3
a e i
b f j
c g
d h
After: echo a b c d e f g h i j | demo 3 h
a b c
d e f
g h i
j
*/
그렇지만 많은 경우에 동적 다형성은 실제로 필수가 아니다. 일반적으로 바탕 클래스 참조를 기대하는 함수에 건넨 파생 클래스 객체는 (언제나 참인) 불변 객체이다. 고정된 위치에서 고정된 클래스 유형을 사용하여 객체를 생성한다. 바탕 클래스를 참조로 기대하는 객체를 받는 함수 안에서 이런 객체들의 다형적 성격이 사용된다. 예를 들어 네트워크 소켓으로부터 정보를 읽는 것을 생각해 보자. SocketBuffer 클래스는 std::streambuf로부터 파생되고 SocketBuffer를 포인터로는 std::stream은 그저 std::streambuf의 인터페이스를 사용하면 그 뿐이다. 그렇지만 그 구현은 다형성을 사용함으로써 사실은 SocketBuffer에 정의된 함수와 통신하는 것이다.
이 전략의 단점은 첫째로 다형적 바탕 클래스를 참조로 기대하는 함수 안에서 실행 속도가 좀 떨어진다는 것이다. 늦은-묶기 때문이다. 멤버 함수들은 직접적으로 호출되지 않는다. 그러나 간접적으로 객체의 vpointer와 파생 클래스의 vtable을 통하여 호출된다. 둘째로 동적 다형성을 사용하는 프로그램은 정적 묶기를 사용하는 프로그램에 비해 약간 코드가 커지는 경향이 있다. 코드 비만은 최종 프로그램을 구성하는 모든 오브젝트 파일에 언급된 모든 참조를 링크 시간에 만족시키려는 요구 때문에 야기된다. 이 요구 조건 때문에 링커는 모든 동적 클래스의 vtable에 저장된 주소에 있는 함수를 모두 링크한다. 심지어 함수가 실제로 호출되지 않더라도 말이다.
이런 단점은 정적 다형성으로 극복할 수 있다. 동적 다형성 대신에 위에 언급한 불변 객체가 보유하는 정적 다형성을 사용할 수 있다. 정적 다형성은 흥미롭게도 재귀적 템플릿 패턴이라고도 불리운다. 템플릿 메타 프로그래밍의 한 예이다 (템플릿 메타 프로그래밍의 예제는 제 23장).
동적 다형성은 vpointer와 Vtable 그리고 함수 재정의라는 개념에 기반하는 반면에, 정적 다형성은 함수 템플릿이 (멤버 템플릿) 실제로 호출될 경우에만 실행 코드로 컴파일되어 들어간다는 사실을 이용한다. 이 덕분에 코드 작성 시점에 완전히 존재하지 않는 함수를 호출하는 코드를 작성할 수 있다. 그렇지만 이것은 너무 걱정하지 않아도 된다. 어쨌거나 추상 바탕 클래스의 순수한 가상 함수를 호출할 때 비슷한 접근법을 사용한다. 그 함수는 실제로 호출되지만 결국 어느 함수가 호출될지는 나중에 결정된다. 동적 다형성은 실행 시간에 결정된다. 반면에 정적 다형성은 컴파일 시간에 결정된다.
정적 다형성과 동적 다형성을 서로 배척하는 것으로 생각할 필요가 없다. 그 보다 둘 모두를 함께 사용하면 그 힘을 배가할 수 있다.
이 절은 여러 항이 들어 있다.
동적 다형성의 문맥에서 재정의할 수 있는 이 멤버들은 바탕 클래스의 가상 멤버들이다. 정적 다형성의 문맥에서 가상 멤버는 없다. 대신에 정적 다형성 바탕 클래스(앞으로 '바탕 클래스')는 템플릿 유형 매개변수(앞으로 '파생 클래스 유형')를 선언한다. 다음, 바탕 클래스의 인터페이스 멤버는 파생 클래스 유형의 멤버를 호출한다.
다음은 간단한 예이다. 바탕 클래스로 행위하는 클래스 템플릿을 살펴 보자. 그의 공개 인터페이스는 하나의 멤버로 구성된다. 그러나 동적 다형성과 다르게 클래스 인터페이스에 다형적 행위를 보여주는 멤버에 대한 참조가 전혀 없다 (즉, `가상' 멤버가 전혀 선언되어 있지 않다):
template <class Derived>
struct Base
{
void interface();
}
`interface' 멤버를 더 자세하게 살펴 보자. 이 멤버는 바탕 클래스에 대한 참조나 포인터를 받는 함수들이 호출한다. 그러나 interface가 호출될 시점에 파생 클래스 유형에서 사용할 수 있어야 하는 멤버들을 호출할 수도 있다. 파생 클래스 유형의 멤버를 호출할 수 있으려면 먼저 파생 클래스 유형의 객체를 사용할 수 있어야 한다. 이 객체는 상속을 통하여 얻는다. 파생 클래스 유형은 바탕 클래스로부터 파생될 것이다. 그리하여 Base 클래스의 this 포인터는 또한 Derived 클래스의 this 포인터이기도 하다.
잠시 다형성에 관해서는 잊어 버리자: class Derived: public Base가 있다면 (상속 덕분에) static_cast<Derived *>를 사용하여 Base *를 Derived 객체로 유형을 변환할 수 있다. 물론 dynamic_cast는 적용할 수 없다. 동적 다형성을 사용하지 않았기 때문이다. 그러나 static_cast는 적절하다. 실제로 Base *는 Derived 클래스 객체를 가리키기 때문이다.
그래서 Derived 클래스 멤버를 interface 안에서 호출하려면 다음 구현을 사용할 수 있다 (Base는 Derived의 바탕 클래스임을 기억하라):
template<class Derived>
void Base<Derived>::interface()
{
static_cast<Derived *>(this)->polymorphic();
}
특이하게도 컴파일러에게 이 구현을 주면 컴파일러는 Derived가 실제로 Base로부터 파생되었는지 아닌지 결정하지 못한다. 심지어 Derived 클래스가 실제로 polymorphic 멤버를 제공하는지 그 여부도 결정하지 못한다. 컴파일러는 단지 이것이 참이라고 간주할 뿐이다. 그렇다면 제공된 구현은 구문적으로 올바르다. 템플릿을 사용하는 핵심 특징 중 하나는 구현의 가시성이 결국 함수가 구체화되는 시점에 결정된다는 것이다 (21.6절). 그 시점에야 컴파일러는 polymorphic 함수를 실제로 사용할 수 있는지 없는지 결정할 수 있을 것이다.
그래서 위의 전략을 사용하려면 다음을 확인해야 한다.
polymorphic' 멤버를 정의하는가?
class First: public Base<First>
이 묘한 패턴에서 First 클래스는 Base로부터 파생되고 Base자체는 First에 대하여 구체화된다. 이것은 받아 들일 수 있다. First 유형이 존재한다고 컴파일러가 이미 결정했기 때문이다. 이 시점에 그것으로 충분하다.
