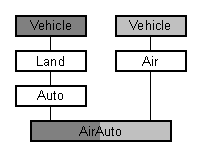
Vehicle *vp가 Car 객체를 가리키더라도 Car의 speed 멤버 또는 brandName 멤버를 사용할 수는 없다.
이전 장에서 클래스 사이에 관련된 두 가지 기본 방식을 연구했다. 한 가지 방식은 클래스는 또다른 클래스의 관점에서 구현할 수 있다는 것이다. 또 다른 방식은 파생 클래스는 바탕 클래스이다라는 것이다. 앞의 관계는 합성을 사용하여 구현된다. 뒤의 관계는 특별한 형태의 상속을 사용하여 구현된다. 이를 다형성(polymorphism)이라고 하며 이것이 바로 이 장의 주제이다.
클래스 사이가 is-a 관계라면 리스코프 교체 원리(Liskov Substitution Principle (LSP))를 적용할 수 있다. 바탕 클래스 실체를 가리키는 참조나 포인터를 기대하는 코드에 파생 클래스를 건네고 사용할 수 있다. 이 책에서는 지금까지 LSP를 많이 적용해 보았다. ostream을 기대하는 함수에 ostringstream이나 ofstream 또는 fstream을 건넬 때마다 이 원리를 적용해 왔다. 이 장에서는 그에 맞게 클래스를 설계하는 법을 알아 보겠다.
LSP는 다형성을 이용하여 구현된다. 바탕 클래스의 포인터가 사용되지만 행위는 실제로 가리키는 실체의 (파생) 클래스에 정의된다. 그래서 Vehicle *vp가 Car를 가리키면 마치 Car *처럼 행위하는 것 같이 보인다. (스타트랙의 한 장면이다. 커크 선장은 언제나 그렇듯이 궁지에 빠졌다. 너무나 눈부신 미녀를 만났다. 그렇지만 나중에 그녀는 무서운 괴물로 변했다. 커크는 몹시 놀랐다. 그 미녀는 이렇게 말했다. ``내가 모습을 바꿀 수 있다는 것을 몰랐나요(polymorph)?'').
다형성은 늦은 묶기(late binding)라고 부르는 특징을 사용하여 구현된다. 그렇게 부르는 이유는 (바탕 클래스의 함수인지 아니면 파생 클래스의 함수인지) 어느 함수를 호출할지 그 결정이 컴파일 시간에 이루어지는 것이 아니라 프로그램이 실제로 실행될 때까지 지연되기 때문이다. 실행 시간이 되어서야 어느 멤버 함수를 실제로 호출할지 결정한다.
C++에서 늦은 묶기는 함수가 호출되는 기본 방식이 아니다. 기본적으로 이른 묶기(early binding)가 사용된다. 다른 말로 정적 묶기(static binding)라고도 한다. 정적 묶기에서 호출되는 함수는 컴파일 시간에 컴파일러가 결정한다. 단순히 객체의 클래스 유형과 객체 포인터 또는 객체 참조만 사용한다.
늦은 묶기는 본질적으로 다른 (약간 더 느린) 처리 과정으로서 어떤 함수가 호출될지 컴파일 시간에 결정되지 않고 실행 시간에 결정된다. C++는 늦은 묶기와 이른 묶기를 모두 지원하기 때문에 C++ 프로그래머는 어느 묶기를 사용할지 당면한 상황에 따라 최적으로 선택하면 된다. (Java 언어처럼) 객체 지향적 편의기능을 제공하는 다른 많은 언어는 기본으로 늦은 묶기만 지원하거나 늦은 묶기가 기본값이다. C++ 프로그래머는 이를 잘 인지해야 한다. 이른 묶기가 기대되는 곳에서 늦은 묶기로 처리하면 성가신 버그를 양산할 가능성이 높다.
간단한 예제를 하나 살펴보자. 이른 묶기와 늦은 묶기 사이의 차이를 감상해 보자. 예제는 그저 예시용일 뿐이다. 왜 그런지는 잠시 후에 설명하겠다.
다음의 작은 프로그램을 연구해 보자:
#include <iostream>
using namespace std;
class Base
{
protected:
void hello()
{
cout << "base hello\n";
}
public:
void process()
{
hello();
}
};
class Derived: public Base
{
protected:
void hello()
{
cout << "derived hello\n";
}
};
int main()
{
Derived derived;
derived.process();
}
/*
출력:
base hello
*/
위 프로그램에서 중요한 특징은 hello 함수를 호출하는 Base::process 함수이다. process 함수가 공개 인터페이스에 유일하게 정의된 멤버 함수이므로 두 클래스에 속하지 않은 코드에서 유일하게 호출할 수 있는 함수이다. Base로부터 파생시킨 Derived 클래스는 Base 클래스의 인터페이스를 상속받았으므로 process 함수는 Derived 실체에서 사용할 수 있다. 그래서 main 함수에서 Derived 실체는 process 함수는 호출할 수 있지만 hello 함수는 호출하지 못한다.
지금까지는 문제가 없다. 새로운 것도 없고 모든 것은 이전 장에서 다룬 것들이다. 도대체 왜 Derived 클래스를 정의했는지 궁금하실 것이다. 의도적으로 Base::hello 멤버 함수의 구현과 다르게 적절한 hello 함수의 구현을 Derived 클래스에 정의했다. Derived 클래스를 만든 사람의 생각은 다음과 같았다. Base 클래스의 hello 함수 구현은 몹시 마음에 안든다. 적절한 구현을 제공해서 Derived 클래스 실체가 그것을 해결하도록 만들고 싶다. 게다가 우리의 저자는 다음과 같이 생각한다.
``실체의 유형이 사용중인 인터페이스를 결정하므로process함수는Derived::hello멤버 함수를 호출할 것이 틀림없다.hello함수는Derived클래스 실체로부터process함수를 통하여 호출되기 때문이다.''.
불행하게도 저자의 생각은 결점이 있다. 정적 묶기를 생각하지 못했다. Base::process 멤버가 컴파일될 때 정적 묶기 때문에 컴파일러는 hello 호출을 Base::hello()에 묶어 버린다.
저자의 의도는 Base 클래스와 is-a 관계인 Derived 클래스를 만드는 것이다. 그러나 부분적으로만 성공할 뿐이다. Base의 인터페이스는 상속받았지만, 그 이후로 Derived는 무슨 일이 일어날지에 관한 통제권을 모조리 포기해 버렸다. process 함수 안에 있으면 Base 클래스의 멤버 구현만 볼 수 있다. 다형성은 탈출구를 제공한다. (파생 클래스 안에서) 바탕 클래스의 멤버를 재정의할 수 있다. 이렇게 재정의된 멤버들을 바탕 클래스의 인터페이스를 통하여 사용할 수 있다.
이것이 바로 LSP의 핵심이다. 공개 상속은 바탕 클래스 멤버를 (파생 클래스 안에서) 재사용하는 데 있지 않고 파생 클래스의 멤버가 재사용되는 데 있다. (바탕 클래스 멤버를 재구현한 파생 클래스 멤버를 바탕 클래스가 다형적으로 사용하는 데 있다).
잠시 위의 작은 프로그램이 암시하는 것들을 감상해 보자. hello 멤버와 process 멤버가 그렇게 인상적이지는 않다. 그러나 이 예제에 관련된 의미는 다음과 같다. process 멤버는 디렉토리 순회를 구현할 수 있고 hello 멤버는 파일을 만날 때 수행할 조치를 정의할 수 있다. Base::hello 멤버 함수는 그저 파일의 이름을 보여줄 뿐이지만 Derived::hello 멤버 함수는 그 파일을 제거할 수도 있다. 특정 시각보다 새로우면 그냥 그 이름을 나열할 수도 있고; 어떤 텍스트가 담겨 있으면 그 이름을 나열할 수도 있다. 등등... 지금까지 Derived 클래스는 process 멤버의 조치 자체를 구현했어야 한다. 지금까지 Base 클래스의 참조나 포인터를 기대하는 코드는 Base의 행위만을 수행할 수 있을 뿐이었다.
다형성으로 바탕 클래스의 멤버를 재구현할 수 있고 그렇게 재구현된 멤버들을 바탕 클래스의 참조나 포인터를 기대하는 코드에서 사용할 수 있다. 다형성을 사용하면 바탕 클래스의 적절한 멤버들을 재구현한 파생 클래스가 기존의 코드를 재사용할 수도 있다. 어떻게 이 마법을 실현할 수 있는지 비밀을 파헤쳐 볼 차례이다.
C++에서 기본 값이 아닌 다형성으로 문제를 해결하고 마침내 클래스의 저자는 목적을 이룰 수 있다. 궁금한 독자는 Base 클래스의 void hello() 멤버 앞에 virtual 키워드를 붙이고 다시 컴파일해 보자. 변경된 프로그램을 실행하면 의도에 맞게 예상대로 derived hello를 보여준다. 왜 이런 일이 일어나는지 다음에 설명한다.
Vehicle *은 Vehicle 클래스의 멤버 함수를 활성화한다. 파생 클래스의 실체를 가리킬 때에도 그렇다. 이것을 이른 묶기 또는 정적 묶기라고 부른다. 호출할 함수는 컴파일 시간에 결정된다. C++에서 늦은 묶기 다시 말해 동적 묶기는 가상 멤버 함수를 사용하여 구현한다.
멤버 함수는 선언이 virtual 키워드로 시작하면 가상 멤버 함수가 된다. 다시 한 번 강조한다. 다른 객체 지향 언어와 다르게 C++는 동적 묶기가 아니라 정적 묶기를 기본으로 사용한다.
함수를 바탕 클래스에서 가상으로 선언하면 모든 파생 클래스에서도 그대로 가상 함수이다. 바탕 클래스에서 가상 함수로 선언한 멤버에 virtual 키워드를 붙이면 안된다. 파생 클래스에서 그런 멤버는 override 표시자를 붙여 주어야 한다. 그러면 컴파일러는 기존의 가상 멤버 함수를 실제로 참조하고 있는지 검증할 수 있다.
운송 분류 시스템에서 mass 멤버와 setMass 멤버에 집중하자 (13.1절). 이 멤버들은 Vehicle 클래스의 사용자 인터페이스를 정의한다. Vehicle 클래스에 그리고 이로부터 상속받은 모든 클래스에 이 사용자 인터페이스를 사용하고 싶다.
