malloc 등등의) 함수와 비교하여 C++에서 메모리 배당은 new 연산자와 delete 연산자로 처리된다. malloc과 new 사이의 중요한 차이점은 다음과 같다.
malloc 함수는 배당된 메모리가 어떻게 사용될지 알지 못한다. 예를 들어 int에 메모리를 배당하려면 프로그래머가 손수 sizeof(int)만큼 곱해서 올바른 표현식을 공급해야 한다. 대조적으로 new는 유형을 지정해 주어야 한다. sizeof 표현식은 묵시적으로 컴파일러가 처리한다. 그러므로 new를 사용하면 유형에 안전하다.
malloc으로 배당된 메모리는 calloc으로 초기화되는데, 할당된 문자들을 설정가능한 초기 값으로 초기화한다. 이 방식은 클래스의 실체를 사용할 때는 별로 유용하지 못하다. new 연산자는 할당될 실체의 유형을 알고 있기 때문에 그 실체가 보유한 생성자를 호출할 수 있다. 이 생성자는 인자로 제공할 수도 있다.
NULL이 돌아오는지 조사해야 한다. new를 사용하면 더 이상 조사하지 않아도 된다. 사실, 메모리 배당에 실패했을 때 new의 행위는 new_handler 함수를 사용하면 처리가 가능하다 (9.2.2항).
free와 delete 사이에 연관 관계가 존재한다. 실체가 할당이 해제되면 delete는 반드시 그의 소멸자를 호출한다.
실체가 생성되고 파괴될 때 생성자와 소멸자의 자동 호출은 대단히 중요하므로 이 장에서 다루고자 한다. C 프로그램 개발에서 마주하는 많은 문제들이 올바르지 못한 메모리 배당이나 메모리 누수에 의하여 야기된다. 메모리가 배당되지 않거나 해제되지 않거나 아니면 초기화되지 않거나 그도 아니면 경계선이 침범을 당하거나 등등의 문제로 야기되는 것이다. C++가 이런 문제들을 `마법처럼' 해결해 주지는 못하지만 이런 종류의 문제에 대처할 도구들을 제공해 준다.
malloc과 그 친구들의 중요성이 사라짐에 따라 자주 사용되는 str... 함수들, 예를 들어 malloc에 기반하는 strdup과 같은 함수들은 C++ 프로그램에서 피하는 것이 좋다. 대신에 string 클래스의 편의기능과 new 연산자 그리고 delete 연산자를 사용해야 한다.
메모리 배당 절차는 동적으로 자신의 메모리를 배당하는 클래스를 설계해야 하는 방식에 영향을 미친다. 그러므로 이 장에서는 new 연산자 그리고 delete 연산자와 더불어 이런 주제들을 다룬다. 먼저 new 연산자와 delete 연산자의 특이성을 다룬 후에 다음 주제를 다루어 보겠다.
this 포인터는 멤버 함수를 호출한 실체를 명시적으로 참조할 수 있다.
new 연산자와 그것을 `공유 풀'로 반납하는 delete 연산자가 정의되어 있다.
다음은 사용법을 보여주는 간단한 예이다. int 포인터 변수는 new 연산자로 배당된 메모리를 가리킨다. 이 메모리는 나중에 delete 연산자로 해제된다.
int *ip = new int;
delete ip;
다음은 new 연산자와 delete 연산자의 특징이다.
new와 delete는 연산자이다. 그러므로 괄호가 필요 없다. malloc과 free 같은 함수라면 필요하겠지만 말이다.
new는 자신의 피연산자가 요구하는 메모리의 종류를 포인터로 돌려준다 (예를 들어, int를 포인터로 돌려준다.).
new는 유형을 자신의 피연산자로 사용한다. 이 덕분에 할당될 실체의 유형이 주어지므로 필요한 메모리만큼 올바르게 배당된다.
new는 유형에 안전한 연산자이다. 왜냐하면 언제나 그의 피연산자로 언급된 유형을 포인터로 돌려주기 때문이다. 게다가 받은 포인터의 유형은 반드시 new로 지정된 유형에 일치한다.
new도 실패할 수 있지만 프로그래머에게 큰 고민거리가 되지는 않는다. 특히 프로그램은 메모리 배당이 성공했는지 검증하지 않아도 된다. malloc과 그 친구들이라면 필수이겠지만 말이다. 9.2.2항에 new의 이 측면을 깊이 다루어 보겠다.
delete는 void를 돌려준다.
new를 호출할 때마다 그에 맞는 짝으로 delete를 실행해야 한다. 그래야 메모리 누수가 일어나지 않는다.
delete는 0-포인터를 안전하게 처리한다 (아무것도 하지 않음);
delete는 오직 new로 배당된 메모리를 돌려주는 데에만 사용해야 한다. malloc과 그 친구들이 배당한 메모리를 돌려주는 데 사용하면 안 된다
malloc 함수와 그 친구들은 비추천 상태이며 사용하지 말아야 한다.
new 연산자를 사용하여 원시 유형을 배당할 수 있지만 또한 실체를 할당할 수도 있다. 원시 유형 또는 struct 유형을 소멸자 없이 배당하면 그 메모리는 0으로 초기화된다는 보장이 없다. 그러나 초기화 표현식을 공급할 수 있다.
int *v1 = new int; // 0으로 초기화된다는 보장 없음
int *v1 = new int(); // 0으로 초기화
int *v2 = new int(3); // 3으로 초기화
int *v3 = new int(3 * *v2); // 9로 초기화
클래스 유형의 실체를 할당할 때 생성자의 인자를 new표현식의 유형을 지정한 바로 다음에 지정한다. 그리고 그 실체는 그렇게 지정된 생성자로 초기화된다. 예를 들어 string 실체를 할당하려면 다음 서술문을 사용하면 된다.
string *s1 = new string; // 기본 생성자를 사용한다.
string *s2 = new string(); // 위와 같음
string *s3 = new string(4, ' '); // 4 개의 빈 공백으로 초기화.
한 실체 또는 실체 무리에 new 연산자를 사용하여 메모리를 배당하는 외에도 날 메모리를 배당하는 방식도 있다. operator new(sizeInBytes)가 그것이다. 날 메모리가 void *로 반환된다. 여기에서 new는 불특정 목적으로 한 덩어리의 메모리를 배당한다. 날 메모리가 여러 문자로 구성되어 있더라도 문자 배열이라고 해석하면 안된다. new가 돌려주는 날 메모리는 void *로 반환되므로 그의 반환 값은 void * 변수에 할당할 수 있다. 보통은 유형 변환을 이용해 char * 변수에 할당되는 경우가 더 많다. 다음은 한 예이다.
char *chPtr = static_cast<char *>(operator new(numberOfBytes));
날 메모리의 사용법은 배치 new 연산자와 연관되어 자주 보게되며 이에 관한 것은 9.1.5항에 다룬다.
new[] 연산자는 배열을 배당한다. C++ 주해서는 new[] 표기법을 사용한다. 배당된 요소의 갯수는 각 괄호 사이에 지정해야 한다. 그리고 할당될 실체의 유형을 그 앞에 지정해야 한다. 예를 들어:
int *intarr = new int[20]; // 20개의 int를 배당한다.
string *stringarr = new string[10]; // 10개의 문자열을 배당한다.
new 연산자는 new[] 연산자와 전혀 다르다. 이 차이점의 중요성을 다음 9.1.2항에 다룬다.
new[] 연산자로 배당된 배열은 동적 배열이라고 부른다. 프로그램을 실행하는 동안에 생성되며 자신이 태어난 함수의 생애보다 더 오래 생존할 수도 있다. 동적으로 배당된 배열은 프로그램이 실행되는 동안 쭉 생존할 수 있다.
new[]를 사용하여 원시 값 배열 또는 실체 배열을 할당할 때 반드시 유형을 지정해야 하고 각괄호 사이에 (무부호) 표현식을 지정해야 한다. 컴파일러는 필요한 메모리 블록을 결정하는 데 유형과 표현식을사용한다. new[]를 사용할 때 배열의 원소들은 메모리에 순차적으로 저장된다. 배열 인덱스 표현식을 사용하면 배열의 원소에 접근할 수 있다. intarr[0]는 첫 번째 int 값을 나타내며 바로 다음에 intarr[1]가 오고, 등등 마지막 원소까지 계속된다 (intarr[19]). (원시 유형이나 생성자가 없는 struct 유형과 같이) 비-클래스 유형이라면 new[] 연산자가 돌려주는 메모리 블록은 0으로 초기화된다는 보장이 없다.
new[] 연산자로 실체 배열을 할당하면 생성자가 자동으로 호출된다. 결과적으로 new string[20]은 string 실체로 초기화된 20개의 블록이다. 실체의 배열을 할당할 때 클래스의 기본 생성자는 각각의 실체를 초기화한다. 비-기본 생성자를 호출하지는 못하지만 우회할 수는 있다. 이에 관해서는 13.8절에 다룬다.
new[] 연산자에서 각괄호 사이의 표현식은 배당할 배열의 원소 갯수를 나타낸다. C++ 표준은 0-크기의 배열 배당을 허용한다. 다음 서술문 new int[0]은 C++에서 올바르다. 그렇지만 아무 의미도 없으며 혼란은 피하는 게 좋다. 아무 원소도 가리키고 있지 않으므로 의미가 없으며, 반환된 포인터가 쓸모없는 0-아닌 값을 가지므로 혼란스럽다. 값 배열을 가리킬 의도의 포인터라면 반드시 0으로 초기화해야 한다 (메모리를 아직 가리키지 않는 다른 모든 포인터와 마찬가지이다). 그래서 다음과 같은 if (ptr) ... 표현식을 사용할 수 있어야 한다.
new[] 연산자를 사용하지 않고서도 가변 크기의 배열을 지역 배열로 생성할 수 있다. 그런 배열은 동적 배열이 아니며 생존도 자신이 정의된 블록 안으로 국한된다.
일단 생성되면 모든 배열은 크기가 고정이다. 배열을 손쉽게 늘리거나 줄이는 방법은 없다. C++는 `renew' 연산자가 없다. 9.1.3절은 배열을 확장하는 법을 보여준다.
delete[] 연산자로 삭제한다. 이전에 new[] 연산자로 배당된 메모리 블록을 포인터로 기대한다.
delete[] 연산자의 피연산자가 배열 실체를 가리키는 포인터이면 두 단계의 조치가 수행된다.
std::string *sp = new std::string[10];
delete[] sp;
동적으로 배당된 배열이 삭제될 때 값이 기본 유형이라면 특별한 조치가 수행되지 않는다. 다음 int *it = new int[10]에서 서술문 delete[] it는 그냥 it가 가리키는 메모리를 돌려줄 뿐이다. 포인터는 기본 유형이므로 실체가 동적으로 배당된 포인터 배열을 삭제한다고 해서 그 배열의 원소가 가리키는 실체의 소멸자가 올바르게 호출되는 것은 아니다라는 사실을 깨닫아야 한다. 그래서 다음 예제는 메모리 누수라는 결과를 야기한다.
string **sp = new string *[5];
for (size_t idx = 0; idx != 5; ++idx)
sp[idx] = new string;
delete[] sp; // 메모리 누수!
이 예제에서 delete[]가 수행하는 유일한 조치는 문자열을 가리키는 다섯개의 포인터를 공유 풀에 돌려주는 것이다.
