exit 함수를 호출하여 프로그램을 완전히 끝낸다. 문제를 해결하기에는 아주 어려운 방법이다. 지역 객체의 소멸자가 활성화되지 않기 때문이다.
setjmp와 longjmp를 사용하여 영역을 벗어나도록 강제할 수 있다. 이 메커니즘은 일종의 goto 건너뛰기를 구현한다. 그러면 내포된 함수들로부터 일련의 return을 사용했다면 방문했어야 할 중간 수준을 건너 뛰고 바깥 수준에서 계속 진행할 수 있다.
setjmp와 longjmp는 C++ 프로그램에서 (심지어 C 프로그램에서도) 좀처럼 만나기 힘들다. 프로그램의 흐름이 완전히 뒤죽박죽되기 때문이다.
C++는 setjmp와 longjmp의 대안으로 예외를 제공한다. 예외로 C++ 프로그램은 통제된 영역을 벗어나 귀환할 수 있다. longjmp와 setjmp의 단점을 겪을 필요가 없다.
예외는 함수 자체에서는 쉽게 처리가 불가능한 그러나 프로그램이 완전히 종료할 정도로 그렇게 재앙적인 것은 아닌 상황을 빠져 나오는 적절한 방법이다. 또, 예외는 범위가 작은 return과 거친 exit 사이에 유연한 제어 계층을 제공한다.
이 장은 예외를 다룬다. 먼저 다양한 예외와 setjmp/longjmp 조합이 프로그램에 미치는 충격에 관하여 예제를 하나 보여준다. 소프트웨어가 예외를 맞이할 때 제공해야 할 보장을 제시한다. 예외와 그 보장은 소멸자와 생성자에 중대한 의미가 있다. 그 중요성을 이 장을 마치면서 만나 보겠다.
throw 서술문으로 던진다. throw 키워드 다음에 특정 유형의 표현식이 나오고 예외 값이 예외로 던져진다. C++에서 값 의미구조를 가진 것이면 무엇이든 예외로 던질 수 있다. int, bool, string, 등등. 그렇지만 표준 예외 유형도 존재한다 (10.8절). 새로운 예외 유형을 정의하여 바탕 클래스로 사용할 수 있다 (제 13장).
try-블록이라는 정의가 잘된 지역 환경 안에서 일어난다. 실행 시간 지원 시스템은 프로그램의 모든 코드가 전역 try 블록 안에 둘러싸여 있음을 보장한다. 그리하여 코드에서 일어나는 예외마다 언제나 최소한 한 개의 try-블록의 경계에 도달하게 되어 있다. 프로그램은 예외가 전역 try 블록의 경계에 도달할 때 종료된다. 이런 일이 일어나더라도 예외가 발생할 시점까지 살아있는 지역 객체와 전역 객체의 소멸자들은 호출되지 않는다. 이것은 바람직한 상황이 아니다. 그러므로 모든 예외는 프로그램이 명시적으로 정의한 try-블록 안에서 일어나야 한다. 다음은 try-블록 안으로부터 던져진 문자열 예외의 예이다.
try
{
// 여기에 어떤 코드도 정의할 수 있다.
if (someConditionIsTrue)
throw string("this is the std::string exception");
// 여기에 어떤 코드도 정의할 수 있다.
}
catch: try-블록 다음에 바로 따라온다. 하나 이상의 catch-절을 정의해야 한다. catch-절은 잡을 수 있는 예외의 유형을 정의한 catch-헤더로 구성된다. 다음에 잡은 예외로 무엇을 할지 정의하는 복합 서술문이 따라온다.
catch (string const &msg)
{
// 잡은 문자열 객체를 처리하는 서술문
}
잡아야 할 예외의 유형마다 하나씩 catch 절이 순서대로 여러 개 나타날 수 있다. 일반적으로 catch 절은 순서에 관계없이 나타날 수 있지만 특정한 순서를 요구하는 예외가 있다. 혼란을 피하기 위해 가장 좋은 것은 최대한 일반적인 예외를 마지막 catch 절에 배치하는 것이다. 그러면 적어도 마지막 예외 절 하나는 활성화된다. C++는 catch 절이 완료된 후에 마지막으로 finally-절이 활성화되는 Java-스타일을 지원하지 않는다.
Outer와 Inner 두 개의 클래스가 있다.
먼저, Outer 객체는 main에 정의되고 Outer::fun 멤버가 호출된다. 다음, Outer::fun에 Inner 객체가 정의된다. Inner 객체를 정의한 후에 자신의 Inner::fun 멤버를 호출한다.
이상이다. Outer::fun 함수는 inner의 소멸자를 호출하면서 끝난다. 그러면 프로그램은 종료하면서 outer의 소멸자를 활성화한다. 다음이 그 기본 프로그램이다.
#include <iostream>
using namespace std;
class Inner
{
public:
Inner();
~Inner();
void fun();
};
Inner::Inner()
{
cout << "Inner constructor\n";
}
Inner::~Inner()
{
cout << "Inner destructor\n";
}
void Inner::fun()
{
cout << "Inner fun\n";
}
class Outer
{
public:
Outer();
~Outer();
void fun();
};
Outer::Outer()
{
cout << "Outer constructor\n";
}
Outer::~Outer()
{
cout << "Outer destructor\n";
}
void Outer::fun()
{
Inner in;
cout << "Outer fun\n";
in.fun();
}
int main()
{
Outer out;
out.fun();
}
/*
출력:
Outer constructor
Inner constructor
Outer fun
Inner fun
Inner destructor
Outer destructor
*/
컴파일하고 실행하면 완전히 예상대로 출력된다. 소멸자가 올바른 순서로 호출된다 (생성자를 호출한 순서의 역순이다).
이제 두 가지 변형에 관심을 두어 보자. Inner::fun 함수 안에서 비-치명적 재앙 사건을 시연한다. 이 사건은 main이 끝날 때 처리하도록 되어 있다.
두 개의 변형을 연구해 보겠다. 첫 번째 변형은 setjmp와 longjmp가 사건을 처리하고 두 번째 변형은 C++의 예외 메커니즘으로 사건을 처리한다.
jmp_buf jmpBuf 변수를 포함해 setjmp와 longjmp를 사용하도록 만들었다.
Inner::fun 함수는 longjmp을 호출해 재앙적 사건을 시연하고 main이 종료할 때 쯤 처리한다. main에서 longjmp의 목표 위치는 setjmp 함수를 통하여 정의된다. Setjmp가 0을 돌려주면 jmp_buf 변수가 초기화되었다는 뜻이고 그러면 Outer::fun이 호출된다. 이 상황은 `정상 흐름'으로 표현된다.
프로그램의 반환 값은 Outer::fun 멤버가 정상적으로 끝났을 때만 0이다. 그렇지만 이런 일은 일어나지 않도록 설계되어 있다. Inner::fun 멤버는 longjmp 함수를 호출한다. 결과적으로 실행 흐름은 setjmp 함수로 돌아온다. 이 경우 반환 값으로 0을 돌려주지 않는다. 결과적으로 Outer::fun 멤버로부터 Inner::fun 멤버를 호출한 후에 main의 if-서술문에 들어가고 프로그램은 반환 값 1을 가지고 종료한다. 다음 프로그램 소스를 연구할 때 이 처리 흐름을 따르도록 노력하라. 10.2절에 제시된 기본 프로그램을 직접 변경했다.
#include <iostream>
#include <setjmp.h>
#include <cstdlib>
using namespace std;
jmp_buf jmpBuf;
class Inner
{
public:
Inner();
~Inner();
void fun();
};
Inner::Inner()
{
cout << "Inner constructor\n";
}
void Inner::fun()
{
cout << "Inner fun\n";
longjmp(jmpBuf, 0);
}
Inner::~Inner()
{
cout << "Inner destructor\n";
}
class Outer
{
public:
Outer();
~Outer();
void fun();
};
Outer::Outer()
{
cout << "Outer constructor\n";
}
Outer::~Outer()
{
cout << "Outer destructor\n";
}
void Outer::fun()
{
Inner in;
cout << "Outer fun\n";
in.fun();
}
int main()
{
Outer out;
if (setjmp(jmpBuf) != 0)
return 1;
out.fun();
}
/*
출력:
Outer constructor
Inner constructor
Outer fun
Inner fun
Outer destructor
*/
이 프로그램의 출력은 inner의 소멸자가 호출되지 않는다는 것을 확실하게 보여준다. 이것은 longjmp가 직접 영역이 아닌 곳으로 건너뛴 결과이다. Inner::fun안의 longjmp 호출로부터 main안의 setjmp로 즉시 실행은 계속된다. 거기에서 반환 값은 0이 아니다. 프로그램은 반환 값을 1로 하여 종료한다. 영역이 아닌 곳으로 건너뛰기 때문에 Inner::~Inner는 절대로 실행되지 않는다. main의 setjmp에 돌아오면 기존의 스택은 망가져 버리므로 기다리고 있는 소멸자들을 모조리 무시해 버린다.
이 예제는 longjmp와 setjmp를 사용하면 객체의 소멸자가 쉽게 무시될 수 있다는 사실을 보여준다. 그러므로 C++ 프로그램은 이 함수들을 절대로 사용하지 말아야 한다.
setjmp와 longjmp로 야기되는 문제들에 대한 C++의 해결책이다. 다음은 예외를 사용하는 예이다. 한 번 더 10.2절의 기본 프로그램을 활용한다.
#include <iostream>
using namespace std;
class Inner
{
public:
Inner();
~Inner();
void fun();
};
Inner::Inner()
{
cout << "Inner constructor\n";
}
Inner::~Inner()
{
cout << "Inner destructor\n";
}
void Inner::fun()
{
cout << "Inner fun\n";
throw 1;
cout << "This statement is not executed\n";
}
class Outer
{
public:
Outer();
~Outer();
void fun();
};
Outer::Outer()
{
cout << "Outer constructor\n";
}
Outer::~Outer()
{
cout << "Outer destructor\n";
}
void Outer::fun()
{
Inner in;
cout << "Outer fun\n";
in.fun();
}
int main()
{
Outer out;
try
{
out.fun();
}
catch (int x)
{}
}
/*
출력:
Outer constructor
Inner constructor
Outer fun
Inner fun
Inner destructor
Outer destructor
*/
Inner::fun은 이제 int 예외를 던진다. 이전에는 longjmp를 사용했었다. in.fun은 out.fun이 호출하기 때문에 예외는 out.fun 호출을 둘러싸고 있는 try 블록 안에서 일어난다. int를 던졌기 때문에 이 값은 try 블록을 벗어나서 catch 절에 다시 나타난다.