Vehicle 클래스로부터 상속받은 클래스에 상관없이 바탕 클래스의 사용자 인터페이스를 여전히 사용할 수 있도록 정의할 수 있다면 소프트웨어의 재사용도가 엄청나게 높아질 것이다. Vehicle 클래스의 사용자 인터페이스를 중심으로 설계하기만 하면 우리의 소프트웨어는 파생된 클래스들에도 적절하게 작동할 것이다. 평범한 상속으로는 이 목적을 달성할 수 없다.
std::ostream &operator<<(std::ostream &out, Vehicle const &vehicle)
{
return out << "Vehicle's mass is " << vehicle.mass() << " kg.";
}
위와 같이 정의했는데 Vehicle 클래스의 mass 멤버는 0을 돌려주지만 Car의 mass 멤버는 1000을 돌려준다면 다음 프로그램을 실행할 때 무게 0이 두 번 보고된다.
int main()
{
Vehicle vehicle;
Car vw(1000);
cout << vehicle << '\n' << vw << endl;
}
중복정의 삽입 연산자를 정의했다. 그러나 그것은 Vehicle 클래스의 사용자 인터페이스만 알기 때문에 `cout << vw'는 vw의 Vehicle 클래스의 사용자 인터페이스도 역시 사용할 것이다. 그래서 무게 0을 화면에 보여준다.
재사용이 가능한 인터페이스를 바탕 클래스의 인터페이스에 추가하면 재사용성이 개선된다. 재사용이 가능한 인터페이스로 파생 클래스는 사용자 인터페이스에 영향을 미치지 않고 자신만의 구현을 채워 넣을 수 있다. 동시에 사용자 인터페이스는 바탕 클래스의 기본 구현은 물론이고 파생 클래스의 의도에 맞게 행위할 것이다.
재사용 가능한 인터페이스의 멤버는 클래스의 비공개 구역에 선언해야 한다. 개념적으로 그것들은 자신의 클래스에 속해 있다 (14.7절 ). 바탕 클래스에서 이 멤버들은 가상으로 선언해야 한다. 이 멤버들은 파생 클래스가 다시 정의할 수 있다. 그리고 거기에 override 표시자를 붙여야 한다.
사용자 인터페이스(mass)는 그대로 유지하고 재사용 가능한 vmass 멤버를 Vehicle 클래스의 인터페이스에 추가했다.
class Vehicle
{
public:
size_t mass() const;
size_t si_mass() const; // 아래 참고
private:
virtual size_t vmass() const;
};
사용자 인터페이스와 재사용 가능한 인터페이스를 분리하는 것이 합리적이다. 그러면 한 곳에서만 유지관리하면 되므로 사용자 인터페이스를 세밀하게 조율할 수 있고 그와 동시에 앞으로 예상되는 재사용 가능한 인터페이스의 멤버의 행위를 표준화할 수 있다. 예를 들어 많은 나라에서 국제 도량형을 사용한다. 무게에 킬로그램을 단위로 사용한다. 어떤 나라는 다른 단위를 사용한다 (예를 들어 lbs: 1 kg은 대략 2.2046 lbs임). 사용자 인터페이스를 재사용 가능한 인터페이스와 분리하면 재사용 가능한 인터페이스에 표준을 사용할 수 있고 다른 사용자 인터페이스에는 정보를 변환할 수 있는 유연성을 자유자재로 구사할 수 있다.
두 인터페이스를 깔끔하게 분리하기 위해 또다른 접근자를 Vehicle 클래스에 추가하는 방법을 고려해 볼 수 있다. si_mass 멤버를 제공한다면 다음과 같이 간단하게 구현할 수 있다.
size_t Vehicle::si_mass() const
{
return vmass();
}
Vehicle 클래스가 d_massFactor 멤버를 지원하면 mass 멤버는 다음과 같이 구현할 수 있다.
size_t Vehicle::mass()
{
return d_massFactor * si_mass();
}
Vehicle 자체는 토큰 값을 돌려주도록 vmass 멤버를 정의할 수 있다. 예를 들어,
size_t Vehicle::vmass()
{
return 0;
}
Car 클래스를 살펴 보자. Vehicle 클래스로부터 파생되었고 그의 사용자 인터페이스를 상속받았다. 또 멤버 데이터로 size_t d_mass 멤버가 있고 자신만의 재사용 가능한 인터페이스를 구현하고 있다.
class Car: public Vehicle
{
...
private:
size_t vmass() override;
}
Car 클래스의 생성자가 d_mass 멤버에 저장된 자동차의 무게를 지정하기를 요구하면 Car 클래스는 자신의 vmass 멤버를 다음과 같이 구현하면 된다.
size_t Car::vmass() const
{
return d_mass;
}
Car 클래스로부터 상속받은 Truck 클래스는 트랙터의 무게와 트레일러의 무게가 필요하다. 트랙터의 무게는 Car 바탕 클래스에 건네지고 트레일러의 무게는 Vehicle d_trailor 멤버 데이터에 건네진다. Truck 클래스도 vmass 멤버를 재정의한다. 이 번에는 트랙터와 트레일러의 무게를 합해서 돌려준다.
size_t Truck::vmass() const
{
return Car::si_mass() + d_trailer.si_mass();
}
클래스 멤버가 가상으로 선언되어 있으면 이 멤버에 override 표시자가 있건 없건 상관없이 모든 파생 클래스에서 가상 멤버가 된다. 그러나 override 키워드는 꼭 사용해야 한다. 그래야 컴파일러가 파생 클래스 인터페이스를 써 내려갈 때 식자 오류를 잡아낼 수 있기 때문이다.
멤버 함수는 클래스 계통도 어디에든 virtual로 선언할 수 있다. 그러나 이렇게 하면 아마도 그 아래의 다형적 클래스 설계를 부술 가능성이 있다. 원래의 바탕 클래스는 더 이상 파생 클래스의 재사용 가능한 인터페이스를 완전하게 다루지 못하기 때문이다. mass 멤버가 Car 클래스에서는 virtual로 선언되어 있지만 Vehicle 클래스에서는 그렇지 않다면 특정한 가상 멤버만 Car 실체에 그리고 그로부터 파생된 클래스 실체에 사용할 수 있을 것이다. Vehicle 클래스의 포인터나 참조에는 여전히 정적 묶기가 사용될 것이다.
아래에 늦은 묶기(다형성)의 효과를 보여준다.
void showInfo(Vehicle &vehicle)
{
cout << "Info: " << vehicle << '\n';
}
int main()
{
Car car(1200); // 무게가 1200인 자동차
Truck truck(6000, 115, // 캐빈 무게가 6000인 트럭,
"Scania", 15000); // 속도는 115, 제조사는 Scania,
// 무게가 15000인 트레일러
showInfo(car); // 아래 (1) 참고
showInfo(truck); // 아래 (2) 참고
Vehicle *vp = &truck;
cout << vp->speed() << '\n';// 에러 발생, 아래 (3) 참고
}
mass가 virtual로 선언되어 있고 늦은 묶기가 사용된다.
Car의 무게를 보여준다.
Truck의 무게를 보여준다.
speed 멤버는 Vehicle 클래스의 멤버가 아니다. 그래서 Vehicle* 포인터를 통하여 호출할 수 없다.
가상 멤버를 통하여 파생 클래스는 바탕 클래스 멤버로부터 또는 바탕 클래스를 가리키는 포인터나 참조로부터 호출된 함수가 수행하는 행위를 재정의할 수 있다. 이렇게 바탕 클래스의 멤버를 파생 클래스가 재정의하는 것을 멤버를 재정의한다라고 부른다.
Vehicle *vp = new Land(1000, 120);
delete vp; // 객체 소멸
먼저 바탕 클래스 포인터를 삭제한다. 바탕 클래스에 인터페이스가 정의되어 있기 때문에 delete vp는 ~Vehicle을 호출하고 ~Land는 여전히 눈에 보이지 않는다. Land가 메모리를 할당하고 있다면 메모리 누수가 일어난다. 메모리 해제만이 소멸자가 수행할 수 있는 유일한 조치는 아니다. 일반적으로 객체가 존재하기를 멈출 때 필요한 조치는 무엇이든 할 수 있다. 그러나 여기에서 ~Land가 정의한 조치는 무엇이든 수행되지 않는다.
C++는 이 문제를 가상 소멸자로 해결할 수 있다. 소멸자를 virtual로 선언할 수 있다. 바탕 클래스 소멸자를 가상으로 선언하면 delete bp를 실행할 때 바탕 클래스 포인터 bp가 가리키는 실제 클래스의 소멸자가 호출된다. 그리하여 파생 클래스의 소멸자가 이름이 유일함에도 불구하고 그 소멸자에는 늦은 묶기가 실현된다. 예를 들어:
class Vehicle
{
public:
virtual ~Vehicle(); // 파생된 클래스 소멸자도
// 모두 가상이다.
};
가상 소멸자를 선언함으로써 위의 delete vp 연산은 Vehicle 클래스의 소멸자가 아니라 올바르게 Land의 소멸자를 호출한다.
일단 소멸자가 호출되면 평소대로 수행된다. 가상 소멸자이든 아니든 상관이 없다. 그래서 ~Land는 먼저 자신의 서술문을 실행한 다음에 ~Vehicle을 호출한다. 그리하여 위의 delete vp 서술문은 늦은 묶기를 사용하여 ~Vehicle을 호출하고 이 시점부터 평소대로 객체가 소멸된다.
다른 클래스들이 파생되어 나갈 바탕 클래스로 설계된 클래스라면 소멸자는 언제나 virtual로 선언해야 한다. 소멸자 자체가 아무 일도 수행하지 않는 경우가 가끔 있다. 이 경우 가상 소멸자의 몸체는 비어 있다. 예를 들어 Vehicle::~Vehicle()의 정의는 다음과 같이 단순하다.
Vehicle::~Vehicle()
{}
가상 소멸자를 (심지어 빈 소멸자를) 인라인으로 정의하고픈 유혹을 이겨 내라. 그렇게 하면 클래스를 유지관리하기가 복잡해진다. 14.11절에 이 제일 규칙 뒤에 숨은 이유를 연구한다.
Vehicle 바탕 클래스에 mass 그리고 setMass 가상 멤버를 구체적으로 구현한다. 그렇지만 가상 멤버 함수는 반드시 바탕 클래스에 구현되어 있어야 할 필요가 없다.
가상 멤버의 구현을 바탕 클래스로부터 생략하면 바탕 클래스는 구현할 책임을 파생 클래스에게 떠넘긴다. 파생 클래스는 `빠진 구현'을 제공해야 한다.
C#와 Delphi 그리고 Java 같은 여러 언어에서 인터페이스라고 부르는 이런 접근법은 프로토콜을 정의한다. 파생 클래스는 아직 구현되지 않은 멤버를 구현함으로써 프로토콜을 준수해야 한다. 구현이 빠진 멤버가 하나라도 있다면 그 클래스는 어떤 객체도 정의할 수 없다.