다음은 그런 경우 소멸자가 어떻게 수행되어야 하는지 보여준다.
delete를 호출한다.
for (size_t idx = 0; idx != 5; ++idx)
delete sp[idx];
delete[] sp;
당연한 결과로 메모리가 반환될 때까지 포인터를 사용할수 있어야 할 뿐만 아니라 그 안에 담긴 원소의 갯수도 알아야 한다. 이것은 포인터와 원소의 갯수를 저장한 다음 그 클래스의 실체를 사용하면 쉽게 달성할 수 있다.
delete[] 연산자는 delete 연산자와 전혀 다르다. 기억해야 할 제일 규칙은 new[]를 사용했다면 반드시 delete[]를 사용하라는 것이다.
renew 연산자가 없다. 배열을 확대하기 위한 절차는 다음과 같다.
#include <string>
using namespace std;
string *enlarge(string *old, unsigned oldsize, unsigned newsize)
{
string *tmp = new string[newsize]; // 더 큰 메모리 배당
for (size_t idx = 0; idx != oldsize; ++idx)
tmp[idx] = old[idx]; // old를 tmp에 복사
delete[] old; // 예전 배열을 삭제
return tmp; // 새 배열을 반환
}
int main()
{
string *arr = new string[4]; // 처음에는: 4개의 문자열 배열
arr = enlarge(arr, 4, 6); // arr을 원소 6개로 확장.
}
예제에서 보여준 확장 방식은 몇 가지 단점이 있다.
newsize 생성자를 호출하기를 요구한다.
oldsize만큼 즉시 원래 배열의 상응하는 값에 재배당된다.
new 연산자는 실체에 대하여 메모리를 배당하고 이어서 해당 실체의 생성자를 호출하여 초기화한다. 마찬가지로 delete 연산자는 실체의 소멸자를 호출하고 이어서 new 연산자가 배당했던 메모리를 공유 풀에 돌려준다.
이번 항에서 new의 또다른 사용법을 만나본다. 실체를 이른바 날 메모리(raw memory)에서 초기화할 수 있다. 날 메모리란 정적 또는 동적 배당으로 만들어진, 그냥 바이트로 구성된 메모리를 말한다.
날 메모리는 operator new(sizeInBytes)로 사용할 수 있다. 배열 종류라고 간주하면 안된다. 그저 동적으로 만들어진 일련의 메모리 위치일 뿐이다. 어쨌든 다음 new 변형은 초기화를 수행하지 않는다.
두 변형 모두 void *s를 돌려준다. 그래서 메모리로 사용하려면 정적 유형변환이 요구된다.
다음은 두 가지 예이다.
// 5 개의 int를 위한 공간 배당
int *ip = static_cast<int *>(operator new(5 * sizeof(int)));
// 앞의 예제와 같음
int *ip2 = static_cast<int *>(operator new[](5 * sizeof(int)));
// 5 개의 문자열을 위한 공간 배당
string *sp = static_cast<string *>(operator new(5 * sizeof(string)));
operator new는 데이터 유형이라는 개념이 없으므로 실체를 날 메모리에 배당할 때 의도한 데이터 유형의 크기를 명시해 주어야 한다. 그러므로 operator new는 malloc의 사용법과 닮았다.
operator new의 짝은 operator delete이다. operator delete는 (operator delete[] 역시 마찬가지로) void *를 기대한다 (그래서 유형에 상관없이 포인터를 거기에 건넬 수 있다). 포인터는 더 이상 조치 없이 공유 풀에 반납되는 날 메모리를 가리킨다. 특히, operator delete로는 소멸자가 호출되지 않는다. 그러므로 operator delete는 free의 사용법과 닮았다. 위에 언급한 ip와 sp 변수가 가리키는 메모리를 돌려주려면 operator delete를 사용해야 한다.
// operator new로 배당된 날 메모리를 삭제한다.
operator delete(ip);
operator delete(sp);
new 연산자의 눈에 띄는 형태는 배치(placement) new 연산자라고 부른다. 배치 new 연산자를 사용하려면 먼저 <memory> 헤더를 포함해야 한다.
배치 new에 기존의 메모리 블록이 건네지고 new는 그 안에 실체나 값을 초기화해 넣는다. 메모리 블록은 충분히 커서 그 실체를 담을 수 있어야 한다. 그러나 그것만 제외하면 별다른 요구 조건은 없다. Type 유형의 한 객체(실체나 변수)가 메모리를 얼마나 많이 차지하는지 쉽게 알 수 있다. sizeof 연산자는 Type 실체가 사용하는 메모리의 바이트 갯수를 돌려준다.
물론 실체는 자신이 사용하기 위해 동적으로 메모리를 배당할 수 있다. 그렇지만 그 메모리는 실체의 메모리 `발자국(footprint)'에 속하지 않는다. 그게 아니라 언제든지 그 실체가 외부적으로 사용할 수 있는 메모리이다. 이 때문에 길이가 다르고 가용능력이 다른 string 실체에 sizeof를 적용하더라도 같은 값을 돌려주는 것이다.
배치 new 연산자는 다음 구문을 사용한다 (Type을 사용하여 사용된 데이터 유형을 나타낸다):
Type *new(void *memory) Type(arguments);
여기에서 memory는 적어도 sizeof(Type) 바이트의 메모리 블록이다. 그리고 Type(arguments)는 Type 클래스의 생성자이다.
배치 new 연산자는 클래스가 나중에 사용될 메모리를 확보하는 경우에 유용하다. 예를 들어 std::string은 이것을 이용하여 자신의 가용능력을 바꾼다. string::reserve를 호출하면 가용능력이 확대된다. 문자열의 길이를 넘어서 메모리를 만들지 않아도 즉시 string 실체를 사용할 수 있다. 그러나 실체 자체는 메모리를 더 사용할 수도 있다. 예를 들어 정보가 string 실체에 추가되면 자신에게 있는 메모리를 끌어올 수 있다. 내용으로 추가된 문자 하나하나에 또다시 배당하지 않는다.
이 원칙을 std::string 실체를 저장하고 있는 Strings 클래스에 적용해 보자. 안에 string *d_memory 변수가 정의되어 있다. 이 변수가 접근하는 메모리는 d_size 길이의 문자열 객체와 더불어 d_capacity - d_size 길이의 메모리를 확보한다. 기본 생성자는 d_capacity를 1로 초기화하고 string이 추가로 저장될 때마다 d_capacity를 두 배로 만든다고 가정하면 클래스는 다음 연산을 반드시 지원해야 한다.
reserve 멤버로) 가용능력을 두 배로 만들어야 한다.
string 실체를 추가해야 한다.
Strings 실체가 존재하기를 멈추면 설치된 문자열과 메모리를 적절하게 삭제해야 한다.
d_capacity로 확대해야 한다면 비공개 void Strings::reserve 멤버가 호출된다. 다음과 같이 작동한다. 먼저 날 메모리를 새로 배당한다 (줄 1). 이 메모리는 문자열로 초기화되지 않는다. 다음 배치 new 연산자를 사용하여 예전 메모리에 있는 문자열을 새로 배당된 날 메모리에 복사한다. (줄 2). 다음으로 예전 메모리는 삭제한다 (줄 3).
void Strings::reserve()
{
using std::string;
string *newMemory = static_cast<string *>( // 1
operator new(d_capacity * sizeof(string)));
for (size_t idx = 0; idx != d_size; ++idx) // 2
new (newMemory + idx) string(d_memory[idx]);
destroy(); // 3
d_memory = newMemory;
}
append 멤버는 또다른 string 실체를 Strings 실체에 추가한다. (공개) reserve(request) 멤버는 (확대가 필요하면 reserve()를 호출하여 d_capacity를 확대하므로) String 실체의 가용능력이 충분함을 보장한다. 그 다음 배치 new를 사용하여 최근의 문자열을 날 메모리의 적절한 위치에 배치한다.
void Strings::append(std::string const &next)
{
reserve(d_size + 1);
new (d_memory + d_size) std::string(next);
++d_size;
}
String 실체가 삶을 마감할 때 그리고 연산을 확대하는 동안에 현재 사용중인 동적으로 배당된 메모리를 모두 돌려주어야 한다. 이것은 destroy 멤버의 책임이다. 클래스의 소멸자와 reserve()가 호출한다. 소멸자 자체에 관한 더 자세한 논의는 9.2절 소멸자에 다룬다. 그러나 destroy 멤버의 구현은 아래에서 연구한다.
배치 new로 흥미로운 상황을 맞이한다. 스스로 메모리를 배당할 수 있는 실체는 메모리에 배치된다. 동적으로 배당되기도 하고 아니기도 하다. 그러나 언제나 그런 실체로 완전히 채워지는 것은 아니다. 그래서 단순하게 delete[]를 사용할 수는 없다. 반면에 사용 가능한 각 실체에 대하여 delete도 사용할 수 없다. 그런 delete 연산은 동적으로 배당되지 않은 실체 자체의 메모리도 삭제하려고 하기 때문이다.
배치 new를 사용하는 상황에서만 만날 수 있는 이런 특이한 상황은 특이한 방법으로 해결한다. 배치 new를 사용하여 초기화된 실체가 점유한 메모리는 명시적으로 그 실체의 소멸자를 호출하여 반납한다. 소멸자는 아무 인자 없이 이름 앞에 물결문자를 배치한 멤버로 선언된다. 그래서 std::string의 소멸자는 이름이 ~string이다. 실체의 소멸자는 실체 자체가 배당한 메모리만 돌려준다. 그리고 이름과 상관없이 실체는 삭제하지 않는다. 그러므로 string 객체가 배당하여 Strings 클래스에 저장된 메모리는 명시적으로 소멸자를 호출하여 적절하게 파괴된다. 파괴된 후에 d_memory는 다시 원래 상태로 되돌아간다. 즉, 다시 날 메모리를 가리킨다. 그러면 이 날 메모리는 operator delete에 의하여 공유 풀에 반납된다.
void Strings::destroy()
{
for (std::string *sp = d_memory + d_size; sp-- != d_memory; )
sp->~string();
operator delete(d_memory);
}
지금까지는 그런대로 괜찮다. 딱 하나의 실체만 사용하는 한, 아무 문제가 없다. 실체 배열을 배당하면 어떻게 될까? 예와 같이 초기화가 수행된다. 그러나 delete처럼 delete[]는 버퍼가 정적으로 배당될 때 호출할 수 없다. 대신에 정적으로 배당된 버퍼와 조합하여 배치 new 연산자로 여러 실체를 초기화할때 모든 실체의 소멸자는 다음 예제와 같이 명시적으로 호출해야 한다.
using std::string;
char buffer[3 * sizeof(string)];
string *sp = new(buffer) string [3];
for (size_t idx = 0; idx < 3; ++idx)
sp[idx].~string();
exit 호출 때문에 중단되면 이미 전역 실체로 초기화된 실체의 소멸자들만 호출된다. 이런 상황에서 함수가 지역적으로 정의한 실체의 소멸자들은 자동으로 호출되지 않는다. 이 때문에 C++ 프로그램에서는 exit 함수를 사용하지 않는 것이 좋다.
