main 함수가 있고 다음에 main 함수가 호출하는 또 한 수준의 함수가 있다.
C++에서 코드와 데이터 사이의 관계도 역시 클래스 사이의 의존 관계라는 관점에서 자주 정의된다. 이것은 마치 합성 처럼 보인다 (7.3절). 합성이란 클래스의 실체들이 또다른 클래스의 실체를 데이터로 포함하는 것이다. 그러나 여기에 기술된 관계는 종류가 다르다. 클래스는 기존 클래스의 관점에서 정의할 수 있다. 이렇게 하면 새 클래스가 생산된다. 예전 클래스의 모든 기능을 보유하고 거기에다 자신만의 기능을 덧붙여 정의한다. 주어진 클래스가 또다른 클래스를 포함하는 합성이 아니라 여기에서는 파생을 가리킨다. 파생으로 주어진 클래스는 또다른 클래스이거나 또는 또다른 클래스의 관점에서 재구현된 클래스이다.
파생을 이르는 또다른 용어는 상속(inheritance)이다. 새 클래스는 기존 클래스의 기능을 상속받는다. 반면에 기존의 클래스는 새 클래스의 인터페이스에 데이터 멤버로 나타나지 않는다. 상속을 언급할 때 기존의 클래스는 바탕 클래스(base class)라고 부르는 반면에 새 클래스는 파생 클래스(derived class)라고 부른다.
C++ 프로그램 개발 방법을 최대한 이용할 때 클래스를 파생시켜 사용한다. 이 장은 먼저 C++가 클래스 파생을 위해 제공하는 구문을 연구한다. 그 다음에 클래스 파생(상속)으로 얻을 수 있는 구체적인 가능성을 몇 가지 다루어 보겠다.
소개를 위한 장에서 보았듯이 (2.4절) 문제 해결에 객체-지향적으로 접근할 때 클래스는 문제 분석을 하는 동안 가려진다. 이런 접근법으로 정의된 클래스의 실체들은 당면한 문제에서 관찰될 수 있는 실체들을 나타낸다. 클래스는 계통적으로 배치되어 기본 기능이 최상위 클래스에 포함된다. 파생될 때마다 (그러므로 클래스 계통도에서 내림차순으로) 기존의 클래스에 비하여 기능이 새로 추가된다.
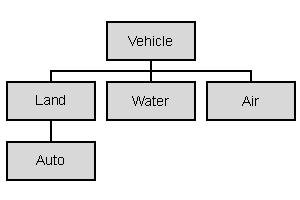
이 장에서는 간단한 운송 분류 시스템을 위한 클래스 계통도를 구축해 본다. 첫 클래스는 Vehicle이다. 운송 수단의 짐을 설정하고 열람할 수 있도록 기능을 구현한다. 객체 계통도에서 다음 수준은 육상과 수상 그리고 공중 운송 수단이다.
최초의 객체 계통도는 그림 13에 보여준다.
이 장은 주로 클래스 파생의 기술적 측면에 초점을 둔다. 바탕 클래스의 관점에서 파생 클래스를 구현하는 상속과 그리고 객체를 바탕 클래스의 실체로 간주하는 파생 클래스를 만드는 상속 사이의 차이점은 다음 장까지 미룬다 (제 14장).
상속은 클래스와 구조체에 사용할 수 있는 공용체에는 정의되어 있지 않다 (다형성은 제 14장 참고).
Car)는 육상 운송 수단(Land)의 특별한 사례이고 또 운송 수단(Vehicle)의 특별한 사례이다.
Vehicle 클래스는 분류 시스템에서 `최대 공약수'를 대표한다. Vehicle은 기본 기능만 있다. 운송 수단의 짐을 열람하고 저장하는 일만 한다.
class Vehicle
{
size_t d_mass;
public:
Vehicle();
Vehicle(size_t mass);
size_t mass() const;
void setMass(size_t mass);
};
이 클래스를 사용하면 상응하는 실체가 생성되자마자 바로 운송 수단의 짐을 정의할 수 있다. 나중에 짐을 바꾸거나 열람할 수 있다.
육상 운송 수단을 대표하기 위해 Land 클래스를 새로 정의해 Vehicle의 기능을 제공하면서 자신만의 기능을 덧붙일 수 있다. 짐과 더불어 육상 운송 수단의 속도에 관심이 있다고 해보자. Vehicle과 Land 사이의 차이점은 물론 합성으로 나타낼 수 있지만 그러기에는 좀 어색하다. 합성과는 달리 Land 운송 수단은 컨테이너, 즉 Vehicle의 관점에서 재구현된다. 그러므로 Land 운송 수단은 Vehicle의 한 종류이다(is)라는 관계가 더 자연스럽다 .
합성의 관점에서 보면 Land 클래스의 디자인이 약간 더 복잡해질 수 있다. 다음 예제를 생각해 보자. 합성을 사용하는 Land 클래스를 보여준다 (setMass 기능만 보여준다).
class Land
{
Vehicle d_v; // 합성된 Vehicle
public:
void setMass(size_t mass);
};
void Land::setMass(size_t mass)
{
d_v.setMass(mass);
}
합성을 사용하여 Land::setMass 함수는 인자를 Vehicle::setMass에 건넬 뿐이다. 그리하여 짐 처리에 관한 한, Land::setMass는 기능을 따로 더 도입하지 않고 그저 약간의 코드를 추가했을 뿐이다. 확실히 이 코드는 중복이 과도하다. 왜냐하면 Land 객체는 Vehicle이기(is) 때문에 Land 객체가 Vehicle 객체를 포함한다고 서술하는 것은 약간 이상하다.
의도한 관계는 상속이 더 잘 나타낸다. 상속과 합성 사이에 선택할 때 제일 원칙은 is-a와 has-a 관계를 구별하는 것이다. 트럭은 운송 수단이다(is). 그래서 Truck은 Vehicle로부터 파생시켜야 한다. 반면에 트럭은 엔진을 가진다(has). 시스템에 엔진이 필요하면 Engine 클래스를 Truck 클래스 안에 합성하여 이를 표현해야 할 것이다.
위의 제일 원칙을 따라 Land 클래스는 Vehicle 바탕 클래스로부터 파생시킨다.
class Land: public Vehicle
{
size_t d_speed;
public:
Land();
Land(size_t mass, size_t speed);
void setspeed(size_t speed);
size_t speed() const;
};
클래스를 또다른 클래스로부터 파생시키려면 (예를 들어 Vehicle로부터 Land 클래스를 파생시키려면) 클래스 이름 Land 다음의 인터페이스에 다음과 같이 : public Vehicle을 덧붙이면 된다.
class Land: public Vehicle
Land 클래스는 Vehicle 바탕 클래스의 모든 기능은 물론 자신만의 특징도 지닌다. 그 특징은 두 개의 인자를 기대하는 생성자 하나와 d_speed 데이터 멤버에 접근하는 멤버 함수이다. 다음은 Land 파생 클래스의 능력을 보여주는 예이다.
Land veh(1200, 145);
int main()
{
cout << "Vehicle weighs " << veh.mass() << ";\n"
"its speed is " << veh.speed() << '\n';
}
이 예제는 파생으로 얻는 특징을 두 가지 보여준다.