그렇게 불완전하게 정의되는 클래스는 언제나 바탕 클래스이다. 바탕 클래스는 그저 이름만 정의함으로써 프로토콜을 강제한다. 그리고 멤버의 값과 인자를 돌려준다. 이런 클래스를 추상 클래스 또는 추상 바탕 클래스라고 부른다. 파생 클래스는 아직 구현되지 않은 멤버들을 구현함으로써 비-추상 클래스가 된다.
추상 바탕 클래스는 많은 디자인 패턴의 토대이다 (참고 Gamma et al. (1995)). 덕분에 프로그래머는 재사용도가 높은 소프트웨어를 만들 수 있다. 이런 디자인 패턴은 이 책에서도 다루지만 (24.2절의 Template Method) 디자인 패턴을 깊게 연구하려면 감마(Gamma et al.)의 책을 참고하라.
바탕 클래스에 단순히 선언만 되어 있는 멤버를 순수 가상 함수라고 부른다. 가상 함수는 선언의 끝에다 = 0을 붙이면 (즉, 선언의 끝에 있는 쌍반점을 `= 0;'으로 교체하면) 순수 가상 멤버가 된다. 예제:
#include <iosfwd>
class Base
{
public:
virtual ~Base();
virtual std::ostream &insertInto(std::ostream &out) const = 0;
};
inline std::ostream &operator<<(std::ostream &out, Base const &base)
{
return base.insertInto(out);
}
Base로부터 파생된 클래스는 모두 반드시 insertInto 멤버 함수를 구현해야 한다. 그렇지 않으면 객체를 생성할 수 없다. 이것은 환영할 일이다. Base로부터 파생된 클래스 유형의 객체를 언제나 ostream 객체에 삽입할 수 있기 때문이다.
바탕 클래스의 가상 소멸자는 언제나 순수 가상 함수가 될 수 있을까? 이 질문에 대답은 '아니오'이다. 무엇보다, 파생 클래스에 소멸자를 강제할 필요가 없다. (소멸자를 = delete 속성으로 선언하지 않는 한) 소멸자는 기본으로 주어지기 때문이다. 둘째, 소멸자가 순수 가상 함수라면 구현이 존재하지 않는다. 그렇지만 파생 클래스의 소멸자는 결국 바탕 클래스의 소멸자를 호출한다. 구현이 없는데 어떻게 바탕 클래스의 소멸자를 호출할 수 있겠는가? 다음 항에 더 자세히 연구해 보겠다.
순수 가상 멤버 함수는 반드시는 아니지만 const 멤버 함수인 경우가 있다. 이렇게 하면 불변 파생 클래스 실체를 생성할 수 있다. 다른 상황이라면 이것은 필요하지 않을지도 모르며 (다시 말해 현실적이지 않으며) 가변 멤버 함수를 요구할 가능성이 있다. const 멤버 함수에 대한 일반 규칙은 순수 가상 함수에도 적용된다. 멤버 함수가 객체의 멤버 데이터를 변경하면 const 멤버 함수가 될 수 없다.
추상 바탕 클래스는 멤버 데이터가 없는 경우가 많다. 그렇지만 바탕 클래스가 순수 가상 멤버를 선언하면 파생 클래스에도 동일하게 선언해야 한다. 파생 클래스의 순수 가상 함수의 구현이 파생 클래스 실체의 데이터를 변경하면 그 함수는 const 멤버로 선언할 수 없다. 그러므로 추상 바탕 클래스의 저자는 순수 가상 멤버가 const 멤버 함수인지 아닌지 주의깊게 살펴야 한다.
= 0;를 지정해야 하지만 구현도 해야 한다. = 0;은 쌍반점으로 끝나므로 순수 가상 멤버는 언제나 클래스에 선언만 될 뿐이다. 그러나 (어쩌면 inline을 사용하여) 인터페이스 밖에 구현할 수도 있다.
파생 클래스 실체나 클래스 또는 파생 클래스 멤버로부터 순수 가상 멤버 함수를 호출할 수 있다. 호출될 멤버와 함께 바탕 클래스와 영역 지정 연산자를 지정하면 된다. 예를 들어:
#include <iostream>
class Base
{
public:
virtual ~Base();
virtual void pureimp() = 0;
};
Base::~Base()
{}
void Base::pureimp()
{
std::cout << "Base::pureimp() called\n";
}
class Derived: public Base
{
public:
virtual void pureimp();
};
inline void Derived::pureimp()
{
Base::pureimp();
std::cout << "Derived::pureimp() called\n";
}
int main()
{
Derived derived;
derived.pureimp();
derived.Base::pureimp();
Derived *dp = &derived;
dp->pureimp();
dp->Base::pureimp();
}
// 다음과 같이 출력됨:
// Base::pureimp() called
// Derived::pureimp() called
// Base::pureimp() called
// Base::pureimp() called
// Derived::pureimp() called
// Base::pureimp() called
순수 가상 멤버를 구현해 봐야 별 쓸모가 없다. 바탕 클래스 수준에서 이미 수행이 가능한 작업을 순수 가상 멤버 함수의 구현이 대신해 수행할 수 있다고 주장할 수 있겠다. 그렇지만 바탕 클래스의 가상 멤버 함수가 실제로 호출될 것이라는 보장이 없다. 그러므로 바탕 클래스에 종속적인 작업도 별도의 멤버로 제공해야 한다. 실제 작업을 수행하는 멤버와 프로토콜을 강제하는 순수 가상 멤버 사이의 경계를 구분지을 필요는 없다.
Value 클래스는 값 클래스이다. 복사 생성자와 중복정의 할당 연산자 어쩌면 이동 연산 그리고 공개 비-가상 생성자를 제공한다. 14.7절에서 그런 클래스는 바탕 클래스로 알맞지 않다고 주장했다. 새 클래스는 Value로부터 상속받으면 안 된다. 어떻게 이것을 강제할까?
Base 클래스는 v_process(int32_t) 가상 멤버를 구현한다. Base으로부터 파생된 클래스는 이 멤버를 재정의할 필요가 있다. 그러나 저자는 실수로 v_proces(int32_t)를 정의해 버렸다. 파생 클래스의 다형적 행위를 깨는 그런 에러를 어떻게 방지할까?
Base 클래스로부터 파생된 Derived 클래스는 Base::v_process 멤버를 재정의한다. 그러나 이번에는 Derived으로부터 파생된 클래스는 더 이상 v_process를 재정의하면 안되지만 v_call과 v_display 같은 다른 가상 멤버들은 재정의해도 된다. Derived으로부터 파생된 클래스에 어떻게 이 제한적인 다형적 성격을 강제할까?
final 식별자와 override 식별자를 사용하면 위의 문제들을 해결할 수 있다. 이 식별자들은 특정한 문맥에서만 특별한 의미를 지닌다. 이 문맥을 벗어나면 그저 평범한 식별자일 뿐이다. 다른 문맥에서는 bool final과 같이 변수로 정의해도 된다.
final 식별자를 클래스 선언에 적용하면 그 클래스가 바탕 클래스로 사용되면 안된다고 지시할 수 있다. 예를 들어:
class Base1 final // 바탕 클래스 불가
{};
class Derived1: public Base1 // 에러: Base1이 마지막이다.
{};
class Base2 // 바탕 클래스로 OK
{};
class Derived2 final: public Base2 // OK, 그러나 Derived2는
{}; // 바탕 클래스로 사용할 수 없다.
class Derived: public Derived2 // 에러: Derived2가 마지막이다.
{};
final 식별자를 가상 멤버 선언에도 추가할 수 있다. 그런 가상 멤버들을 파생 클래스가 재정의하면 안 된다는 뜻이다. 위에서 언급한 클래스의 제한적인 다형적 성격은 다음과 같이 실현할 수 있다.
class Base
{
virtual int v_process(); // 다형적 행위를 정의한다.
virtual int v_call();
virtual int v_display();
};
class Derived: public Base // Derived는 v_call과 v_display에
{ // 다형성을 제한한다.
virtual int v_process() final;
};
class Derived2: public Derived
{
// int v_process(); 더 이상 진행 불가: Derived::v_process가 마지막이다.
virtual int v_display(); // 재정의 OK
};
컴파일러가 철자오류나 매개변수 유형의 차이 또는 (const vs. non-const와 같이) 멤버 함수 수식자의 차이를 탐지하도록 허용하려면 바탕 클래스 멤버를 재정의하는 파생 클래스 멤버에 override 식별자를 추가하면 (해야) 된다. 예를 들어,
class Base
{
virtual int v_process();
virtual int v_call() const;
virtual int v_display(std::ostream &out);
};
class Derived: public Base
{
virtual int v_proces() override; // 에러: v_proces != v_process
virtual int v_call() override; // 에러: const 아님
// 에러: 매개변수 유형이 다름
virtual int v_display(std::istream &out) override;
};
요약하면 final 키워드는 더 이상의 상속을 방지하고 override 키워드는 정확하게 똑 같은 서명으로 재정의되었는지 컴파일러에게 점검해 달라고 요청하는 것이다.
ifstream 클래스와 ofstream 클래스의 특징을 제공하는 fstream 클래스를 만나 보았다. 제 13장에서 클래스를 여러 바탕 클래스로부터 파생시킬 수 있음을 배웠다. 그렇게 파생된 클래스는 바탕 클래스들의 특성을 모두 물려 받는다. 다형성도 역시 다중 상속과 조합하여 사용할 수 있다.
파생 클래스로부터 바탕 클래스로 올라가는 길이 `여러 갈래'일 경우 어떤 일이 일어날지 생각해 보자. 이것을 (인위적으로 만든) 다음 예제에 보여준다. Derived 클래스는 Base 클래스로부터 두 번 상속받는다.
class Base
{
int d_field;
public:
void setfield(int val);
int field() const;
};
inline void Base::setfield(int val)
{
d_field = val;
}
inline int Base::field() const
{
return d_field;
}
class Derived: public Base, public Base
{
};
두 번 파생했기 때문에 Base의 기능은 Derived 클래스에 두 번 일어난다. 이 때문에 모호성이 발생한다. Derived 클래스 실체에 setfield() 함수를 호출하면 둘 중에 어느 함수가 호출될 것인가? 영역 지정 연산자는 도움이 되지 않는다. 그래서 C++ 컴파일러는 위의 예제를 컴파일할 수 없으며 에러를 (올바르게) 식별한다.