Inner::fun 멤버는 longjmp 함수를 호출하는 대신에 예외를 던지면서 종료한다. 예외는 main에서 나포되고 프로그램은 종료한다. 이제 inner의 소멸자가 올바르게 호출되는 것을 볼 수 있다. 흥미로운 것은 Inner::fun의 실행이 실제로 throw 서술문에서 끝난다는 사실이다. throw 서술문 바로 다음에 놓여 있는 cout 서술문은 실행되지 않는다.
이 예제에서 무엇을 배울 수 있는가?
return-서술문을 사용할 필요가 없다. 그리고 exit과 같은 무딘 도구를 사용하여 프로그램을 종료할 필요가 없다.
setjmp와 longjmp는 그 기회를 교란하기 때문에 C++에서 사용하는 것은 엄격하게 금지된다.
throw 서술문으로 던진다. throw 키워드 다음에 던질 예외 값을 정의하는 표현식을 준다. 다음은 그 예이다.
throw "Hello world"; // char *를 던진다.
throw 18; // int를 던진다.
throw string("hello"); // string을 던진다.
지역 변수는 함수가 끝나면 존재하기를 멈춘다. 이것은 예외도 마찬가지다.
예외가 해당 함수를 떠나는 순간, 그 함수에 지역적으로 정의된 객체는 자동으로 파괴된다. 예외로 던져진 객체에도 마찬가지 일이 일어난다. 그렇지만 함수 문맥을 떠나기 바로 전에 객체가 복사된다. 그리고 마침내 적절한 catch 절에 도달하는 것은 바로 이 사본이다.
다음 예제는 이 과정을 보여준다. Object::fun는 지역적으로 Object toThrow를 정의한다. 이것이 예외로 던져진다. 예외는 main에서 나포된다. 그러나 그때 쯤이면 던져진 원래의 객체는 이미 더 이상 존재하지 않는다. main이 받은 것은 그 사본이다.
#include <iostream>
#include <string>
using namespace std;
class Object
{
string d_name;
public:
Object(string name)
:
d_name(name)
{
cout << "Constructor of " << d_name << "\n";
}
Object(Object const &other)
:
d_name(other.d_name + " (copy)")
{
cout << "Copy constructor for " << d_name << "\n";
}
~Object()
{
cout << "Destructor of " << d_name << "\n";
}
void fun()
{
Object toThrow("'local object'");
cout << "Calling fun of " << d_name << "\n";
throw toThrow;
}
void hello()
{
cout << "Hello by " << d_name << "\n";
}
};
int main()
{
Object out("'main object'");
try
{
out.fun();
}
catch (Object o)
{
cout << "Caught exception\n";
o.hello();
}
}
Object의 복사 생성자는 특별하다. 자신의 이름을 다른 객체의 이름으로 정의하기 때문이다. 그 이름에 문자열 " (copy)"가 추가된다. 이 덕분에 객체의 생성과 소멸을 더 자세하게 살펴볼 수 있다. Object::fun은 예외를 일으키고, 지역적으로 정의된 그의 객체를 던진다. 예외를 던지기 바로 전에 프로그램은 다음과 같이 출력한다.
Constructor of 'main object'
Constructor of 'local object'
Calling fun of 'main object'
예외가 일어나면 다음 줄이 출력된다.
Copy constructor for 'local object' (copy)
지역 객체는 throw에 건네지고 거기에서 값 인자로 취급되어 toThrow의 사본을 생성한다. 이 사본을 예외로 던지고 지역 toThrow 객체는 존재하기를 멈춘다. 이제 던져진 예외는 catch 절에서 잡는다. Object 값 매개변수를 정의하고 있다. 이것은 값 매개변수이기 때문에 또다른 사본이 만들어진다. 그래서 프로그램은 다음 텍스트를 출력한다.
Destructor of 'local object'
Copy constructor for 'local object' (copy) (copy)
catch 블록은 이제 다음과 같이 출력한다.
Caught exception
이 다음, o의 hello 멤버가 호출된다. 실제로 toThrow 원본 객체의 사본의 사본을 받았음을 보여준다.
Hello by 'local object' (copy) (copy)
다음으로 프로그램은 종료하고 나머지 객체는 이제 생성의 역순으로 파괴된다.
Destructor of 'local object' (copy) (copy)
Destructor of 'local object' (copy)
Destructor of 'main object'
catch 절이 생성한 사본은 분명히 지나치다. catch 절 안에 참조 매개변수 객체를 정의하면 피할 수 있다. `catch (Object &o)'. 이제 프로그램은 다음과 같이 출력한다.
Constructor of 'main object'
Constructor of 'local object'
Calling fun of 'main object'
Copy constructor for 'local object' (copy)
Destructor of 'local object'
Caught exception
Hello by 'local object' (copy)
Destructor of 'local object' (copy)
Destructor of 'main object'
toThrow 사본을 하나만 생성했다.
지역적으로 정의된 객체를 가리키는 포인터를 던지는 것은 나쁜 생각이다. 포인터는 던져지지만 포인터가 가리키는 객체는 예외가 던져지는 순간, 존재하기를 멈추기 때문이다. 실체가 없는 허상 포인터를 받는다. 좋지 않은 운명이다....
위에서 발견한 사실을 요약해 보자:
if (!parse(expressionBuffer)) // 파싱 실패
throw "Syntax error in expression";
if (!lookup(variableName)) // 변수가 발견되지 않음
throw "Variable not defined";
if (divisionByZero()) // 나눗셈 불능
throw "Division by zero is not defined";
이 throw 서술문들이 배치된 곳은 부적절하다. 프로그램 안쪽 깊숙히 내포되어 나타날 수도 있고 더 위의 수준에서 발견될 수도 있다. 게다가 던질 예외를 함수로 생성할 수도 있다. Exception 객체는 스트림-류의 삽입 연산을 지원할 수도 있어서 다음과 같은 일을 할 수 있다.
if (!lookup(variableName))
throw Exception() << "Undefined variable '" << variableName << "';
이런 상황에 예외 처리자가 간접적으로 호출된다. 던져진 예외를 먼저 중간 수준에서 조사한다. 가능하면 거기에서 처리한다. 처리가 불가능하면 변경되지 않은 그대로 좀 바깥 수준으로 건네진다. 거기에서 그 곤란한 예외가 처리된다.
예외 처리자 코드에 빈 throw 서술문을 배치하면 받은 예외는 특별한 유형의 예외를 처리할 수 있는 다음 수준으로 건네진다. 다시 던져진 예외는 절대로 이웃 예외 처리자에서 처리되지 않는다. 언제나 좀 더 바깥 수준에 있는 예외 처리자로 전송된다.
서버-클라이언트 문맥에서 다음 함수는
initialExceptionHandler(string &exception)
string 예외를 처리하도록 설계할 수 있다. 받은 메시지를 조사한다. 간단한 메시지라면 그냥 처리한다. 그렇지 않으면 예외는 바깥 수준으로 건네진다. initialExceptionHandler의 구현에 빈 throw 서술문이 사용된다.
void initialExceptionHandler(string &exception)
{
if (!plainMessage(exception))
throw;
handleTheMessage(exception);
}
아래 10.5절에서 빈 throw 서술문을 사용하여 catch-블록에서 받은 예외를 던진다. 그러므로 initialExceptionHandler와 같은 함수는 다양한 유형으로 던져지는 예외를 처리할 수 있다. initialExceptionHandler의 문자열 매개변수에 유형이 일치하기만 하면 된다.
다음 예제는 약간 앞으로 건너 뛰어 제 14장에 다룰 주제들이다. 그렇지만 건너 뛰어도 흐름이 끊기지 않는다.
기본 예외 처리 클래스를 생성할 수 있다. 거기에서 특정한 예외 유형을 파생시킨다. Exception이라는 클래스가 있다고 해보자. ExceptionType Exception::severity 멤버 함수가 있다. 이 멤버 함수는 던져진 예외의 심각도를 알려준다 (당연하다!). Info, Notice, Warning, Error 또는 Fatal이 될 수 있다. 예외에 담긴 정보는 심각도에 따라 handle 함수가 처리한다. 게다가 모든 예외는 textMsg와 같은 멤버 함수를 지원한다. 예외에 관한 텍스트 정보를 string 안에 돌려준다.
다형적 handle 함수를 정의함으로써 기본 Exception 포인터나 참조로부터 호출하면 던져진 예외의 유형에 따라 다르게 행동하도록 만들 수 있다.
프로그램은 이 다섯 가지 유형 중 어떤 것이라도 던질 수 있다. Message와 Warning 클래스가 Exception 바탕 클래스로부터 파생된다고 가정하면 예외 유형에 부합하는 handle 함수가 자동으로 다음 예외 나포자에 의하여 호출된다.
//
catch(Exception &ex)
{
cout << e.textMsg() << '\n';
if
(
ex.severity() != ExceptionType::Warning
&&
ex.severity() != ExceptionType::Message
)
throw; // 다른 예외를 건넨다.
ex.handle(); // 메시지 또는 경고를 처리한다.
}
이제 예외 처리자 앞에 있는 try 블록 어디에서든 Exception 객체나 그로부터 파생된 객체를 던질 수 있다. 던져진 객체는 모두 위의 처리자에게 나포된다. 예를 들어,
throw Info();
throw Warning();
throw Notice();
throw Error();
throw Fatal();
try-블록은 throw 서술문을 둘러싼다. 프로그램은 언제나 전역 try 블록에 둘러싸여 있고 그래서 throw 서술문은 코드 어디에든 나타날 수 있다는 사실을 유념하라. 그렇지만 throw 서술문이 함수 몸체에 사용되는 경우가 더 많다. 그런 함수는 try 블록 안에서 호출할 수 있다.
try 블록은 try 키워드와 복합 서술문으로 정의된다. 이어서 catch 절이 적어도 하나는 따라온다.
try
{
// 여기에 할 일을 기술한다.
}
catch(...) // catch 절이 적어도 하나는 있어야 한다.
{}
Try-블록은 내포되어 예외 수준을 형성한다. 예를 들어 main의 코드는 try-블록으로 둘러싸여, 예외를 처리하는 바깥 수준을 형성한다. main의 try-블록 안에서 함수가 호출된다. 그 안에 또 try-블록이 있고 다음 수준의 예외를 형성한다. 10.3.1항에서 보았듯이 안쪽 수준의 try-블록에 던져진 예외는 그 수준에서 처리될 수도 있고 안 될 수도 있다. 빈 throw 서술문을 예외 처리자에 배치하면 던져진 예외는 다음 (바깥) 수준으로 건네진다.
catch 절은 catch 키워드와 다음에 매개변수 하나를 정의한 매개변수 리스트가 따라온다. 여기에 특정한 catch 처리자가 잡을 예외의 유형과 (매개변수) 이름을 정의한다. 이 이름은 catch 절 다음에 오는 복합 서술문에서 변수로 사용될 수 있다. 예제:
catch (string &message)
{
// 메시지를 처리할 코드
}
원시 유형과 객체를 예외로 던질 수 있다. 지역 객체를 가리키는 참조나 포인터를 던지는 것은 나쁜 생각이다. 그러나 동적으로 할당된 객체를 가리키는 포인터는 던져도 된다. 예외 처리자가 할당된 메모리를 지워서 메모리 누수를 방지하기만 하면 된다. 그럼에도 그런 포인터를 던지는 것은 위험하다. 다음 예제에 보여주는 것처럼 동적으로 할당되지 않은 메모리와 동적으로 할당된 메모리를 예외 처리자가 구별하지 못할 수 있기 때문이다.
try
{
static int x;
int *xp = &x;
if (condition1)
throw xp;
xp = new int(0);
if (condition2)
throw xp;
}
catch (int *ptr)
{
// ptr을 지울 것인가 말 것인가?