두 번째 요구 조건은 polymorphic 멤버를 정의하면 간단하게 충족된다. 제 14장에서 가상 멤버와 재정의 멤버는 클래스의 비밀 인터페이스에 속하는 것을 보았다. 같은 정책을 여기에도 적용할 수 있다. polymorphic을 First의 비밀 인터페이스에 배치하면 바탕 클래스에서 접근할 수 있다. 다음과 같이 선언하면 된다.
friend void Base<First>::interface();
이제 First의 클래스 인터페이스를 완전하게 설계할 수 있다. 다음에 polymorphic 구현이 따른다.
class First: public Base<First>
{
friend void Base<First>::interface();
private:
void polymorphic();
};
void First::polymorphic()
{
std::cout << "polymorphic from First\n";
}
First 클래스 자체는 클래스 템플릿이 아니라는 사실에 주목하라: 그의 멤버들은 따로 라이브러리에 컴파일하고 정렬할 수 있다. 또한, 동적 다형성의 경우처럼 polymorphic 멤버는 First의 모든 데이터 멤버와 멤버 함수에 완전히 접근할 수 있다.
이제 다중 클래스를 First처럼 설계할 수 있다. 각 클래스마다 독자적으로 polymorphic을 구현한다. 예를 들어 First처럼 설계된 Second 클래스의 Second::polymorphic 멤버는 다음과 같이 구현할 수 있다.
void Second::polymorphic()
{
std::cout << "polymorphic from Second\n";
}
Base 클래스의 다형적 본성은 함수 템플릿을 정의하고 그 안에서 Base::interface를 호출해 보면 명백하게 드러난다. 역시 컴파일러는 단순히 다음 함수 템플릿의 정의를 읽을 때 interface 멤버가 존재한다고 가정한다.
template <class Class>
void fun(Class &object)
{
object.interface();
}
이 함수가 실제로 호출되는 상황에서만 컴파일러는 생성된 코드의 생존 가능성을 검증할 것이다. 다음 main 함수에서 First 객체는 fun에 건네진다. First는 바탕 클래스를 통하여 interface를 선언하고 First::polymorphic는 interface가 호출한다. 컴파일러는 이 시점에 (즉, fun이 호출되는 시점에) first에 실제로 polymorphic 멤버가 있는지 점검할 것이다. 다음으로 Second 객체를 fun에 건네고 역시 또 컴파일러는 Second에 Second::polymorphic 멤버가 있는지 점검한다.
int main()
{
First first;
fun(first);
Second second;
fun(second);
}
Second 객체를 fun에 건넨다'라는 문장은 형식적으로 올바르지 않다. fun은 함수 템플릿이기 때문에 fun(first)와 fun(second)로 호출된 fun 함수는 서로 전혀 다른 함수이다. 같은 함수를 서로 다른 인자로 호출한 것이 아니다.
정적 다형성에서 자신만의 템플릿 매개변수를 사용하여 구체화하면 무엇이든 템플릿을 구체화할 때 완전히 새로운 코드가 생성된다 (예를 들어 fun). 정적 다형성 바탕 클래스를 만들 때 이 사실을 명심해야 할 것이다. 바탕 클래스가 데이터 멤버와 멤버 함수를 정의하고 이렇게 추가된 멤버들을 파생 클래스 유형이 사용한다면 각 멤버마다 각각의 파생 클래스 유형에 대하여 따로 자신만의 객체가 있다.
이 때문에 코드 비만이 야기된다. 물론 동적 다형성에서 관찰했던 코드 비만과는 종류가 다르다. 이런 종류의 코드 비만은 줄일 수 있다. 자신의 (평범한 비-템플릿) 바탕 클래스로부터 바탕 클래스를 파생시키면 된다. 정적 다형성 바탕 클래스의 템플릿 유형 매개변수에 의존하지 않는 모든 멤버들을 캡슐화해 넣으면 해결된다.
new 연산자를 사용하여) 동적으로 생성되면 반환된 포인터의 유형은 모두 다르다. 게다가 정적 다형성 바탕 클래스를 가리키는 포인터의 유형도 서로 다 다르다. 이 후자의 포인터는 다르다. Base<Derived>를 가리키는 포인터이기 때문이다. 서로 다른 Derived 유형에 대하여 서로 다른 유형을 대표한다. 결과적으로 그리고 동적 다형성과 다르게 이 포인터들은 바탕 클래스 포인터를 가리키는 공유 포인터의 벡터에 모을 수 없다. 바탕 클래스 포인터 유형이 하나가 아니기 때문이다. 바탕 클래스 유형이 모두 다르기 때문에 가상 소멸자와 직접적으로 동등한 정적 다형성 멤버는 없다.
제 14장에서 Vehicle 바탕 클래스와 그의 파생 클래스들을 소개했다. (다형적 행위에 관련된 멤버들에 관하여) Vehicle과 Car 그리고 Truck의 인터페이스는 다음과 같다.
class Vehicle
{
public:
int mass() const;
private:
virtual int vmass() const;
};
class Car: public Vehicle
{
private:
int vmass() const override;
};
class Truck: public Car
{
private:
int vmass() const override;
};
동적 다형성 클래스를 정적 다형성 클래스로 바꿀 때 알아야 할 것이 있다. 다형성 클래스는 두 가지 중요한 특징이 있다.
Vecicle::mass와 같은 멤버 데이터와 멤버 함수를 정의한다. 즉, 인터페이스를 상속받는다). 그리고
Truck::vmass와 같이) 재정의가 가능한 인터페이스를 구현한다.
정적 다형성 클래스에서 이 두 가지 특징은 완전히 분리해야 한다. 이전 절에서 보았듯이 정적 다형성 파생 클래스는 바탕 클래스로부터 상속을 받는다. 자신의 클래스 유형을 바탕 클래스의 유형 매개변수에 인자로 사용하여 상속을 받는다. 이것은 한 단계의 상속일 때만 잘 작동한다 (즉, 바탕 클래스가 하나이고 그 바탕 클래스로부터 하나 이상의 클래스가 직접적으로 파생될 경우에만 잘 작동한다).
여러 단계의 상속이라면 (예를 들어 Truck -> Car -> Vehicle) Truck의 상속 지정은 문제가 된다. 다음은 정적 다형성과 여러 단계의 상속을 사용하려는 최초의 시도이다.
template <class Derived>
class Vehicle
{
public:
void mass()
{
static_cast<Derived *>(this)->vmass();
}
};
class Car: public Vehicle<Car>
{
friend void Vehicle<Car>::mass();
void vmass();
};
class Truck: public Car
{
void vmass();
};
Truck을 Car로부터 상속받으면 Truck은 묵시적으로 Vehicle<Car>로부터 파생된다. Car가 Vehicle<Car>로부터 파생되기 때문이다. 결론적으로 Truck{}.mass()를 호출할 때 Truck::vmass가 활성화되는 것이 아니라 Car의 vmass 함수가 활성화된다. 그러나 Truck은 반드시 Car으로부터 상속을 받아야 Car 보호 특징들을 사용할 수 있고 Car의 공개 특징들을 자신의 공개 인터페이스에 추가할수 있다.