위의 코드는 확실하게 바탕 클래스를 중복해서 파생시킨다. 물론 쉽게 피할 수 있다. Base를 두 번 상속받지 않으면 된다 (또는 합성을 사용하면 된다!). 그러나 바탕 클래스의 복제는 내포 상속을 통해서도 일어날 수 있다. Car 클래스와 Air 클래스로부터 객체를 상속받는다면 (13.1절) 그런 클래스는(제임스 본드의 황금총을 가진 사나이에서 볼 수 있는 자동차와 같이) 하늘을 나는 자동차를 표현하는 데 필요할 것이다. AirCar 클래스는 결국 두 개의 Vehicle을 갖게 된다. 그러므로 두 개의 mass 필드와 두 개의 setMass() 함수 그리고 두개의 mass() 함수를 갖게 된다. 이것이 과연 원한 것인가?
Car 클래스와 Air 클래스로부터 상속받을 때 왜 AirCar 클래스가 모호성을 초래하는지 더 자세히 조사해 보자.
AirCar는 Car이다. 그러므로 Land이고 따라서 Vehicle 클래스이다.
AirCar는 또 Air이다. 그러므로 Vehicle 클래스이다.
Vehicle 클래스의 데이터 복제는 그림 14에 보여준다.
AirCar 클래스의 내부 조직은 그림 15에 보여준다.
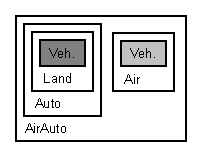
AirCar 객체의 내부 조직.
AirCar 실체에서 모호성을 탐지한다. 그러므로 다음과 같은 서술문을 컴파일하지 않을 것이다.
AirCar jBond;
cout << jBond.mass() << '\n';
어느 mass 멤버 함수를 호출할지 컴파일러가 결정할 수 없기 때문이다. 그러나 모호성을 해결하기 위해 두 가지 방법이 있다.
// mass 멤버가 Car 객체에 // 있다고 기대하자. cout << jBond.Car::mass() << '\n';영역 지정 연산자와 클래스 이름을 멤버 함수 바로 앞에 놓는다.
AirCar 클래스에 전용 mass 함수를 만들 수 있다.
int AirCar::mass() const
{
return Car::mass();
}
AirCar를 사용하는 프로그래머는 특별히 주의를 기울이지 않아도 되기 때문이다.
그렇지만 더 우아한 해결책이 있다. 다음 항에 논의한다.
AirCar는 두 개의 Vehicle을 나타낸다. 이 때문에 어느 함수를 사용하여 mass 멤버 데이터에 접근할지 모호할 뿐만 아니라 두 개의 mass 필드가 AirCar에 정의되어 버린다. 이것은 별로 쓸모가 없다. AirCar는 mass가 하나 뿐이라고 간주하기 때문이다.
그러나 Vehicle은 하나이지만 여전히 다중 상속을 사용하는 클래스로 AirCar를 정의할 수 있다. 파생 클래스의 상속 트리에 여러 번 언급되는 바탕 클래스를 가상으로 상속받아 실현한다.
이것은 Land 클래스와 Air 클래스로부터 AirCar를 파생시킬 때 조금 변경해야 함을 의미한다.
class Land: virtual public Vehicle
{
// etc
};
class Car: public Land
{
// etc
};
class Air: virtual public Vehicle
{
// etc
};
class AirCar: public Car, public Air
{
};
가상 상속으로 Vehicle 클래스는 한 번만 파생 클래스에 추가된다. 이것은 Vehicle 클래스가 AirCar 클래스에 추가되는 경로가 더 이상 바탕 클래스에 직접적으로 의존하지 않는다는 뜻이다. AirCar 실체는 Vehicle 실체라고 주장할 수 있다. 가상 상속 이후에 AirCar 객체의 내부 조직을 그림 16에 보여준다.
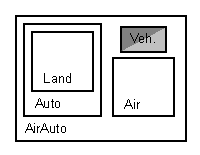
AirCar 객체의 내부 조직.
Third 클래스가 Second 바탕 클래스로부터 파생되고 Second는 First 바탕 클래스로부터 파생되었다면 Third 객체를 생성할 때 Third 생성자는 Second 생성자를 호출하고 Second 생성자는 First 클래스 생성자를 호출한다. 예를 들어:
class First
{
public:
First(int x);
};
class Second: public First
{
public:
Second(int x)
:
First(x)
{}
};
class Third: public Second
{
public:
Third(int x)
:
Second(x) // First(x)를 호출
{}
};
위의 예는 Second가 가상 상속을 사용하면 더 이상 유효하지 않다. Second가 가상 상속을 사용하면 Third가 Second의 생성자를 호출해도 무시된다. 대신에 Second는 기본으로 First의 기본 생성자를 호출한다. 이것을 다음 예제에 보여준다.
class First
{
public:
First()
{
cout << "First()\n";
}
First(int x);
};
class Second: public virtual First // virtual에 주목
{
public:
Second(int x)
:
First(x)
{}
};
class Third: public Second
{
public:
Third(int x)
:
Second(x)
{}
};
int main()
{
Third third(3); // 출력 `First()'
}
Third를 생성할 때 First의 기본 생성자가 사용된다. 그렇지만 Third의 생성자는 이 기본 행위를 지배할 수 있다. 사용할 생성자를 명시적으로 지정하면 된다. First 객체를 먼저 사용할 수 있어야 Second를 생성할 수 있으므로 먼저 지정해야 한다. Third(int)를 생성할 때 First(int)를 호출하기 위해 Third의 생성자를 다음과 같이 사용할 수 있다.
class Third: public Second
{
public:
Third(int x)
:
First(x), // First(int)가 호출된다.
Second(x)
{}
};
이 행위는 단순하게 선형적으로 상속받을 때는 혼란스러워 보인다. 그러나 가상 상속을 사용하는 바탕 클래스와 함께 다중 상속이 사용될 경우에는 의미가 있다. AirCar를 생각해 보자: Air와 Car가 둘 다 가상적으로 Vehicle로부터 상속받는다면 둘 다 공통적인 Vehicle 객체를 초기화할 것인가? 그렇다면 둘 중에 어느 것이 먼저 호출될까? Air와 Car가 서로 다른 Vehicle 생성자를 사용하면 어떻게 될까? 이 모든 의문은 단번에 해결할 수 있다. 공통 바탕 클래스의 초기화 책임을 결국 그 클래스를 사용할 파생 클래스에게 맡기면 된다. 위의 예제에서는 Third가 책임을 진다. 그러므로 First를 초기화할 때 사용할 생성자를 지정할 기회는 Third에게 주어진다.
가상 상속을 전혀 사용하지 않는 클래스를 다중 상속할 수도 있다. Derived1과 Derived2 두 개의 클래스가 있고 둘 다 Base로부터 파생된다 (가상적 파생도 가능).
다음 질문에 접근해 보자. Final: public Derived1, public Derived2 클래스의 생성자를 호출하면 어느 생성자가 호출될 것인가?
먼저 관련 생성자들을 구분하자. Base1은 Derived1이 바탕 클래스 초기화를 위해 호출하는 Base 클래스 생성자를 나타낸다. 비슷하게 Base2는 Derived2가 바탕 클래스 초기화를 위해 호출하는 Base 클래스 생성자를 나타낸다. Base는 그냥 Base의 기본 생성자를 나타낸다.
Derived1과 Derived2는 Final 객체를 생성할 때 사용되는 바탕 클래스 초기화자를 나타낸다.
이제 Final: public Derived1, public Derived2 클래스의 실체를 생성할 때의 다양한 사례를 구별할 준비가 되었다.
Derived1: public Base Derived2: public Base
다음은 보통의 비-가상 다중 상속이다. 생성자가 다음 순서대로 호출된다.Base1, Derived1, Base2, Derived2
Derived2만 가상 상속:
Derived1: public Base Derived2: virtual public Base
Derived2만 가상 상속을 사용한다.Derived2의 바탕 클래스 생성자는 무시된다. 대신에Base가 호출된다. 다른 어떤 생성자보다 먼저 호출된다.Base, Base1, Derived1, Derived2클래스 하나만 가상 상속을 사용하므로 두 개의Base클래스 실체는 마지막Final클래스에서도 여전히 사용할 수 있다.
Derived1만 가상 상속:
Derived1: virtual public Base Derived2: public Base
Derived1만 가상 상속을 사용한다.Derived1의 바탕 클래스 생성자는 무시된다. 대신에Base가 호출되고 다른 어떤 생성자보다 먼저 호출된다. 첫 번째 (비-가상) 사례와 다르게Base1이 아니라Base가 호출된다.Base, Derived1, Base2, Derived2
Derived1: virtual public Base Derived2: virtual public Base
두 클래스 모두 가상 상속을 사용한다. 그래서 하나의Base클래스 실체만Final클래스 실체에 존재할 것이다. 다음 생성자들이 순서대로 호출된다.Base, Derived1, Derived2
Truck의 정의를 연구해 보자 (13.5절):
class Truck: public Car
{
int d_trailer_mass;
public:
Truck();
Truck(int engine_mass, int sp, char const *nm,
int trailer_mass);
void setMass(int engine_mass, int trailer_mass);
int mass() const;
};
Truck::Truck(int engine_mass, int sp, char const *nm,
int trailer_mass)
:
Car(engine_mass, sp, nm)
{
d_trailer_mass = trailer_mass;
}
int Truck::mass() const
{
return // 다음 무게의 합:
Car::mass() + // 엔진 무게 더하기
trailer_mass; // 트레일러 무게
}
이 정의는 두 개의 mass 필드를 포함하기 위하여 어떻게 Truck 객체를 생성하는지 보여준다. 하나는 Car으로부터 상속받아 생성하고 또 하나는 int d_trailer_mass 멤버 데이터를 통하여 생성한다. 물론 그렇게 정의해도 유효하다. 그러나 재작성할 수도 있다. Truck을 Car로부터 그리고 Vehicle로부터 상속받을 수 있다. 그 다음에 명시적으로 Vehicle 클래스가 두 번 존재하기를 요구하면 된다. 하나는 엔진과 캐빈의 무게에 대해 그리고 또 하나는 트레일러의 무게에 대해 존재하기를 요구한다. 약간 복잡한 것은 다음과 같은 클래스 조직을 C++ 컴파일러가 받아 들이지 않는다는 것이다.
class Truck: public Car, public Vehicle
Vehicle 클래스가 이미 Car의 일부이기 때문이다. 그러므로 다시 또 필요하지 않다. 그렇지만 약간의 트릭을 사용하여 강제로 이렇게 조직할 수 있다. Vehicle으로부터 직접 상속받을 것이 아니라 Vehicle로부터 상속받아 추가 클래스를 만들고 그 추가 클래스로부터 Truck을 상속받으면 문제가 해결된다. 그냥 Vehicle으로부터 TrailerVeh 클래스를 상속받은 다음에 Truck을 Car와 TrailerVeh로부터 상속받으면 된다.
class TrailerVeh: public Vehicle
{
public:
TrailerVeh(int mass)
:
Vehicle(mass)
{}
};
class Truck: public Car, public TrailerVeh
{
public:
Truck();
Truck(int engine_mass, int sp, char const *nm, int trailer_mass);
void setMass(int engine_mass, int trailer_mass);
int mass() const;
};
inline Truck::Truck(int engine_mass, int sp, char const *nm,
int trailer_mass)
:
Car(engine_mass, sp, nm),
TrailerVeh(trailer_mass)
{}
inline int Truck::mass() const
{
return // 다음의 합계:
Car::mass() + // 엔진 무게 더하기
TrailerVeh::mass(); // 트레일러 무게
}
dynamic_cast와 typeid 연산자를 통하여 제공한다.
dynamic_cast는 바탕 클래스의 포인터나 참조를 파생 클래스의 포인터나 참조로 변환한다. 이를 하향-형변환이라고 한다.
typeid 연산자는 표현식의 실제 유형을 돌려준다.
dynamic_cast<> 연산자를 사용하면 바탕 클래스의 포인터나 참조를 각각 파생 클래스의 포인터나 참조로 변환할 수 있다. 이를 하향-형변환이라고 한다. 변환의 방향이 계통도 아래를 향하기 때문이다.