소멸자는 다음의 구문 조건을 준수한다.
class Strings
{
public:
Strings();
~Strings(); // 소멸자
};
관례상 생성자가 먼저 선언된다. 다음에 소멸자가 선언되고 그 다음에 나머지 멤버 함수들이 따른다.
소멸자의 주 임무는 실체가 배당한 메모리를 실체가 소멸할 때 적절하게 반환하는 것이다. Strings 클래스의 다음 인터페이스를 연구해 보자:
class Strings
{
std::string *d_string;
size_t d_size;
public:
Strings();
Strings(char const *const *cStrings, size_t n);
~Strings();
std::string const &at(size_t idx) const;
size_t size() const;
};
생성자의 임무는 실체의 데이터 필드를 초기화하는 것이다. 예를 들어 생성자는 다음과 같이 정의된다.
Strings::Strings()
:
d_string(0),
d_size(0)
{}
Strings::Strings(char const *const *cStrings, size_t size)
:
d_string(new string[size]),
d_size(size)
{
for (size_t idx = 0; idx != size; ++idx)
d_string[idx] = cStrings[idx];
}
Strings 클래스의 실체들이 메모리를 배당하기 때문에 소멸자가 확실히 필요하다. 소멸자는 자동으로 호출될 수도 안 될 수도 있지만 소멸자는 완전히 생성된 실체에 대해서만 호출된다는 것에 주목하라 (다시 말해 동적으로 할당된 실체일 경우에만 호출해야 한다).
C++는 적어도 생성자 중 하나를 정상적으로 완료할 수 있다면 실체가 `완전하게 생성되었다'고 간주한다. 예전에는 그것이 바로 생성자였다. 그러나 C++는 생성자 위임을 지원하기 때문에 여러 생성자가 하나의 실체에 작용할 수 있다. 그러므로 `적어도 하나의 생성자'면 충분하다. 나머지 규칙은 완전하게 생성된 실체에 적용된다.
delete로 호출된다.
delete[]로 호출된다.
new로 초기화된 실체의 소멸자는 해당 실체의 소멸자를 명시적으로 호출하면 활성화된다.
Strings 소멸자의 임무는 d_string이 가리키는 메모리를 삭제하는 것이다. 그의 구현은 다음과 같다.
Strings::~Strings()
{
delete[] d_string;
}
다음 예제는 Strings가 작동하는 것을 보여준다. process에서 Strings store가 생성된다. 그리고 데이터가 화면에 표시된다. 동적으로 할당된 Strings 실체를 main에 돌려준다. Strings *은 할당된 실체의 주소를 받고 다시 그 실체를 삭제한다. 그 다음에 또다른 Strings 실체가 main에 지역적으로 마련된 메모리 블록에 생성된다. 그 실체가 배당한 메모리를 반환하려면 명시적으로 ~Strings를 호출해야 한다. 예제에서는 오직 한 번만 Strings 실체가 자동으로 파괴된다. process에 정의된 지역 Strings 실체가 그것이다. 나머지 두 Strings 실체는 메모리 누수를 방지하기 위해 명시적으로 소멸시켜야 한다.
#include "strings.h"
#include <iostream>
using namespace std;;
void display(Strings const &store)
{
for (size_t idx = 0; idx != store.size(); ++idx)
cout << store.at(idx) << '\n';
}
Strings *process(char *argv[], int argc)
{
Strings store(argv, argc);
display(store);
return new Strings(argv, argc);
}
int main(int argc, char *argv[])
{
Strings *sp = process(argv, argc);
delete sp;
char buffer[sizeof(Strings)];
sp = new (buffer) Strings(argv, argc);
sp->~Strings();
}
new 연산자는 실체나 변수를 위해 메모리를 배당하고 delete 연산자는 해제한다. malloc이나 free 같은 함수에 비하여 new와 delete 연산자는 상응하는 실체의 생성자와 소멸자를 호출한다는 장점이 있다.
new 연산자로 실체를 할당하는 작업은 두 단계이다. 먼저, 실체 자체의 메모리가 배당된다. 다음으로 그의 생성자가 호출되어 해당 실체를 초기화한다. 실체의 생성과 마찬가지로 소멸자 역시 두 단계이다. 먼저, 클래스의 소멸자가 호출되어 실체가 통제하던 메모리를 삭제한다. 다음으로 실체 자체가 차지한 메모리를 반납한다.
동적으로 배당된 배열도 new와 delete로 제어할 수 있다. new를 사용하여 배열 실체를 할당하면 배열의 각 실체마다 기본 생성자가 호출된다. 이 경우 delete[] 연산자를 사용하여 배열 안의 각 실체에 대하여 소멸자가 호출되는지 확인해야 한다.
그렇지만 new Type과 new Type[size]으로 돌려받는 주소는 유형이 같다. 두 경우 모두 Type *이다. 결과적으로 포인터의 유형만으로는 동적으로 배당된 메모리를 가리키는 포인터가 과연 하나의 실체를 가리키는지 아니면 실체 배열을 가리키는지 알 수 없다.
만약 delete[] 대신에 delete를 사용하면 무슨 일이 일어날까? 다음 상황을 생각해 보자. 소멸자 ~Strings을 변경하여 호출되었는지 알려주도록 만들어 보자. main 함수에서 두 개의 Strings 실체를 가진 배열이 new로 할당되고 delete []로 삭제될 것이다. 다음, 같은 행위를 반복한다. 단, [] 없이 delete 연산자를 호출해 보자:
#include <iostream>
#include "strings.h"
using namespace std;
Strings::~Strings()
{
cout << "Strings destructor called" << '\n';
}
int main()
{
Strings *a = new Strings[2];
cout << "Destruction with []'s" << '\n';
delete[] a;
a = new Strings[2];
cout << "Destruction without []'s" << '\n';
delete a;
}
/*
출력:
Destruction with []'s
Strings destructor called
Strings destructor called
Destruction without []'s
Strings destructor called
*/
출력을 보면 delete[]를 사용할 때 개별적으로 Strings 실체의 소멸자가 호출된다. 반면에 []를 생략하면 첫 실체의 소멸자만 호출된다.
역으로 delete를 사용해야 하는 상황에 delete[]를 호출하면 그 결과는 예측이 불가능하다. 아마도 프로그램은 충돌할 가능성이 높다. 이런 문제의 행위는 배당된 배열의 크기에 관하여 정보를 저장하는 실행 시간 시스템의 방식 때문에 야기된다 (배열의 첫 원소 바로 앞에 저장하는 것이 보통이다). 실체가 하나만 할당되었다면 배열에 종속적인 정보는 사용할 수 없지만 그럼에도 delete[]가 그 정보를 볼 수 있다고 간주한다. 그래서 후자의 이 연산자는 배열의 첫 원소 바로 앞 메모리 위치에서 엉터리 값을 맞이한다. 그 값을 성실하게 크기 정보로 번역을 하는데 그 때문에 프로그램은 충돌한다.
소멸자를 정의하지 않으면 컴파일러가 간이 소멸자를 정의해 준다. 간이 소멸자는 합성 실체들의 소멸자가 호출되는지 확인한다 (뿐만 아니라 파생클래스라면 바탕 클래스의 소멸자도 확인한다. 제 13장). 이것은 심각한 영향을 초래한다. 메모리를 배당하는 실체는 (적절한 소멸자를 정의해) 미리 조심해서 다루지 않으면 메모리 누수를 일으킨다. 다음 프로그램을 연구해 보자:
#include <iostream>
#include "strings.h"
using namespace std;
Strings::~Strings()
{
cout << "Strings destructor called" << '\n';
}
int main()
{
Strings **ptr = new Strings* [2];
ptr[0] = new Strings[2];
ptr[1] = new Strings[2];
delete[] ptr;
}
이 프로그램은 전혀 출력을 하지 않는다. 왜 그런가? ptr 변수가 포인터를 가리키는 포인터로 정의되어 있기 때문이다. 그러므로 동적으로 배당된 배열은 포인터 변수로 구성되어 있으며 포인터는 기본 유형이다. 기본 유형의 변수에는 소멸자가 존재하지 않는다. 결론적으로 배열 자체만 반환되고 Strings 소멸자는 호출되지 않는다.
물론 이것은 원하는 바가 아니다. 그게 아니라 ptr의 원소들이 가리키는 Strings 실체들도 삭제되기를 원한다. 이 경우 두 가지 선택이 있다.
ptr 배열의 모든 원소를 방문하면서 각 원소마다 delete를 호출한다. 이 절차는 이전 절에 보여준 그대로이다.
Strings과 같은 클래스의 실체를) 둘러 싸도록 설계된다. Strings 실체를 가리키는 포인터의 포인터를 사용하는 대신에 포장 클래스 실체의 배열을 가리키는 포인터가 사용된다. 결과적으로 delete[] ptr은 포장 클래스 실체의 각 소멸자를 호출하고 이어서 d_strings 멤버에 대하여 Strings 소멸자를 호출한다. 예를 들어:
#include <iostream>
using namespace std;
class Strings // 부분적으로 구현됨
{
public:
~Strings();
};
inline Strings::~Strings()
{
cout << "destructor called\n";
}
class Wrapper
{
Strings *d_strings;
public:
Wrapper();
~Wrapper();
};
inline Wrapper::Wrapper()
:
d_strings(new Strings())
{}
inline Wrapper::~Wrapper()
{
delete d_strings;
}
int main()
{
auto ptr = new Strings *[4];
// ... `new Strings'을 ptr의 원소에 할당하는 코드
delete[] ptr; // 메모리 누수: ~Strings()가 호출되지 않음
cout << "===========\n";
delete[] new Wrapper[4]; // 좋음: 소멸자가 네 번 호출됨
}
/*
출력:
===========
destructor called
destructor called
destructor called
destructor called
*/
new 연산자의 반환 값을 점검할 필요가 없다. new 연산자의 기본 행위는 다양하게 바꿀 수 있다. 그 중 하나는 메모리를 배당하지 못하면 호출될 함수를 재정의하는 것이다. 그런 함수는 다음 조건을 만족시켜야 한다.
void이다.
예를 들어 재정의된 에러 함수는 메시지를 인쇄하고 프로그램을 끝낼 수 있다. 사용자가 작성한 에러 함수는 set_new_handler 함수를 통하여 배당 시스템의 일부가 된다.
그런 에러 함수를 아래에 보여준다 (이 구현은 Gnu C/C++ 필수 요건에 적용된다. 실제로 다음 예제에 제공된 프로그램을 사용하는 것은 권장하지 않는다. 컴퓨터가 엄청나게 느려질 것이다. 운영 체제의 교체 영역을 사용하기 때문이다.):
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
void outOfMemory()
{
cout << "메모리가 고갈됨. 프로그램을 종료합니다." << '\n';
exit(1);
}
int main()
{
long allocated = 0;
set_new_handler(outOfMemory); // 에러 함수 설치
while (true) // 메모리를 모조리 소비
{
memset(new int [100000], 0, 100000 * sizeof(int));
allocated += 100000 * sizeof(int);
cout << "Allocated " << allocated << " bytes\n";
}
}
새로운 에러 함수를 설치하면 메모리를 배당하지 못할 때 자동으로 호출되어 프로그램을 종료한다. 메모리 배당은 간접적으로 호출된 코드에서도, 예를 들어 스트림을 생성하거나 사용할 때 또는 저-수준 함수로 문자열을 복제할 때도 실패할 가능성이 있다.