Truck을 Vehicle<Truck>과 Car으로부터 상속을 받으면 결과로 나온 Truck 클래스도 역시 (Truck의 Car 바탕 클래스를 통하여) Vehicle<Car>으로부터 상속을 받는다. 때문에 컴파일에 실패한다. Vehicle::mass를 구체화할 때 컴파일러가 모호성을 만나기 때문이다. Class::vmass를 호출해야 하는가 아니면 Truck::vmass를 호출해야 하는가?
Truck{}.mass()가 Truck::vmass를 호출하도록 하기 위해) 재정의가 가능한 인터페이스를 상속이 가능한 인터페이스와 분리해야 한다.
파생 클래스에서 바탕 클래스의 보호 인터페이스와 공개 인터페이스는 표준 상속으로 사용할 수 있다. 이를 그림 27의 왼편에 보여준다.
다음 레벨의 속성에 대하여 왼쪽 클래스가 바탕 클래스로 사용된다 (TruckBase는 제외한다. 그러나 또다른 레벨의 클래스 상속에 대하여 TruckBase를 바탕 클래스로 사용할 수 있다.). 이 상속 계통을 따라 클래스의 상속 인터페이스를 선언한다.
왼쪽의 클래스 각각은 오른쪽 클래스의 바탕 클래스이다. VehicleBase는 Vehicle에 대하여 바탕 클래스이고 TruckBase는 Truck에 대하여 바탕 클래스이다. 왼쪽 클래스의 멤버들은 정적 다형성의 실현과 전혀 무관하게 완전히 독립적이다. 그것은 정적 다형성을 여러 레벨로 실현하기 위한 설계 원칙일 뿐이므로 보통의 데이터 은닉 원칙은 느슨하게 적용했다. 그리고 왼쪽 클래스는 오른쪽 짝이 되는 파생 클래스 템플릿을 친구로 선언하기 때문에 오른쪽에 짝이 되는 파생 클래스 템플릿으로부터 왼쪽 클래스의 비밀 멤버는 물론이고 모든 멤버에 완전히 접근할 수 있다. 예를 들어 VehicleBase는 Vechicle를 친구로 선언한다.
class VehicleBase
{
template <class Derived>
friend class Vehicle;
// 원래 Vehicle에 있지만 정적 다형성의 실현에 관련이 없는
// 모든 멤버는 여기에 선언된다. 예를 들어,
size_t d_massFactor = 1;
};
오른쪽 최상위 레벨의 클래스는 (VehicleBase) 정적으로 재정의 함수를 사용하는 인터페이스의 일부를 정의함으로써 정적 다형성의 토대를 놓는다. 예를 들어 흥미롭게도 재귀적인 템플릿 패턴을 사용하여 mass 클래스 멤버를 정의한다. 이 멤버는 파생 클래스의 vmass 함수를 호출한다 (게다가 비-클래스 템플릿 바탕 클래스의 모든 멤버를 사용할 수 있다.). 예를 들어:
template <class Derived>
class Vehicle: public VehicleBase
{
public:
int mass() const
{
return d_massFactor *
static_cast<Derived const *>(this)->vmass();
}
};
vmass를 호출할 때 어느 함수가 호출될지는 Derived의 구현에 따라 달라진다. 호출은 아래 Vehicle에 보여주듯이 (자신의 ...Base 클래스는 물론이고) 이로부터 파생된 나머지 모든 클래스에 의하여 처리된다. 이 클래스들은 흥미로운 재귀 템플릿 패턴을 사용한다. 예를 들어,
class Car: public CarBase, public Vehicle<Car>
그래서 Car가 이제 자신만의 vmass 함수를 구현하면 자신의 모든 멤버를 (즉, CarBase 멤버를) 사용할 수 있다. 그러므로 Vehicle의 mass 함수를 호출하면 vmass 함수가 호출된다. 예를 들어,
template <class Vehicle>
void fun(Vehicle &vehicle)
{
cout << vehicle.mass() << '\n';
}
int main()
{
Car car;
fun(car); // Car의 vmass가 호출된다.
Truck truck;
fun(truck); // Truck의 vmass가 호출된다.
}
이제 다중 레벨의 상속을 사용하여 정적 다형성 클래스의 디자인을 분석했으므로 정적 다형성을 구현하는 절차를 요약해 보자.
Vehicle 바탕 클래스에서 시작한다. Vehicle에서 재정의가 불가능한 인터페이스는 VehicleBase 클래스로 이동시키고 Vehicle 자체는 정적 다형성 바탕 클래스로 탈바꿈시킨다. 일반적으로 원래의 다형성 바탕 클래스에서 가상 멤버를 사용하지 않는 또는 구현하지 않는 멤버는 모두 XBase 클래스로 이동시켜야 한다.
VehicleBase는 Vehicle를 friend로 선언한다. 이제 Vehicle은 VehicleBase에 있는 멤버 함수에 완전히 접근할 수 있다.
Vehicle의 멤버는 재정의 인터페이스를 참조한다. 즉, 그의 멤버들은 Derived 템플릿 유형 매개변수의 멤버들을 호출한다. 이 구현에서 Vehicle은 자신의 vmass 멤버를 구현하지 않는다. Vehicle<Vehicle>를 정의할 수 없다. 그리고 정적 다형성으로 바탕 클래스는 본질적으로 추상 바탕 클래스나 다름없다. 이것이 불편하다면 Vehicle의 Derived 클래스에 대하여 바탕 클래스를 지정할 수 있다. 원래 다형성 바탕 클래스의 재정의 인터페이스를 구현한다 (Vehicle<> vehicle와 같이 정의할 수 있게 된다).
Car 클래스는 CarBase로 이동시키고 Truck은 TruckBase로 이동시킨다.
VehicleBase로부터 CarBase까지 그리고 거기부터 TruckBase까지 사용한다.
Car와 Truck) 클래스는 바탕 클래스로부터 상속받는 클래스 템플릿이다. 또한 흥미롭게도 재귀 템플릿 패턴을 사용하여 Vehicle로부터도 상속받는다.
Vehicle의 멤버들이 사용한다.
이 디자인 패턴을 레벨에 상관없이 얼마든지 상속에 확장할 수 있다. 새 레벨마다 바탕 클래스가 생성되고 지금까지 가장 깊이 내포된 XXXBase 클래스로부터 상속을 받고 그리고 Vehicle<XXX>로 부터 상속을 받는다. 그리고 재정의 인터페이스에 관하여 자신만의 아이디어를 구현한다.