동적 유형변환은 실행 시간에 결정된다. 바탕 클래스가 가상 멤버 함수를 선언한 경우에만 사용할 수 있다. 동적 유형변환이 성공하려면 목표 클래스의 Vtable이 동적 유형변환의 인자가 참조하는 Vtable과 같아야 한다. (포인터를 동적으로 변환하기를 요구한 경우) 유형변환이 실패해서 0을 돌려주거나 또는 (참조를 동적으로 변환하기를 요구한 경우) std::bad_cast 예외를 던지지만 않는다면 말이다.
다음 예제에서 Derived 클래스를 가리키는 포인터는 Base 클래스 포인터 bp로부터 얻는다.
class Base
{
public:
virtual ~Base();
};
class Derived: public Base
{
public:
char const *toString();
};
inline char const *Derived::toString()
{
return "Derived object";
}
int main()
{
Base *bp;
Derived *dp,
Derived d;
bp = &d;
dp = dynamic_cast<Derived *>(bp);
if (dp)
cout << dp->toString() << '\n';
else
cout << "dynamic cast conversion failed\n";
}
위의 if 조건 서술문에서 동적 유형변환이 성공했는지 실행 시간에 검증한다. 포인터가 가리키는 객체의 실제 클래스는 그 때가 되어서야 겨우 알려지기 때문이다.
바탕 클래스의 포인터가 제공되면 동적 유형변환 연산자는 실패시 0을 돌려준다. 성공하면 요청된 파생 클래스를 포인터로 돌려준다.
vector<Base *>를 사용한다고 가정하자. 그런 벡터의 포인터는 Base로부터 파생된 다양한 모든 클래스의 실체를 가리킬 수 있다. 바탕 클래스에 그 실체를 가리키는 포인터가 지정되어 있다면 동적 유형변환은 그 포인터를 돌려주고 그렇지 않으면 0을 돌려준다.
일련의 점검을 수행하면 포인터가 가리키는 실체의 실제 클래스를 결정할 수 있다. 예를 들어:
class Base
{
public:
virtual ~Base();
};
class Derived1: public Base;
class Derived2: public Base;
int main()
{
vector<Base *> vb(initializeBase());
Base *bp = vb.front();
if (dynamic_cast<Derived1 *>(bp))
cout << "bp points to a Derived1 class object\n";
else if (dynamic_cast<Derived2 *>(bp))
cout << "bp points to a Derived2 class object\n";
}
대안으로 바탕 클래스 실체를 참조할 수 있다. 이 경우 하향 유형변환에 실패하면 dynamic_cast 연산자는 예외를 던진다. 예제:
#include <iostream>
#include <typeinfo>
class Base
{
public:
virtual ~Base();
virtual char const *toString();
};
inline char const *Base::toString()
{
return "Base::toString() called";
}
class Derived1: public Base
{};
class Derived2: public Base
{};
Base::~Base()
{}
void process(Base &b)
{
try
{
std::cout << dynamic_cast<Derived1 &>(b).toString() << '\n';
}
catch (std::bad_cast)
{}
try
{
std::cout << dynamic_cast<Derived2 &>(b).toString() << '\n';
}
catch (std::bad_cast)
{
std::cout << "Bad cast to Derived2\n";
}
}
int main()
{
Derived1 d;
process(d);
}
/*
출력:
Base::toString() called
Bad cast to Derived2
*/
예제에 std::bad_cast 값이 사용된다. 파생 클래스 실체에 대한 참조의 동적 유형변환에 실패하면 std::bad_cast 예외가 던져진다.
catch 절의 형태에 주목하라: bad_cast는 유형의 이름이다. 17.4.1항에 그런 유형을 어떻게 정의할 수 있는지 기술한다.
동적 유형변환 연산자는 기존의 바탕 클래스가 변경되면 안되거나 변경할 수 없을 때 (자원이 없을 때) 그 대신에 파생 클래스를 변경할 때 유용한 도구이다. 그러면 바탕 클래스의 포인터나 참조를 받는 코드는 파생 클래스에 동적 유형변환을 수행하여 그의 기능에 접근할 수 있다.
어떤 점에서 dynamic_cast의 행위가 static_cast의 행위와 다른지 자못 궁금하실 것이다.
static_cast가 사용되면 컴파일러는 표현식 유형에 대한 포인터나 참조를 목표 유형의 포인터나 참조로 변환해야 한다. 이것은 바탕 클래스가 가상 멤버를 선언하든 말든 상관없이 유효하다. 결론적으로 static_cast의 모든 조치는 컴파일러가 결정할 수 있다. 다음은 문제없이 컴파일된다.
class Base
{
// 가상 멤버일 수도 아닐 수도 있다.
};
class Derived1: public Base
{};
class Derived2: public Base
{};
int main()
{
Derived1 derived1;
Base *bp = &derived1;
Derived1 &d1ref = static_cast<Derived1 &>(*bp);
Derived2 &d2ref = static_cast<Derived2 &>(*bp);
}
두 번째 static_cast에 주목하자. 여기에서 Base 클래스 실체는 Derived2 클래스 참조로 유형변환된다. 컴파일에 아무 문제가 없다. Base와 Derived2는 상속으로 관련되어 있기 때문이다.
그렇지만 의미구조적으로 의미가 없다. 사실 bp가 Derived1 클래스 실체를 가리키기 때문이다. 이것은 dynamic_cast로 탐지된다. dynamic_cast는 static_cast처럼 관련 포인터나 참조 유형을 변환한다. 그러나 dynamic_cast는 실행 시간 보호책을 제공한다. 가리키고 있는 실제 유형과 요청된 유형이 부합하지 않으면 동적 유형변환은 실패한다. 게다가 dynamic_cast는 static_cast보다 훨씬 더 제한적으로 사용된다. dynamic_cast는 가상 멤버를 가진 파생 클래스로의 하향 유형변환에만 사용할 수 있다.
결국 동적 유형변환은 형변환이고 형변환은 가능하면 피하는 게 좋다. 동적 유형변환이 필요하면 바탕 클래스가 올바르게 설계되어 있는지 스스로에게 물어보자. 코드가 바탕 클래스의 참조나 포인터를 기대한다면 바탕 클래스 인터페이스로 모든 게 충분하다. 동적 유형변환을 사용할 필요가 전혀 없다. 바탕 클래스의 가상 인터페이스를 변경해서 동적 유형변환의 필요성을 미리 방지할 수도 있을 것이다. 동적 유형변환을 사용하는 코드를 만나면 기분이 찜찜하다. 여러분의 코드에 동적 유형변환을 사용한다면 어떻게 동적 유형변환이 적절하게 사용되는지 왜 피할 수 없었는지 언제나 적절하게 문서화하라.
dynamic_cast 연산자처럼 typeid는 파생 클래스 실체를 참조하는 바탕클래스 실체에 대한 참조에 적용된다. typeid는 가상 멤버가 있는 바탕 클래스에만 사용해야 한다.
typeid를 사용하기 전에 <typeinfo> 헤더를 포함해야 한다.
typeid 연산자는 type_info 유형의 객체를 돌려준다. 컴파일러마다 type_info 클래스의 구현이 다를 수 있다. 그러나 typeid는 최소한 다음 인터페이스를 제공한다.
class type_info
{
public:
virtual ~type_info();
int operator==(type_info const &other) const;
int operator!=(type_info const &other) const;
bool before(type_info const &rhs) const
char const *name() const;
private:
type_info(type_info const &other);
type_info &operator=(type_info const &other);
};
이 클래스는 비공개 복사 생성자와 비공개 중복정의 할당 연산자가 있음을 눈여겨보라. 이 때문에 코드는 type_info 객체를 생성하지 못하며 type_info 객체를 서로 할당하지 못한다. 대신에 type_info 객체는 typeid 연산자가 생성해 돌려준다.
typeid 연산자에 바탕 클래스 참조를 건네면 그 참조 유형의 실제 이름을 돌려준다. 예를 들어:
class Base;
class Derived: public Base;
Derived d;
Base &br = d;
cout << typeid(br).name() << '\n';
이 예제에서 typeid 연산자에 바탕 클래스 참조를 넘겨준다. ``Derived'' 텍스트를 출력하는데 이것은 br이 실제로 참조하는 클래스의 이름이다. Base에 가상 함수가 없다면 ``Base'' 텍스트가 출력된다.
typeid 연산자를 사용하면 클래스 실체 유형의 이름뿐만 아니라 표현식 유형의 실제 이름을 알 수 있다. 예를 들어:
cout << typeid(12).name() << '\n'; // 출력: int
cout << typeid(12.23).name() << '\n'; // 출력: double
그렇지만 위의 예제는 기껏해야 예시용일 뿐이라는 것을 주의하라. int와 double을 출력할 수는 있지만 반드시 이런 경우만 있는 것은 아니다. 이식성이 요구되면 이런 정적인 내장 텍스트 문자열을 검증할 필요가 없도록 확인하라. 잘 모르겠으면 컴파일러가 무슨 메시지를 보여주는지 살펴 보라.
typeid 연산자를 적용하여 파생 클래스의 유형을 결정해야 한다면 typeid 연산자의 인자에 바탕 클래스 참조를 사용해야 한다. 다음 예제를 연구해 보자:
class Base; // 적어도 가상 함수가 하나는 있다.
class Derived: public Base;
Base *bp = new Derived; // 파생 객체를 가리키는 바탕 클래스 포인터
if (typeid(bp) == typeid(Derived *)) // 1: false
...
if (typeid(bp) == typeid(Base *)) // 2: true
...
if (typeid(bp) == typeid(Derived)) // 3: false
...
if (typeid(bp) == typeid(Base)) // 4: false
...
if (typeid(*bp) == typeid(Derived)) // 5: true
...
if (typeid(*bp) == typeid(Base)) // 6: false
...