지금까지 이론을 설명했다. 어떤 시스템에서는 `메모리 부족' 조건까지 실제로는 도달하지 못한다. 운영 체제가 미리 손을 써 주는 덕분에 실행 시간 지원 시스템이 프로그램을 종료할 기회를 좀처럼 갖지 못하기 때문이다 (리눅스의 메모리 고갈 문제 참고).
메모리를 배당하는 (strdup, malloc, realloc 등등의) 표준 C 함수는 메모리 배당에 실패하더라도 new 처리자를 촉발시키지 않는다. 그러므로 C++ 프로그램에서는 반드시 피해야 한다.
Person 클래스를 사용해 보자:
class Person
{
char *d_name;
char *d_address;
char *d_phone;
public:
Person();
Person(char const *name, char const *addr, char const *phone);
~Person();
private:
char *strdupnew(char const *src); // src의 사본을 돌려준다.
};
// strdupnew는 쉽게 구현된다. 다음은 그의 인라인 구현이다.
inline char *Person::strdupnew(char const *src)
{
return strcpy(new char [strlen(src) + 1], src);
}
Person의 데이터 멤버는 0으로 초기화되거나 아니면 strdup류의 함수를 사용해서 Person의 생성자에 건네준 NTB 문자열 사본으로 초기화된다. 할당된 메모리는 최종적으로 Person의 소멸자가 돌려준다.
다음 예제에서 Person 실체를 사용한 결과를 연구해 보자:
void tmpPerson(Person const &person)
{
Person tmp;
tmp = person;
}
다음은 tmpPerson이 호출되면 일어나는 일이다.
person 매개변수에 Person의 참조를 기대한다.
tmp 지역 실체를 정의하는데, 그의 데이터 멤버는 0으로 초기화된다.
person을 참조하는 실체가 tmp로 복사된다. sizeof(Person) 갯수의 바이트가 person으로부터 tmp로 복사된다.
person 안의 실제 값은 할당된 메모리를 가리키는 포인터이다. 할당 후에 이 메모리는 person 그리고 두 개의 tmp 실체가 접근한다.
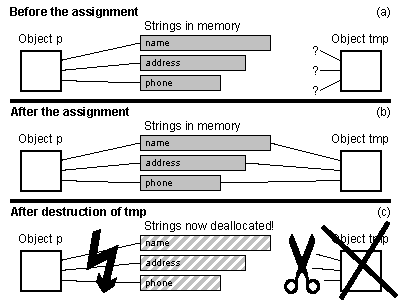
tmpPerson 함수가 종료하는 순간에 잠재적으로 심각한 위험 상황으로 발전한다. tmp는 파괴된다. Person 클래스의 소멸자는 d_name과 d_address 그리고 d_phone 필드가 가리키는 메모리를 해제한다. 그런데 불행하게도 이 메모리는 또 person도 가리키고 있다....
tmpPerson을 실행하면 person이 참조하는 실체에 삭제된 메모리를 가리키는 포인터가 담긴다.
말할 필요도 없이 이것은 tmpPerson 함수를 사용하면서 원한 효과가 아니다. 삭제된 메모리는 잇따르는 할당에 재사용될 가능성이 높다. person에 있는 포인터 멤버는 허상 포인터가 된 것이다. 더 이상 할당된 메모리를 가리키지 않기 때문이다. 일반적으로 다음과 같이 결론을 내릴 수 있다.
다행스럽게도 이런 문제를 다음에 논의하는 바와 같이 방지할 수 있다.
Person 실체를 또다른 실체에 할당하는 방법은 실체의 내용을 바이트 단위로 복사하는 것이 아니다라는 것은 분명하다. 더 좋은 방법은 상등한 실체를 만드는 것이다. 자신만의 할당된 메모리에 원래 문자열의 사본을 담고 있도록 만들면 된다.
Person 실체를 또다른 실체에 할당하는 법은 그림 5에 보여준다.
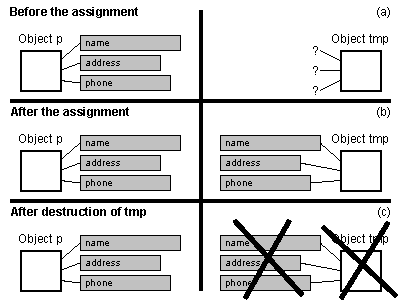
Person 실체에 또다른 실체를 할당하는 방법은 여러 가지가 있다. 한 가지 방법은 특별한 멤버 함수를 정의하여 할당을 처리하는 것이다. 이 멤버 함수의 목적은 실체의 사본을 만드는 것이다. 자신만의 이름(name)과 주소(address) 그리고 전화번호(phone) 문자열을 가진다. 다음은 그 멤버 함수이다.
void Person::assign(Person const &other)
{
// 이전에 사용된 메모리를 제거한다.
delete[] d_name;
delete[] d_address;
delete[] d_phone;
// 다른 Person의 데이터를 복사한다.
d_name = strdupnew(other.d_name);
d_address = strdupnew(other.d_address);
d_phone = strdupnew(other.d_phone);
}
assign을 사용하면 꺼림직한 tmpPerson을 재작성할 수 있다.
void tmpPerson(Person const &person)
{
Person tmp;
// tmp는 (자신만의 메모리를 보유함) person 사본을 보유한다.
tmp.assign(person);
// tmp가 소멸되어도 문제가 없다.
}
이 해결책은 유효하지만 겨우 증상만 치료할 뿐이다. 프로그래머는 할당 연산자 대신에 여전히 특정한 멤버 함수를 사용하지 않을 수 없다. 원래의 문제는 여전히 해결되지 않았다 (할당은 예측 불가능한 포인터를 양산한다). `엄격하게 규칙을 준수하는 것'은 어렵기 때문에 원래의 문제 해결 방법이 물론 더 좋다.
다행스럽게도 연산자 중복정의라는 해결책이 존재한다. C++는 주어진 문맥 안에서 연산자의 행위를 재정의할 수 있다. 연산자 중복정의는 이전에 간략하게 언급한 바 있다. 그 때 << 연산자와 >> 연산자를 재정의하여 (cin과 cout 그리고 cerr와 같은) 스트림에 사용했었다(3.1.4항).
할당 연산자를 중복정의하는 것은 아마도 C++에서 가장 일반적인 형태의 연산자 중복정의일 것이다. 그렇지만 약간 주의를 해야 한다. C++가 연산자 중복정의를 허용한다고 해서 그것이 곧 이 특징을 무분별하게 사용해도 된다는 뜻은 아니다. 다음은 꼭 명심해야 할 것들이다.
Person 클래스의 문맥에서 할당 연산자가 확실한 예이다.
std::string에서 볼 수 있다. 한 문자열 실체에 또다른 문자열을 할당하면 목표 문자열에 소스 문자열의 내용을 사본으로 제공한다. 여기에 놀라움은 없다.
int가 하는 것처럼 하라. int에 적용한 연산자의 행위는 예상한대로이지만 다른 모든 구현은 아마도 놀라움과 혼란을 야기할 것이다. 그러므로 스트림 문맥에서 삽입 연산자(<<)와 추출 연산자(>>)를 중복정의하면 거의 잘못된 선택이다. 스트림 연산은 비트별 이동 연산과 아무 공통점이 없기 때문이다.
= 할당 연산자를 중복정의하려면 operator=(Class const &rhs) 멤버를 클래스에 추가한다. 함수 이름이 두 개의 부분으로 구성되어 있음을 눈여겨보라: operator 키워드가 있고 다음에 해당 연산자가 따른다. 클래스 인터페이스에 operator= 연산자를 덧붙이면 해당 클래스에 대하여 지정한 연산자가 재정의된다. 이렇게 하면 기본 연산자가 사용되지 않는다. 기본 할당 연산자를 사용함으로써 야기되는 문제를 해결하기 위해 이전 항에서 assign 함수를 사용했다. 보통의 멤버 함수를 사용하는 대신에 C++는 전용 연산자를 사용하여 자신이 정의된 클래스의 기본 행위를 일반화하는 것이 보통이다.
앞에서 언급한 assign 멤버 함수는 다음과 같이 재정의할 수 있다 (아래에 제시된 operator= 멤버는 다듬지 않은 중복정의 할당 연산자의 첫 버전이다. 조만간 개선해 보자):
class Person
{
public: // Person 클래스를 확장
// 이전 멤버는 그대로라고 가정한다.
void operator=(Person const &other);
};
구현은 다음과 같다.
void Person::operator=(Person const &other)
{
delete[] d_name; // 예전 데이터 삭제
delete[] d_address;
delete[] d_phone;
d_name = strdupnew(other.d_name); // other의 데이터 복제
d_address = strdupnew(other.d_address);
d_phone = strdupnew(other.d_phone);
}
이 멤버의 행위는 앞에서 언급한 assign의 행위와 비슷하다. 그러나 이 멤버는 = 할당 연산자가 사용될 때마다 자동으로 호출된다. 실제로 다음 예제에 보여주는 바와 같이 중복정의 연산자를 호출하는 방법은 두 가지가 있다.
void tmpPerson(Person const &person)
{
Person tmp;
tmp = person;
tmp.operator=(person); // 위와 같음
}
중복정의 연산자는 명시적으로 호출되는 법이 드물다. 그러나 (평범한 연산자 구문을 사용하기 보다) 실체를 가리키는 포인터로부터 중복정의 연산자를 호출하고 싶다면 명시적으로 호출해야 한다 (먼저 포인터를 해제한 다음, 평범한 연산자 구문을 사용하는 것도 역시 가능하다. 다음 예제를 보라):
void tmpPerson(Person const &person)
{
Person *tmp = new Person;
tmp->operator=(person);
*tmp = person; // 좋다, 역시 가능함...
delete tmp;
}
this를 정의하여 이 실체에 다다른다.
this 키워드는 포인터 변수로서 언제나 안에 멤버 함수를 호출한 실체의 주소가 담긴다. this 포인터는 묵시적으로 각 멤버 함수마다 선언된다 (public이나 protected 또는 private). this 포인터는 멤버 함수의 클래스 실체를 가리키는 상수 포인터이다. 예를 들어 Person 클래스의 멤버는 모두 묵시적으로 다음을 선언한다.
extern Person *const this;
Person::name과 같은 멤버 함수는 this 포인터를 사용한 버전과 사용하지 않은 버전 두 가지 방식으로 구현할 수 있다.
char const *Person::name() const // 묵시적으로 `this'를 사용
{
return d_name;
}
char const *Person::name() const // 명시적으로 `this'를 사용
{
return this->d_name;
}
this 포인터는 거의 사용되지 않는다. 그러나 this 포인터가 실제로 필수인 상황이 존재한다 (제 16장).
a = b = c;
b = c 표현식이 먼저 평가되고, 이번에는 그 결과가 a에 할당된다.
지금까지 만나 본 중복정의 할당 연산자의 구현은 그런 식의 생성을 허용하지 않는다. void를 돌려주기 때문이다.
이런 불완전성은 손쉽게 치료가 가능하다. this 포인터를 사용하면 된다. 중복정의 할당 연산자는 클래스의 실체를 참조로 기대한다. 또한 그의 실체를 참조로 돌려준다. 이제 이 참조는 연속 할당에 인자로 사용된다.