정적 다형성 클래스와 함게 조합하여 사용되는 함수들은 그 자체로 함수 템플릿이다. 예를 들어,
template <class Vehicle>
void fun(Vehicle &vehicle)
{
cout << vehicle.mass() << '\n';
}
여기에서 Vehicle은 그저 형식적 이름이다. 객체를 fun에 건넬 때 mass 멤버를 제공해야 한다. 그렇지 않으면 컴파일 에러가 일어날 것이다. 객체가 실제로 Car이거나 Truck이면 Vehicle<Type> 정적 바탕 클래스의 mass 멤버가 호출된다. 이번에는 차례로 정적 다형성을 사용하여 vmass 멤버를 호출한다. 이 멤버는 실제로 건넨 클래스 유형에 의하여 구현된다. 다음 main 함수는 각각 1000과 15000을 화면에 보여준다.
int main()
{
Car car;
fun(car);
Truck truck;
fun(truck);
}
이 프로그램은 fun을 두 번 구현한다는 것에 주목하라. 동적 다형성의 경우라면 한 번이다. Vehicle 클래스 템플릿에도 같은 규칙이 적용된다. 두 번 구현되는데, 한 번은 Car 유형에 또 한번은 Truck 유형에 대하여 구현된다. 그렇지만 정적 다형성을 사용하는 프로그램이 조금 더 빠를 것이다.
(컴파일해 볼 수 있는 정적 다형성을 사용하는 예제는 소스 디렉토리 yo/classtemplates/examples/staticpolymorphism/polymorph.cc 파일에 있다.)
(제 14장의 Vehicle 클래스처럼) 다형적 바탕 클래스 유형을 가리키는 포인터를 담고 있는 컨테이너가 클래스에 들어 있다고 생각해 보자. 그런 컨테이너를 어떻게 또다른 컨테이너로 복사할까? 여기에서 공유 포인터를 사용하자고 제시하지 않겠다. 오히려 완전히 사본을 만들고 싶다. 확실히, 포인터들이 가리키는 객체들을 복제할 필요가 있을 것이다. 그리고 이 새 포인터들을 그 복사된 객체의 컨테이너에 할당할 필요가 있을 것이다.
원형(프로토타입) 디자인 패턴은 바탕 클래스를 가리키는 포인터가 주어져 있다면 다형적 클래스의 객체의 사본을 만드는 데 사용된다.
원형 디자인 패턴을 적용하려면 newCopy를 모든 파생 클래스에 구현할 필요가 있다. 구현 그 자체는 어렵지 않다. 그러나 정적 다형성을 여기에 사용하면 이 함수를 파생 클래스마다 구현해야 하는 수고를 멋지게 피할 수 있다.
추상 VehicleBase 바탕 클래스로 시작하자. 순수하게 newCopy 가상 멤버를 선언한다.
struct VehicleBase
{
virtual ~VehicleBase();
VehicleBase *clone() const; // newCopy를 호출
// 공개 사용자 인터페이스를 정의하는
// 추가 멤버들은 여기에 선언한다.
private:
VehicleBase *newCopy() const = 0;
};
다음으로 정적 다형성 CloningVehicle 클래스를 정의한다. 이 클래스는 VehicleBase로부터 파생된다 (그리하여 정적 다형성과 동적 다형성을 조합해 사용하고 있음을 주목하라). 이 클래스는 newCopy의 총칭 구현이다. 이것이 가능한 이유는 파생된 모든 클래스가 이 구현을 사용하기 때문이다. 또한, CloningVehicle은 결국 사용될 구체적인 운송수단의 유형마다 즉, Car, Truck, AmphibiousVehicle, 등등마다 재구현될 것이다. 그래서 CloningVehicle은 공유되지 않지만 (VehicleBase처럼) 새 유형의 운송수단마다 구체화된다.
정적 다형성 클래스의 핵심적인 특징은 자신의 클래스 템플릿 유형 매개변수를 자신만의 유형으로 static_cast를 통하여 사용할 수 있다는 것이다. newCopy와 같은 함수는 언제나 같은 방식으로 구현된다. 즉, 파생 클래스의 복사 생성자를 사용하여 구현된다. 다음은 CloningVehicle 클래스이다.
template <class Derived>
class CloningVehicle: public VehicleBase
{
VehicleBase *newCopy() const
{
return new Derived(*static_cast<Derived const *>(this));
}
};
이제 완성이다. 운송 수단의 모든 유형은 이제 CloningVehicle으로부터 파생된다. newCopy를 따로따로 자동으로 구현한다. 예를 들어 Car 클래스는 모습이 다음과 같다.
class Car: public CloningVehicle<Car>
{
// 차의 인터페이스,
// newCopy를 선언할 필요도 구현할 필요도 없다,
// 그러나 복사 생성자는 필요하다.
};
std::vector<VehicleBase *> original를 정의하였으므로 다음과 같이 original의 사본을 만들 수 있다.
for(auto pointer: original)
duplicate.push_back(pointer->clone());
포인터가 가리키는 운송 수단의 실제 유형에 관계 없이 clone 멤버는 새로 할당된 사본을 돌려줄 것이다. 해당 사본마다 자신의 유형이 있다.
PtrVector 클래스 안에 iterator 클래스가 정의되어 있다. 내포된 클래스는 내포하는 PtrVector<Type> 클래스로부터 정보를 얻는다. 이 내포하는 클래스는 반복자를 생성하는 유일한 클래스가 되어야 하기 때문에 iterator의 생성자는 비밀로 만들고 묶인 친구(bound friend) 선언을 사용하여 내포하는 클래스에 접근 권한을 준다. 다음은 PtrVector 클래스 인터페이스의 앞부분이다.
template <typename Type>
class PtrVector: public std::vector<Type *>
이를 보면 std::vector 바탕 클래스는 값 자체가 아니라 Type 값을 포인터로 저장한다. 물론 이제 소멸자가 필요하다. Type 객체에 대하여 (외부적으로 할당된) 메모리를 결국 해제해야 하기 때문이다. 대안으로, 할당 작업은 PtrVector가 원소를 새로 저장할 때 맡을 수도 있다. 다음은 PtrVector의 클라이언트가 필요한 할당을 처리하고 소멸자가 나중에 구현된다고 가정한다.
내포된 클래스는 자신의 생성자를 비밀 멤버로 정의하고 PtrVector<Type> 객체가 그의 비밀 멤버에 접근한다. 그러므로 내포하는 PtrVector<Type> 클래스 유형의 객체만 iterator 객체를 생성하도록 허용된다. 그렇지만 PtrVector<Type>의 클라이언트는 PtrVector<Type>::iterator 객체의 사본을 생성할 수도 있다.