Base &br = *bp;
if (typeid(br) == typeid(Derived)) // 7: true
...
if (typeid(br) == typeid(Base)) // 8: false
...
여기에서 (1)은 false를 돌려준다. Base *가 Derived *이 아니기 때문이다. (2)는 true를 돌려준다. 두 포인터의 유형이 같기 때문이다. (3)과 (4)는 false를 돌려준다. 객체를 가리키는 포인터가 객체 자체가 아니기 때문이다.
반면에 *bp를 위의 표현식에 사용하면 (1)과 (2)는 false를 돌려준다. 객체가 (또는 객체에 대한 참조가) 객체를 가리키는 포인터가 아니기 때문이다. 반면에 (5)는 true를 돌려준다. *bp가 실제로 Derived 클래스 실체를 가리키고 typeid(*bp)가 typeid(Derived)를 돌려주기 때문이다. 바탕 클래스 참조를 사용하더라도 비슷한 결과를 얻는다. (7)은 true를 돌려주고 (8)은 false를 돌려준다.
type_info::before(type_info const &rhs) 멤버는 클래스의 대조 순서(collating order)를 결정한다. 이것은 두 유형이 같은지 비교할 때 유용하다. 사용된 유형의 대조 순서 즉, 계통도에서 *this가 rhs보다 앞에 있으면 함수는 0 아닌 값을 돌려준다. 파생 클래스를 바탕 클래스에 비교하면 0을 돌려주고 그렇지 않으면 0-아닌 값을 돌려준다. 예를 들어:
cout << typeid(ifstream).before(typeid(istream)) << '\n' << // 0 아님
typeid(istream).before(typeid(ifstream)) << '\n'; // 0
내장 유형일 경우 `더 넓은' 유형을 `더 좁은' 유형에 비교하면 0-아닌 값을 돌려주고 그렇지 않으면 0을 돌려주도록 구현할 수 있다.
cout << typeid(double).before(typeid(int)) << '\n' << // 0 아님
typeid(int).before(typeid(double)) << '\n'; // 0
두 유형이 같으면 0을 돌려준다.
cout << typeid(ifstream).before(typeid(ifstream)) << '\n'; // 0
0-포인터를 operator typeid에 건네면 bad_typeid 예외가 던져진다.
지금까지 보았듯이 다형적 클래스는 한편으로 바탕 클래스에게 요구하는 기능을 정의한 인터페이스 멤버를 제공하고 다른 한편으로 재정의가 가능한 가상 멤버를 제공한다. 좋은 클래스 설계의 징표 하나는 멤버 함수가 `함수 하나에 과업 하나'라는 원칙에 충실하게 설계되어 있는 것이다. 현재 문맥에서 클래스 멤버는 클래스의 공개 인터페이스 또는 보호 인터페이스의 멤버가 되어야 한다. 그렇지 않으면 가상 멤버로 파생 클래스가 구현해 주기를 기다려야 한다. 이 때문에 가상 멤버는 결국 바탕 클래스의 비밀 구역에 정의된다. 그런 함수들은 바탕 클래스를 사용하는 코드가 호출하면 안 된다. 그러나 파생 클래스가 재정의할 수 있다. 다형성을 사용하여 바탕 클래스의 행위를 재정의한다.
그 아래의 원칙은 이미 이 장의 서두에 언급했듯이 클래스 사이가 리스코프 교체 원칙(LSP(Liskov Substitution Principle))에 따라 (파생 클래스 실체는 바탕 클래스 실체이다를 가리키는) is-a 관계라면 바탕 클래스 실체를 기대하는 코드가 파생 클래스 실체를 사용할 수 있다는 뜻이다.
이 경우 상속을 사용하는 이유는 파생 클래스가 이미 바탕 클래스로 구현된 기능들을 사용할 수 있도록 하기 위함이 아니라 파생 클래스에 바탕 클래스의 가상 멤버를 구현함으로써 바탕 클래스를 다형적으로 재사용하기 위해서이다.
이 절은 상속을 사용해야 하는 이유를 연구한다. 왜 상속을 사용해야 (아니면 하지 말아야) 하는가? 상속을 사용한다면 무엇을 얻으려고 노력해야 하는가?
상속은 합성과 경쟁하는 경우가 많다. 다음 두 가지의 대안 클래스 설계를 연구해 보자:
class Derived: public Base
{ ... };
class Composed
{
Base d_base;
...
};
왜 그리고 언제 Derived가 Composed보다 더 좋은가 아니면 그 반대가 더 좋은가? Derived 클래스를 설계할 때 어떤 종류의 상속을 사용해야 하는가?
Composed와 Derived는 대체 관계이기 때문에
또다른 클래스의 관점에서 구현된 클래스의 설계를 보고 있는 중이다.
Composed 자체는 Base의 인터페이스를 사용하지 못하기 때문에 Derived도 역시 사용하면 안된다. 그 아래의 원칙은 Derived 클래스를 Base로부터 파생시킬 때 비밀 상속을 사용해야 한다는 것이다. 여기에서 Derived는 Base의 관점에서 구현된다.
std::string 멤버를 가진 클래스를 생각해 보라). 상속으로는 이런 클래스를 실현할 수 없다.
Base가 멤버를 보호 인터페이스에 제공하면 Derived 상속을 구현할 때 사용해야 하는 인터페이스를 역시 사용해야 한다. 또 다시 상속의 관점에서 구현을 하고 있으므로 비밀 유형이 되어야 한다.
D)가 스스로 바탕 클래스가 되어 자신의 바탕 클래스(B)로부터 물려 받은 멤버들을 자신의 파생 클래스에 물려주기만 하면 될 때 보호 상속을 고려해 볼 수 있다.
파생 클래스는 바탕 클래스의 is-a 유형이지만 그 바탕 클래스 실체를 초기화하기 위하여 또다른 클래스 유형이 필요할 때도 역시 비밀 상속을 사용해야 한다. 예를 들어 새로운 istream 클래스 유형은 (즉, 난수를 추출할 수 있는 IRandStream 스트림은) std::istream으로부터 파생된다. istream을 빈 채로 생성할 수 있지만 (나중에 rdbuf 멤버를 사용하여 streambuf을 받을 수 있지만) 즉시 istream 바탕 클래스를 초기화하는 것이 확실히 더 좋다.
난수를 뽑기 위해 Randbuffer: public std::streambuf를 생성했다고 간주하면 IRandStream을 Randbuffer와 std::istream으로부터 파생시킬 수 있다. 그런 식으로 Randbuffer 바탕 클래스를 사용하여 istream 바탕 클래스를 초기화할 수 있다.
RandStream은 Randbuffer가 확실히 아니기 때문에 공개 상속은 적절하지 않다. 이 경우 IRandStream은 Randbuffer의 관점에서 구현되므로 비공개 상속을 사용해야 한다.
그러므로 IRandStream의 클래스 인터페이스는 다음과 같이 시작한다.
class IRandStream: private Randbuffer, public std::istream
{
public:
IRandStream(int lowest, int highest) // 범위를 정의한다.
:
Randbuffer(lowest, highest),
std::istream(this) // &Randbuffer를 건넨다.
{}
...
};
공개 상속은 LSP 원칙이 유효한 클래스에 예약되어 있다. 그런 경우 언제나 바탕 클래스를 대신하여 파생 클래스를 사용할 수 있다. 단순히 바탕 클래스를 참조나 포인터 또는 멤버를 사용한 코드로 파생시켜 사용하면 된다. (즉, 개념적으로 파생 클래스는 바탕 클래스이다(is-a)). 이 원리는 가상 멤버가 있는 바탕 클래스로부터 파생된 클래스에 대부분 적용된다.
사용자 인터페이스와 재정의가 가능한 인터페이스를 분리하기 위하여 바탕 클래스의 공개 인터페이스는 가상 멤버를 포함하면 안된다 (가상 소멸자는 제외함). 그리고 가상 멤버는 모두 바탕 클래스의 비밀 구역에 있어야 한다. 그런 가상 멤버는 여전히 파생 클래스가 재정의할 수 있다 (결코 놀라운 일이 아니다. 다형성이 어떻게 구현되는지 생각해 보자). 그리고 이 설계로 바탕 클래스는 재정의된 멤버가 사용되는 문맥을 완전히 통제할 수 있다. 공개 인터페이스는 단순히 가상 멤버를 호출할 뿐이지만 그런 멤버들은 언제든지 재정의할 수 있고 거기에 수행할 임무를 더 줄 수 있다.
class Base
{
public:
virtual ~Base();
void process(); // 가상 멤버를 호출한다
// (예를 들어 v_process)
private:
virtual void v_process(); // 파생 클래스가 재정의한다.
};
대안으로 바탕 클래스는 비-가상 소멸자를 제공할 수 있다. 이 소멸자는 보호해야 한다. 바탕 클래스 포인터를 통하여 객체를 삭제하지 못하도록 해야 하기 때문에 공개하면 안된다 (이 경우 가상 소멸자를 사용해야 한다). 파생 클래스의 소멸자가 각자의 바탕 클래스 소멸자를 호출하도록 허용하기 위하여 보호해야 한다. 같은 이유로 그런 바탕 클래스의 생성자와 중복정의 할당 연산자도 비공개이어야 한다.
std::streambuf 클래스는 스트림이 처리한 문자 연속열을 받고 (디스크 상의 파일처럼) 스트림 객체와 장치 사이의 인터페이스를 정의한다. streambuf 객체는 직접적으로 생성되지 않고 바탕 클래스로 사용된다. 그로부터 파생된 클래스가 구체적인 장치와의 통신을 구현한다.
streambuf 클래스가 존재하는 핵심 이유는 장치와 거기에 작동하는 stream 클래스를 분리하는 것이다. 장치와의 통신에 사용하는 클래스와 실제 장치 사이에 얇은 겹을 하나 더 추가함으로써 그 사이에서 서로 통신할 수 있다. 이렇게 하면 명령어 사슬이 구현된다. 이 설계는 소프트웨어 설계에서 자주 보이는 것이다.