중복정의 할당 연산자는 현재 실체를 참조로 돌려준다 (즉, *this를 돌려줌). 그러므로 Person 클래스에 대하여 중복정의 할당 연산자의 버전은 다음과 같이 된다.
Person &Person::operator=(Person const &other)
{
delete[] d_address;
delete[] d_name;
delete[] d_phone;
d_address = strdupnew(other.d_address);
d_name = strdupnew(other.d_name);
d_phone = strdupnew(other.d_phone);
// 현재 객체를 참조로 돌려준다.
return *this;
}
중복정의 연산자는 자신을 중복정의할 수 있다. string 클래스를 연구해 보자. 중복정의 할당 연산자 operator=(std::string const &rhs)과 operator=(char const *rhs) 그리고 다양한 중복정의 버전을 더 갖추고 있다. 이렇게 추가된 중복정의 버전은 다양한 상황을 처리하는데, 예와 같이 인자 유형으로 상황을 인지한다. 이 중복정의 버전은 모두 같은 틀을 따른다. 필요하면 실체가 제어하는 동적으로 할당된 메모리를 제거한다. 그리고 중복정의 연산자의 매개변수 값을 사용하여 새 값을 할당하고 *this를 반환한다.
Strings 클래스를 다시 한 번 연구해 보자. 이 클래스는 여러 원시 유형의 데이터 멤버와 더불어 동적으로 할당된 메모리를 포인터로 포함하고 있으므로 생성자와 소멸자 그리고 중복정의 할당 연산자가 필요하다. 실제로 이 클래스는 두 개의 생성자를 제공한다. 기본 생성자 말고도 char const *const * 그리고 size_t를 예상하는 생성자도 제공한다.
다음 조각 코드를 연구해 보자. 예제 옆에 달아 놓은 참조를 기준으로 논의한다.
int main(int argc, char **argv)
{
Strings s1(argv, argc); // (1)
Strings s2; // (2)
Strings s3(s1); // (3)
s2 = s1; // (4)
}
s1 실체는 main의 매개변수로 초기화된다. Strings의 두 번째 생성자가 사용된다.
Strings의 기본 생성자가 사용된다. 빈 Strings 실체로 초기화된다.
Strings 실체가 생성되는데 기존의 Strings 실체를 받는 생성자를 사용한다. 이런 형태의 초기화는 아직 언급하지 않았다. 이를 복사 생성이라고 부르며 초기화를 수행하는 생성자를 복사 생성자라고 부른다. 복사 생성자는 다음과 같은 형태로도 만난다.
Strings s3 = s1;
이것은 생성이며 따라서 초기화이다. 할당이 아닌 이유는 왼쪽 피연산자가 미리 정의되어 있어야 하기 때문이다. C++는 매개변수가 하나만 있더라도 생성에 할당 구문을 사용할 수 있다. 그렇지만 추천하지는 않는다.
여기에서 새롭게 복사 생성자를 만난다. 클래스 인터페이스에 선언되어 있지 않더라도 컴파일 에러를 일으키지 않는다. 그래서 다음과 같은 규칙을 얻는다.
복사 구성자는 (거의) 언제나 사용할 수 있다. 클래스의 인터페이스에 정의되어 있지 않더라도 말이다.`(거의)'라고 지정한 이유는 9.7.1항에서 알려 드리겠다.
컴파일러가 만들어 주는 복사 생성자도 역시 간이 복사 생성자라고 부른다. 그 사용법은 쉽게 억누를 수 있다 (= delete 관용구 사용). 간이 복사 생성자는 기존 실체의 원시 데이터를 새로 생성된 실체에 바이트 단위로 복사한다. 그리고 복사 생성자를 호출해 기존 실체의 상응하는 짝으로부터 그 실체의 클래스 데이터 멤버를 초기화한다. 상속이 사용된다면 바탕 클래스의 복사 생성자를 호출하여 그 새 실체의 바탕 클래스를 초기화한다.
결론적으로 위의 예제에서 간이 복사 생성자가 사용된다. 실체의 원시 데이터를 바이트 단위로 복사한다. 그것이 바로 정확하게 서술문 (3)에서 일어나는 일이다. s3이 존재하기를 멈출 때 쯤이면 소멸자가 문자열 배열을 삭제한다. 불행하게도 d_string은 원시 데이터 유형이다. 그래서 s1의 데이터도 삭제한다. 또다시 실체가 영역을 벗어난 결과로 인해 허상 포인터를 맞이한다.
치료법은 간단하다. 간이 복사 생성자를 사용하는 대신에 복사 생성자를 명시적으로 클래스 인터페이스에 추가하면 된다. 그의 정의 덕분에 허상 포인터가 방지될 것이다. 중복정의 할당 연산자에 구현했던 방식과 비슷하다. 동적으로 할당된 실체의 메모리는 복제된다. 그래서 자신만의 할당된 데이터를 가진다. 복사 생성자는 중복정의 할당 연산자보다 더 간단하다. 이전에 배당된 메모리를 제거하지 않아도 되기 때문이다. 실체가 생성되려고 할 때 이전에 배당된 메모리가 전혀 존재하지 않기 때문이다.
Strings의 복사 생성자는 다음과 같이 구현할 수 있다.
Strings::Strings(Strings const &other)
:
d_string(new string[other.d_size]),
d_size(other.d_size)
{
for (size_t idx = 0; idx != d_size; ++idx)
d_string[idx] = other.d_string[idx];
}
자신의 클래스의 또다른 실체를 사용하여 실체가 초기화될 때 언제나 복사 생성자가 호출된다. 지금까지 마주했던 간이 복사 생성 외에도 복사 생성자가 사용되는 상황이 또 있다.
void process(Strings store) // 포인터 없음, 참조 없음
{
store.at(3) = "modified"; // `outer'를 변경하지 않는다.
}
int main(int argc, char **argv)
{
Strings outer(argv, argc);
process(outer);
}
Strings copy(Strings const &store)
{
return store;
}
store는 copy의 반환 값을 초기화한다. 반환된 Strings 실체는 임시의 익명 실체이다. copy를 사용하여 코드에 즉시 사용할 수 있다. 그러나 그 다음의 그의 생애에 관해서는 어떤 가정도 할 수 없다.
소멸자를 연구하면서 보았듯이 소멸자는 명시적으로 호출할 수 있지만 (복사) 생성자에는 해당되지 않는다 (9.2절). 그러나 중복정의 할당 연산자가 무엇을 하기로 되어 있는지 간략하게 요약해 보자:
Strings &operator=(Strings const &other)
{
Strings tmp(other);
// 이후에 코드 계속
return *this;
}
operator=(String tmp) 최적화가 매력적이라고 생각하실지 모르겠다. 그러나 이에 관해서는 잠시 미루어 두자 (적어도 9.7절까지는 미루는게 좋겠다).
복사 부분을 완료했지만 지우는 부분은 어떤가? 또다른 작은 문제도 역시 있지 않은가? 어쨌거나 복사는 완료했지만 의도한 (현재의 *this) 실체는 얻지 못했다.
이 시점에서 교체를 소개한다. 두 변수를 교체하는 것은 두 개의 변수가 그 값을 교환한다는 뜻이다. 다음 절에서 더 자세하게 다루겠지만 지금 당장은 swap(Strings &other) 멤버 함수를 Strings 클래스에 추가하는 것이라고 생각해 두자. 이렇게 하면 String의 operator= 구현을 완성할 수 있다.
Strings &operator=(Strings const &other)
{
Strings tmp(other);
swap(tmp);
return *this;
}
이렇게 operator=를 구현하면 총칭적이다. 교체 능력이 있는 어떤 클래스에도 적용할 수 있다. 어떻게 작동하는가?
other 실체의 정보는 지역 tmp 실체를 초기화한다. 이렇게 하여 할당 연산자의 복사 부분을 책임진다.
swap을 호출하면 현재 실체가 그의 새로운 값을 받는다는 보장을 할 수 있다 (tmp는 현재 실체의 원래 값을 받는다.).
operator=가 끝나면 그의 지역 tmp 실체는 사망하고 소멸자가 호출된다. 이제 이전에 현재 실체가 소유했던 데이터가 담겨 있으므로 원래 데이터는 소멸되고 없다. 그리하여 할당 연산자의 파괴 부분을 효과적으로 완수한다.
swap 멤버 함수를 제공하는 클래스가 많다 (예, std::string). 이 멤버를 이용하면 두 실체를 서로 바꿀 수 있다. 표준 템플릿 라이브러리는 교체와 관련하여 다양한 함수를 제공한다 (STL에 관해서는 18장 참고). 심지어 swap 총칭 알고리즘도 있다 (19.1.61항). 할당 연산자를 사용하여 구현되는 것이 보통이다. String의 모든 데이터 멤버를 바꿀 수 있다면 Strings 클래스에 대하여 swap 멤버를 구현할 때 할당 연산자를 사용할 수 있었다. 그러므로 class Strings에 다음과 같이 swap 멤버 함수를 추가할 수 있다 (왜 그런지는 잠시 후에 논의한다):
void Strings::swap(Strings &other)
{
swap(d_string, other.d_string);
swap(d_size, other.d_size);
}
이 멤버 함수를 Strings에 추가하면 String::operator=의 복사 교체 구현을 사용할 수 있다.
두 변수를 서로 바꿀 때 (예, double one 그리고 double two) 각 변수는 교체된 후에 다른 쪽 변수의 내용을 보유한다. 그래서 one == 12.50이고 two == -3.14일 경우에 swap(one, two)를 수행하면 one == -3.14이고 two == 12.50이 된다.
(포인터나 내장 유형과 같이) 기본 데이터 유형의 변수는 당연히 교체가 가능하고 클래스 유형의 실체는 클래스에서 swap 멤버 함수를 제공하면 교체할 수 있다.
그래서 클래스에 swap 멤버 함수를 어떻게 구현해야 할 것인가?
위의 예제는 swap 멤버 함수를 구현하는 표준 방식을 보여준다 (Strings::swap): 각각의 데이터 멤버는 차례대로 교체된다. 그러나 클래스에 이런 식으로 swap 멤버 함수를 구현할 수 없는 경우가 있다. 클래스에 기본 유형의 데이터만 정의하더라도 마찬가지이다. 그림 6에 묘사된 상황을 연구해 보자.
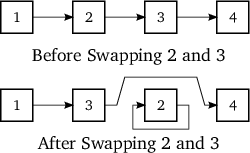
이 그림에 네 개의 실체가 있다. 각 실체마다 이웃 실체를 가리키는 포인터가 있다. 이런 클래스는 기본적으로 다음과 같은 형태가 될 것이다.
class List
{
List *d_next;
...
};
처음에 네 개의 실체는 d_next 포인터가 있다. 포인터는 이웃 실체를 가리키도록 설정되어 있다. 1은 2를, 2는 3을, 3은 4를 가리킨다. 이것이 윗쪽에 보이는 그림이다. 아래 그림은 실체 2와 실체 3이 교체되면 어떤 일이 일어나는지 보여준다. 3 실체의 d_next 포인터는 이제 실체 2를 가리키며 실체 2는 여전히 실체 4를 가리킨다. 2 실체의 d_next 포인터는 3 실체의 주소를 가리키지만 2 실체의 d_next는 이제 실체 3에 있다. 그러므로 실체 3은 자기 자신을 가리키는 셈이다. 좋지 않은 그림이다!