}
예외 처리자의 매개변수 성격에 주의를 기울여야 한다. 동적으로 할당된 메모리를 가리키는 포인터가 예외로 던져질 때 처리자가 그 포인터를 처리한 후에 해당 메모리가 반납되는지 확인해야 한다. 포인터로 예외를 던지면 안된다. 동적으로 할당된 메모리를 포인터로 예외 처리자에게 건네야 한다면 unique_ptr이나 shared_ptr 같은 스마트 포인터로 싸서 건네야 한다 (18.3절과 18.4절).
여러 catch 처리자가 try 블록 다음에 따라 올 수 있다. 각 처리자는 자신만의 예외 유형을 정의하고 있다. 예외 처리자의 순서가 중요하다. 예외가 던져지면 그 유형에 제일 처음 부합하는 예외 처리자가 사용되며 나머지 예외 처리자는 무시된다. 결국 try-블록 다음에 기껏해야 예외 처리자 하나만 활성화된다. 보통 이것은 논란거리가 아니다. 각 예외마다 자신만의 독특한 유형이 있기 때문이다.
예를 들어 예외 처리자가 char *와 void *에 정의되어 있으면 NTB 문자열은 앞의 처리자가 잡는다. char *는 void *로도 간주할 수 있음을 눈여겨보라. 그러나 예외 유형을 부합시켜 보는 과정은 던져진 NTBS에 char * 처리자를 사용할 정도로 충분히 똑똑하다. 상응하는 유형의 예외를 잡으려면 유형에 아주 가깝도록 예외 처리자를 설계해야 한다. 예를 들어 int-예외는 double-나포자가 잡지 않는다. char-예외는 int-나포자가 잡지 않는다. 다음은 서로 계층적 관계가 없는 유형이라면 나포자의 순서가 중요하지 않음을 보여주는 작은 예제이다 (즉, int는 double로부터 파생되지 않는다. string은 NTBS로부터 파생되지 않는다):
#include <iostream>
using namespace std;
int main()
{
while (true)
{
try
{
string s;
cout << "Enter a,c,i,s for ascii-z, char, int, string "
"exception\n";
getline(cin, s);
switch (s[0])
{
case 'a':
throw "ascii-z";
case 'c':
throw 'c';
case 'i':
throw 12;
case 's':
throw string();
}
}
catch (string const &)
{
cout << "string caught\n";
}
catch (char const *)
{
cout << "ASCII-Z string caught\n";
}
catch (double)
{
cout << "isn't caught at all\n";
}
catch (int)
{
cout << "int caught\n";
}
catch (char)
{
cout << "char caught\n";
}
}
}
특정한 예외 처리자를 정의하는 대신에 특정한 클래스를 설계할 수 있다. 그의 객체는 예외에 관한 정보를 담는다. 이런 접근법은 앞서 10.3.1항에 언급했다. 이 접근법을 사용하면 처리자가 하나만 있으면 된다. 다른 유형의 예외는 모른다는 사실을 알기 때문이다.
try
{
// 코드는 예외 포인터만 던진다.
}
catch (Exception &ex)
{
ex.handle();
}
예외 처리 코드가 처리를 끝내면 실행은 마지막 예외 처리자 다음에 부합하는 try-블록에서 곧바로 계속된다 (기본 실행 흐름을 깨기 위하여 예외 처리자 자체는 (return이나 throw같은) 흐름 제어 서술문을 사용하지 않는다고 가정한다). 다음 사례들을 구별할 수 있다.
try-블록 안에서 예외가 던져지지 않으면 예외 처리자는 활성화되지 않는다. 그리고 실행은 try-블록 안의 마지막 서술문으로부터 마지막 catch-블록을 넘어 첫 번째 서술문까지 계속된다.
try-블록 안에서 던져졌지만 현재 수준이나 또다른 수준에 적절한 예외 처리자가 전혀 없는 경우라면 프로그램의 기본 예외 처리자가 호출되고 프로그램은 종료한다.
try-블록으로부터 던져지고 적절한 예외 처리자가 있으면 그 예외 처리자 코드가 실행된다. 그 다음에 프로그램의 실행은 마지막 catch-블록을 넘어 첫 번째 서술문에서 계속된다.
throw-서술문 다음의 try 블록 안에 있는 서술문은 모조리 무시된다. 그렇지만 throw 서술문을 실행하기 전에 try 블록 안에서 성공적으로 생성된 객체들은 예외 처리자 코드가 실행되기 전에 파괴된다.
try 블록의 예외 처리자에게 전달한다.
기본 예외 처리자를 사용하면 간접적으로 예외를 처리할 수 있다. 기본 예외 처리자는 (10.5절에 언급한 예외 나포자의 계통적 성질 때문에) 다른 모든 구체적인 예외 처리자 다음에 배치해야 한다.
이 기본 예외 나포자는 던져진 예외의 실제 유형을 알지 못하고 그 값도 알 수는 없지만 서술문은 실행할 수 있으므로 기본적인 처리를 할 수 있다. 게다가 나포된 예외는 소실되지 않는다. 그리고 기본 예외 처리자는 빈 throw 서술문을 사용하여 그 예외를 바깥 수준의 예외 처리자에게 되던질 수 있다 (10.3.1항). 거기에서 실제로 처리가 된다. 다음은 기본 예외 처리자를 이런 식으로 사용하는 법을 보여주는 예제이다.
#include <iostream>
using namespace std;
int main()
{
try
{
try
{
throw 12.25; // 배정도 수 전용의 처리자가 없음
}
catch (int value)
{
cout << "Inner level: caught int\n";
}
catch (...)
{
cout << "Inner level: generic handling of exceptions\n";
throw;
}
}
catch(double d)
{
cout << "Outer level may use the thrown double: " << d << '\n';
}
}
/*
출력:
Inner level: generic handling of exceptions
Outer level may use the thrown double: 12.25
*/
프로그램의 출력은 기본 예외 처리자 안의 빈 throw 서술문이 받은 예외를 다음 (바깥) 수준의 예외 나포자에게 던지는 것을 보여준다. 던져진 예외의 유형과 값을 그대로 보존하면서 말이다.
그리하여 내부 수준에서 기본적으로 또는 총칭적으로 예외를 처리할 수 있다. 아니면 바깥 수준에서 예외의 유형에 기반하여 구체적으로 처리할 수 있다. 덧붙여서, 특히 멀티-쓰레드 프로그램에서 (제 20 장) 던져진 예외는 std::exception 객체를 std::exception_ptr 객체로 변환하면 쓰레드 사이에 전달할 수 있다. 이 절차는 기본 나포자 안에서 사용할 수 있다. std::exception_ptr 클래스의 사용 범위는 20.13.1항을 참고하라.
그렇게 호출된 함수는 예외를 던질 가능성이 있다. 그런 함수의 선언에 함수 투포 리스트 또는 예외 지정 리스트를 담을 수 있다 (이제는 비추천이다. 23.7절). 함수가 던질 수 있는 예외의 유형을 지정한다. 예를 들어 `char *'와 `int' 예외를 던질 수 있는 함수는 다음과 같이 선언할 수 있다.
void exceptionThrower() throw(char *, int);
함수 투포 리스트는 함수 헤더 다음에 바로 따라온다 (또 다음에 const 지정자가 올 수 있다). 투포 리스트는 비어 있을 수 있으며 유형마다 쉼표로 분리하여 지정한다. 일반적인 구문은 다음과 같다.
throw ()
throw (type)
throw (type1, type2, type3 ...)
여기에서 생략기호는 갯수에 상관없이 쉼표로 분리된 유형이 지정된다는 뜻이다.
함수가 예외를 던지지 않을 것이라고 보장하려면 빈 함수 투포 리스트를 사용할 수도 있다. 예를 들어,
void noExceptions() throw ();
함수 정의에 사용된 함수 헤더는 선언에 사용된 함수 헤더에 정확하게 일치해야 한다. 물론 빈 함수 투포 리스트도 여기에 포함된다.
함수 투포 리스트가 지정된 함수는 투포 리스트에 언급된 유형의 예외만 던질 수 있다. 다른 유형의 예외를 던지면 실행 시간 에러가 일어난다. 예를 들어 아래에 보이는 charPintThrower 함수는 확실히 char const * 예외를 던진다. intThrower는 int 예외를 던질 수도 있기 때문에 charPintThrower의 함수 투포 리스트에도 역시 int가 담겨 있어야 한다.
#include <iostream>
using namespace std;
void charPintThrower() throw(char const *, int);
class Thrower
{
public:
void intThrower(int) const throw(int);
};
void Thrower::intThrower(int x) const throw(int)
{
if (x)
throw x;
}
void charPintThrower() throw(char const *, int)
{
int x;
cerr << "Enter an int: ";
cin >> x;
Thrower().intThrower(x);
throw "this text is thrown if 0 was entered";
}
void runTimeError() throw(int)
{
throw 12.5;
}
int main()
{
try
{
charPintThrower();
}
catch (char const *message)
{
cerr << "Text exception: " << message << '\n';
}
catch (int value)
{
cerr << "Int exception: " << value << '\n';
}
try
{
cerr << "Generating a run-time error\n";
runTimeError();
}
catch(...)
{
cerr << "not reached\n";
}
}
투포 리스트가 없는 함수는 종류에 상관없이 예외를 던질 수 있다. 투포 리스트가 없다면 프로그램의 설계자는 올바른 처리자를 제공할 책임이 있다.
다양한 이유로 예외 투포자를 선언하는 것은 이제 비추천이다. 예외 투포자를 선언하더라도 부적절한 예외가 던져졌는지 컴파일러가 점검해 주지 않기 때문이다. 그 보다는 던져진 실제 예외를 처리하는 추가 코드로 그 함수가 둘러싸일 것이다. 거기에서 실제로 던져진 예외를 점검한다. 해당 예외가 함수 투포 리스트 안에 있는 유형이라면 그 예외를 되던진다. 그렇지 않으면 실행 시간 에러가 던져진다. 컴파일 시간 점검 부담 대신에 실행 시간 부담이 있다. 결과적으로 그 함수의 코드에 (실행 시간) 코드가 추가된다. 예를 들어 다음과 같이 작성할 수는 있다.
void fun() throw (int)
{
// 이 함수의 코드. 예외를 던짐
}
그러나 함수는 다음과 같은 형태로 컴파일될 것이다 (함수 헤더 바로 다음의 try의 사용법은 10.11절 참조 그리고 bad_exception의 설명은 10.8절 참고):
void fun()
try // 이 코드는 throw(int)의 결과임
{
// 함수의 코드, 모든 종류의 예외를 던진다.