명령어 사슬은 재사용 가능한 소프트웨어를 설계할 때 총칭 패턴으로 간주된다. TCP/IP 스택에서 자주 만나는 패턴이다.
streambuf는 명령어 사슬 패턴의 또다른 예로 간주할 수 있다. 여기에서 프로그램은 stream 객체와 대화한다. 이 객체는 이번에는 요청을 streambuf 객체에 전달하고, 이 객체는 이어서 장치와 통신한다. 그리하여 잠시 후에 보게 되듯이 이전에 (비싼) 시스템 호출을 통하여 하던 일들을 사용자 소프트웨어에서 할 수 있게 되었다.
streambuf 클래스는 공개 생성자가 없다. 그러나 여러 공개 멤버 함수를 사용할 수 있다. 공개 멤버 함수 외에도 streambuf로부터 파생된 클래스 전용의 여러 멤버 함수를 사용할 수 있다. streambuf 클래스에 미리 정의된 특정화를 14.8.2항에 소개했다. 여기에 논의하는 streambuf의 모든 공개 함수는 filebuf에도 사용할 수 있다.
다음은 streambuf로부터 클래스를 파생시킬 때 재정의할 수 있는 streambuf 멤버를 보여준다. streambuf로부터 파생된 클래스의 실전 예제는 제 24장에 보여준다.
streambuf 클래스는 입력 연산을 수행하는 스트림과 출력 연산을 수행하는 스트림이 사용한다. 그의 멤버 함수들을 마찬가지로 정리할 수 있다. 아래에 사용된 std::streamsize 유형은 실용적 목적으로 size_t 유형과 같다고 간주해도 좋다.
정보를 ostream 객체에 삽입할 때 그 정보는 결국 ostream의 streambuf에 건네진다. streambuf는 예외를 던지기로 결정할 수 있다. 그렇지만 이 예외는 streambuf를 사용하는 ostream을 떠나지 못한다. 그 보다 예외는 ostream이 잡는다. 그리고 ios::bad_bit 깃발이 올라간다. ostream 객체에 삽입된 조작자가 던진 예외는 ostream 객체가 잡지 않는다.
입력 연산을 위한 공개 멤버
std::streamsize in_avail():
즉시 읽을 수 있는 문자 갯수의 하한 값을 돌려준다.
int sbumpc():
다음 문자 또는EOF를 돌려준다. 반환된 문자는streambuf객체로부터 제거된다. 입력이 없으면sbumpc함수는uflow(보호) 멤버를 호출하여 (14.8.1항) 새 문자를 사용할 수 있도록 만들어 준다. 더 이상 문자가 없으면EOF를 돌려준다.
int sgetc():
다음 문자 또는EOF를 돌려준다. 해당 문자는streambuf객체로부터 제거되지 않는다. 문자를streambuf객체로부터 제거하려면sbumpc를 (또는sgetn를) 사용할 수 있다.
int sgetn(char *buffer, std::streamsize n):
최대n개의 문자를 입력 버퍼로부터 열람한다. 그리고buffer에 저장한다. 실제로 읽은 문자의 갯수를 돌려준다. (보호)xsgetn멤버를 (14.8.1항) 호출하여 요청된 문자의 갯수를 획득한다.
int snextc():
현재 문자를 입력 버퍼로부터 획득하고 다음 사용 가능한 문자로 돌려준다. 아니면EOF를 돌려준다. 문자는streambuf객체로부터 제거되지 않는다.
int sputback(char c):
c문자를streambuf의 버퍼에 삽입한다. 이 문자는streambuf객체로부터 읽을 다음 문자로 반환된다. 이 함수를 사용할 때 주의를 기울여야 한다. 제자리로 되돌려 놓을 수 있는 문자가 최대 단 한 개만 있는 경우가 가끔 있다.
int sungetc():
입력 버퍼에 읽은 마지막 문자를 돌려준다. 다음 입력 연산에 다시 읽는다. 이 함수를 사용할 때 주의를 기울여야 한다. 종종 제자리로 되돌려 놓을 수 있는 문자가 최대 단 한 개만 있는 경우가 있다.
출력 연산을 위한 공개 멤버
int pubsync():
현재streambuf에 있는 모든 정보를 장치에 씀으로써 버퍼를 동기화한다 (즉, 비운다).streambuf로부터 파생된 클래스만 사용한다.
int sputc(char c):
문자c를streambuf객체에 삽입한다. 문자를 쓴 후에, 버퍼가 꽉 차면 이 함수는 (보호) 멤버 함수overflow를 호출하여 버퍼를 장치로 비운다 (아래 14.8.1항 참고).
int sputn(char const *buffer, std::streamsize n):
최대n개의 문자를buffer버퍼로부터streambuf객체로 삽입한다. 실제로 삽입된 갯수를 돌려준다. 이 멤버 함수는 (보호)xsputn멤버 함수를 호출하여 (아래 14.8.1항 참고) 요청된 갯수의 문자를 삽입한다.
다양한 연산을 위한 공개 멤버
다음 멤버 세 개는 streambuf 클래스로부터 파생된 클래스만 사용한다.
ios::pos_type pubseekoff(ios::off_type offset, ios::seekdir way, ios::openmode mode = ios::in | ios::out):
읽을 또는 쓸 다음 문자의 오프셋을offset에 설정한다. 검색 방향을 알려주는 표준ios::seekdir값에 상대적이다.
ios::pos_type pubseekpos(ios::pos_type offset, ios::openmode mode = ios::in | ios::out):
쓸 또는 읽을 다음 문자의 절대 위치를 pos에 설정한다.
streambuf *pubsetbuf(char* buffer, std::streamsize n):
streambuf객체는 적어도n개의 문자를 수용하는buffer를 사용한다.
streambuf 클래스의 보호 멤버들은 streambuf 객체를 이해하고 사용하는 데 중요하다. 보호 멤버 데이터와 보호 멤버 함수가 모두 streambuf 클래스에 정의되어 있지만 보호 데이터 멤버는 여기에 언급하지 않는다. 멤버 데이터를 사용하면 데이터 은닉의 원칙에 어긋나기 때문이다. streambuf의 멤버 함수들은 상당히 비싸기 때문에 멤버 데이터를 직접적으로 사용해야 할 필요는 거의 없다. 이번 항은 모든 보호 멤버 함수를 나열하지 않고 특정화를 생성하는 데 쓸모가 많은 멤버들만 다루겠다.
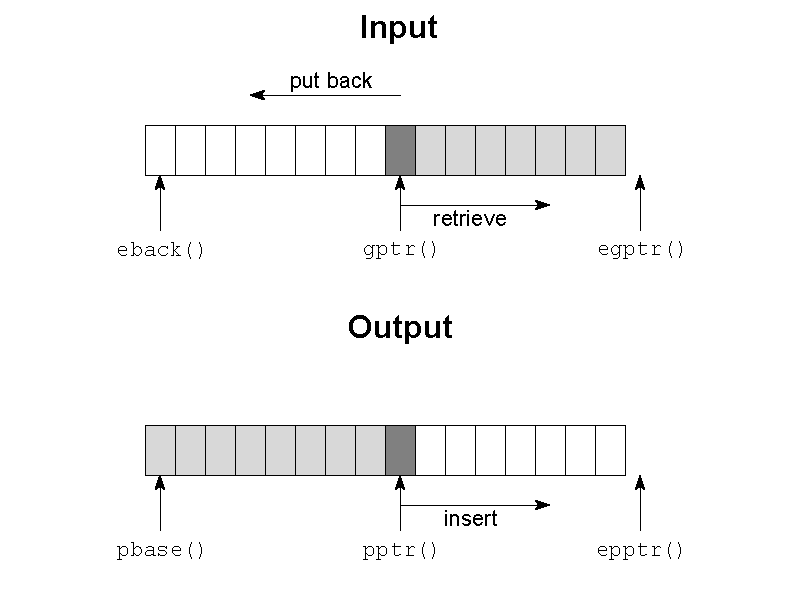
streambuf 객체는 입력/출력에 사용되는 버퍼를 통제한다. 이를 위해 begin-포인터와 actual-포인터 그리고 end-포인터가 정의되어 있으며 그림 17에 보여준다.
streambuf는 두 개의 보호 생성자를 제공한다.
streambuf::streambuf(): streambuf 클래스의 (보호) 기본 생성자
streambuf::streambuf(streambuf const &rhs):streambuf클래스의 (보호) 복사 생성자. 이 복사 생성자는 단순히rhs의 멤버 데이터 값을 복사할 뿐이라는 것을 주목하라: 복사 생성자를 사용하고 나면 두streambuf객체는 같은 데이터 버퍼를 참조하고 처음에는 포인터들이 같은 위치를 가리킨다. 이것은 공유 포인터가 아니고 그저 `날 사본'이라는 것을 눈여겨보라.
virtual 표식이 붙은 멤버 함수는 파생 클래스에서 재정의할 수 있다.
char *eback():streambuf는 입력 버퍼를 통제하기 위해 세 개의 포인터를 관리한다.eback은 제자리(putback)의 끝을 가리킨다. 문자들을 안전하게 이 위치까지 돌려 놓을 수 있다 (그림 17).Eback은 입력 버퍼의 시작을 가리킨다.
char *egptr():Egptr는 입력 버퍼로부터 열람할 수 있는 마지막 문자 바로 다음을 가리킨다 (그림 17).gptr이egptr가 같다면 버퍼는 재충전되어야 한다. 이것은underflow를 호출하여 구현해야 한다. 아래 참고.
void gbump(int n):객체의gptr이n위치만큼 앞으로 이동된다 (위 참고).
char *gptr():gptr은 객체의 입력 버퍼로부터 열람할 다음 문자를 가리킨다 (그림 17).virtual int pbackfail(int c):이 멤버 함수는 파생 클래스가 재정의할 수 있다.c문자를 제자리에 돌려놓기에 실패할 경우 뭔가 지능적인 일을 할 수 있다. 입력 버퍼의 처음에 도달하면 예전의 읽기 포인터를 복구하고 싶은 생각이 들 것이다. 이 멤버 함수는 문자를 버리거나 되돌려 놓기에 실패할 때 호출된다. 특히 다음과 같은 경우에 호출된다.
gptr() == 0: 버퍼링을 사용하지 않음,gptr() == eback(): 더 이상 되돌릴 공간이 없다,*gptr() != c: 다음으로 읽을 문자와 다른 문자를 제자리에 돌려놓아야 한다.c == endOfFile()이면 입력 장치를 한 문자 위치만큼 재설정해야 한다. 그렇지 않으면c가 읽을 문자들의 앞에 붙는다. 실패하면EOF를 돌려준다. 그렇지 않으면 0을 돌려준다.
void setg(char *beg, char *next, char *beyond):입력 버퍼를 초기화한다.beg은 입력 구역의 처음을 가리키고next는 열람할 다음 문자를 가리키며 그리고beyond는 입력 버퍼의 마지막 문자 바로 다음 위치를 가리킨다.next는 적어도beg + 1이다. 제자리에 되돌려 놓을 수 있어야 하기 때문이다. 이 멤버를setg(0, 0, 0)로 호출하면 입력 버퍼를 처리하지 않는다. 아래uflow멤버 참고.