실체를 교체할 때 잘못될 만한 또다른 상황이 있다. 클래스가 보유한 데이터 멤버가 같은 실체의 데이터 멤버를 가리키거나 참조하는 경우가 있다. 그런 상황을 그림 7에 보여준다.
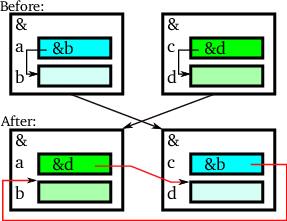
여기에서 실체는 두 개의 데이터 멤버가 있다. 다음과 같이 클래스가 설정되어 있다면:
class SelfRef
{
size_t *d_ownPtr; // &d_data로 초기화
size_t d_data;
};
그림 7의 윗쪽은 두 개의 실체를 보여준다. 윗쪽 데이터 멤버는 아랫쪽 데이터 멤버를 가리킨다. 그러나 이 실체들을 교체하면 그림의 아랫쪽에 보여주는 상황을 맞이한다. 여기에서 주소 a와 c에 있는 값이 교체된다. 그래서 아래의 데이터 멤버를 가리키지 않고 갑자기 상대 실체의 데이터 멤버들을 가리키게 된다. 역시 좋지 않은 그림이다.
이렇게 교체 연산에 실패하는 흔한 원인은 쉽게 파악된다. 데이터 멤버가 교체에 연관된 데이터를 가리키거나 참조한다면 그냥 단순히 교체하면 안된다. 만약 그림 7에서 a와 c 데이터 멤버가 두 실체의 바깥에 있는 정보를 가리킨다면 (예를 들어 동적으로 할당된 메모리를 가리킨다면) 그러면 그냥 교체해도 성공할 것이다.
그렇지만 SelfRef 실체를 교체하는데 어려움이 있다고 해서 그것이 곧 두 개의 SelfRef 실체를 서로 바꿀 수 없다는 뜻은 아니다. 단지 주의를 기울여 swap 멤버 함수를 설계해야 한다는 뜻일 뿐이다. 다음은 SelfRef::swap를 구현한 것이다.
void SelfRef::swap(SelfRef &other)
{
swap(d_data, other.d_data);
}
이 구현에서 교체는 자기 참조의 데이터 멤버를 그대로 두고 나머지 데이터만 교체한다. 비슷한 swap 멤버 함수를 연결 리스트에도 설계할 수 있을 것이다. 그림 6에 보여준다.
new 에서 보았듯이 실체는 sizeof(Class) 바이트 크기만큼의 메모리 블록을 구성할 수 있다. 그래서 두 실체가 같은 클래스이면 각각 sizeof(Class) 바이트만큼 메모리를 차지한다.
클래스의 실체들을 서로 바꿀 수 있다면 그리고 클래스의 데이터 멤버가 교체 연산에 실제적으로 연관된 데이터를 참조하지만 않는다면 이미 실체가 얼마나 큰지 알고 있다는 사실에 기반하여 아주 빠른 교체 방법을 구현할 수 있다.
이런 빠른-교체 방법에서는 sizeof(Class) 바이트만큼 내용을 서로 바꾸기만 하면 된다. 이 절차는 멤버별 교체 연산을 사용하여 자신의 실체를 바꾸어도 되는 클래스에 적용할 수 있으며 (사실, 이 방법은 C++ ANSI/ISO 표준에 기술되어 있듯이 허용된 연산을 과도하게 넘어선 것일 수 있지만 말이다) 또 참조 데이터 멤버를 가진 클래스에도 사용할 수 있다. 그냥 sizeof(Class) 바이트 크기의 버퍼를 정의하고 순환적으로 memcpy 연산을 수행한다. 다음은 Class 가상 클래스에 대하여 구현한 것이다. 그 결과 아주 빠른 교체가 가능하다.
#include <cstring>
void Class::swap(Class &other)
{
char buffer[sizeof(Class)];
memcpy(buffer, &other, sizeof(Class));
memcpy(&other, this, sizeof(Class));
memcpy(this, buffer, sizeof(Class));
}
다음은 참조 데이터 멤버를 정의하고 위와 예제와 같이 구현된 swap 멤버를 제공하는 클래스의 간단한 예이다. 참조 데이터 멤버는 외부 스트림을 가리키도록 초기화된다. 프로그램을 실행하면 one에는 두 개의 hello to 1 줄과 two에는 hello to 2 줄이 담긴다 (간결하게 Reference의 모든 멤버는 클래스 안에 정의했다):
#include <fstream>
#include <cstring>
class Reference
{
std::ostream &d_out;
public:
Reference(std::ostream &out)
:
d_out(out)
{}
void swap(Reference &other)
{
char buffer[sizeof(Reference)];
memcpy(buffer, this, sizeof(Reference));
memcpy(this, &other, sizeof(Reference));
memcpy(&other, buffer, sizeof(Reference));
}
std::ostream &out()
{
return d_out;
}
};
int main()
{
std::ofstream one("one");
std::ofstream two("two");
Reference ref1(one); // ref1/ref2는 스트림을 가리키는
Reference ref2(two); // 참조점을 가진다.
ref1.out() << "hello to 1\n"; // 출력 생성
ref2.out() << "hello to 2\n";
ref1.swap(ref2);
ref2.out() << "hello to 1\n"; // 또 출력
ref1.out() << "hello to 2\n";
}
빠른 교체는 자기-정의 클래스에만 사용해야 한다. 빠르게 교체하더라도 자신의 실체가 훼손되지 않는다고 증명할 수 있을 경우에만 사용해야 한다.
정보 이동은 (임시의) 이름없는 데이터라는 개념에 기반한다. operator-()와 같은 함수와 operator+(Type const &lhs, Type const &rhs) 그리고 일반적으로 참조나 포인터를 돌려주는 대신에 결과를 `값으로' 돌려주는 함수에 의하여 임시 값이 반환된다.
익명 값은 언제나 생애가 짧다. 반환된 데이터가 (int, double, 등등의) 기본 유형이면 특별한 일이 일어나지 않는다. 그러나 클래스 유형의 실체가 값으로 반환되면 그 값을 생산한 함수의 호출이 끝날 때 곧바로 그의 소멸자가 호출될 수 있다. 어느 경우든 그 값 자체는 호출이 끝나면 접근이 불가능하다. 물론, 임시 반환 값이 참조에 묶여 있을 수 있다 (lvalue 또는 rvalue). 그러나 컴파일러의 눈에는 이제 그 값은 이름이 있고 그래서 그 자체는 임시 값으로서의 사명을 다한다.
이 절은 이름없는 임시 값에 초점을 두고 그것을 사용하여 어떻게 효율적으로 실체를 생성하고 할당하는지 보여준다. 익명 값을 이용한 특별한 생성과 할당 방법을 이동 생성(move construction)과 이동 할당(move assignment)이라고 부른다. 이동 연산을 지원하는 클래스를 이동을 인지(move-aware)한다고 부른다.
일반적으로 자신의 메모리를 할당하는 클래스는 이동-인지로 혜택을 누릴 수 있다. 그러나 클래스는 이동 연산으로 장점을 누릴 때까지 동적으로 메모리를 할당할 필요가 없다. 합성을 사용하는 (또는 상속할 때 바탕 클래스가 합성을 사용하는) 대부분의 클래스도 역시 이동 연산으로 혜택을 누릴 수 있다.
Class 클래스에 대하여 이동이 가능한 매개변수들은 다음과 같이 Class &&tmp 형태를 취한다. 그 매개변수는 rvalue 참조이고 익명의 임시 값에만 묶인다. 가능하면 컴파일러는 이동이 가능한 매개변수를 제공하는 함수를 호출하도록 되어 있다. 클래스에 Class && 매개변수를 지원하는 클래스가 정의되어 있고 익명의 임시 값이 그런 함수로 건네질 때 이런 일이 일어난다. 임시 값이 이름이 있다면 (이미 그런 일이 Class const &이나 Class &&tmp 매개변수를 정의하고 있는 함수 안에서 일어난다. 그런 함수 안에서 이런 매개변수의 이름을 사용할 수 있기 때문이다) 더 이상 이름 없는 임시 값이 아니며 그런 함수 안에서 이동 매개변수가 인자로 사용되더라도 컴파일러는 더 이상 익명 값을 기대하는 함수를 호출하지 않는다.
(간결하게 인라인 멤버로 구현한) 다음 예제는 비-const 실체와 임시 실체 그리고 const 실체가 이런 종류의 매개변수가 정의되어 있는 fun 함수에 건네질 때 무슨 일이 일어나는지 보여준다. 이 함수들은 각각 역시 이런 종류의 매개변수가 정의된 gun을 호출한다. 맨 처음 fun이 호출되면 (예상대로) gun(Class &)을 호출한다. 다음 fun(Class &&)이 호출된다. 그의 인자가 익명의 (임시) 실체이기 때문이다. 그렇지만 fun 안에서 익명 값은 이름을 받고 그래서 더 이상 익명이 아니다. 결과적으로 gun(Class &)이 한 번 더 호출된다. 마지막으로 fun(Class const &)이 호출되고 (예상대로) gun(Class const &)이 호출된다.
#include <iostream>
using namespace std;
class Class
{
public:
Class()
{};
void fun(Class const &other)
{
cout << "fun: Class const &\n";
gun(other);
}
void fun(Class &other)
{
cout << "fun: Class &\n";
gun(other);
}
void fun(Class &&tmp)
{
cout << "fun: Class &&\n";
gun(tmp);
}
void gun(Class const &other)
{
cout << "gun: Class const &\n";
}
void gun(Class &other)
{
cout << "gun: Class &\n";
}
void gun(Class &&tmp)
{
cout << "gun: Class &&\n";
}
};
int main()
{
Class c1;
c1.fun(c1);
c1.fun(Class());
Class const c0;
c1.fun(c0);
}
일반적으로 반환 유형이 rvalue 참조인 함수를 정의하는 것은 의미가 없다. 제공된 인자에 기반하여 컴파일러는 rvalue 참조를 기대하는 중복정의 멤버를 사용할지 말지 결정한다. 익명의 임시 멤버라면 되도록이면 rvalue 참조 매개변수를 정의한 그 함수를 호출한다. 인자가 가진 rvalue 참조의 본성을 유지하기 위해 std::move를 호출하여 rvalue 참조를 반환 유형으로 사용한다. 그러므로 반환 값은 임시의 익명 실체가 될 것이다. 이런 상황을 함수에 임시 실체를 건네야 할 (그리고 반환해야 할) 상황에도 활용할 수 있다. 해당 함수는 그 임시 실체를 변경할 수 있어야 한다. const &를 건네는 대안은 별로 매력적이지 않다. 실체를 변경하려면 먼저 const_cast를 요구하기 때문이다. 다음은 한 예이다.
std::string &&doubleString(std::string &&tmp)
{
tmp += tmp;
return std::move(tmp);
}
이것으로 다음과 같은 일을 할 수 있다.
std::cout << doubleString(std::string("hello "));
hello hello 를 cout에 삽입한다.
컴파일러는 호출할 함수를 선택할 때 매우 단순한 알고리즘을 적용하고 복사를 생략할 수 있는지 고려한다. 잠시 후에 이에 관하여 다룬다 (9.8절).