다음은 iterator 내포 클래스이다. (요구된) friend 선언을 사용한다. typename 키워드의 사용에 주목하라: std::vector<Type *>::iterator는 템플릿 매개변수에 의존하기 때문에 아직 구체화된 클래스가 아니다. 그러므로 iterator는 묵시적인 typename이 된다. 컴파일러는 typename을 생략하면 경고를 보여준다. 다음은 클래스 인터페이스이다.
class iterator
{
friend class PtrVector<Type>;
typename std::vector<Type *>::iterator d_begin;
iterator(PtrVector<Type> &vector);
public:
Type &operator*();
};
멤버의 구현을 보면 바탕 클래스의 begin 멤버가 호출되어 d_begin을 초기화한다. PtrVector<Type>::begin의 반환 유형도 역시 앞에 typename 키워드가 와야 한다.
template <typename Type>
PtrVector<Type>::iterator::iterator(PtrVector<Type> &vector)
:
d_begin(vector.std::vector<Type *>::begin())
{}
template <typename Type>
Type &PtrVector<Type>::iterator::operator*()
{
return **d_begin;
}
나머지는 간단하다. 다른 모든 함수를 구현하지 않고 생략해도 begin 함수는 새로 생성된 PtrVector<Type>::iterator 객체를 돌려준다. iterator 클래스가 그를 둘러싼 클래스를 친구로 선언했기 때문에 그 생성자를 호출해도 된다.
template <typename Type>
typename PtrVector<Type>::iterator PtrVector<Type>::begin()
{
return iterator(*this);
}
다음은 간단한 뼈대 프로그램이다. iterator 내포 클래스를 어떻게 사용할 수 있는지 보여준다.
int main()
{
PtrVector<int> vi;
vi.push_back(new int(1234));
PtrVector<int>::iterator begin = vi.begin();
std::cout << *begin << '\n';
}
내포된 열거체와 내포된 typedef도 역시 클래스 템플릿에서 정의할 수 있다. 앞서 언급한 Table은 TableType::FillDirection 열거체를 상속받았다 (22.11.3항). Table을 완벽한 클래스 템플릿으로 구현했다면 이 열거체는 Table 자체에 다음과 같이 정의되었을 것이다.
template <typename Iterator>
class Table: public TableType
{
public:
enum FillDirection
{
HORIZONTAL,
VERTICAL
};
...
};
이 경우, FillDirection 값이나 그의 유형을 참조할 때 템플릿 유형 매개변수의 실제 값을 지정해야 한다. 예를 들어 (iter와 nCols는 22.11.3항과 같이 정의되어 있다고 간주한다):
Table<istream_iterator<string> >::FillDirection direction =
argc == 2 ?
Table<istream_iterator<string> >::VERTICAL
:
Table<istream_iterator<string> >::HORIZONTAL;
Table<istream_iterator<string> >
table(iter, istream_iterator<string>(), nCols, direction);
특정 유형이 반복자로 번역되도록 클래스의 객체가 확인하려면 클래스는 std::iterator으로부터 상속을 받아야 한다. 상속을 받으려면 먼저 <iterator> 헤더를 포함해야 한다.
18.2절에서 반복자의 특징을 연구했다. (설계된 반복자 클래스와 Type의 총칭 이름으로 Iterator를 사용하여 Iterator 객체가 참조하는 데이터 유형을 나타내려면 (const라면 관련 연산자 역시 const 멤버가 되어야 한다))
모든 반복자는 다음을 지원해야 한다.
Iterator &operator++());
Type &operator*());
Type *operator->());
bool operator==(Iterator const &other), bool operator!=(Iterator const &other)).
반복자를 총칭 알고리즘의 문맥에 사용하려면 충족해야 할 요구 조건이 더 있다. 이것은 총칭 알고리즘이 반복자의 유형에 대하여 점검을 수행하기 때문이다. 간단한 포인터는 대부분 받아 들이지만 만약 반복자-객체가 사용되면 그가 나타내는 반복자의 종류를 명시할 수 있어야 한다.
클래스를 iterator로부터 상속받을 때 그 반복자의 유형은 클래스 템플릿의 첫 번째 매개변수에 의하여 정의된다. 그리고 그 반복자가 참조하는 데이터 유형은 클래스 템플릿의 두 번째 매개변수에 의하여 정의된다.
파생 클래스로 구현된 반복자 유형은 이른바 iterator_tag를 사용하여 지정된다. iterator 클래스의 첫 번째 템플릿 인자로 제공된다. 다섯 가지 기본 반복자 유형에 대하여 태그는 다음과 같다.
std::input_iterator_tag.InputIterator 역참조 연산자는 다음과 같이 선언해야 한다.
Type const &operator*() const;
표준 연산자를 제외하면 InputIterator에 대하여 더 이상의 요구 조건은 없다.
std::output_iterator_tag.OutputIterator 역참조 연산자는 그의 역참조 연산자가 참조하는 데이터에 대하여 할당을 허용해야 한다. 그러므로 OutputIterator 역참조 연산자는 다음과 같이 선언할 수 있다.
Type &operator*();
표준 연산자를 제외하면 OutputIterator에 대하여 더 이상의 요구 조건은 없다.
std::forward_iterator_tag.ForwardIterator 역참조 연산자는 그의 역참조 연산자가 참조하는 데이터에 대하여 할당을 허용해야 한다. 그러므로 ForwardIterator 역참조 연산자는 다음과 같이 선언할 수 있다.
Type &operator*();
표준 연산자를 제외하면 ForwardIterator에 대하여 더 이상의 요구 조건은 없다.
std::bidirectional_iterator_tag.양방향 역참조 연산자는 그의 역참조 연산자가 참조하는 데이터에 할당을 허용해야 한다. 그리고 거꾸로 이동하는 것도 허용해야 한다. 그러므로 BidirectionalIterator는 표준 연산자 외에도 다음 연산자를 제공해야 한다.
Type &operator*();
Iterator &operator--();
std::random_access_iterator_tag.RandomIterator 클래스 역참조 연산자는 그가 참조하는 데이터에 할당을 허용해야 한다. 게다가 표준 연산자 말고도 다음 연산자를 제공해야 한다.
Type &operator*()
역참조 연산자가 참조하는 데이터에 할당을 허용한다.
Iterator &operator--() 하나씩 역방향으로 이동을 허용한다.
Type operator-(Iterator const &rhs) const 현재 반복자와rhs반복 사이의 원소의 갯수를 돌려준다 (rhs가 참조하는 원소가this반복자가 참조하는 원소를 넘어서면 음의 값을 돌려준다);
Iterator operator+(int step) const this반복자가 참조하는 데이터 원소를 넘어서step개의 데이터 원소 다음의 데이터 원소를 참조하는 반복자를 돌려준다.
Iterator operator-(int step) const this반복자가 참조하는 데이터 원소 이전에step개의 데이터 원소를 뛴 다음의 데이터 원소를 가리키는 반복자를 돌려준다.
bool operator<(Iterator const &rhs) const this반복자가 참조하는 원소가rhs반복자가 참조하는 원소 앞에 위치하면true를 돌려준다.
반복자는 언제나 일정 범위에 대하여 정의된다 ([begin, end)). 결과 반복자 값이 이 범위를 벗어난 위치를 참조하게 되면 증감 연산은 미정의 행위를 야기할 수 있다.
보통, 반복자는 일정 범위의 원소에 접근만 할 뿐이다. 내부적으로 반복자는 보통의 포인터를 사용할 수도 있지만 반복자가 메모리를 할당하는 일은 거의 없다. 그러므로 할당 연산자와 복사 생성자는 메모리를 할당할 필요가 없기 때문에 기본 구현만으로도 충분하다. 같은 이유로 반복자는 소멸자를 요구하지 않는다.