Land의 인터페이스에 mass 데이터 멤버가 언급되어 있지 않다. 그런데도 veh.mass에 사용된다. 이 멤버 함수는 `부모' 운송 수단으로부터 상속받아 묵시적으로 포함되어 있다.
Land 파생 클래스에 Vehicle의 기능이 포함되어 있지만 Vehicle의 비밀 멤버는 여전히 비밀로 유지된다. Vehicle 자신의 멤버 함수만 접근할 수 있다. 다시 말해 Land의 멤버 함수는 반드시 (mass와 setMass처럼) Vehicle의 멤버 함수를 사용해야만 mass 필드에 접근할 수 있다는 뜻이다. Land에 부여된 접근 권한과 Vehicle 클래스 밖의 다른 코드에 부여된 접근 권한 사이에 아무 차이가 없다. Vehicle 클래스는 Vehicle의 특징을 캡슐화한다. 그리고 데이터 은닉은 캡슐화를 실현하는 한 가지 방법이다.
캡슐화는 좋은 클래스 디자인의 핵심 원리이다. 캡슐화로 클래스 사이의 의존 관계가 감소하므로 클래스의 유지 관리와 테스트 가능성이 개선되고 의존적인 코드를 수정할 필요없이 클래스를 수정할 수 있다. 엄격하게 데이터 은닉의 원리를 준수하면 관련 코드를 바꿀 필요없이 클래스 내부의 데이터 조직을 변경할 수 있다. 예를 들어 원래 C-문자열을 저장한 Lines 클래스의 데이터 조직을 어느 시점에서든 바꿀 수 있다. char ** 저장 방식을 버리고 저장 장치에 기반하여 vector<string>로 바꿀 수 있다. Lines 클래스가 완벽하게 데이터 은닉을 사용하고 있으면 의존 소스 코드는 새로운 Lines 클래스를 사용하면서도 전혀 수정할 필요가 없다.
제일 규칙으로서 바탕 클래스의 데이터 조직이 (즉, 데이터 멤버가) 바뀌면 파생 클래스는 완전히 새로 컴파일되어야 한다 (그러나 수정할 필요는 없다). 바탕 클래스에 멤버 함수를 새로 추가해도 데이터 조직이 바뀌지 않으며 그래서 멤버 함수를 새로 추가할 경우에도 재컴파일할 필요가 없다.
한 가지 미묘한 예외가 있다. 새 멤버 함수를 바탕 클래스에 추가하고 그 함수가 어쩌다가 바탕 클래스의 첫 번째 가상 멤버 함수로 선언되면 바탕 클래스의 데이터 조직도 바뀐다 (가상 멤버 함수의 개념에 관한 연구는제 14장 참고).
Land가 Vehicle로부터 파생되었으므로 다음 클래스를 파생시킬 준비가 되었다. Car 클래스를 정의하여 자동차를 표현하겠다. Car 객체는 Land 운송 수단이고 Car는 제조사 이름이 있다고 생각하면 Car 클래스를 쉽게 디자인할 수 있다.
class Car: public Land
{
std::string d_brandName;
public:
Car();
Car(size_t mass, size_t speed, std::string const &name);
std::string const &brandName() const;
};
위의 클래스 정의에서 Car는 Land로부터 파생되었다. Land는 순서대로 Vehicle로부터 파생되었다. 이를 내포 파생이라고 부른다. Land는 Car의 직접 바탕 클래스로 불리우는 반면에 Vehicle은 Car의 간접 바탕 클래스라고 부른다.
Car가 Land로부터 파생되었고 Land는 Vehicle로부터 파생되었으므로 이 클래스 계통도는 클래스를 설계할 때 그대로 반영될 것이라고 생각하고 싶을 것이다. 그러나 그런 유혹은 떨쳐 버리는 것이 좋다.
클래스를 클래스로부터 반복적으로 파생시키다 보면 순식간에 거대하고 복잡한 클래스 계통도가 생겨나서 이해하기 어렵고 사용하기도 어려우며 유지관리하기도 어렵게 된다. 파생 클래스의 사용자는 (간접) 바탕 클래스의 특징도 모두 알 필요가 있기 때문에 사용하기도 어렵고 이해하기도 어렵다. 그 모든 클래스는 아주 밀접하게 연결되어 있기 때문에 유지관리하기도 어렵다. 데이터 은닉을 꼼꼼하게 지키면 바탕 클래스가 데이터 조직을 변경하더라도 파생 클래스를 변경할 필요가 없지만 반면에 현재 조직에 의존하는 (파생된) 클래스가 하나 둘 늘어갈수록 실제적으로 그런 바탕 클래스를 변경하기가 어렵게 되어 버린다.
바탕 클래스의 인터페이스를 상속받는 것은 처음에 보면 큰 이득인 것처럼 보이지만 결국 의존성에 발목을 잡히게 된다. 바탕 클래스의 인터페이스를 완벽하게 요구하는 경우는 거의 없다. 클래스는 상속을 통하여 물려 받기보다 자신의 멤버 함수를 명시적으로 정의하는 편이 더 좋다.
클래스를 기존의 클래스의 관점에서 정의하는 경우가 많다. 몇몇 특징은 사용되지만 다른 특징들은 감출 필요가 있다. 스택 컨테이너를 생각해 보자. 스택 컨테이너는 데크의 관점에서 구현된다. deque::back의 값을 stack::top의 값으로 돌려준다.
상속으로 is-a 관계를 구현할 때 확실하게 `사용 방향' 권한을 얻어라. is-a 관계 구현을 목표로 하는 상속은 바탕 클래스에 초점을 두어야 한다. 바탕 클래스의 편의기능은 파생 클래스에 의하여 사용되지 않지만 파생 클래스의 편의기능은 다형성을 사용하여 바탕 클래스의 편의기능을 재정의(재구현)해야 한다. (이것이 다음 장의 주제이다). 그래야 코드는 파생 클래스의 편의기능을 바탕 클래스를 통하여 다형적으로 사용할 수 있다. 이 접근법은 스트림을 연구할 때 보았다. 바탕 클래스가 (즉, ostream이) 종종 사용된다. ostream으로부터 파생된 클래스가 (예를 들어 ofstream과 ostringstream이) 정의한 편의기능들은 ostream 클래스가 제공하는 편의기능에만 의존하는 코드에 의해 사용된다. 절대로 파생 클래스를 직접적으로 사용하지 않는다.
클래스를 디자인할 때 되도록이면 결합도를 낮추는 것을 목표로 하라. 커다란 클래스 계통도는 튼튼한 클래스 디자인을 제대로 이해하지 못했다는 뜻이다. 클래스의 인터페이스가 부분적으로만 사용되고 그리고 파생 클래스가 또다른 클래스의 관점에서 구현되어 있다면 상속보다 합성을 사용할 것을 고려하라. 그리고 합성 객체들이 제공하는 멤버의 관점에서 인터페이스 멤버를 적절하게 정의하라.
private 키워드는 클래스 인터페이스 부분에서 시작한다. 거기에 멤버가 선언되고 클래스 자체의 멤버만 접근할 수 있다. 이것은 데이터 은닉을 실현하는 핵심 도구이다. 이미 확립된 클래스 디자인의 좋은 관례에 따라 공개 부분은 멤버 함수로 채워 깨끗한 인터페이스로 클래스의 기능을 제공한다. 이 멤버들로 사용자는 객체와 교신할 수 있다. 요청을 전송할 뿐 어떻게 처리될 지는 객체에게 맡겨둔다. 디자인이 잘된 클래스라면 그 실체는 자신의 데이터를 완전히 통제한다.