Strings 클래스는 멤버 중에서도 string *d_string 데이터 멤버가 있다. Strings는 복사 생성자와 소멸자 그리고 중복정의 할당 연산자를 정의해야 한다.
다음 loadStrings(std::istream &in) 함수를 연구해 보자. Strings 실체에게 건넬 문자열을 in으로부터 추출한다. 다음, loadStrings에 의해서 채워진 Strings 실체가 반환된다. loadStrings 함수는 임시 실체를 돌려준다. 그러면 이를 이용하여 외부의 Strings 실체를 초기화할 수 있다.
Strings loadStrings(std::istream &in)
{
Strings ret;
// 문자열들을 'ret' 안에 적재한다.
return ret;
}
// 사용법:
Strings store(loadStrings(cin));
이 예제에서 두 Strings 실체의 완전한 사본이 필요하다.
Strings ret 실체로부터 loadString 값의 반환 유형을 초기화한다.
loadString의 반환 값으로부터 store를 초기화한다.
Strings 클래스의 이동 생성자 선언이다.
Strings(Strings &&tmp);
동적으로 메모리를 할당하는 클래스의 이동 생성자는 포인터 데이터 멤버의 값을 자신의 포인터 데이터 멤버에 할당할 수 있다. 소스 데이터의 사본을 요구하지 않는다. 다음, 임시 포인터 값은 0으로 설정되어 이제는 방금 생성한 실체가 소유한 그 데이터를 소멸자가 파괴하지 못하도록 방지한다. 이동 생성자는 임시 실체로부터 그 데이터를 강탈했거나 아니면 훔쳤지만, 이것은 문제가 되지 않는다. 임시 실체는 다시 참조할 수 없기 때문이다 (익명이기 때문에 다른 코드가 접근할 수 없다). 그리고 임시 실체는 생성자가 호출되면 곧바로 소멸해 버리기 때문이다. 다음은 Strings의 이동 생성자를 구현한 것이다.
Strings::Strings(Strings &&tmp)
:
d_memory(tmp.d_memory),
d_size(tmp.d_size),
d_capacity(tmp.d_capacity)
{
tmp.d_memory = 0;
}
9.5절에 복사 생성자는 거의 언제든지 사용할 수 있다고 서술한 적이 있다. 거의 언제든지라고 언급한 이유는 이동 생성자를 선언하면 복사 생성자의 기본 기능을 억제하기 때문이다. 기본 복사 생성자는 이동 할당 연산자가 선언되는 경우에도 억제된다 (9.7.3항).
다음 예제는 이동 생성자를 선언한 Class 클래스를 간략하게 보여준다. 클래스 인터페이스 다음의 main 함수에 Class 실체가 정의된다. 다음 두 번째 Class 실체의 생성자에 건네진다. 컴파일은 다음 에러를 보고하며 실패한다.
error: cannot bind 'Class' lvalue to 'Class&&'
error: initializing argument 1 of 'Class::Class(Class&&)'
class Class
{
public:
Class() = default;
Class(Class &&tmp)
{}
};
int main()
{
Class one;
Class two(one);
}
치료법은 간단하다. (default 가능) 복사 생성자를 선언하면 에러 메시지는 사라진다.
class Class
{
public:
Class() = default;
Class(Class const &other) = default;
Class(Class &&tmp)
{}
};
int main()
{
Class one;
Class two(one);
}
합성된 데이터 멤버의 클래스 유형이 이동이나 복사를 지원하지 않으면 이동 연산을 구현할 수 없다. 따라서 stream 클래스는 이 범주에 들지 못한다.
이동-인지 클래스의 예는 std:string 클래스이다. Person 클래스는 std::string d_name과 std::string d_address를 정의함으로써 합성을 사용할 수 있다. 그의 이동 생성자는 원형이 다음과 같다.
Person(Person &&tmp);
그렇지만 이동 생성자를 다음과 같이 구현하는 것은 올바르지 않다.
Person::Person(Person &&tmp)
:
d_name(tmp.d_name),
d_address(tmp.d_address)
{}
string의 이동 생성자가 아니라 복사 생성자가 호출되기 때문이다. 왜 이런 일이 일어나는지 궁금하시다면 이동 연산은 오직 익명 실체에 대해서만 수행된다는 사실을 명심하라. 컴파일러의 눈에는 무엇이든 이름이 있으면 익명이 아니다. 그래서 묵시적으로 rvalue 참조를 사용할 수 있다고 해서 그것이 곧 익명 실체를 참조하고 있다는 뜻은 아니다. 그러나 이동 생성자는 익명 인자에 대해서만 호출된다는 사실을 우리는 알고 있다. 상응하는 string 이동 연산을 사용하려면 익명 데이터 멤버에 관하여 언급하고 있다는 사실도 컴파일러에게 알려줄 필요가 있다. 이 목적을 위해 (예를 들어 static_cast<Person &&>(tmp)와 같이) 유형을 변환할 수도 있겠지만 C++-0x 표준은 std::move를 제공해 이름 있는 실체의 이름을 없애준다. 그러므로 올바르게 Person의 이동 생성을 구현하면:
Person::Person(Person &&tmp)
:
d_name( std::move(tmp.d_name) ),
d_address( std::move(tmp.d_address) )
{}
std::move 함수는 (간접적으로) 많은 헤더 파일에 선언되어 있다. 헤더 파일에 std::move가 정의되어 있지 않다면 utility 헤더를 반입하면 된다.
합성을 사용하는 클래스가 클래스 유형의 데이터 멤버는 물론이고 다른 유형의 데이터(포인터나 참조 또는 원시 데이터 유형)도 포함하고 있을 때 이 다른 데이터 유형을 평소대로 초기화할 수 있다. 기본 유형의 데이터 멤버는 그냥 복사하면 된다. 참조는 평소대로 초기화하면 된다. 이전 절에 논의한 바와 같이 포인터도 이동 연산을 사용할 수 있기 때문이다.
컴파일러는 이름이 있는 변수에 대해서는 절대로 이동 연산을 호출하지 않는다. 이 말이 무슨 뜻인지 다음 예제를 살펴 보면서 연구해 보자. Class는 이동 생성자와 복사 생성자를 제공한다고 간주한다.
Class factory();
void fun(Class const &other); // a
void fun(Class &&tmp); // b
void callee(Class &&tmp);
{
fun(tmp); // 1
}
int main()
{
callee(factory());
}
fun의 인자는 이름 없는 임시 실체가 아니고 이름 있는 임시 실체이다.
fun(tmp)가 두 번 호출될 수 있다는 사실을 알고 있으므로 그 선택은 이해할 만 하다. 만약 tmp의 데이터가 첫 번째 호출에서 잡혔다면 두 번째 호출은 아무 데이터가 없는 tmp를 받게 될 것이다. 그러나 마지막 호출에서 tmp가 다시 사용되지 않음을 알았고 그래서 fun(Class &&)이 호출되는 것을 확인하고 싶다. 이 때문에 다시 또 std::move가 사용된다.
fun(std::move(tmp)); // 마지막 호출이다!
Class &operator=(Class &&tmp)
{
swap(tmp);
return *this;
}
교체를 지원하지 않으면 데이터 멤버 각각에 대하여 순서대로 할당할 수 있다. 앞 절에서 Person 클래스에 보여준 바와 같이 std::move를 사용하면 된다. 다음은 Person 클래스에 대하여 구현하는 방법을 보여준다.
Person &operator=(Person &&tmp)
{
d_name = std::move(tmp.d_name);
d_address = std::move(tmp.d_address);
return *this;
}
앞서 지적했듯이 (9.7.1항) 이동 할당 연산자를 선언하면 기본적으로 복사 생성자를 억제한다. 다시 사용하려면 복사 생성자를 클래스 인터페이스 안에 선언하면 된다 (물론 명시적으로 구현하거나 = default 기본 구현을 제공하면 된다).
Class 클래스에 대한 구현을 다시 한 번 들여다보자. 그의 swap 멤버를 이용하여 교체를 지원하자. 다음은 중복정의 할당 연산자를 총칭적으로 구현한 것이다.
Class &operator=(Class const &other)
{
Class tmp(other);
swap(tmp);
return *this;
}
그리고 다음은 이동-할당 연산자이다.
Class &operator=(Class &&tmp)
{
swap(tmp);
return *this;
}
모습이 너무나 비슷하다. other 실체의 사본을 사용할 수 있다면 중복정의 할당 연산자의 코드가 이동-할당 연산자의 코드와 동일하다. 중복정의 할당 연산자의 tmp 실체는 실제로는 그저 Class의 임시 실체에 불과하므로 이 사실을 이용하여 이동-할당의 관점에서 중복정의 할당 연산자를 구현할 수 있다. 다음은 중복정의 할당 연산자의 두 번째 구현이다.
Class &operator=(Class const &other)
{
Class tmp(other);
return *this = std::move(tmp);
}
클래스가 데이터 멤버를 포인터로 정의하면 이동될 포인터만 있는게 아니라 포인터 배열의 원소 갯수를 정의한 size_t도 있다.
Strings 클래스를 다시 한 번 연구해 보자. 소멸자는 다음과 같이 구현되어 있다.
Strings::~Strings()
{
for (string **end = d_string + d_size; end-- != d_string; )
delete *end;
delete[] d_string;
}
이동 생성자는 (그리고 이동 연산자는!) 소멸자가 d_string만 삭제하는게 아니라 d_size도 고려하고 있음을 깨닫아야 한다. 그러므로 이동 연산을 구현한 멤버는 d_string을 0으로 설정해야 할 뿐만 아니라 d_size도 0으로 설정해야 한다. 그러므로 Strings를 위하여 이전에 보여준 이동 생성자는 올바르지 않다.
Strings::Strings(Strings &&tmp)
:
d_memory(tmp.d_memory),
d_size(tmp.d_size),
d_capacity(tmp.d_capacity)
{
tmp.d_memory = 0;
tmp.d_size = 0;
}
d_string이 0-아닌 값을 가지는 것에 모든 소멸자 연산이 의존하고 있다면 물론 위의 접근법을 변경하는 것도 가능하다. 이동 연산은 그저 d_memory을 0으로 설정할지 말지 결정할 수 있을 뿐이다. 그리고 소멸자에서 d_memory == 0인지 테스트해 보고 (그렇다면 소멸자의 조치를 끝낸다), 약간의 d_size 할당을 절약할 수 있을 뿐이다.
// 다음이 있다고 간주함: char *filename
ifstream inStream(openIstream(filename));
이 예제가 ifstream 스트림 생성자를 작동시키려면 이동 생성자를 제공해야 한다. 그러면 열린 istream 스트림을 가리키는 실체는 오직 하나 뿐이라고 보장할 수 있다.
클래스가 이동 의미구조를 제공하면 그의 실체도 안전하게 표준 컨테이너에 저장할 수 있다 (제 12장). 그런 컨테이너가 재할당을 수행하면 (예를 들어 크기를 확대할 경우) 그 실체의 복사 생성자가 아니라 이동 생성자를 사용한다. 이동-전용 클래스는 복사 의미구조를 억제하기 때문에 이동-전용 클래스의 실체를 저장한 컨테이너는 그런 컨테이너를 서로 할당할 수 없다는 점에서 올바른 행위를 구현한다.