반복자를 돌려주는 멤버를 제공하는 대부분의 클래스는 필요한 반복자를 자신의 멤버가 생성해서 객체로 반환하도록 만든다. 이 멤버 함수의 호출자는 그냥 반환된 반복 객체를 사용하거나 아니면 복사하기만 하면 될 뿐이므로 복사 생성자를 제외하고 공개적으로 생성자를 제공할 필요가 없다. 그러므로 이런 생성자들은 비밀 또는 보호 멤버로 정의된다. 둘레 클래스에서 반복자 객체를 만들도록 허용하기 위해 반복자 클래스는 둘레 클래스를 친구로 선언한다.
다음 절에서 RandomAccessIterator의 생성과 매우 복잡한 모든 반복자의 생성 그리고 역방향 RandomAccessIterator를 연구한다. 무작위 접근 반복자에 대한 컨테이너 클래스는 실제로는 데이터 멤버를 다양한 방식으로 저장할 수 있다 (예를 들어 컨테이너 또는 포인터의 포인터를 사용한다). 그러므로 광범위한 유형의 컨테이너 클래스에 딱 맞는 템플릿 반복자 클래스를 생성하기가 무척 까다롭다.
다음 절에서 std::iterator 클래스를 사용하여 무작위 접근 반복자를 나타내는 내부 클래스를 생성한다. 다른 문맥에 대하여 반복자 클래스를 생성하려면 독자 여러분은 거기에 예시된 접근법을 따를 수 있다. 그런 템플릿 반복자 클래스의 예는 24.7절에 보여준다.
다음 절은 원소에 포인터를 통해서만 접근할 수 있는 무작위 반복자를 개발한다. 반복자 클래스는 문자열 포인터의 벡터로부터 상속받은 클래스의 내부 클래스로 설계되었다.
unique_ptr과 shared_ptr 유형의 객체를 사용할 수는 있다). 권하는 것은 아니지만 특정한 문맥에서는 포인터 데이터 유형을 사용할 수 있다. 다음 StringPtr 클래스에서 평범한 클래스를 std::vector 컨테이너로부터 파생시킨다. std::string *를 데이터 유형으로 사용한다.
#ifndef INCLUDED_STRINGPTR_H_
#define INCLUDED_STRINGPTR_H_
#include <string>
#include <vector>
class StringPtr: public std::vector<std::string *>
{
public:
StringPtr(StringPtr const &other);
~StringPtr();
StringPtr &operator=(StringPtr const &other);
};
#endif
이 클래스는 소멸자가 필요하다. 객체에 문자열 포인터가 저장되어 있으므로 StringPtr 객체가 파괴될 때 그 문자열을 파괴하기 위해 소멸자가 필요하다. 비슷하게, 복사 생성자와 중복정의 할당이 요구된다. 다른 멤버들은 (특히 생성자들은) 이 절의 주제에 적절하지 않기 때문에 명시적으로 여기에 선언하지 않는다.
sort 총칭 알고리즘을 StringPtr 객체에 사용하고 싶다고 가정해 보자. 이 알고리즘은 두 개의 RandomAccessIterator를 요구한다 (19.1.58항 ). (std::vector의 begin과 end 멤버를 통하여) 이런 반복자를 사용할 수는 있지만 반복자를 std::string *에 돌려줄 것이고 이것은 합리적으로 비교할 수가 없다.
이를 치료하기 위하여 내부 StringPtr::iterator 유형을 정의할 수 있다. 반복자를 포인터가 아니라 이 포인터들이 가리키는 객체들에게 돌려준다. 이런 iterator 유형을 사용할 수 있으면 다음 멤버를 StringPtr 클래스 인터페이스에 추가할 수 있다. 바탕 클래스에서 이름이 동일하지만 쓸모 없는 멤버를 가릴 수 있다.
StringPtr::iterator begin(); // 첫 번째 원소를 가리키는 반복자를 돌려준다.
StringPtr::iterator end(); // 마지막 원소를 가리키는 반복자를
// 돌려준다.
이 두 멤버는 (적절한) 반복자를 돌려주기 때문에 StringPtr 객체 안의 원소들을 쉽게 정렬할 수 있다.
int main()
{
StringPtr sp; // sp가 채워져 있다고 간주한다.
sort(sp.begin(), sp.end()); // sp는 정렬되었다.
}
이 모든 것을 작동시키기 위해 StringPtr::iterator 유형을 정의해야 한다. 그 이름이 암시하듯이 iterator는 StringPtr에 내포된 유형이다. StringPtr::iterator를 sort 총칭 알고리즘과 함께 사용하려면 RandomAccessIterator이어야 한다. 그러므로 StringPtr::iterator 자체는 기존의 std::iterator 클래스로부터 상속받아야 한다.
클래스를 std::iterator으로부터 상속받으려면 반복자가 가리키는 반복자 유형과 데이터 유형을 모두 지정해야 한다. 약점이 있다. 우리의 반복자는 string * 역참조를 책임진다. 그래서 요구된 데이터 유형은 std::string이지 std::string *이 아니다. 그러므로 iterator 클래스는 다음과 같이 인터페이스를 시작한다.
class iterator:
public std::iterator<std::random_access_iterator_tag, std::string>
바탕 클래스 지정이 상당히 복잡하기 때문에 이 유형을 더 짧은 이름에 연관짓는 것을 고려해 볼 수 있다. 다음 typedef를 사용하면 된다.
typedef std::iterator<std::random_access_iterator_tag, std::string>
Iterator;
실용적인 측면에서 유형을 (Iterator) 한 번 또는 두 번만 사용한다면 이런 유형 정의는 인터페이스를 지저분하게 할 뿐 차라리 사용하지 않는 게 좋다.
이제 StringPtr 클래스의 인터페이스를 재설계할 준비가 되었다. (역방향) 반복자를 돌려주는 멤버와 내포된 iterator 클래스를 제공한다. 다음은 그 인터페이스이다.
class StringPtr: public std::vector<std::string *>
{
public:
class iterator: public
std::iterator<std::random_access_iterator_tag, std::string>
{
friend class StringPtr;
std::vector<std::string *>::iterator d_current;
iterator(std::vector<std::string *>::iterator const ¤t);
public:
iterator &operator--();
iterator operator--(int);
iterator &operator++();
iterator operator++(int);
bool operator==(iterator const &other) const;
bool operator!=(iterator const &other) const;
int operator-(iterator const &rhs) const;
std::string &operator*() const;
bool operator<(iterator const &other) const;
iterator operator+(int step) const;
iterator operator-(int step) const;
iterator &operator+=(int step); // increment over `n' steps
iterator &operator-=(int step); // decrement over `n' steps
std::string *operator->() const;// access the fields of the
// struct an iterator points
// to. E.g., it->length()
};
typedef std::reverse_iterator<iterator> reverse_iterator;
iterator begin();
iterator end();
reverse_iterator rbegin();
reverse_iterator rend();
};
예와 같이 이 인터페이스는 클래스를 더욱 깊이 연구하기 위한 실마리가 된다.