상속은 이런 원칙을 훼손하지 않는다. private 키워드와 protected 키워드가 작동하는 방식도 바꾸지 않는다. 파생 클래스는 바탕 클래스의 비밀 구역에 접근하지 못한다.
이것은 너무 제한적인 경우가 가끔 있다. 난수를 구현하여 streambuf를 생성하는 클래스를 생각해 보자 (제 6장). 그런 streambuf를 사용하면 istream irand를 생성할 수 있다. 그 다음에 irand로부터 다음 난수를 추출해 낸다. 다음 예제와 같이 스트림 I/O를 사용하여 10 개의 난수를 얻는다.
RandBuf buffer;
istream irand(&buffer);
for (size_t idx = 0; idx != 10; ++idx)
{
size_t next;
irand >> next;
cout << "next random number: " << next << '\n';
}
irand는 얼마나 많은 난수를 생성할 수 있어야 할까? 다행스럽게도 이 질문에 답할 필요가 없다. RandBuf가 책임을 지고 다음 난수를 생성해 줄 수 있기 때문이다. 그러므로 RandBuf는 다음과 같이 작동한다.
streambuf 바탕 클래스에 텍스트 형태로 건네진다.
istream 객체가 이 난수를 추출한다. 단순히 streambuf의 인터페이스를 사용한다.
RandBuf가 다음 난수의 텍스트 표현을 버퍼에 저장했으면 자신의 streambuf 바탕 클래스에 그 난수의 문자를 찾을 곳을 알려 주어야 한다. 이를 위해 streambuf는 setg 멤버를 제공한다. 난수 문자를 담고 있는 버퍼의 크기와 위치를 기대한다.
setg 멤버를 streambuf의 비밀 구역에 선언하면 안되는 것은 확실하다. RandBuf는 다음 난수 추출을 준비하기 위해 setg 멤버를 사용해야 하지만 streambuf의 공개 구역에 있어서도 안 된다. 결과적으로 쉽게 irand의 예상치 못한 행위를 맞이하기 때문이다. 다음의 가상 예제를 연구해 보자.
RandBuf randBuf;
istream irand(&randBuf);
char buffer[] = "12";
randBuf.setg(buffer, ...); // setg가 공개 구역에 있으므로 buffer는 12가 담긴다.
size_t next;
irand >> next; // *난수* 값이 아니다. 12이다.
streambuf와 그로부터 파생된 RandBuf 클래스 사이에 확실히 밀접한 관련이 있다. streambuf가 문자들을 읽도록 버퍼를 지정함으로써 RandBuf는 여전히 통제 상태에 머무르면서도 다른 곳에서 정의가 잘 된 행위를 깨지 못하도록 방지한다.
바탕 클래스와 파생 클래스 사이의 이 밀접한 연관은 클래스 멤버의 접근과 관련하여 protected라는 제 3의 키워드로 실현된다. 다음은 setg 멤버를 어떻게 streambuf 클래스에 선언할 수 있는지 보여준다.
class streambuf
{
// (예와 같이) 여기에 비밀 데이터 배치
protected:
void setg(... parameters ...); // 파생 클래스에서 사용 가능함
public:
// 여기에 공개 멤버 배치
};
보호 멤버는 파생 클래스에서 접근할 수 있지만 클래스의 공개 인터페이스에 포함되지 않는다.
데이터 멤버를 클래스의 보호 구역에 선언하고 싶은 유혹을 피하라. 그것은 나쁜 클래스 디자인의 확실한 징표이다. 불필요하게 바탕 클래스와 파생 클래스가 긴밀하게 결합되어 버리기 때문이다. protected 키워드가 도입되었다고 해서 데이터 은닉의 원리를 포기해서는 안 된다. 파생 클래스가 바탕 클래스에 접근할 수 있도록 권한을 주어야 한다면 멤버 함수를 사용하라. 바탕 클래스의 보호 구역에 선언된 접근자와 변경자를 사용하라. 이렇게 하면 결합도를 높이지 않고 접근을 제한할 수 있다.
is-a 관계를 정의하려면 공개 파생으로 상속을 받아야 한다. 파생 클래스 실체는 바탕 클래스 실체이므로 (is-a) 바탕 클래스 실체를 기대하는 코드에 파생 클래스 실체를 다형적으로 사용할 수 있다.
그러나 파생 클래스에서 private 또는 protected로 상속의 종류를 정의할 수 있다.
protected 키워드를 바탕 클래스의 앞에 두면 보호 파생으로 상속을 받는다.
class Derived: protected Base
보호 파생이 사용되면 바탕 클래스의 공개 멤버와 보호 멤버는 모두 파생 클래스에서 보호 멤버가 된다. 파생 클래스는 바탕 클래스의 모든 공개 멤버와 보호 멤버에 접근할 수 있다. 파생 클래스로부터 또 파생된 클래스는 바탕 클래스의 멤버들을 보호 멤버로 간주한다. (상속 트리 밖의) 다른 코드는 무엇이든 바탕 클래스의 멤버에 접근할 수 없다.
private 키워드를 바탕 클래스의 앞에 두면 비밀 파생으로 상속을 받는다.
class Derived: private Base
비밀 파생이 사용되면 바탕 클래스의 모든 멤버는 파생 클래스에서 비밀 멤버가 된다. 파생 클래스의 멤버는 바탕 클래스의 모든 보호 멤버에 접근할 수 있지만 다른 곳에서는 바탕 클래스의 멤버를 사용할 수 없다.
바탕 클래스의 관점에서 파생 클래스의 실체를 정의하는 상황에 합성을 사용할 수 없으면 비밀 상속을 사용한다. 보호 상속의 사용법은 문서화가 별로 되어 있지 않다. 그러나 자신이 파생 클래스이기도 한 바탕 클래스를 정의할 때 보호 상속을 고려해 볼 수 있을 것이다. 바탕 클래스의 멤버를 자신의 파생 클래스에도 사용할 수 있도록 만들 필요가 있기 때문이다.
유형을 조합하여 상속을 받기도 한다. 예를 들어 스트림 클래스를 디자인할 때 std::istream이나 std::ostream으로부터 파생시킨다. 그렇지만 스트림이 생성되기 전에 std::streambuf를 먼저 사용할 수 있어야 한다. 상속 순서가 클래스 인터페이스에 정의되어 있다는 사실을 활용하여 std::streambuf와 (그 다음에) std::ostream의 두 클래스로부터 다중 상속을 받아 그 스트림 클래스를 파생시킨다 (13.6절).
class Derived: private std::streambuf, public std::ostream
클래스의 사용자에게는 std::streambuf가 아니라 std::ostream이 보인다. 그래서 전자를 위해 비밀 파생이 사용되고 후자를 위해 공개 파생이 사용된다.