}
catch (int) // throw(int)의 결과인 나머지 코드
{
throw; // `해당' 처리자가 잡을 수 있도록
// 예외를 되던진다.
}
catch (...) // 다른 예외를 모두 잡는다.
{
throw bad_exception{};
}
던지고 받는 예외의 횟수가 배로 늘어나기 때문에 실행 시간 부담이 가중된다. 투포 리스트가 없다면 던져진 int 예외는 단순히 해당 처리자가 잡기만 하면 된다. 투포 리스트가 있다면 int 예외는 먼저 함수에 추가된 `safeguarding' 처리자가 잡는다. 거기에서 해당 처리자가 잡도록 그 예외를 되던진다.
noexcept는 그렇지 않다. noexcept 키워드는 이전에 빈 함수 투포 리스트가 사용되던 곳에 사용된다 (10.9절에서 noexcept가 사용되는 예제를 참고하라). 빈 함수 투포 리스트와 마찬가지로 실행 시간에 부담이 좀 있지만 규칙 위반이 보일 때 빈 함수 투포 리스트보다 noexcept가 더 엄격하다. 함수 투포 리스트 규칙을 위반하면 std::unexpected 예외가 던져진다. noexcept를 위반하면 std::terminate가 실행되고 결과적으로 프로그램이 끝난다.
그리고 noexcept에 인자를 부여해 컴파일 시간에 평가할 수 있다. true로 평가되면 noexcept 요구 조건이 사용된다. 평가가 false를 돌려주면
noexcept 요구 조건은 무시된다. noexcept의 고급 사용법은 23.7절에 다룬다.
ios::exceptions 멤버 함수를 사용하면 그 행위를 바꿀 수 있다. 이 함수는 중복정의 버전이 두 가지 있다.
ios::iostate exceptions():
이 멤버는 상태 깃발을 돌려준다. 거기에 스트림이 예외를 던진다.
void exceptions(ios::iostate state)
이 멤버는 state 상태가 보이면 스트림에게 예외를 던지도록 만든다.
ios::exception으로부터 파생된 ios::failure 클래스의 객체이다. failure 객체를 정의할 때 std::string const &message를 지정할 수 있다. 그러면 그 메시지는 virtual char const *what() const 멤버를 사용하여 열람할 수 있다.
예외는 예외적인 상황에 사용해야 한다. 그러므로 EOF처럼 정상적인 상황에 스트림 객체가 예외를 던지도록 만드는 것은 문제가 있다고 생각한다. (입력 에러가 일어나면 안 되는 상황에 그리고 부패된 파일을 뜻하는 상황에) 예외를 사용하여 입력 에러를 처리하는 것은 나무랄 것이 없다. 그러나 적절한 에러 메시지를 가지고 프로그램을 종료하는 것이 더 합당한 조치일 것이다. 다음의 상호대화 프로그램을 연구해 보자. 예외를 사용하여 부정확한 예외를 잡는다.
#include <iostream>
#include <climits>
using namespace::std;
int main()
{
cin.exceptions(ios::failbit); // 실패하면 예외를 던진다.
while (true)
{
try
{
cout << "enter a number: ";
int value;
cin >> value;
cout << "you entered " << value << '\n';
}
catch (ios::failure const &problem)
{
cout << problem.what() << '\n';
cin.clear();
cin.ignore(INT_MAX, '\n'); // 결함 있는 줄을 무시한다.
}
}
}
기본값으로 ostream 객체 안에서 일어난 예외는 이 객체들이 잡는다. 결과로 ios::badbit 깃발이 올라간다. 이 문제에 관한 연구는 14.8절을 참고하라.
<stdexcept> 헤더를 포함해야 한다. 이 모든 표준 예외는 그 자체가 클래스 유형일 뿐만 아니라 std::exception 클래스의 모든 편의기능을 제공한다. 표준 예외 클래스의 객체들은 std::exception 클래스의 객체로 간주하면 된다.
std::exception 클래스는 다음 멤버를 제공한다.
char const *what() const;
예외의 본성을 짧은 텍스트 메시지로 기술한다.
C++는 다음의 표준 예외 클래스를 정의한다.
std::bad_alloc (<new> 헤더 파일 필요):
operator new가 실패할 때 던져진다.
std::bad_exception (<exception> 헤더 파일 필요): 함수가 자신의 함수 리스트에 정의된 유형 말고 또다른 유형이 예외를 일으키려고 시도할 때 던져진다.
std::bad_cast (<typeinfo> 헤더 파일 필요): 다형성의 문맥일 때 던져진다.
(14.6.1항);
std::bad_typeid (<typeinfo> 헤더 파일 필요): 역시 다형성의 문맥일 때 던져진다 (14.6.2항);
모든 예외 클래스는 std::exception으로부터 파생된다. 이 모든 추가 클래스의 생성자는 std::string const & 인자를 받는다. 이 인자는 예외의 이유를 요약하고 있다 (exception::what 멤버로 열람한다). 추가로 정의된 예외 클래스는 다음과 같다.
std::domain_error: (수학적인) 도메인 에러를 탐지했다.
std::invalid_argument: 함수 인자의 값이 유효하지 않다.
std::length_error: 객체가 최대 허용 길이를 초과할 때 던져진다.
std::logic_error: 프로그램의 내부 로직에 논리 에러를 탐지할 때 던져진다. 예를 들어 C의 printf같은 함수가 자신의 형식화 문자열에 있는 형식 지정자들보다 더 많은 인자를 가지고 호출될 때;
std::out_of_range: 인자가 허용된 범위를 초과할 때 던져진다. 예를 들어 인자가 인덱스 값의 범위를 벗어날 때 at 멤버가 던진다.
std::overflow_error: 산술 계산에 상한초과를 탐지할 때 던져진다. 예를 들어 값을 아주 작은 값으로 나눌 때;
std::range_error: 내부 계산의 결과 값이 허용 범위를 초과할 때 던져진다.
std::runtime_error: 프로그램이 실행 중일 때만 탐지할 수 있는 문제를 만날 때 던져진다. 예제: 프로그램은 정수 값을 입력하기를 기대하는 데 정수값이 아닌 다른 값을 입력할 때.
std::underflow_error: 산술 계산에 하한초과를 탐지할 때 던져진다. 예를 들어 아주 작은 값을 아주 큰 값으로 나눌 때.
C++ 공동체에서 현재의 관례는 예외적인 상황에서만 예외를 던지는 것이다. 그런 점에서 예외 사용에 관한 C++의 철학은 다른 언어의 세계에서 사용되는 예외 처리 방식과 현저하게 다르다. 예를 들어 자바라면 예외인 상황에서도 C++는 예외로 간주하지 않는 경우가 있다. 또다른 일반적인 관례는 소프트웨어를 설계할 때 `개념적인' 스타일을 따르는 것이다. 멋진 예외 사례는 소스의 어느 시점에서 예외를 던져서 무슨 일이 일어나는지 보여줄 수 있다는 것이다. std::out_of_range 예외를 던져주면 소프트웨어 유지라는 관점에서는 좋다. 그 즉시 예외의 이유를 인지할 수 있기 때문이다.
catch-절에서 의미구조적 문맥은 더 이상 적절하지 않게 된다. std::exception 예외를 잡아서 what()으로 내용을 보여줌으로써 사용자에게 무슨 일이 일어났는지 알려준다.
그러나 다른 유형의 값을 던지는 것도 역시 유용할 수 있다. 예외를 던지고 좀 낮은 수준에서 그것을 잡고 싶은 상황이라면 어떨까? 그 사이에 프로그래머가 통제하지 못하는 외부 소프트웨어 라이브러리를 따라 다양한 수준을 넘나들 수도 있다. 그런 상황에 예외가 일어날 수 있다. 그리고 그런 예외를 라이브러리 코드에서 잡아 버릴 수도 있다. 표준 예외 유형을 던질 때 그 예외가 외부 라이브러리에서 잡혀버리지 않는다고 확신하기가 힘들다. 모두-잡기가 (즉, catch (...)가) 사용되지 않았다면 std::exception 가족으로부터 예외를 던지는 것은 별로 좋은 생각이 아닐 수 있다. 그렇다면 그냥 비어 있는 enum으로부터 값을 던지면 잘 작동한다.
enum HorribleEvent
{};
... 깊은 수준에서:
throw HorribleEvent{};
... 얕은 수준에서:
catch (HorribleEvent hs)
{
...
}
다른 예제들은 쉽게 발견할 수 있다. 메시지와 에러 (종료) 코드를 보유한 클래스를 하나 설계하라. 필요하면 그 클래스의 객체를 던지고, main 함수의 try 블록 catch 절에서 잡아라. 그러면 그 사이에 정의된 객체들이 모두 산뜻하게 소멸된다고 확신할 수 있다. 마지막으로 비-예외 객체에 내장된 에러 메시지를 보여주고 종료 코드를 돌려주면 끝이다.
그래서 가능하면 std::exception 유형을 사용하고 필요한 작업을 깔끔하게 마치기를 권고한다. 그러나 그저 불쾌한 상황을 모면하기 위해 예외를 사용하거나 또는 외부에 제공된 코드가 std::exception 예외를 잡을 가능성이 있다면 다른 유형의 값이나 객체를 던지는 것을 고려해 보라.
system_error 객체std::system_error 클래스는 std::runtime_error 클래스로부터 파생된다.
system_error 클래스와 그 관련 클래스를 사용하기 전에 <system_error> 헤더를 포함해야 한다.
(시스템) 에러 값에 연관된 에러를 만나면 system_error 객체를 던질 수 있다. 그런 에러는 전형적으로 (운영 체제 수준의) 낮은-수준의 함수에 연관되어 있다. 그러나 (사용자의 나쁜 입력이나 존재하지 않는 요구처럼) 다른 유형의 에러도 처리할 수 있다.
에러 코드 객체에 에러 값과 그에 부합하는 범주가 저장된다. 범주는 에러 코드가 속하는 구역을 정의한다. 사실상 이것은 열거체가 일련의 에러 코드에 연관되고 범주가 그 열거체에 연관된다는 뜻이다. 새로 열거체와 범주를 정의할 수 있다. 서로 다른 열거체 사이에 열거 심볼과 열거 값은 동일할 수 있다. 혼란을 피하기 위해 마치 이름공간처럼 범주를 사용할 수 있다. 범주를 사용하는 이유 한 가지는 열거체가 상속을 지원하지 않기 때문이다. error_code 객체 안에 열거체가 int 값으로 저장되어 있고, 원래의 열거 클래스는 잃어 버린다.