먼저 StringPtr::iterator의 특징을 살펴보자:
iterator는 StringPtr을 친구로 정의한다. 그래서 iterator의 생성자는 여전히 비밀로 남을 수 있다. 이제 StringPtr 클래스 자체만 iterator를 생성할 수 있다. 이것이 합리적으로 보인다. 물론 현재 구현 아래에서 복사-생성도 역시 가능해야 한다. 게다가 반복자는 이미 StringPtr의 바탕 클래스가 제공하고 있기 때문에 그 반복자를 사용하여 StringPtr 객체에 저장된 정보에 접근할 수 있다.
StringPtr::begin과 StringPtr::end은 그냥 iterator 객체를 돌려준다. 다음과 같이 구현되어 있다.
inline StringPtr::iterator StringPtr::begin()
{
return iterator(this->std::vector<std::string *>::begin());
}
inline StringPtr::iterator StringPtr::end()
{
return iterator(this->std::vector<std::string *>::end());
}
iterator의 나머지 모든 멤버는 공개된다. 구현하는 것은 아주 쉽다. 주로 반복자 d_current를 조작하고 역참조하는 일만 처리하면 된다. (가장 복잡한) RandomAccessIterator는 일련의 연산자를 요구한다. 구현이 아주 간단하다. 덕분에 인라인-멤버의 훌륭한 후보가 된다.
iterator &operator++(); 전위-증가 연산자:
inline StringPtr::iterator &StringPtr::iterator::operator++()
{
++d_current;
return *this;
}
iterator operator++(int); 후위-증가 연산자:
inline StringPtr::iterator StringPtr::iterator::operator++(int)
{
return iterator(d_current++);
}
iterator &operator--(); 전위-감소 연산자:
inline StringPtr::iterator &StringPtr::iterator::operator--()
{
--d_current;
return *this;
}
iterator operator--(int); 후위-감소 연산자:
inline StringPtr::iterator StringPtr::iterator::operator--(int)
{
return iterator(d_current--);
}
iterator &operator=(iterator const &other); 중복정의 할당 연산자. iterator 객체는 메모리를 전혀 할당하지 않기 때문에 기본 할당 연산자를 사용할 수 있다.
bool operator==(iterator const &rhv) const; 두 iterator 객체가 같은지 검증한다.
inline bool StringPtr::iterator::operator==(iterator const &other) const
{
return d_current == other.d_current;
}
bool operator<(iterator const &rhv) const; 왼쪽 반복자가 오른쪽 반복자가 가리키는 원소 앞에 위치한 일련의 원소를 가리키는지 검증한다.
inline bool StringPtr::iterator::operator<(iterator const &other) const
{
return d_current < other.d_current;
}
int operator-(iterator const &rhv) const; 왼쪽 반복자가 가리키는 원소와 오른쪽 반복자가 가리키는 원소 사이의 원소의 갯수를 돌려준다 (즉, 오른쪽 반복자의 값과 같게 하기 위해 왼쪽 반복자에 더해야 할 값):
inline int StringPtr::iterator::operator-(iterator const &rhs) const
{
return d_current - rhs.d_current;
}
Type &operator*() const; 현재 반복자가 가리키는 객체를 참조로 돌려준다. InputIterator와 모든 const_iterator에서 이 중복정의 연산자의 반환 유형은 반드시 Type const &가 되어야 한다. 이 연산자는 문자열를 참조로 돌려준다. 이 문자열은 d_current 값을 역참조하면 얻을 수 있다. d_current는 string * 원소를 가리키는 반복자이므로 두 개의 역참조 연산자가 있어야 문자열에 접근할 수 있다.
inline std::string &StringPtr::iterator::operator*() const
{
return **d_current;
}
iterator operator+(int stepsize) const; 이 연산자는 현재 반복자를 stepsize만큼 전진 시킨다.
inline StringPtr::iterator StringPtr::iterator::operator+(int step) const
{
return iterator(d_current + step);
}
iterator operator-(int stepsize) const; 이 연산자는 현재 반복자를 stepsize만큼 감소 시킨다.
inline StringPtr::iterator StringPtr::iterator::operator-(int step) const
{
return iterator(d_current - step);
}
iterator(iterator const &other); 반복자는 기본의 반복자로부터 생성할 수 있다. 이 생성자는 구현할 필요가 없다. 기본 복사 생성자를 사용할 수 있기 때문이다.
std::string *operator->() const는 추가된 연산자이다. 여기에서는 역참조 연산만 요구된다. 문자열을 포인터로 돌려준다. 이 포인터를 통하여 문자열에 접근할 수 있다.
inline std::string *StringPtr::iterator::operator->() const
{
return *d_current;
}
operator+=와 operator-=이다. 공식적으로 RandomAccessIterator가 요구하는 것은 아니다. 그러나 어쨌든 편리하다.
inline StringPtr::iterator &StringPtr::iterator::operator+=(int step)
{
d_current += step;
return *this;
}
inline StringPtr::iterator &StringPtr::iterator::operator-=(int step)
{
d_current -= step;
return *this;
}
operator+(int step)는 인터페이스에서 뺄 수 있다. 그러면 물론 사용할 꼬리표는 std::forward_iterator_tag가 될 것이다. 꼬리표는 (그리고 요구된 연산자 집합은) 반복자 유형에 따라 달라진다.
std::iterator에 비교하여 std::reverse_iterator가 존재한다. 반복자 클래스를 구현했다면 역방향 반복자를 멋지게 구현해 준다. 생성자는 역방향 반복자를 생성하고자 하는 반복자 유형의 객체를 하나 요구할 뿐이다.
StringPtr에 대하여 역방향 반복자를 구현하려면 인터페이스에 reverse_iterator 유형을 정의하기만 하면 된다. 한 줄의 코드만 지정하면 그 뿐이다. iterator 클래스 인터페이스 다음에 삽입한다.
typedef std::reverse_iterator<iterator> reverse_iterator;
또한, 유명한 rbegin 멤버와 rend 멤버도 StringPtr의 인터페이스에 추가한다. 역시 인라인으로 쉽게 구현할 수 있다.
inline StringPtr::reverse_iterator StringPtr::rbegin()
{
return reverse_iterator(end());
}
inline StringPtr::reverse_iterator StringPtr::rend()
{
return reverse_iterator(begin());
}
reverse_iterator 생성자가 받는 인자에 주목하라: 역방향 반복자의 시작 지점은 reverse_iterator의 생성자에 end 멤버가 반환한 값을 제공하여 얻는다. 정방향 반복자 범위의 끝 지점이 그것이다. 역방향 반복자의 끝 지점은 reverse_iterator의 생성자에 begin 멤버가 반환한 값을 제공하여 얻는다. 정방향 반복자 범위의 시작 지점이 그것이다.
다음의 작은 프로그램은 StringPtr의 RandomAccessIterator를 사용하는 방법을 보여준다.