어떤 상황에서는 이 체계가 너무 제한적이다. RandStream 클래스를 연구해 보자. RandBuf로부터 비밀 파생되었고 또한 istream으로부터 공개 파생되었다. 또 RandBuf 자체는 std::streambuf으로부터 파생되었다.
class RandBuf: public std::streambuf
{
// 난수를 저장할 버퍼를 구현한다.
};
class RandStream: private RandBuf, public std::istream
{
// 난수 값을 추출할 스트림을 구현한다.
};
이런 클래스는 istream 표준 인터페이스를 사용하여 난수를 추출할 수 있다.
RandStream 클래스는 istream 객체의 기능을 염두에 두고 생성했지만 std::streambuf 클래스의 멤버 중에서도 그 자체로 유용하다고 간주할 수 있는 함수들이 있다. 예를 들어 streambuf::in_avail 함수는 즉시 읽을 수 있는 문자 갯수의 최소 값을 돌려준다. 이 함수를 이용하는 표준적인 방식은 바탕 클래스의 멤버를 호출하는 그림자 멤버를 정의하는 것이다.
class RandStream: private RandBuf, public std::istream
{
// 난수 값을 뽑아내는 스트림을 구현한다.
public:
std::streamsize in_avail();
};
inline std::streamsize RandStream::in_avail()
{
return std::streambuf::in_avail();
}
보호 또는 비밀 바탕 클래스로부터 겨우 멤버 하나를 사용가능하도록 만드는 데 수고가 너무 많은 듯 보인다. in_avail 멤버를 사용하고 싶다면 접근 승격(access promotion)을 사용할 수 있다. 접근 승격을 사용하면 비밀 또는 보호 바탕 클래스에서 어느 멤버를 파생 클래스의 보호 또는 공개 인터페이스에 사용가능하도록 만들지 말지 지정할 수 있다. 다음은 위의 예제와 똑같지만 이제는 접근 승격을 사용한다.
class RandStream: private RandBuf, public std::istream
{
// 난수 값을 뽑아내는 스트림을 구현한다.
public:
using std::streambuf::in_avail;
};
접근 승격은 선언된 바탕 클래스 멤버에서 중복정의 버전을 모두 사용 가능하게 만들어 버린다는 사실에 주의해야 한다. 그래서 streambuf가 in_avail 뿐만 아니라 in_avail(size_t *)도 지원해야 한다면 두 멤버 모두 공개 인터페이스에 포함되어야 한다.
생성자는 실체의 데이터 멤버를 초기화하기 위해 존재한다. 파생 클래스의 생성자도 역시 책임을 지고 적절하게 바탕 클래스를 초기화한다. 이전에 소개한 Land 클래스의 정의를 보면 (13.1절) 생성자는 그냥 다음과 같이 정의할 수 있다.
Land::Land(size_t mass, size_t speed)
{
setMass(mass);
setspeed(speed);
}
그렇지만 이런 구현은 몇 가지 단점이 있다.
Land의 생성자는 다음과 같이 개선할 수 있다.
Land::Land(size_t mass, size_t speed)
:
Vehicle(mass),
d_speed(speed)
{}
파생 클래스 생성자는 언제나 기본으로 바탕 클래스의 기본 생성자를 호출한다. 물론 이것은 파생 클래스의 복사 생성자에는 올바르지 않다. Land 클래스에 복사 생성자가 제공될 것이라고 간주하고서 Land const &other를 사용하여 other의 바탕 클래스를 나타낼 수 있다.
Land::Land(Land const &other) // 복사 생성자가 필요하다고 간주한다.
:
Vehicle(other), // 바탕 클래스 부분을 복사 생성한다.
d_speed(other.speed) // Land의 데이터 멤버를 복사 생성한다.
{}
데이터 멤버를 이동하는 이동 생성자의 설계는 9.7절에 다루었다. 이동을 인지하는 바탕 클래스로부터 파생된 클래스에 대한 이동 생성자는 rvalue 참조를 익명으로 만든 다음에 그것을 바탕 클래스의 이동 생성자에 건네야 한다. 바탕 클래스 또는 합성 객체의 정보를 새로운 목표 객체로 이동시키기 위해 이동 생성자를 구현할 때 std::move 함수를 사용해야 한다.
첫 번째 예제는 Car 클래스에 대하여 이동 생성자를 보여준다. 이동 가능한 char *d_brandName 데이터 멤버가 있고 Land는 이동-인지 클래스라고 간주한다. 두 번째 예제는 Land 클래스에 대하여 이동 생성자를 보여준다. 자체는 이동 가능한 데이터 멤버가 없지만 Vehicle 바탕 클래스는 이동을-인지한다고 간주한다.
Car::Car(Car &&tmp)
:
Land(std::move(tmp)), // 이름없는 `tmp'
d_brandName(tmp.d_brandName) // char *의 값을 이동
{
tmp.d_brandName = 0;
}
Land(Land &&tmp)
:
Vehicle(std::move(tmp)), // 이동-인지 Vehicle
d_speed(tmp.d_speed) // 평범한 데이터의 평범한 복사
{}
Car 클래스에 대하여 이것은 다음과 같이 요약할 수 있다.
Car &Car::operator=(Car &&tmp)
{
swap(tmp);
return *this;
}
교체가 지원되지 않으면 std::move를 사용하여 바탕 클래스의 이동 할당 연산자를 호출할 수 있다.
Car &Car::operator=(Car &&tmp)
{
static_cast<Land &>(*this) = std::move(tmp);
// Car의 데이터 멤버를 다음으로 이동시킨다.
return *this;
}
이 특징은 사용되기도 하고 안 되기도 한다. 파생 클래스에서 어떤 생성자는 생략할 수 없다. 대신에 바탕 클래스에서 그에 상응하는 생성자를 사용하기 때문이다. 여러 바탕 클래스로부터 파생된 클래스에 이 특징을 사용하려면 (13.6절) 바탕 클래스의 생성자가 모두 서명이 달라야 한다. 여기에 연관된 복잡성을 생각하면 아마도 다중 상속을 사용하는 클래스에는 바탕 클래스의 생성자를 사용하지 않는 것이 제일 좋을 것이다.
파생 클래스 실체의 생성은 다음 구문을 사용하면 바탕 클래스의 생성자에게 맡길 수 있다.
class BaseClass
{
public:
// BaseClass constructor(s)
};
class DerivedClass: public BaseClass
{
public:
using BaseClass::BaseClass; // DerivedClass에 생성자가
// 정의되지 않았다.