에러 코드와 에러 범주 말고도 에러 조건이 더 있다. 에러 조건은 `높은 수준의' 에러 원인에 연관된다. 사용자 입력이 나쁘거나 시스템 함수가 실패하거나 또는 존재하지 않은 요구를 할 경우에 에러가 일어난다. 에러 조건은 또한 플랫폼에 독립적이다. 예를 들어 사용자가 이런 저런 플랫폼에서 엉터리로 입력을 하더라도 에러 코드와 에러 범주는 특정한 프로그램과 라이브러리 함수에 맞게 재단된다.
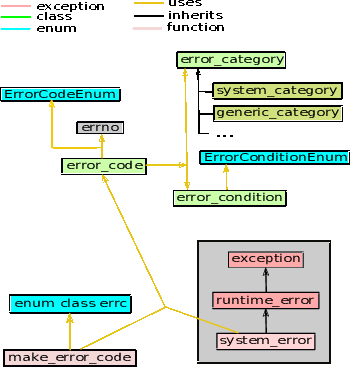
system_error 객체를 생성할 때 error_code 클래스와 error_category 클래스를 지정할 수 있다. 뒤의 두 클래스와 더불어 error_condition 클래스를 소개한다. 그 다음에 system_error 클래스를 더 자세하게 다룬다.
그림 8은 다양한 구성요소들이 서로 어떻게 작용하는지 보여준다.
system_error는 결국exception으로부터 파생되기 때문에 표준 what 멤버가 제공된다. 두 번째 데이터 요소는 error_code이다. error_code는 int 값으로 구성할 수 있다. 별도로 정의된 에러 코드 열거 값으로부터도 구성할 수 있다. error_code는 error_categorie에 연관되어 있기 때문에 int 에러 값을 사용할 수 있으면 부합하는 error_category를 제공해야 한다.
POSIX 시스템에서 errno 변수는 수 많은, 종종 좀 비밀스러운, 심볼에 연관되어 있다. 대신에 미리 정의된 enum class errc는 직관적으로 더 매력적인 심볼을 사용하려고 시도한다. 그 심볼들은 강력한 유형의 열거체에 정의되기 때문에 부합하는 error_code를 정의할 때 직접적으로 사용할 수 없다. 대신에 make_error_code 함수를 사용할 수 있다. 이 함수는 enum class errc 값을 error_code 객체로 변환한다.
큰 개요는 보여주었으므로 그림 8에 보여준 다양한 구성요소들을 더 가까이 살펴 볼 시간이다.
error_code 객체는 error_category와 system_error가 사용한다. 예를 들어 system_error 생성자는 std::error_code 객체를 받는다.
error_code 객체의 주 목적은 에러 값과 관련된 에러 범주를 캡슐화하는 것이다. 종종 에러 값은 전역 int errno에 할당된다.
error_code 클래스는 다음 공개 인터페이스와 자유 함수를 선언한다.
생성자:
error_code() noexcept:
기본 생성자는 에러 값 0과 system_category 에러 범주로 에러 코드를 초기화한다. 에러 값 0은 에러로 간주되지 않는다.
error_code(int ec, error_category const &cat) noexcept:
이 생성자는 에러 값ec와 (예, 실패한 함수가 설정하는errno) 에러범주로 (예,&system_category()또는generic_category()) 에러 코드를 초기화한다.
error_code(ErrorCodeEnum value) noexcept:
멤버 템플릿이다 (22.1.3항). 템플릿 헤더로template <class ErrorCodeEnum>를 사용한다.make_error_code(value)의 반환 값을 가지고 객체를 초기화한다. 23.6.3 항에ErrorCodeEnum을 정의하는 법을 다룬다.
멤버:
ErrorCodeEnum을 받는 할당 연산자를 사용할 수 있다.
void assign(int val, error_category const &cat):
새 값을 현재 객체의value멤버와category멤버에 할당한다.
error_category const &category() const noexcept:
객체의 에러 범주를 참조로 돌려준다.
void clear() noexcept:
이 멤버를 호출하면 값은 0으로 설정되고 객체의 에러 범주는 system_category로 설정된다.
error_condition default_error_condition() const noexcept:
category().default_error_condition(value())를 돌려준다.
string message() const:
category().message(value())를 돌려준다.
explicit operator bool() const noexcept:
value() != 0을 돌려준다.
int value() const noexcept:객체의 에러 값을 돌려준다.
자유 함수:
error_code 객체가 (같은지) 비교하고 (operator<를 사용하여) 정렬할 수 있다.
error_code make_error_code(errc value) noexcept:
error_code(static_cast<int>(value), generic_category())를 돌려준다 (errc: 아래 참고).
std::ostream &operator<<(std::ostream & os, error_code const &ec):
다음 서술문을 실행한다:return os << ec.category().name() << ':' << ec.value();
std 이름공간에 정의된 enum class errc에 정의된 심볼의 값들은 C 마크로가 사용하는 전통적인 에러 코드 값과 같다. 그러나 그의 값은 약간 더 명확하게 에러 조건을 기술한다. 예를 들어,
enum class errc
{
address_family_not_supported, // EAFNOSUPPORT
address_in_use, // EADDRINUSE
address_not_available, // EADDRNOTAVAIL
already_connected, // EISCONN
argument_list_too_long, // E2BIG
argument_out_of_domain, // EDOM
bad_address, // EFAULT
...
};
강력하게 유형이 정의되는 다른 열거체도 몇 가지가 있다. 예를 들어 enum class future_errc에는 (20.9절) 멀티 쓰레드의 문맥에 사용되는 에러 심볼이 정의되어 있다. 자신만의 에러 코드 열거체를 정의하는 법은 23.6.3항에 다룬다.
std::error_category 바탕 클래스로부터 파생된 클래스의 실체들은 (14.9절) 에러 코드 그룹을 식별한다. 새로운 에러 범주는 새로운 에러 코드 열거체에 부합하도록 정의된다.
std::error_category으로부터 error_category 클래스가 새로 파생된다. 그 다음에 system_error 생성자가 사용할 수 있다.
에러 범주는 싱글턴(singleton)으로 설계된다. 클래스마다 실체가 하나만 존재해야 한다. 싱글턴을 사용함으로써 error_category 객체가 같은지 주소를 보고 손쉽게 추론할 수 있다.
error_category 클래스는 여러 멤버를 제공한다. 대부분은 가상(virtual)으로 선언된다 (제 14장). 우리가 직접 설계할 에러 범주 클래스에 그런 멤버들을 정의할 수 있다는 뜻이다 (23.6.3항). 다음 멤버들이 std::error_category에 선언되어 있다:
virtual char const *name() const noexcept:
이 멤버는 반드시 자신만의 범주 클래스가 정의해야 한다. (generic처럼) 에러 범주의 이름을 NTBS로 돌려준다.
virtual string message(int ev) const:
이 멤버는 반드시 자신만의 범주 클래스가 정의해야 한다. ev로 표기된 에러 조건을 기술하는 문자열을 돌려준다.
virtual error_condition default_error_condition(int ev) const noexcept:
현재error_category에 정의된 에러 값ev에 상응하는error_condition을 돌려준다.
virtual bool equivalent(int ev, error_condition const &condition)
const noexcept:
에러 값ev의 에러 조건이condition과 같으면true를 돌려준다.
virtual bool equivalent(error_code const &code, int condition) const
noexcept:
code의 에러 범주가 현재 범주와 같고code에러 조건이condition과 같으면true를 돌려준다.
bool operator<(error_category const &rhs) const noexcept:
less<const error_category*>()(this, &rhs)를 돌려준다.
미리 정의된 에러 범주를 돌려주는 함수는 다음과 같다.
error_category const &generic_category() noexcept:
총칭error_category객체를 참조로 돌려준다. 반환된 객체의name멤버는 문자열"generic"을 포인터로 돌려준다.
error_category const &system_category() noexcept:
운영 체제error_category객체를 참조로 돌려준다. 운영 체제가 보고하는 에러에 사용된다. 반환된 객체의name멤버는 문자열"system"을 포인터로 돌려준다.
error_category const &iostream_category() noexcept:
iostreamerror_category객체를 참조로 돌려준다. 스트림 객체가 보고하는 에러에 사용된다. 반환된 객체의name멤버는 문자열"iostream"을 포인터로 돌려준다.
error_category const &future_category() noexcept:
futureerror_category객체를 참조로 돌려준다. `future' 객체가 보고하는 에러에 사용된다 (20.9절). 반환된 객체의name멤버는 문자열"future"를 포인터로 돌려준다.
error_condition 객체는 에러의 원인에 관한 정보를 저장한다. 예를 들어 사용자가 입력을 엉터리로 하거나 접근 권한이 없거나 시스템 함수가 실패하면 에러가 일어난다. 그런 에러의 원인은 특정한 플랫폼에 국한되지 않는다. 그래서 플랫폼에 독립적인 범주를 나타낸다.
에러 조건 객체는 error_code와 error_category 클래스의default_error_condition 멤버가 돌려준다. 이 객체는 error_category::equivalent 멤버가 인자로 기대한다.
error_condition 클래스는 다음 공개 인터페이스를 선언한다.
생성자:
error_condition() noexcept:
이 기본 생성자는 에러 값 0과 system_category 에러 범주로 에러 코드를 초기화한다. 에러 값 0은 에러로 간주되지 않는다.
error_condition(int ec, error_category const &cat) noexcept:
이 생성자는 에러 값ec와cat에러 범주로 에러 조건을 초기화환다.
error_condition(ErrorConditionEnum e) noexcept:
이 멤버 템플릿은 (22.1.3항)template <class ErrorConditionEnum>헤더를 사용한다.make_error_condition(e)의 반환 값을 가지고 객체를 초기화한다. 23.6.5항에 자신만의ErrorConditionEnum을 정의하는 법을 다룬다.
멤버:
ErrorConditionEnum을 받는 복사 할당 연산자와 더불어 할당 연산자를 사용할 수 있다.
void assign(int val, error_category const &cat):
새 값을 현재 객체의 value와 category 데이터 멤버에 할당한다.
error_category const &category() const noexcept:
객체의 에러 범주를 참조로 돌려준다.
void clear() noexcept:이 멤버를 호출하고 나면 value는 0으로 설정되고 객체의 에러 범주는 generic_category로 설정된다.
string message() const:category().message(value())를 돌려준다.
explicit operator bool() const noexcept:value() != 0을 돌려준다.
int value() const noexcept:객체의 에러 값을 돌려준다.