컴파일러는 이동 생성자와 이동 할당 연산자에 대하여 기본 구현을 제공할 수 있다. 그렇지만 기본 생성자와 할당 연산자를 언제나 제공할 수 있는 것은 아니다.
다음은 컴파일러가 제공해야 할지 말지 결정할 때 적용하는 규칙이다.
복사 생성자나 이동 생성자 또는 할당 연산자의 기본 구현이 억제되지만 꼭 필요한 경우가 있다. 그런 경우 필요한 서명을 지정하고 `= default'를 지정하기만 하면 기본 구현을 쉽게 제공할 수 있다.
다음은 모든 기본 멤버를 제공하는 클래스의 예이다. 생성자, 복사 생성자, 이동 생성자, 할당 연산자와 이동 할당 연산자:
class Defaults
{
int d_x;
Mov d_mov;
};
Mov가 표준의 깊은 복사 연산 말고도 이동 연산을 제공하는 클래스라고 가정하고 다음 조치를 목표의 d_mov와 d_x에 수행한다.
Defaults factory();
int main()
{ Mov operation: d_x:
---------------------------
Defaults one; Mov(), undefined
Defaults two(one); Mov(Mov const &), one.d_x
Defaults three(factory()); Mov(Mov &&tmp), tmp.d_x
one = two; Mov::operator=( two.d_x
Mov const &),
one = factory(); Mov::operator=( tmp.d_x
Mov &&tmp)
}
그렇지만 Defaults가 생성자를 적어도 하나 (아마도 복사 생성자일 것이다) 그리고 할당 연산자 하나를 선언하고 있다면 오직 그런 멤버와 복사 생성자만 사용이 가능하다. 예를 들어:
class Defaults
{
int d_x;
Mov d_mov;
public:
Defaults(int x);
Defaults operator=(Defaults &&tmp);
};
Defaults factory();
int main()
{ Mov operation: resulting d_x:
--------------------------------
Defaults one; ERROR: not available
Defaults two(one); Mov(Mov const &), one.d_x
Defaults three(factory()); ERROR: not available
one = two; ERROR: not available
one = factory(); Mov::operator=( tmp.d_x
Mov &&tmp)
}
기본값을 재설정하려면 = default를 적절한 선언 뒤에 추가하라:
class Defaults
{
int d_x;
Mov d_mov;
public:
Defaults() = default;
Defaults(Defaults &&tmp) = default;
Defaults(int x);
// Default(Default const &) 여전히 사용 가능함
Defaults operator=(Defaults const &rhs) = default;
Defaults operator=(Defaults &&tmp);
};
기본을 구현할 때 주의하라. 기본 구현은 소스 실체로부터 목표 실체에 원시 유형의 데이터 멤버를 바이트 단위로 복사하기 때문이다. 이것은 포인터 유형의 데이터 멤버에 문제를 일으킬 가능성이 높다.
= default 접미사는 클래스의 공개 구역에 생성자나 할당 연산자를 선언할 경우에만 사용할 수 있다.
이전 항에서 이동-인지 클래스에 적용할 수 있는 중요한 설계 원칙을 만나 보았다.
멤버 함수가 클래스의 const & 실체를 받고 거기에 실제로 조치하기 위해 그 실체의 사본을 만들 때마다 그 함수를 rvalue 참조를 기대하는 중복정의 함수로 구현할 수 있다.
앞의 함수는 거기에 std::move(tmp)를 건네어 뒤의 함수를 호출할 수 있다. 이 설계 원칙의 장점은 명백하다. 오직 하나의 구현만 실제로 작동한다. 그리고 그 클래스는 해당 함수에 관련하여 자동으로 이동-인지 클래스가 된다.
이 원칙을 사용하는 최초의 예제를 9.7.4 항에서 보았다. 물론 이 원칙은 복사 생성자 자체에 적용할 수는 없다. 사본을 만들려면 복사 생성자가 필요하기 때문이다. 복사 생성자와 이동 생성자는 언제나 따로 서로 독립적으로 구현해야 한다.
아래에 두 개의 표를 보여준다. 첫 번째 표는 함수 인자에 이름이 있을 때 사용되고 두 번째 표는 인자가 익명일 때 사용된다. 각 표에서 상수 또는 비-상수 컬럼을 선택한 다음, 지정된 매개변수 유형을 가진 상단의 중복정의 함수를 사용하라.
표는 값 매개변수를 정의한 함수를 다루지 않는다. 함수에 중복정의 함수가 있어서 각각, 값 매개변수와 어떤 형태의 참조 매개변수를 기대하면 컴파일러는 그런 함수를 호출할 때 모호하다고 보고한다. 다음 선택 절차에서 일반성을 잃지 않고서 다음과 같이 간주할 수 있다. 즉, 이런 모호성은 일어나지 않으며 모든 매개변수 유형은 참조 매개변수이다.
유형이 T인 함수의 인자에 부합하는 매개변수 유형은 다음과 같다. 인자가 다음과 같다면:
| 인자는 다음과 같다. | ||
| non-const | const | |
| 제일 먼저 사용한다 | (T &) | |
| 가능한 함수 | (T const &) | (T const &) |
int x 인자에 대하여 fun(int const &) 함수가 아니라 fun(int &) 함수가 선택된다. fun(int &) 함수가 없다면 fun(int const &) 함수가 사용된다. 둘 다 없다면 (그리고 대신에 fun int가 아직 정의되어 있지 않다면) 컴파일러는 에러를 보고한다.
| 인자는 다음과 같다. | ||
| non-const | const | |
| 가장 먼저 사용한다 | (T &&) | |
| 가능한 함수 | (T const &&) | (T const &&) |
| 가능한 함수 | (T const &) | (T const &) |
int arg() 함수의 반환 값이 다양한 중복정의 버전을 보유한 fun 함수에 건네지면 fun(int &&)가 선택된다. 이 함수는 없지만 fun(int const &) 함수는 있다면 뒤의 함수가 사용된다. 이 두 함수가 모두 없다면 컴파일러는 에러를 보고한다.
T const & 매개변수를 지정한 함수에 사용할 수 있다. 익명 인자에 대하여 우선 순위가 높은 순서대로 비슷하게 모두 잡을 수 있다. T const &&는 익명 인자이면 무엇이든 부합한다. 이 서명을 가진 함수는 일반적으로 정의되어 있지 않다. 그 구현이 T const & 매개변수를 기대하는 함수의 구현과 동일하(여야 하)기 때문이다. 익명 실체는 변경할 수가 없기 때문에 T const && 매개변수를 정의한 함수는 익명 실체의 자원을 복사하는 방법 말고는 대안이 없다. 이 작업은 이미 T const & 매개변수를 기대하는 함수가 수행했기 때문에 T const && 매개변수를 기대하는 함수를 구현할 필요가 없다.
이미 보았듯이 이동 생성자는 익명 실체로부터 따로 정보를 얻는다. 익명 실체는 어쨋거나 그 이후에 파괴될 것이기 때문에 문제가 없다. 또한 익명 실체의 데이터 멤버가 변경된다는 뜻이기도 하다.
복사/이동 생성자를 정의했는데 놀랍게도 컴파일러는 복사 또는 이동 연산을 제거하기로 결정할 수도 있다. 결국 복사도 없고 이동도 없는 쪽이 더 효율적이기는 하다.
컴파일러가 사본 만들기를 (또는 이동 연산을 수행하기를) 피해야 하는 옵션을 복사 생략 또는 반환 값 최적화라고 부른다. 복사나 이동 생성이 적절한 모든 상황에 컴파일러는 복사 생략을 적용할 수도 있다. 다음은 그 규칙이다. 컴파일러는 다음 옵션을 고려한다. 기로에 설 때마다 한 번씩 멈춰서 선택할 수 있다.
class Elide;
Elide fun() // 1
{
Elide ret;
return ret;
}
void gun(Elide par);
Elide elide(fun()); // 2
gun(fun()); // 3
ret는 전혀 존재하지 않을 수도 있다. ret를 사용하는 대신에 그리고 ret을 fun의 반환 값에 복사하는 대신에 fun의 반환 값을 담기 위해 사용된 곳을 직접적으로 사용할 수도 있다.
fun의 반환 값은 전혀 존재하지 않을 수도 있다. fun의 반환 유형을 담을 곳을 정의하는 대신에 그리고 그 반환 값을 elide에 복사하는 대신에 컴파일러는 fun의 반환 값을 담기 위하여 elide를 사용하기로 결정할 수도 있다.
gun의 par 매개변수에 같은 결정을 내릴 수도 있다. fun의 반환 값은 직접적으로 par의 구역에 생성된다. 그래서 fun의 반환 값을 par로 복사하지 않는다.
double과 bool 그리고 std::string을 반환할 필요가 있다면 이 세 가지 다른 유형은 struct를 사용해 모을 수 있다. 이 경우 구조체는 그저 값을 모아서 건네기 위해 존재한다. 데이터 보호와 기능성은 거의 문제가 되지 않는다. 그런 경우 C와 C++는 구조체(structs)를 사용한다. 그러나 C++의 구조체(struct)는 특별한 접근 권한을 가진 클래스(class)이기 때문에 어떤 멤버는 (생성자와 소멸자 그리고 중복정의 할당 연산자가) 묵시적으로 정의된다. 평범한 구형 데이터는 그의 정의가 되도록이면 간단하게 유지되도록 요구함으로써 이 개념을 활용한다. Pod는 다음과 같은 특징을 가지는 구조체 또는 클래스로 간주한다.
표준 레이아웃 클래스 또는 구조체는
게다가 클래스 파생이라는 문맥에서 (제 14 장과 13장), 표준 레이아웃 클래스 또는 구조체는 다음과 같은 특징이 있다.
동적으로 할당된 메모리를 가리키는 포인터 데이터 멤버를 가진 데이터는 메모리 누수의 잠재적인 근원이다. 그 메모리를 클래스의 실체들이 통제하기 때문이다. 이 장에서 소개한 확장들은 그런 메모리 누수를 막기 위한 표준적인 방어 방법을 구현한다.
(데이터를 은닉하는) 캡슐화로 실체의 데이터 정합성이 유지된다고 확신할 수 있다. 자동으로 생성자와 소멸자가 활성화되므로 메모리를 동적으로 할당하는 실체들의 데이터 정합성을 보장하는 능력이 크게 개선되었다.
그러므로 간단하게 결론을 내리자면 실체들이 자신의 통제하에 메모리를 할당하려면 적어도 소멸자와 중복정의 할당 연산자 그리고 선택적으로 복사 생성자를 구현해야 한다. 이동 생성자의 구현은 선택적이지만 클래스에 공장 함수를 사용할 수 있어서 복사 생성 또는 할당을 허용하지 않을 수 있다.
마지막으로, 최소한 복사 또는 이동 생성자의 능력이 있다고 간주하고서 컴파일러는 복사 생략(copy elision)을 사용하여 복사나 생성을 피할 수도 있다. 컴파일러는 가능하면 자유롭게 복사 생략을 사용한다. 그렇지만 필수는 아니다. 그러므로 컴파일러는 복사 생략을 사용하지 않기로 결정할 수도 있다. 그렇지 않으면 복사 또는 이동 생성자가 사용되었을 거라고 짐작되는 모든 상황에서 컴파일러는 언제나 복사 생략의 사용을 고려할 것이다.