};
활괄호 표기법으로 구조체를 초기화할 수 있다. C++17은 이런 초기화 편의기능을 확장한다 (집합체 초기화(Aggregate Initializations)). 파생 구조체의 바탕 구조체를 초기화할 때 활괄호 표기법을 사용하도록 허용한다. 바탕-수준의 구조체마다 파생-수준의 구조체를 초기화해 자신만의 활괄호 집합을 받는다.
struct Base
{
int value;
};
struct Derived: public Base
{
string text;
};
// 파생 구조체의 초기화:
Derived der{{value}, "hello world"};
// -------
// 바탕 구조체의 초기화
class Base
{
public:
~Base();
};
class Derived: public Base
{
public:
~Derived();
};
int main()
{
Derived derived;
}
main 함수가 끝나면 derived 실체는 존재하기를 멈춘다. 그러므로 그의 소멸자(~Derived)가 호출된다 . 그렇지만 derived는 또한 Base 객체이므로 ~Base 소멸자도 호출된다. 파생 클래스의 소멸자는 절대로 바탕 클래스의 소멸자를 명시적으로 호출하지 못한다.
생성자와 소멸자는 마치 스택처럼 호출된다. derived가 생성될 때 적절한 바탕 클래스의 생성자가 먼저 호출된다. 다음, 적절한 파생 클래스의 생성자가 호출된다. derived 객체가 파괴될 때 그의 소멸자가 먼저 호출된다. 자동으로 다음에 Base 클래스의 소멸자가 호출된다. 파생 클래스의 소멸자는 언제나 바탕 클래스의 소멸자보다 먼저 호출된다.
파생 클래스 실체의 생성이 성공적으로 완료되지 못하면 (즉, 생성자가 예외를 던진다면) 그의 소멸자는 호출되지 않는다. 그렇지만 파생 클래스의 생성자가 예외를 던지더라도 적절하게 생성된 바탕 클래스의 소멸자는 여전히 호출될 것이다. 이것은 당연히 그래야 한다. 어쨌거나 적절하게 생성된 객체도 역시 파괴되어야 하기 때문이다.
#include <iostream>
struct Base
{
~Base()
{
std::cout << "Base destructor\n";
}
};
struct Derived: public Base
{
Derived()
{
throw 1; // 이 시점에 Base가 생성되어 있다.
}
};
int main()
{
try
{
Derived d;
}
catch(...)
{}
}
/*
출력
Base destructor
*/
mass 함수는 그 두 무게를 더해 돌려주어야 한다.
Truck의 정의는 클래스 정의로 시작한다. 최초의 Truck 클래스는 Car로부터 파생시킨다. 그러나 무게 정보를 나타내는 size_t 필드를 하나 더 가지도록 확대한다. 여기에서 트랙터의 무게를 Car 클래스에 나타내고 트럭 전체(트랙터 + 트레일러)의 무게를 자신의 d_mass 데이터 멤버에 저장하기로 결정한다.
class Truck: public Car
{
size_t d_mass;
public:
Truck();
Truck(size_t tractor_mass, size_t speed, char const *name,
size_t trailer_mass);
void setMass(size_t tractor_mass, size_t trailer_mass);
size_t mass() const;
};
Truck::Truck(size_t tractor_mass, size_t speed, char const *name,
size_t trailer_mass)
:
Car(tractor_mass, speed, name)
d_mass = trailer_mass + trailer_mass;
{ }
Car 바탕 클래스에 존재하는 setMass와 mass라는 두 함수가 Truck 클래스에 이미 포함되어 있음을 눈여겨보라.
setMass는 재정의해도 아무 문제가 없다. 이 함수를 그냥 재정의해 Truck 객체에만 조치를 수행할 수 있다.
setMass를 재정의하면 Car::setMass가 가려져 보이지 않는다. Truck에 대하여 두 개의 size_t 인자를 가진 setMass 함수만 사용할 수 있다.
Vehicle의 setMass 함수는 Truck에 대하여 그대로 사용할 수 있다. 그러나 이제는 명시적으로 호출해야 한다. Car::setMass가 시야에 보이지 않기 때문이다. Car::setMass에 size_t 인자가 하나만 있을지라도 마찬가지로 보이지 않는다. Truck::setMass를 다음과 같이 구현할 수 있다.
void Truck::setMass(size_t tractor_mass, size_t trailer_mass)
{
d_mass = tractor_mass + trailer_mass;
Car::setMass(tractor_mass); // 주의: Car::가 요구됨
}
Car::setMass 클래스의 밖으로부터 영역 지정 연산자를 사용하여 접근한다. 그래서 Truck truck이 자신의 Car 무게를 설정할 필요가 있다면 다음과 같이 사용해야 한다.
truck.Car::setMass(x);
class Truck 멤버를 추가한다.
// 인터페이스에:
void setMass(size_t tractor_mass);
// 인터페이스 아래에:
inline void Truck::setMass(size_t tractor_mass)
{
(d_mass -= Car::mass()) + tractor_mass;
Car::setMass(tractor_mass);
}
이제 영역 지정 연산자를 사용할 필요없이 Truck 객체는 인자가 하나인 setMass 멤버 함수를 사용할 수 있다. 함수가 인라인으로 정의되어 있기 때문에 따로 더 함수를 호출하는 부담도 없다.
using 선언을 파생 클래스 인터페이스에 추가하면 된다. 그러면 Truck의 클래스 인터페이스에서 해당 부분은 다음과 같다.
class Truck: public Car
{
public:
using Car::setMass;
void setMass(size_t tractor_mass, size_t trailer_mass);
};
using 선언은 언급된 (모든 버전의 중복정의) 멤버 함수를 직접적으로 파생 클래스의 인터페이스 안으로 반입한다. 바탕 클래스 멤버에 파생 클래스 멤버와 동일한 서명이 있으면 컴파일에 실패한다 (using Car::mass 선언은 Truck이 인터페이스에 추가할 수 없다). 이제 코드는 truck.setMass(5000, 2000) 뿐만 아니라 truck.setMass(5000)도 사용할 수 있다.
using 선언은 접근 권한을 준수한다. 비-클래스 멤버가 영역 지정 연산자 없이 setMass(5000)를 사용하지 못하도록 방지하려면 그러나 파생 클래스 멤버에게는 그렇게 하도록 허용하려면 using Car::setMass 선언을 Truck 클래스의 비밀 구역에 배치해야 한다.
mass 함수는 이미 Car에도 정의되어 있다. Vehicle로부터 상속을 받았기 때문이다. 이 경우, Truck 클래스는 이 멤버 함수가 트럭의 전체 무게를 돌려주도록 재정의한다.
size_t Truck::mass() const
{
return d_mass;
}
int main()
{
Land vehicle(1200, 145);
Truck lorry(3000, 120, "Juggernaut", 2500);
lorry.Vehicle::setMass(4000);
cout << '\n' << "Tractor weighs " <<
lorry.Vehicle::mass() << '\n' <<
"Truck + trailer weighs " << lorry.mass() << '\n' <<
"Speed is " << lorry.speed() << '\n' <<
"Name is " << lorry.name() << '\n';
}
Truck 클래스는 Car로부터 파생되었다. 그렇지만 이 클래스 설계에 의문을 제기할지도 모르겠다. 트럭은 트랙터와 트레일러를 조합한 것으로 간주되기 때문에 아마도 설계를 혼용하여 정의하는 것이 더 좋을 것이다. 트랙터 부분은 상속을 사용하는 편이 더 좋을 것이다 (Car로부터 상속을 받고 트레일러 부분은 합성을 사용하는 것이 좋다).