두 개의 error_condition 객체가 서로 같은지 비교할 수 있고 operator<를 사용하여 정렬할 수 있다.
system_error 객체는 error_codes나 에러 값 (ints) 또는 부합하는 에러 범주 객체로부터 구성할 수 있다. 일어난 에러의 본성을 표준적으로 기술하는 텍스트가 선택적으로 따라온다.
다음은 system_error 클래스의 공개 인터페이스이다:
class system_error: public runtime_error
{
public:
system_error(error_code ec);
system_error(error_code ec, string const &what_arg);
system_error(error_code ec, char const *what_arg);
system_error(int ev, error_category const &ecat);
system_error(int ev, error_category const &ecat,
char const *what_arg);
system_error(int ev, error_category const &ecat,
string const &what_arg);
error_code const &code() const noexcept;
char const *what() const noexcept;
}
ev 값은 종종 errno 변수의 값과 같다. chmod(2)와 같은 시스템 수준의 함수가 실패할 때 설정된다.
인터페이스 앞쪽부터 세 개의 생성자는 error_code 객체를 첫 인자로 받는다. error_code 생성자 중 하나가 int와 error_category를 인자로 기대하기 때문에, 두 번째 집합인 세 개의 생성자도 첫 번째 생성자 집합 대신에 사용할 수 있다. 예를 들어,
system_error(errno, system_category(), "context of the error");
// 다음과 동일:
system_error(error_code(errno, system_category()),
"context of the error");
두 번째 집합 세 개의 생성자는 기존의 함수가 이미 error_code를 돌려줄 때 주로 사용된다. 예를 들어,
system_error(make_error_code(errc::bad_address),
"context of the error");
// 아니면 다음도 가능함:
system_error(make_error_code(static_cast<errc>(errno)),
"context of the error");
표준 what 멤버 외에도 system_error 클래스는 또 code 멤버를 제공한다. 예외의 에러 코드에 대한 상수 참조를 돌려준다.
what 멤버가 돌려준 NTBS는 다음과 같이 system_error 객체로 형식화할 수 있다:
what_arg + ": " + code().message()
주의하라. system_error가 runtime_error으로부터 파생되었지만 std::exception 객체를 받을 때 code 멤버를 잃어 버리게 될 것이다. 물론 하향 형변환을 할 수는 있지만 그것은 임시 방편에 불과하다. 그러므로 system_error가 던져지면 부합하는 catch(system_error const &) 절을 제공해 code 멤버가 돌려주는 값을 열람해야 한다. 이 때문에 그리고 system_error를 사용할 때 관련된 클래스가 복잡하게 조직되어 있기 때문에 일반적으로 예외를 처리하기가 몹시 복잡하고 어렵게 된다. 그러나 복잡성을 대가로 하여 편리하게 int나 enum 에러 값을 범주화할 수 있다. 관련된 복잡성을 제 23장에 더 자세하게 다룬다. 특히 23.6.3항과 23.6.5항을 참고하라 (유연한 다른 방법은 필자의 Bobcat 라이브러리에서 FBB::Exception 클래스를 참고하라. )
예외는 어떤 C++ 함수에서든 일어날 가능성이 있다. 이 모든 예외 상황을 직접적으로 그리고 직관적으로 알 수는 없다. 다음 함수를 연구해 보고 어느 지점에서 예외가 일어날 지 생각해 보자:
void fun()
{
X x;
cout << x;
X *xp = new X(x);
cout << (x + *xp);
delete xp;
}
위와 같이 사용되는 cout은 예외를 던지지 않는다고 간주할 수 있을지라도 적어도 13 가지의 상황에 예외가 던져질 가능성이 있다.
X x: 기본 생성자는 예외를 던질 수 있다 (#1).
cout << x: 중복정의 삽입 연산자는 예외를 던질 수 있다 (#2). 그러나 그의 rvalue 인자는 X가 아니라 int일 수 있다. 그래서 X::operator int() const이 호출될 가능성이 있으며 이 때문에 예외의 가능성이 하나 더 늘어 난다 (#3).
*xp = new X(x): 복사 생성자는 예외를 던질 수 있다 (#4). new 연산자 역시 마찬가지다 (#5a). 그러나 후자의 예외는::new가 아니라 X 자신의 operator new 중복정의로부터 던져질 수 있다는 사실을 깨닫으셨는지? (#5b)
cout << (x + *xp): 두 X 객체가 더해진다고 생각할 것이다. 그러나 반드시 그래야 하는 것은 아니다. 별개로 Y 클래스가 존재하고 X 클래스에 operator Y() const 변환 연산자가 있을 수 있다. 그리고 operator+(Y const &lhs, X const &rhs)와 operator+(X const &lhs, Y const &rhs) 그리고 operator+(X const &lhs, X const &rhs)도 모두 존재할 가능성이 있다. 그래서 변환 연산자가 존재하면 operator+의 중복정의의 종류에 따라 덧셈의 왼쪽 피연산자 (#6)나 오른쪽 피연산자 (#7) 또는 operator+ 자체가 (#8) 예외를 던질 수 있다. 결과 값도 역시 아무 유형이든 될 수 있다. 그래서 중복정의 cout << return-type-of-operator+ 연산자는 예외를 던질 수 있다 (#9). operator+는 임시 객체를 돌려주기 때문에 사용이 끝나면 곧바로 소멸된다. X의 소멸자는 예외를 던질 수 있다 (#10).
delete xp: operator new가 중복정의될 때마다 operator delete도 역시 중복정의해야 한다. 이 때문에 예외가 던져질 수 있다 (#11). 물론 X의 소멸자도 예외를 던질 수 있다 (#12).
}: 함수가 종료할 때 지역 x 객체가 파괴된다. 그 때문에 역시 예외가 일어날 수 있다 (#13).
이 많은 상황에 예외를 던질지도 모르는데 어떻게 작동하는 프로그램을 만들 수 있다고 기대할 수 있을까?
예외는 엄청나게 많은 상황에 일어날 수 있다. 그러나 심각한 문제는 적어도 다음 예외 보장 중 하나만 제공할 수 있으면 방지된다.
catch 처리자의 과업은 할당된 자원을 모두 돌려준 다음, 다시 그 예외를 되던지는 것이다.
void allocator(X **xDest, Y **yDest)
{
X *xp = 0; // 예외를 던지지 않는 것으로 시작
Y *yp = 0;
try // 이 부분은 예외를 던질 가능성이 있다.
{
xp = new X[nX]; // 다른 방법으로 객체 할당
yp = new Y[nY];
}
catch(...)
{
delete xp;
throw;
}
delete[] *xDest; // 예외를 던지지 않는 것으로 종료
*xDest = xp;
delete[] *yDest;
*yDest = yp;
}
try 이전 코드에서 new 연산자 호출로 반환된 주소를 받는 포인터는 0으로 초기화된다. 나포 처리자는 배당된 메모리를 모두 돌려줄 수 있어야 하기 때문에 try 블록 밖에 있어야 한다. 할당에 성공하면 목표 포인터가 가리키는 메모리가 반환된 후에 그 포인터에 새 값이 주어진다.
배당과 초기화는 실패할 수 있다. 배당하지 못하면 new는 std::bad_alloc 예외를 던지고 나포 처리자는 그냥 0 포인터를 삭제한다. 그것으로 OK이다.
배당에 성공하지만 객체를 생성하지 못하면 예외를 던지는데 확실하게 다음과 같은 일이 일어난다.
결론적으로 new가 실패하더라도 메모리 누수는 없다. 위의 try 블록 안에서 new X는 실패할 수 있다. 그래도 0-포인터에는 영향을 미치지 않는다. 그래서 나포 처리자는 그냥 0 포인터를 삭제하기만 하면 된다. new Y가 실패하면 xp는 할당된 메모리를 가리킨다. 그래서 공용 풀에 돌려 주어야 한다. 이런 일은 나포 처리자 안에서 일어난다. new Y가 적절하게 완료되면 마지막 포인터는 (즉, yp는) 0이 아니게 된다. 그래서 나포 처리자는 yp가 가리키는 메모리를 돌려줄 필요가 없다.
Class &operator=(Class const &other)
{
Class tmp(other);
swap(tmp);
return *this;
}
복사 생성은 예외를 던질 수 있지만 이 방법은 현재 객체의 상태를 건드리지 않은 채로 유지해 준다. 사본 생성에 성공하면 swap은 현재 객체의 내용과 tmp의 내용을 바꾸고 현재 객체의 참조를 돌려준다. 이 방법이 성공하려면 swap이 예외를 던지지 않을 것이라는 보장을 해야 한다. 참조를 (또는 원시 유형의 값을) 돌려주는 것은 예외를 던지지 않는다고 보장할 수 있다. 그러므로 중복정의 할당 연산자의 표준적 형태는 강력 보장의 요구 조건을 만족한다.
강력 보장과 관련하여 몇 가지 규칙이 정해졌다 (Sutter, H., Exceptional C++, Addison-Wesley, 2000). 예를 들어,
표준 할당 연산자는 첫 번째 규칙에 맞는 좋은 예이다. 또다른 예는 객체를 저장하는 클래스에서 볼 수 있다. 여러 Person 객체를 저장하는 PersonDb 클래스를 연구해 보자. 이 클래스에 void add(Person const &next) 멤버를 구현해 보자. 이 함수의 평범한 구현은 다음과 같을 것이다 (그저 첫 번째 규칙이 적용되는 것을 보여주기 위한 의도이다. 그 목적 말고는 효율성의 측면을 완전히 무시한다.).
void PersonDb::newAppend(Person const &next)
{
Person *tmp = 0;
try
{
tmp = new Person[d_size + 1];
for (size_t idx = 0; idx < d_size; ++idx)
tmp[idx] = d_data[idx];
tmp[d_size] = next;
}
catch (...)
{
delete[] tmp;
throw;
}
}
void PersonDb::add(Person const &next)
{
Person *tmp = newAppend(next);
delete[] d_data;
d_data = tmp;
++d_size;
}
(비공개) newAppend 멤버의 과업은 다음 Person 객체의 데이터를 포함하여 현재 할당된 Person 객체의 사본을 만드는 것이다. 그리고 catch 처리자는 복사 또는 할당중에 던져지는 모든 예외를 잡는다. 지금까지 할당된 메모리를 모두 돌려주고, 마지막으로 그 예외를 되던진다. 이 함수는 예외를 독점하지 않는다. 모든 예외를 호출자에게 전파하기 때문이다. 이 함수는 또한 PersonDb 객체의 데이터를 변경하지도 않는다. 그래서 예외 강력 보장을 만족한다. newAppend으로부터 돌아오면 add 멤버는 이제 그의 데이터를 변경할 수 있다. 기존의 데이터는 반환되고 d_data 포인터는 새로 생성된 Person 객체의 배열을 가리킨다. 마지막으로 d_size가 증가한다. 이 세 단계는 예외를 던지지 않으므로 add도 역시 강력 보장을 만족한다.