#include <iostream>
#include <algorithm>
#include "stringptr.h"
using namespace std;
int main(int argc, char **argv)
{
StringPtr sp;
while (*argv)
sp.push_back(new string(*argv++));
sort(sp.begin(), sp.end());
copy(sp.begin(), sp.end(), ostream_iterator<string>(cout, " "));
cout << "\n======\n";
sort(sp.rbegin(), sp.rend());
copy(sp.begin(), sp.end(), ostream_iterator<string>(cout, " "));
cout << '\n';
}
/*
다음과 같이 호출하면:
a.out bravo mike charlie zulu quebec
다음과 같이 출력된다.
a.out bravo charlie mike quebec zulu
======
zulu quebec mike charlie bravo a.out
*/
정방향 반복자로부터 역방향 방복자를 생성하는 것은 가능하지만 그 반대는 불가능하다. 역방향 반복자로부터 정방향 반복자를 초기화하는 것은 불가능하다.
빈 줄이 나타날 때까지 vector<string> lines에 저장된 줄을 모두 처리하고 싶다고 가정하자. 어떻게 처리해야 할까? 한 가지 접근법은 벡터 안의 첫 줄부터 처리를 시작하는 것이다. 계속해서 빈 줄을 처음으로 만날 때까지 처리한다. 그렇지만 첫 번째 빈 줄을 만나더라도 다음에 꼭 빈 줄이 이어져야 할 필요는 없다. 이 경우 다음 알고리즘을 사용하는 게 더 좋다.
reverse_iterator rit를 얻는다.
rit = find_if(lines.rbegin(), lines.rend(), NonEmpty());
for_each(lines.begin(), --rit, Process());
reverse_iterator를 사용하여 두 번째 반복자를 초기화할 수 있을까? 해결책은 별로 어렵지 않다. 반복자는 포인터로부터 초기화할 수 있기 때문이다. 역방향 반복자 rit는 포인터가 아니지만 &*(rit - 1) 또는 &*--rit는 포인터이다. 그래서 다음을 사용하면 이끌리는 빈 줄들의 첫 번째 줄까지 모든 줄을 처리할 수 있다.
for_each(lines.begin(), &*--rit, Process());
일반적으로 rit가 어떤 원소를 가리키는 reverse_iterator라면 그리고 그 원소를 가리킬 iterator가 필요하다면 &*rit를 사용하여 그 반복자를 초기화할 수 있다. 여기에서 역참조 연산자를 적용하면 역방향 반복자가 참조하는 원소에 도달할 수 있다. 다음으로 주소 연산자를 적용하여 그의 주소를 얻는다. 그 주소로 반복자를 초기화할 수 있다.
const_reverse_iterator를 정의할 때 (예를 들어 const_iterator 클래스에 부합하면) const_iterator's operator* 멤버는 변경이 불가능한 값이나 객체를 돌려주는 멤버가 되어야 한다. const_reverse_iterator는 반복자의 operator-- 멤버를 사용하기 때문에 작은 개념적 충돌에 반하여 실행하는 셈이다. 반면에 std::input_iterator_tag는 부적절하다. 반복자가 감소하도록 허용해야 하기 때문이다. 또 한편으로 std::bidirectional_iterator도 부적절하다. 데이터의 변경을 허용하지 않기 때문이다.
반복자 태그는 주로 개념적이다. const_iterator와 const_reverse_iterator가 증가 연산만 허용한다면 input_iterator_tag는 그 반복자의 사용 의도에 아주 밀접하게 부합한다. 그러므로 아래에 이 태그를 사용한다.
게다가 input_iterator_tag의 본성상 우리의 const_iterator는 operator--를 제공하면 안 된다. 물론 이 때문에 문제가 생긴다. 역방향 반복자는 operator-- 멤버를 사용할 수 있어야 한다. 이 문제는 쉽게 해결할 수 있다. 반복자의 operator--를 비밀 구역에 두고 std::reverse_iterator<(const_)iterator>를 친구로 선언하면 된다. (주목하라. std::reverse_iterator으로부터 상속받아 (const_)reverse_iterator를 선언하더라도 이 문제는 해결되지 않는다. 반복자의 operator--를 호출하는 것은 std::reverse_iterator이지 자신을 파생시킨 클래스가 아니다).
그렇지만 또다른 문제가 있다. const_iterator으로부터 const_reverse_iterator를 상속받은 후에 이어서 const_reverse_iterator를 역참조하면 컴파일러는 다음과 같은 에러 메시지를 보여준다 (Type = int 사용):
error: invalid initialization of non-const reference of type
'std::reverse_iterator<const_iterator>::reference {aka int&}' from an rvalue
of type 'int'
return *--__tmp;
이 메시지는 std::reverse_iterator 때문에 야기된다. 기본값으로 반복자의 operator*가 변경이 가능한 Type를 참조로 돌려준다고 기대하기 때문이다.
그런 기본 예상을 제어하기 위해 반복자는 typedef를 사용하여 그런 예상을 더 세밀하게 조율할 수 있다. std::reverse_iterator는 typedef를 다음과 같이 이해한다.
pointer - 데이터를 가리키는 포인터 유형
(e.g., Type *)
const_pointer - 변경 불능 데이터를 가리키는 포인터 유형
(e.g., Type const *)
reference - 데이터를 가리키는 참조 유형
(e.g., Type &)
const_reference - 변경 불능 데이터에 대한 참조 유형
(e.g., Type const &)
difference_type - 포인터 사이의 차를 나타내는 유형
(기본값 `ptrdiff_t')
위에 언급된 에러는 iterator 클래스에 `typedef int const &reference'를 선언하면 간단하게 방지할 수 있다. 대안으로, std::iterator의 바탕 클래스에 대하여 데이터 유형으로 int const를 지정할 수 있다.
Data 클래스에 대하여 iterator와 const_iterator 그리고 reverse_iterator와 const_reverse_iterator를 정의하려면 다음 작업틀을 사용하면 된다.
#include <string>
#include <iterator>
class Data
{
std::string *d_data;
size_t d_n;
public:
class iterator;
class const_iterator;
typedef std::reverse_iterator<iterator> reverse_iterator;
typedef std::reverse_iterator<const_iterator> const_reverse_iterator;
};
class Data::iterator: public std::iterator<std::input_iterator_tag,
std::string>
{
public:
iterator() = default;
iterator &operator++();
std::string &operator*();
private:
friend class Data;
iterator(std::string *data, size_t idx);
friend class std::reverse_iterator<iterator>;
iterator &operator--();
};
bool operator==(Data::iterator const &lhs, Data::iterator const &rhs);
class Data::const_iterator: public std::iterator<std::input_iterator_tag,
std::string const>
{
public:
const_iterator() = default;
const_iterator &operator++();
std::string const &operator*() const;
private:
friend class Data;
const_iterator(std::string const *data, size_t idx);
friend class std::reverse_iterator<const_iterator>;
const_iterator &operator--();
};
bool operator==(Data::const_iterator const &lhs,
Data::const_iterator const &rhs);
int main()
{
Data::iterator iter;
Data::reverse_iterator riter(iter);
*riter;
Data::const_iterator citer;
Data::const_reverse_iterator criter(citer);
*criter;
};