이렇게 재설계를 하면 Car로서의 Truck으로부터 (좀 묘하게 데이터 멤버가 추가되기는 했지만) 여전히 Car이면서도 Vehicle(트레일러)을 가지고 있는 Truck(트랙터)으로 눈길이 간다.
Truck의 인터페이스는 이제 아주 구체적이다. 사용자는 Car와 Vehicle의 인터페이스에 신경을 쓰지 않아도 된다. 그리고 `도로 열차'를 정의할 수 있는 가능성이 열린다. 여러 트레일러를 끄는 트랙터이다. 다음은 그런 대안 클래스를 설정하는 예이다.
class Truck: public Car // 트랙터
{
Vehicle d_trailer; // 전차에 대하여 vector<Vehicle>를 사용한다.
public:
Truck();
Truck(size_t tractor_mass, size_t speed, char const *name,
size_t trailer_mass);
void setMass(size_t tractor_mass, size_t trailer_mass);
void setTractorMass(size_t tractor_mass);
void setTrailerMass(size_t trailer_mass);
size_t tractorMass() const;
size_t trailerMass() const;
// 연구 대상:
Vehicle const &trailer() const;
};
다중 상속으로 파생된 클래스는 두 바탕 클래스의 실체로 간주해도 아무 문제가 없어야 한다. 그렇지 않으면 합성이 더 적절하다. 일반적으로 (바탕 클래스 하나만 사용하는) 선형적 파생이 다중 파생보다 훨씬 더 자주 사용된다. 좋은 클래스 디자인 원칙에 의하면 클래스는 잘 기술된 책임을 하나만 져야 한다. 그리고 그 원칙은 종종 다중 상속과 충돌한다. 파생된 Derived 클래스를 Base1과 Base2 객체로 둘 다 언급할 수 있기 때문이다.
그렇다면 다중 상속이 극단까지 사용된 객체의 원형을 하나 연구해 보자. 스위스 군용 칼이 그것이다! 이 객체는 칼이며, 가위이며, 깡통따개이자, 코르크 따개이면서, 등등 ....
`스위스 군용 칼'은 다중 상속의 극단적 예이다. C++는 `한 클래스에 책임 하나'라는 원칙을 어기면 안 되는 좋은 이유가 몇 가지 있다. 이 원칙은 다음 장에서 다룬다. 이 절은 다중 상속을 이용한 클래스를 생성하는 방법에 관하여 기술적으로 상세하게 연구한다.
`스위스 군용 칼'을 C++로 어떻게 생성할까? 예를 들어 비행기 조종석의 장비들을 생성할 수 있는 툴킷을 설계하려고 한다고 가정하자. 먼저 (적어도) 두 개의 바탕 클래스가 필요하다. 수평계와 고도계 같은 모든 종류의 도구를 설계한다. 비행기에서 자주 보는 컴포넌트 중 하나는 nav-com 세트이다. 운항 신호 수신기 (`nav' 부분)과 라디오 통신 유닛 (`com'-부분)의 조합이다. nav-com 세트를 정의하기 위해 NavSet 클래스를 설계하기 시작한다 (Intercom과 VHF_Dial 그리고 Message 클래스가 이미 존재한다고 가정).
class NavSet
{
public:
NavSet(Intercom &intercom, VHF_Dial &dial);
size_t activeFrequency() const;
size_t standByFrequency() const;
void setStandByFrequency(size_t freq);
size_t toggleActiveStandby();
void setVolume(size_t level);
void identEmphasis(bool on_off);
};
다음으로 ComSet 클래스를 디자인한다.
class ComSet
{
public:
ComSet(Intercom &intercom);
size_t frequency() const;
size_t passiveFrequency() const;
void setPassiveFrequency(size_t freq);
size_t toggleFrequencies();
void setAudioLevel(size_t level);
void powerOn(bool on_off);
void testState(bool on_off);
void transmit(Message &message);
};
이 클래스의 실체를 사용하면 Intercom을 통하여 전송되는 메시지를 받을 수 있다. 또 Message 객체를 사용하여 메시지를 전송(transmit)할 수도 있다. ComSet 객체에 건네서 그의 transmit 멤버 함수를 사용하면 된다.
이제 NavCom 세트를 생성할 준비가 되었다.
class NavComSet: public ComSet, public NavSet
{
public:
NavComSet(Intercom &intercom, VHF_Dial &dial);
};
완성이다. NavComSet을 정의했다. NavSet이면서 ComSet이기도 하다. 두 바탕 클래스의 편의기능들은 다중 상속을 통하여 파생 클래스에서 사용할 수 있다.
다음을 주의깊게 읽어 보자.
NavSet 그리고 ComSet) 두 바탕 클래스 이름 앞에 public 키워드가 있다. 기본으로 상속은 비밀 파생이다. 그리고 public 키워드를 각 바탕 클래스를 지정하기 전에 반복해야 한다. 바탕 클래스는 같은 파생 유형을 사용하지 않아도 된다. 한 바탕 클래스는 공개 파생을 사용하고 또다른 바탕 클래스는 비밀 파생을 사용해도 된다.
NavComSet 클래스는 자신만의 기능을 따로 더 도입하지 않았다. 그저 기존의 두 클래스를 조합하여 새로 집합 클래스를 만들었을 뿐이다. 그리하여 C++는 단순한 클래스 여러 개를 모아 복잡한 클래스 하나로 만들 수 있는 가능성을 제공한다.
NavComSet 생성자의 구현이다.
NavComSet::NavComSet(Intercom &intercom, VHF_Dial &dial)
:
ComSet(intercom),
NavSet(intercom, dial)
{}
생성자는 따로 더 코드가 필요없다. 바탕 클래스들의 생성자를 활성화하는 것이 목적이다. 바탕 클래스 초기화자가 호출되는 순서는 생성자 코드의 호출 순서에 의해 결정되는 것이 아니라 클래스 인터페이스에 있는 바탕 클래스의 순서에 의하여 결정된다.
NavComSet 클래스 정의는 데이터 멤버나 멤버 함수를 따로 더 요구하지 않는다. 여기에서는 (그리고 보통은) 다중 파생된 클래스가 적절하게 작동하기 위하여 필요한 모든 기능과 데이터를 상속된 인터페이스가 제공한다.
setVolume 함수가 NavSet 클래스에 있고 setAudioLevel 함수가 ComSet 클래스에 있다. 약간은 모른 체한 점이 있다. 사실 볼륨 설정을 처리하는 Amplifier 합성 객체를 두 기구 모두 가진다는 것을 충분히 예상할 수 있기 때문이다. 개선된 클래스라면 Amplifier &lifier() const 멤버 함수를 제공할 수 있다. 그리고 증폭기에 대한 자신의 인터페이스 설정은 어플리케이션에게 맡길 수 있다. 또, 개선된 클래스는 NavSet이나 ComSet 부분에 볼륨을 설정하는 멤버를 정의할 수 있다.
두 바탕 클래스가 동일한 이름의 멤버를 제공하는 경우 특별히 주의를 기울여 모호성을 방지할 필요가 있다.