두 번째 제일 규칙은 PersonDb::erase(size_t idx) 멤버를 사용하여 보여줄 수 있다 (객체의 데이터를 변경하는 함수는 (포함된) 원래의 객체를 값으로 돌려주면 안된다). 다음은 원래의 d_data[idx] 객체를 돌려주기 위한 구현이다.
Person PersonData::erase(size_t idx)
{
if (idx >= d_size)
throw string("Array bounds exceeded");
Person ret(d_data[idx]);
Person *tmp = copyAllBut(idx);
delete[] d_data;
d_data = tmp;
--d_size;
return ret;
}
복사 생략은 ret를 돌려줄 때 복사 생성자의 사용을 막는다. 하지만 일어나지 않는다는 보장은 없다. 게다가, 복사 생성자는 예외를 던질 가능성이 있다. 예외가 던져지면 함수는 PersonDb의 데이터를 회복할 수 없을 정도로 뭉개 버리기 때문에 강력 보장을 할 수 없다.
값으로 d_data[idx]를 돌려주지 말고 외부에 Person 객체를 할당한 다음에 PersonDb의 데이터에 손대는 것이 좋다.
void PersonData::erase(Person *dest, size_t idx)
{
if (idx >= d_size)
throw string("Array bounds exceeded");
*dest = d_data[idx];
Person *tmp = copyAllBut(idx);
delete[] d_data;
d_data = tmp;
--d_size;
}
이렇게 변경해도 작동은 하지만 원래 객체를 돌려주는 멤버를 만든다는 원래 과업의 목적에 어긋나 버린다. 그렇지만 두 함수 모두 과도한 과업 때문에 고통을 겪는다. PersonDb의 데이터를 변경하고 또 원래의 객체를 돌려주기 때문이다. 이와 같은 상황에 함수-하나에-책임-하나라는 규칙을 명심해야 한다. 함수는 정의가 잘된 책임을 하나만 져야 한다.
좋은 접근법은 Person const &at(size_t idx) const와 같은 멤버를 사용하여 PersonDb의 객체를 열람하고 void PersonData::erase(size_t idx)와 같은 멤버를 사용하여 객체를 삭제하는 것이다.
swap 함수이다. 다시 한 번 표준 중복정의 할당 연산자를 연구해 보자:
Class &operator=(Class const &other)
{
Class tmp(other);
swap(tmp);
return *this;
}
swap 함수가 예외를 던져도 허용한다면 완전히 교체되지 않은 상태로 현재 객체를 떠날 가능성이 높다. 결과적으로 현재 객체의 상태가 바뀌어 있을 가능성이 매우 높을 것이다. 나포 처리자가 던져진 예외를 잡을 즈음이면 tmp가 이미 파괴되어 없으므로 객체의 원래 상태를 열람하기가 아주 어렵다 (사실상 불가능하다). 결과적으로 강력 보장을 할 수 없다.
그러므로 swap 함수는 절대 보장을 제공해야 한다. 마치 다음과 같은 원형처럼 사용되도록 설계되어 있어야 한다 (23.7절도 참고):
void Class::swap(Class &other) noexcept;
마찬가지로 operator delete와 operator delete[]는 절대 보장을 제공한다. C++ 표준에 따라 소멸자는 자체로 예외를 던지지 않는다 (만약 예외를 던지면 어떻게 대응해야 하는지 공식적으로 정의되어 있지 않다. 아래 10.12절 참고).
C 언어는 예외 개념이 정의되어 있지 않으므로 표준 C 라이브러리의 함수는 절대 보장을 묵시적으로 제공한다. 이 덕분에 9.6절에 memcpy를 사용하여 총칭 swap 함수를 작성할 수 있다.
원시 유형의 연산은 절대 보장을 제공한다. 포인터를 재할당할 수 있고 참조를 돌려줄 수 있다. 등등. 혹시나 예외가 던져질까 걱정할 필요가 없다.
try 블록 안에 내포시키는 것은 문제를 해결하지 못한다. 그때 쯤이면 예외는 생성자를 떠나 있고 생성하고자 하는 객체는 아직 완성되지 않았기 때문이다.
내포 try 블록을 사용하는 방법은 다음 예제에 보여준다. main에 PersonDb의 객체를 정의한다. PersonDb의 생성자가 예외를 던진다고 가정하자. PersonDb의 생성자가 할당해 둔 자원에 catch 처리자가 접근할 방법이 없다. pdb 객체가 영역을 벗어나 있기 때문이다.
int main(int argc, char **argv)
{
try
{
PersonDb pdb(argc, argv); // 예외를 던질 가능성이 있다.
... // main()의 다른 코드
}
catch(...) // 그리고/또는 다른 처리자
{
... // 여기에서 pdb에 접근할 수 없다.
}
}
try 블록 안에 정의된 모든 객체와 변수는 관련된 catch 처리자로부터 접근할 수 없지만 객체 데이터 멤버는 try 블록을 시작하기 전에 사용할 수 있다. 그래서 catch 처리자가 접근할 수 있다. 다음 예제에서 PersonDb 생성자의 catch 처리자는 자신의 d_data 멤버에 접근할 수 있다.
PersonDb::PersonDb(int argc, char **argv)
:
d_data(0),
d_size(0)
{
try
{
initialize(argc, argv);
}
catch(...)
{
// d_data, d_size: 접근 가능
}
}
안타깝게도 이것은 별로 도움이 되지 않는다. PersonDb const pdb가 정의되어 있으면 initialize 멤버는 d_data와 d_size를 재할당할 수 없다. initialize 멤버는 적어도 기본 예외 보장을 해야 한다. 그리고 던져진 예외 때문에 종료하기 전에 획득한 자원을 모두 돌려주어야 한다. 원시 데이터 유형이기 때문에 d_data와 d_size는 절대 보장을 제공하지만 클래스 유형의 데이터 멤버라면 예외를 던질 가능성이 있고 그 결과로 기본 보장을 범할 가능성이 있다.
PersonDb의 다음 구현에 생성자가 이미 할당된 Person 객체의 메모리 블록을 포인터로 받는다고 가정하자. PersonDb 객체는 할당된 메모리의 소유권을 획득한다. 그러므로 할당된 메모리를 끝까지 파괴할 책임이 있다. 게다가 d_data와 d_size는 PersonDbSupport 합성 객체도 사용한다. 그의 생성자는 Person const *와 size_t 인자를 기대한다. 구현은 다음과 같이 보일 것이다.
PersonDb::PersonDb(Person *pData, size_t size)
:
d_data(pData),
d_size(size),
d_support(d_data, d_size)
{
// 더 이상 조치 없음
}
이렇게 설정하면 PersonDb const &pdb를 정의할 수 있다. 불행하게도 PersonDb는 기본 보장을 제공하지 않는다. PersonDbSupport의 생성자가 예외를 던지더라도 잡히지 않는다. 물론 이미 할당된 메모리를 d_data가 가리키고 있기 때문이다.
이 문제의 해결책을 함수 try 블록이 제공한다. 함수 try 블록은 try 블록과 연관 처리자들로 구성된다. 함수 try 블록은 함수 헤더 다음에 곧바로 시작하고 그의 블록은 함수 몸체를 정의한다. 생성자로서 바탕 클래스와 데이터 멤버 초기화자를 try 키워드와 여는 활괄호 사이에 배치할 수 있다. 다음은 PersonDb의 최종 구현이다. 이제 기본 보장을 제공한다.
PersonDb::PersonDb(Person *pData, size_t size)
try
:
d_data(pData),
d_size(size),
d_support(d_data, d_size)
{}
catch (...)
{
delete[] d_data;
}
불필요한 것을 모두 뺀 예제를 하나 살펴 보자. 생성자는 함수 try 블록을 정의한다. Throw 객체가 던진 예외는 제일 처음 자체에서 잡는다. 다음 그 예외를 되던진다. 바깥의 Composer의 생성자도 함수 try 블록을 정의한다. Throw가 되던진 예외는 적절하게 Composer의 예외 처리자가 잡는다. 그의 멤버 초기화 리스트 안에서 예외가 일어났을지라도 적절하게 잡는다.
#include <iostream>
class Throw
{
public:
Throw(int value)
try
{
throw value;
}
catch(...)
{
std::cout << "Throw's exception handled locally by Throw()\n";
throw;
}
};
class Composer
{
Throw d_t;
public:
Composer()
try // 주의: 초기화 리스트보다 먼저 시도
:
d_t(5)
{}
catch(...)
{
std::cout << "Composer() caught exception as well\n";
}
};
int main()
{
Composer c;
}
이 예제를 실행하면 놀라운 일을 겪는다. 프로그램은 실행되고 중단 예외와 함께 깨진다. 다음은 프로그램의 출력이다. 마지막 두 줄은 시스템의 마지막 총괄 나포 처리자가 추가한 것이다. 마지막 처리자는 잡지 못한 나머지 예외를 모두 잡는다.
Throw's exception handled locally by Throw()
Composer() caught exception as well
terminate called after throwing an instance of 'int'
Abort
그 이유는 C++ 표준에 문서화되어 있다. 생성자나 소멸자 함수 try 블록에 속한 나포-처리자의 끝에서 원래의 예외가 자동으로 되던져진다.
처리자 자체에서 또다른 예외를 던지면 그 예외는 되던져지지 않는다. 던져진 예외를 또다른 예외로 교체할 방법을 생성자나 소멸자에게 제공한다. 예외는 생성자나 소멸자 함수 try 블록의 나포 처리자의 끝에 다다를 경우에만 되던져진다. 내포된 나포 처리자가 잡은 예외는 자동으로 되던져지지 않는다.
생성자와 소멸자만 자신의 함수 try 블록 나포 처리자 안에서 잡은 예외를 되던지기 때문에 위 예제의 실행 시간 에러는 간단하게 고칠 수 있다. main 함수에 따로 함수 try 블록을 배치하면 된다.
int main()
try
{
Composer c;
}
catch (...)
{}
이제 프로그램은 계획대로 실행되고 다음과 같이 출력한다.
Throw's exception handled locally by Throw()
Composer() caught exception as well
마지막 당부 말씀을 드린다. 함수 try 블록을 정의한 함수가 또 예외 나포 리스트를 선언하면 되던져진 예외의 유형만 그 리스트에 언급된 유형에 부합한다.
다음 예제는 원형적 형태로 이 상황을 보여준다. Incomplete 클래스의 생성자는 먼저 메시지를 보여준 다음에 예외를 던진다. 소멸자도 메시지를 보여준다.
class Incomplete
{
public:
Incomplete()
{
cerr << "Allocated some memory\n";
throw 0;
}
~Incomplete()
{
cerr << "Destroying the allocated memory\n";
}
};
다음으로 main()은 Incomplete 객체를 try 블록 안에 생성한다. 예외는 일어나면 무엇이든 잇달아 나포된다.
int main()
{
try
{
cerr << "Creating `Incomplete' object\n";
Incomplete();
cerr << "Object constructed\n";
}
catch(...)