NavComSet navcom(intercom, dial); navcom.NavSet::setVolume(5); // NavSet 볼륨 레벨을 설정한다. navcom.ComSet::setVolume(5); // ComSet 볼륨 레벨을 설정한다.
class NavComSet: public ComSet, public NavSet
{
public:
NavComSet(Intercom &intercom, VHF_Dial &dial);
void comVolume(size_t volume);
void navVolume(size_t volume);
};
inline void NavComSet::comVolume(size_t volume)
{
ComSet::setVolume(volume);
}
inline void NavComSet::navVolume(size_t volume)
{
NavSet::setVolume(volume);
}
NavComSet 클래스를 제삼자로부터 얻었고 변경할 수 없다면 모호성을 제거하는 포장 클래스를 사용하면 된다.
class MyNavComSet: public NavComSet
{
public:
MyNavComSet(Intercom &intercom, VHF_Dial &dial);
void comVolume(size_t volume);
void navVolume(size_t volume);
};
inline MyNavComSet::MyNavComSet(Intercom &intercom, VHF_Dial &dial)
:
NavComSet(intercom, dial);
{}
inline void MyNavComSet::comVolume(size_t volume)
{
ComSet::setVolume(volume);
}
inline void MyNavComSet::navVolume(size_t volume)
{
NavSet::setVolume(volume);
}
NavCom 클래스를 계속 연구해 보자. 바탕 클래스 실체와 파생 클래스 실체, 두 개의 객체를 정의한다.
ComSet com(intercom);
NavComSet navcom(intercom2, dial2);
navcom 객체는 Intercom 객체와 VHF_Dial 객체를 사용하여 생성한다. 그렇지만 NavComSet은 동시에 ComSet이다. 따라서 (파생 클래스 실체) navcom을 (바탕 클래스 실체) com에 할당할 수 있다.
com = navcom;
이 할당의 효과는 com 객체가 intercom2와 통신한다는 것이다. ComSet 객체는 VHF_Dial이 없으므로 navcom의 dial은 할당에서 무시된다. 파생 클래스의 실체를 바탕 클래스의 실체에 할당할 때 바탕 클래스의 데이터 멤버만 할당된다. 파생 클래스의 데이터 멤버는 폐기된다. 이런 현상을 슬라이싱(slicing)이라고 부른다. 이와 같은 상황에 슬라이싱은 아마도 심각한 결과를 초래하지는 않을 것이다. 그러나 바탕 클래스 멤버를 정의한 함수에 파생 클래스의 실체를 건네거나 또는 바탕 클래스의 실체를 돌려줄 함수가 파생 클래스 실체를 돌려주면 역시 복사손실이 일어난다. 그러면 불쾌한 부작용을 경험할 수가 있다.
바탕 클래스 실체를 파생 클래스 실체에 할당하는 것은 문제가 있다. 다음과 같은 서술문은
navcom = com;
NavComSet의 VHF_Dial 데이터 멤버를 어떻게 재할당해야 할지 확실하지 않다. ComSet 실체인 com에 VHF_Dial 데이터 멤버가 없기 때문이다. 그러므로 그런 할당은 컴파일러가 거부한다. 파생 클래스 실체는 바탕 클래스 실체이지만 그 반대는 유효하지 않다. 바탕 클래스 실체는 파생 클래스 실체가 아니다.
다음 일반 규칙이 적용된다. 바탕 클래스 실체와 파생 클래스 실체가 관련된 할당에서 데이터를 빼고 할당해도 합법적이다 (이를 슬라이싱(slicing)이라고 부름). 데이터를 지정하지 않은 채로 두고 할당하는 것은 허용되지 않는다. 물론, 할당 연산자를 중복정의하면 바탕 클래스 실체를 파생 클래스 실체에 할당할 수 있다. 다음 서술문을 컴파일하려면
navcom = com;
NavComSet 클래스는 인자에 ComSet 객체를 받는 중복정의 할당 연산자를 정의하고 있어야 한다. 그 경우 할당 연산자가 빠진 데이터로 무엇을 할지 결정하는 것은 프로그래머의 책임이다.
Vehicle 클래스로 되돌아가 다음 실체와 포인터 배열을 정의한다.
Land land(1200, 130);
Car auto(500, 75, "Daf");
Truck truck(2600, 120, "Mercedes", 6000);
Vehicle *vp;
파생 클래스의 실체 주소 세 개를 Vehicle 포인터에 할당할 수 있다.
vp = &land;
vp = &auto;
vp = &truck;
이 할당은 받아 들일 수 있다. 그렇지만 파생 클래스가 Vehicle 바탕 클래스로 묵시적으로 변환된다. vp가 Vehicle을 가리키는 포인터로 정의되어 있기 때문이다. 그러므로 vp를 사용할 때 mass를 조작하는 멤버 함수만 호출할 수 있다. 이것이 Vehicle의 유일한 기능이기 때문이다. 컴파일러가 구별할 수 있는 한, 이것은 vp가 가리키는 객체이다.
Vehicle에 대한 참조에도 똑 같은 규칙이 적용된다. 예를 들어 함수에 Vehicle 참조 매개변수를 가지도록 정의되어 있으면 그 함수에 Vehicle로부터 파생된 클래스의 실체를 건넬 수 있다. 함수 안에서 구체적인 Vehicle 멤버에 여전히 접근할 수 있다. 포인터와 참조 사이의 이 유사성은 일반적으로 유효하다. 참조는 변장한 포인터에 불과하다는 사실을 기억하라. 평범한 변수인 척하지만 실제로는 포인터이다.
이 제한된 기능은 Truck 클래스에 대하여 중요하다. vp = &truck를 실행하고 나면 vp는 Truck 객체를 가리킨다. 그래서 vp->mass()는 8600 대신에 2600을 돌려준다 (트레일러와 캐빈을 합한 값: 2600 + 6000). 이 값은 truck.mass()가 돌려 주었을 것이다.
실체를 가리키는 포인터를 사용하여 함수를 호출하면 어느 멤버 함수를 사용할 수 있으며 실행할 수 있는지 결정하는 것은 (객체의 유형이 아니라) 포인터 유형이다. 다른 말로, C++는 포인터를 통하여 도달된 객체의 유형을 묵시적으로 포인터 유형으로 변환한다.
포인터가 가리키는 객체의 실제 유형을 알면 명시적으로 유형을 변환하여 그 객체의 (사용 가능한) 모든 멤버 함수에 접근할 수 있다.
Truck truck;
Vehicle *vp;
vp = &truck; // vp는 이제 트럭 객체를 가리킨다.
Truck *trp;
trp = static_cast<Truck *>(vp);
cout << "Make: " << trp->name() << '\n';
마지막 서술문 바로 앞에서 Vehicle * 변수는 Truck *으로 유형이 변환된다. 예와 같이 (유형변환을 할 때) 이 코드는 위험에 노출되어 있다. vp가 실제로 Truck을 가리킬 때만 작동한다. 그렇지 않으면 예상치 못한 결과가 나올 수 있다.
new[] 연산자가 클래스의 기본 생성자를 호출한다는 것이다. 예를 들어 문자열이 10개인 배열을 할당하려면 다음과 같이 할 수 있다.
new string[10];
그러나 또다른 생성자를 사용할 수가 없다. hello world 텍스트로 문자열을 초기화하고 싶다고 가정해 보자. 다음과 같이 작성할 수가 없다.
new string("hello world")[10];
동적으로 할당된 객체의 초기화는 보통 두 단계의 과정으로 구성된다. 첫째, 배열을 할당한다 (묵시적으로 기본 생성자를 호출한다). 둘째, 다음 예제와 같이 배열의 원소를 초기화한다.
string *sp = new string[10];
fill(sp, sp + 10, string("hello world"));
이 접근법들은 모두 `이중 초기화' 때문에 고통을 받는다. 마치 생성자에서 멤버 초기화자를 사용하지 않는 것과 비슷하다.
이중 초기화를 피하는 한 가지 방법은 상속을 사용하는 것이다. new[] 연산자와 조합하여 비-기본 생성자를 호출하는 데 상속을 유익하게 사용할 수 있다. 이 접근법은 다음과 같은 사실을 이용한다.
위의 접근법은 또다른 가능한 접근법을 제안한다.
new[]의 반환 표현식을 바탕 클래스 실체를 가리키는 포인터에 할당한다.
hello world 텍스트 10 줄을 출력한다.
#include <iostream>
#include <string>
#include <algorithm>
#include <iterator>
using namespace std;
struct Xstr: public string
{
Xstr()
:
string("hello world")
{}
};
int main()
{
string *sp = new Xstr[10];
copy(sp, sp + 10, ostream_iterator<string>(cout, "\n"));
}
물론 위의 예제는 상당히 허술하다. 그러나 어렵지 않게 예제를 다듬을 수 있다. Xstr 클래스는 익명의 이름공간에 정의할 수 있다. 주어진 getString() 함수만 size_t nObjects 매개변수에 접근할 수 있다. 사용자는 hello world로 초기화된 문자열의 갯수를 마음대로 지정할 수 있다.
바탕 클래스 인자를 하드-코딩하는 대신에 변수나 함수를 사용하여 적절한 값을 건네는 것도 가능하다. 다음 예제에서 Xstr지역 클래스는 nStrings(size_t nObjects, char const *fname) 함수 안에 정의된다. 할당해야 할 string 객체의 갯수와 그 객체들을 초기화할 줄들이 담긴 파일의 이름을 기대한다. 지역 클래스는 nStrings 함수 밖에서 보이지 않는다. 그래서 이름공간 보호막이 필요없다.
7.9절에 연구한 바와 같이 지역 클래스의 멤버 함수는 둘레 함수에 있는 지역 변수에 접근할 수 없다. 그렇지만 그 둘레 함수가 정의한 정적 데이터와 전역 데이터에는 접근할 수 있다.
지역 클래스를 사용하면 깔끔하게 해결된다. 구현 상세를 nStrings 함수 안에 감출 수 있기 때문이다. 그냥 파일을 열고 객체를 할당한 다음에 파일을 다시 닫으면 그 뿐이다. 지역 클래스는 string으로부터 파생되었으므로 자신의 바탕 클래스 초기화자를 위하여 string 생성자를 사용할 수 있다. 이 특별한 경우 string(char const *) 생성자를 호출한다. 방금 연 스트림의 연속 줄을 자신의 정적 nextLine() 멤버 함수를 통하여 거기에 제공한다. 이 함수는 정적 멤버 함수이므로 Xstr 기본 생성자의 멤버 초기화자도 사용할 수 있다. 그 시점에 Xstr 객체가 생성되어 있지 않아도 상관이 없다.
#include <fstream>
#include <iostream>
#include <string>
#include <algorithm>
#include <iterator>
using namespace std;
string *nStrings(size_t size, char const *fname)
{
static ifstream in;
struct Xstr: public string
{
Xstr()
:
string(nextLine())
{}
static char const *nextLine()
{
static string line;
getline(in, line);
return line.c_str();
}
};
in.open(fname);
string *sp = new Xstr[size];
in.close();
return sp;
}
int main()
{
string *sp = nStrings(10, "nstrings.cc");
copy(sp, sp + 10, ostream_iterator<string>(cout, "\n"));
}
이 프로그램을 실행하면 nstrings.cc 파일의 첫 10 줄을 화면에 보여준다.
멀티 쓰레드 환경에서는 위의 구현을 안전하게 사용할 수 없음을 주의하라. 이 경우 상호배제(mutex)를 사용하여 함수의 return 서술문 바로 앞에 있는 세 개의 서술문을 보호해야 한다.
이중 초기화를 피하는 완전히 다른 방법 하나는 (상속을 사용하지 않고) 배치 new를 사용하는 것이다 (9.1.5항). 그냥 필요한 양만큼 메모리를 배당한 다음에 그 자리에 적절한 생성자를 사용하여 실체를 할당하면 된다. 다음 예제는 멀티 쓰레드 환경에서도 사용할 수 있다. 이 접근법은 필요한 초기화를 한 쌍의 정적 construct/destroy 멤버로 수행한다.
아래에 보여주는 프로그램에서 construct는 istream을 기대한다. 이 스트림은 단순히 std::string 객체를 하나 담고 있는 String 클래스의 실체에게 초기화 문자열을 제공한다. construct는 먼저 n개의 String 실체에 충분한 메모리를 배당한다. 그리고 초기의 size_t 값을 위한 메모리도 배당한다. 이 초기의 size_t 값은 n으로 초기화된다. 다음 for 서술문에서 배치 new 호출을 사용하여, 제공된 스트림으로부터 줄들을 읽어 들여 생성자에게 건넨다. 마지막으로 첫 번째 String 객체의 주소가 반환된다.
destroy 멤버는 실체를 파괴한다. 파괴할 실체의 첫 주소의 위치 바로 앞에 있는 size_t로부터 파괴할 실체의 갯수를 열람한다. 소멸자를 명시적으로 호출하면 객체들은 파괴된다. 마지막으로 원래 construct가 배당한 날 메모리가 반납된다.
#include <fstream>
#include <iostream>
#include <string>
using namespace std;
class String
{
union Ptrs
{
void *vp;
String *sp;
size_t *np;
};
std::string d_str;
public:
String(std::string const &txt)
:
d_str(txt)
{}
~String()
{
cout << "destructor: " << d_str << '\n';
}
static String *construct(istream &in, size_t n)
{
Ptrs p = {operator new(n * sizeof(String) + sizeof(size_t))};
*p.np++ = n;
string line;
for (size_t idx = 0; idx != n; ++idx)
{
getline(in, line);
new(p.sp + idx) String(line);
}
return p.sp;
}
static void destroy(String *sp)
{
Ptrs p = {sp};
--p.np;
for (size_t n = *p.np; n--; )
sp++->~String();
operator delete (p.vp);
}
};
int main()
{
String *sp = String::construct(cin, 5);
String::destroy(sp);
}
/*
각각 alfa, bravo, charlie, delta, echo가 담긴
다섯 줄을 제공하면
다음과 같이 화면에 보여준다.
destructor: alfa
destructor: bravo
destructor: charlie
destructor: delta
destructor: echo
*/