{
cerr << "Caught exception\n";
}
}
이 프로그램을 실행하면 다음과 같이 출력한다.
Creating `Incomplete' object
Allocated some memory
Caught exception
그리하여 Incomplete의 생성자가 실제로 메모리를 할당했다면 프로그램은 메모리 누수를 겪게 된다. 이를 방지하기 위해 다음의 참조 횟수 세기 방법을 사용할 수 있다.
try 블록으로 둘러싸서 그 예외를 나포해야 한다. 이 접근법은 생성자가 예외의 원인을 고쳐서 유효한 객체로 생성을 완료할 수 있을 때 사용하면 좋다.
try 블록은 던져진 예외를 잡을 수 없다. 이 결과 언제나 예외는 생성자를 벗어나 버리고 그리하여 그 객체는 올바르게 생성되지 않았다고 간주된다. try 블록은 멤버 초기화자를 포함할 수 있고 try 블록의 복합 서술문은 다음 예제와 같이 생성자의 몸체가 된다.
class Incomplete2
{
Composed d_composed;
public:
Incomplete2()
try
:
d_composed(/* arguments */)
{
// body
}
catch (...)
{}
};
멤버 초기화자나 몸체에서 던져진 예외는 몸체의 닫는 괄호에 절대로 도달하지 못한다. 대신에 catch 절에 도달한다. 생성자 몸체가 적절하게 완료되지 않았기 때문에 객체가 올바르게 생성되지 않은 것으로 간주되므로 결국 소멸자는 호출되지 않는다.
try 블록에 있는 catch 절은 평범한 함수의 try 블록에 있는 catch 절과 약간 다르게 행위한다. 생성자 함수의 try 블록에 도달하는 예외는 또다른 예외로 변형이 가능하지만 (catch 절에서 던짐) catch 절에서 예외를 명시적으로 던지지 않으면 그 예외는 언제나 다시 던져진다. 결과적으로 바탕 클래스의 생성자나 멤버 초기화자에게서 던져진 예외를 생성자 안으로 제한할 방법이 없다. 그런 예외는 언제나 좀더 바깥 수준으로 전파되고 그리하여 객체의 생성은 언제나 미완성이라고 간주된다.
결과적으로 미완성 객체가 예외를 던지면 생성자의 catch 절이 메모리(자원) 누수를 책임을 지고 막아야 한다. 이를 실현하려면 몇 가지 방법이 있다.
shared_ptr은 객체이기 때문이다.
catch 절에서 클래스의 평범한 데이터 멤버가 가리키는 메모리를 제거한다. 예제:
class Incomplete2
{
Composed d_composed;
char *d_cp; // 평범한 포인터
int *d_ip;
public:
Incomplete2(size_t nChars, size_t nInts)
try
:
d_composed(/* arguments */), // 예외 가능성
d_cp(0),
d_ip(0)
{
preamble(); // 예외 가능성
d_cp = new char[nChars]; // 예외 가능성
d_ip = new int[nChars]; //예외 가능성
postamble(); // 예외 가능성
}
catch (...)
{
delete[] d_cp; // 정리
delete[] d_ip;
}
};
반면에 C++는 생성자 위임을 지원하기 때문에 C++ 실행 시간 시스템에 맞게 객체를 완벽하게 생성할 수는 있지만 여전히 그의 생성자는 예외를 던질 가능성이 있다. 위임된 생성자는 성공적으로 임무를 마쳤지만 (이후로 객체는 `완벽하게 생성되었다'고 간주된다) 해당 생성자 자체가 예외를 던지면 이런 일이 일어난다. 다음 예제에 보여준다.
class Delegate
{
public:
Delegate()
:
Delegate(0)
{
throw 12; // 예외는 던지지만 완전하게 생성됨
}
Delegate(int x) // 생성 완료
{}
};
int main()
try
{
Delegate del; // 예외를 던짐
} // del의 소멸자가 여기에서 호출됨
catch (...)
{}
이 예제에서 Delegate의 설계자는 예외를 던지는 기본 생성자가 Delegate의 소멸자가 수행한 조치를 무효화하지 못하도록 책임을 지고 확인해야 한다. 예를 들어 위임된 생성자가 메모리를 배당했지만 소멸자에게 파괴될 운명이라면 기본 생성자는 메모리를 그대로 두거나 아니면 메모리를 삭제하고 상응하는 포인터를 0으로 설정할 수 있다. 어느 경우든 객체가 유효한 상태로 남아 있는지 확인하는 것은 비록 예외를 던질지라도 Delegate의 책임이다.
C++ 표준에 의하면 예외는 소멸자를 벗어나면 안된다. 그러므로 소멸자에 함수 try 블록을 제공하는 것은 표준에 어긋난다. 함수 try 블록의 catch 절에 잡힌 예외는 이미 소멸자를 떠났기 때문이다. 만약 표준을 위배하여 소멸자에 함수 try 블록을 제공하고 예외가 그 try 블록에 잡힌다면 그 예외는 다시 던져진다. 생성자 함수의 try 블록의 catch 절에서 일어나는 일과 비슷하다.
예외가 소멸자를 벗어날 경우 그 결과는 정의되어 있지 않다. 예상치 못한 행위를 야기할 수도 있다. 다음 예제를 연구해 보자:
서랍 하나가 달린 찬장을 짠다고 가정해 보자. 찬장이 완성되고 그 찬장을 산 고객은 기대한 대로 사용할 수 있음을 알게 된다. 그 고객은 찬장에 아주 만족하여 이 번에는 서랍이 두 개 달린 찬장을 주문한다. 두 번째 찬장이 완성되어 배달된다. 고객은 몹시 놀란다. 처음 열자마자 바로 완전히 부서졌기 때문이다.
이상한 이야기 같은가? 그러면 다음 프로그램을 연구해 보자:
int main()
{
try
{
cerr << "Creating Cupboard1\n";
Cupboard1();
cerr << "Beyond Cupboard1 object\n";
}
catch (...)
{
cerr << "Cupboard1 behaves as expected\n";
}
try
{
cerr << "Creating Cupboard2\n";
Cupboard2();
cerr << "Beyond Cupboard2 object\n";
}
catch (...)
{
cerr << "Cupboard2 behaves as expected\n";
}
}
이 프로그램을 실행하면 다음과 같이 출력한다.
Creating Cupboard1
Drawer 1 used
Cupboard1 behaves as expected
Creating Cupboard2
Drawer 2 used
Drawer 1 used
terminate called after throwing an instance of 'int'
Abort
마지막의 Abort는 프로그램이 취소되었다는 뜻이다. 원래는 Cupboard2 behaves as expected 메시지를 보여주었어야 한다.
관련된 세 클래스를 살펴 보자. Drawer 클래스는 별로 큰 특징이 없다. 단, 그의 소멸자가 예외를 던진다.
class Drawer
{
size_t d_nr;
public:
Drawer(size_t nr)
:
d_nr(nr)
{}
~Drawer()
{
cerr << "Drawer " << d_nr << " used\n";
throw 0;
}
};
Cupboard1 클래스도 역시 특징이 없다. 그저 한 개짜리 합성 Drawer 객체를 가졌을 뿐이다.
class Cupboard1
{
Drawer left;
public:
Cupboard1()
:
left(1)
{}
};
Cupboard2 클래스도 똑같이 생성된다. 그러나 합성 Drawer 객체를 두 개 가졌다.
class Cupboard2
{
Drawer left;
Drawer right;
public:
Cupboard2()
:
left(1),
right(2)
{}
};
Cupboard1의 소멸자가 호출될 때 Drawer의 소멸자가 결국 호출되어 자신의 합성 객체를 파괴한다. 이 소멸자는 예외를 던진다. 예외는 멀리 프로그램의 첫번째 try 블록에서 나포된다. 이 행위는 완전히 예상대로이다.
여기에서 미묘한 점은 생성하자마자 Cupboard1의 소멸자가 (그러므로 Drawer의 소멸자가) 곧바로 이어서 활성화된다는 것이다. 생성하자마자 그의 소멸자가 즉시 호출된다. Cupboard1()이 익명 객체를 정의하기 때문이다. 결과적으로 Beyond Cupboard1 object 텍스트는 절대로 std::cerr에 삽입되지 않는다.
예외를 던지는 Drawer의 소멸자 때문에 Cupboard2의 소멸자를 호출할 때 문제가 일어난다. 두 합성 객체 중에서 두 번째 Drawer의 소멸자가 먼저 호출된다. 이 소멸자는 예외를 던진다. 이 예외는 멀리 프로그램의 두 번째 try 블록에서 잡아야 한다. 그렇지만 그때 쯤이면 실행 흐름은 Cupboard2의 소멸자 문맥을 떠나 있는데도 그 객체는 아직 완전히 파괴되어 있지 않다. (왼쪽의) 다른 Drawer의 소멸자가 여전히 호출되고 있기 때문이다.
보통 그것은 큰 문제가 아니다. 예외가 Cupboard2의 소멸자로부터 던져지더라도 나머지 조치는 그냥 무시될 것이기 때문이다. 그럼에도 불구하고 (두 서랍 객체 모두 적절히 생성된 객체이기 때문에) left의 소멸자는 여전히 호출될 것이다.
이런 일이 여기에서도 일어난다. left의 소멸자는 예외도 던질 필요가 있다. 그러나 이미 두 번째 try 블록의 문맥을 떠났으므로 현재의 실행 흐름은 이제 완전히 뒤죽박죽이다. 프로그램은 포기하는 방법 말고는 다른 선택이 없다. 그래서 terminate()를 호출하여 끝낸다. 이 번에는 순서대로 abort()를 호출한다. 이로서 서랍 두 개 짜리 찬장은 붕괴되었다. 서랍 하나 짜리 찬장은 완벽하게 작동했지만 말이다.
여러 합성 객체가 소멸자를 떠나 예외를 던지기 때문에 프로그램은 끝난다. 이 상황에서 합성 객체 중 하나는 프로그램의 실행 흐름이 이미 그의 적절한 문맥을 떠날 즈음이면 예외를 던질 것이다. 그 때문에 프로그램은 끝나 버린다.
그러므로 C++ 표준은 다음과 같이 요구한다. 예외는 절대로 소멸자를 떠나면 안된다. 다음은 예외를 던지는 소멸자의 뼈대이다. 소멸자의 조치를 제외하고 어떤 함수 try 블록도 소멸자 몸체 아래에 있는 try 블록 안에 캡슐화되어 들어 있지 않다.
Class::~Class()
{
try
{
maybe_throw_exceptions();
}
catch (...) // 절대로 전부 잡아야 한다.
{}
}