virtual streamsize showmanyc():(발음: s-how-many-c) 이 멤버 함수를 파생 클래스가 재정의할 수 있다.uflow또는underflow가EOF를 돌려주기 전에 장치로부터 읽을 수 있는 문자의 갯수에 보장된 하한 값을 먼저 돌려주어야 한다. 기본으로 0이 반환된다 (뒤의 두 함수가EOF를 돌려주기 전에 문자가 몇 개 (또는 0개) 반환된다는 뜻이다. ). 양의 값이 반환되면 다음에u(nder)flow를 호출해도EOF를 돌려주지 않는다.
virtual int uflow():
이 멤버 함수는 파생 클래스가 재정의하여 입력 버퍼에 새로운 문자들을 재적재한다. 기본 구현은underflow를 호출하는 것이다 (아래 참고).underflow()가 실패하면EOF가 반환된다. 그렇지 않으면 다음의 가능한 문자가*gptr()로 반환된다. 그 다음에gbump(-1)가 따라온다.uflow는 또 반환되어 대기중인 문자를 백업 연속열로 이동시킨다. 이것은underflow()와 다르다. 그저 다음 문자를 돌려줄 뿐 입력 포인터 위치를 변경하지 않기 때문이다.입력 버퍼처리가 필요하지 않으면
underflow대신에 이 함수를 재정의하여 읽어 들일 장치로부터 다음의 가능한 문자를 생산할 수 있다.
virtual int underflow():
이 멤버 함수는 파생 클래스가 재정의하여 또다른 문자를 장치로부터 읽을 수 있다. 기본 구현은EOF를 돌려준다.다음과 같을 때 호출된다.
eback() == 0: 입력 버퍼가 없을 때gptr() >= egptr(): 입력 버퍼가 고갈되었을 때버퍼처리할 때 버퍼 전체를 갱신하지 않는 경우가 가끔 있다. 이렇게 하면 재적재하자마자 바로 문자들을 제자리에 돌려 놓기가 불가능할 수 있기 때문이다. 대신에 버퍼는 절반만큼 갱신된다. 이런 시스템을 분리 버퍼(split buffer)라고 부른다.
읽기 위해
streambuf로부터 파생된 클래스는 적어도underflow는 재정의해야 한다. 중복정의underflow함수의 원형은 다음과 같다.int underflow() { if (not refillTheBuffer()) // 멤버 d_buffer가 있다고 간주한다. return EOF; // 입력 버퍼 포인터를 재설정한다. setg(d_buffer, d_buffer, d_buffer + d_nCharsRead); // 다음 문자를 돌려준다. // (0xff 문자를 EOF로 // 오해하지 않도록 // 유형을 변환한다.) return static_cast<unsigned char>(*gptr()); }
virtual streamsize xsgetn(char *buffer, streamsize n):
이 멤버 함수는 파생 클래스가 재정의하여 입력 장치로부터 한 번에n개의 문자를 열람할 수 있다. 기본 구현은 문자마다sbumpc를 호출하는 것이다. 이것은 기본으로 이 멤버가 문자마다underflow를 호출한다는 뜻이다. 이 함수는 실제로 읽은 문자의 갯수 또는EOF를 돌려준다.EOF가 반환되면streambuf는 장치로부터 읽기를 중단한다.
virtual int overflow(int c):이 멤버 함수는 파생 클래스가 재정의할 수 있다. 현재 출력 버퍼에 저장된 문자들을 출력 장치로 비운 다음에 빈 버퍼를 표현하기 위하여 출력 버퍼 포인터를 재설정한다. 매개변수c는 처리될 다음 문자로 초기화된다. 출력 버퍼처리를 하지 않으면streambuf객체로 씌여지는 문자마다overflow가 호출된다.setp함수를 사용하여 버퍼 포인터를 0으로 설정하면 출력 버퍼처리를 하지 않는다 (아래 참고). 기본 구현은 장치에 더 이상 문자를 쓸 수 없으면EOF를 돌려준다.읽기 위해
streambuf클래스로부터 파생된 클래스라면 적어도overflow함수는 재정의해야 한다. 중복정의overflow함수의 원형은 모습이 다음과 같다.int OFdStreambuf::overflow(int c) { sync(); // 버퍼를 비운다. if (c != EOF) // 문자를 썼는가? { *pptr() = static_cast<char>(c); // 문자를 버퍼에 넣는다. pbump(1); // 버퍼 포인터를 앞으로 이동시킨다. } return c; }
char *pbase():streambuf는 세 개의 포인터로 출력 버퍼를 제어한다.pbase는 출력 버퍼의 처음을 가리킨다 (그림 17).
char *epptr():streambuf는 세 개의 포인터로 출력 버퍼를 제어한다.epptr은 출력 버퍼의 마지막 위치 바로 다음을 가리킨다 (그림 17).pptr이epptr과 같다면 버퍼를 비워야 한다 (아래 참고). 이것은overflow를 호출하여 구현한다 (앞 항목 참고).
void pbump(int n):pptr이 돌려주는 위치가n만큼 앞으로 이동한다 (아래 참고). 스트림에 씌여진 다음 문자가 그 위치에 입력된다.
char *pptr():streambuf는 출력 버퍼를 제어하기 위해 세 개의 포인터를 관리한다.pptr은 출력 버퍼에서 다음 문자를 써야할 위치를 가리킨다 (그림 17).
void setp(char *beg, char *beyond):
streambuf의 출력 버퍼는setp에 건넨 위치로 초기화된다.beg는 출력 버퍼의 처음을 가리키고beyond는 출력 버퍼의 마지막 위치 바로 다음을 가리킨다.setp(0, 0)를 사용하면 버퍼처리를 하지 말라는 뜻이다. 그 경우 장치에 씌여지는 문자마다overflow가 호출된다.
virtual streamsize xsputn(char const *buffer, streamsize n):이 멤버 함수는 파생 클래스가 재정의할 수 있다. 최대n개의 문자를 이어서 출력 버퍼에 쓴다. 삽입된 실제 문자의 갯수를 돌려준다.EOF가 반환되면 장치에 쓰기가 중지된다. 기본 구현은 문자마다sputc를 호출한다.streambuf가ios::openmode ios::app를 지원해야 한다면 이 멤버를 재정의하라.streambuf로부터 파생된MyBuf클래스가 (요청된ios::openmode를 나타내는)ios::openmode d_mode멤버 데이터 그리고 (len개의 바이트를pptr()에 쓰는)write(char const *buf, streamsize len)멤버 함수를 갖추고 있다면 다음 코드는ios::app모드를 받아 들인다.std::streamsize MyStreambuf::xsputn(char const *buf, std::streamsize len) { if (d_openMode & ios::app) seekoff(0, ios::end); return write(buf, len); }
virtual streambuf *setbuf(char *buffer, streamsize n):
이 멤버는 파생 클래스가 버퍼를 설치하기 위해 재정의할 수 있다. 기본 구현은 아무 조치도 수행하지 않는다. pubsetbuf가 호출한다.
virtual ios::pos_type seekoff(ios::off_type offset, ios::seekdir way, ios::openmode mode = ios::in | ios::out):
이 멤버 함수는 입력이나 출력에서 다음 포인터를 새로운 상대 위치로 재설정하기 위하여 파생 클래스가 재정의할 수 있다 (ios::beg나ios::cur또는ios::end를 사용한다). 기본 구현은 -1을 돌려주어 실패를 알린다.tellg이나tellp가 호출될 때 이 함수가 호출된다. 파생 클래스가 위치 찾기를 지원하면 위치 재지정 요구를 처리하기 위해 이 함수를 정의해야 한다.pubseekoff가 호출한다. 새 위치 또는 무효 위치가 (즉, -1이) 반환된다.
virtual ios::pos_type seekpos(ios::pos_type offset, ios::openmode mode = ios::in | ios::out):
이 멤버는 입력 또는 출력에서 다음 포인터를 새로운 절대 위치로 재설정하기 위하여 파생 클래스가 재정의할 수 있다 (즉, ios::beg에 상대적이다). 기본 구현은 실패시 -1을 돌려준다.
virtual int sync():
이 멤버 함수는 파생 클래스가 재정의할 수 있다. 출력 버퍼를 입력 장치로 비우거나 마지막으로 반환된 문자의 위치 바로 다음으로 입력 장치를 재설정할 수 있다. 성공하면 0을 돌려주고 실패하면 -1을 돌려준다. (버퍼를 사용하지 않는) 기본 구현은 동기화에 성공하면 0을 돌려준다. 이 멤버는 streambuf 객체가 존재하기를 멈출 때 여전히 버퍼에 있는 문자들이 장치에 씌여지는 것을 확인하기 위해 또는 소비되지 않은 문자들을 다시 장치에 되돌리기 위해 사용된다.
streambuf로부터 파생될 때 적어도 underflow는 장치로부터 정보를 읽을 파생 클래스가 재정의해야 한다. 그리고 overflow 는 장치에 정보를 쓸 클래스가 재정의해야 한다. streambuf로부터 파생된 클래스의 예는 제 24장에 보여준다.
fstream 유형의 실체는 조합된 입력/출력 버퍼를 사용한다. 이것은 istream과 ostream이 streambuf를 담고 있는 ios로부터 가상적으로 파생된 결과이다. 따로 버퍼를 사용하여 입력과 출력을 동시에 지원하는 클래스를 생성하려면 streambuf 자체에서 두 개의 버퍼를 정의할 수 있다. 읽기를 위해 seekoff를 호출하면 mode 매개변수에 ios::in을 설정하고 그렇지 않으면 ios::out을 설정할 수 있다. 그리하여 파생 클래스는 read 버퍼에 접근해야 하는지 아니면 write 버퍼에 접근해야 하는지 안다. 물론 underflow와 overflow는 모드 깃발을 조사할 필요가 없다. 어느 버퍼에서 작동해야 하는지 묵시적으로 알기 때문이다.
filebuf 클래스는 stream 클래스가 사용하는 streambuf의 특정화이다. filebuf를 사용하기 전에 먼저 <fstream> 헤더를 포함해야 한다.
class streambuf를 통하여 사용할 수 있는 (공개) 멤버 외에도 filebuf는 다음의 (공개) 멤버를 제공한다.
filebuf():
filebuf는 공개 생성자를 제공한다. 아직 스트림에 연결되지 않은 평범한filebuf객체를 초기화한다.
bool is_open():
filebuf가 열린 파일에 실제로 연결되어 있으면true를 돌려주고 그렇지 않으면false를 돌려준다. 아래open멤버를 참고하라.
filebuf *open(char const *name, ios::openmode mode):
filebuf객체를name이름의 파일에 연관짓는다. 이 파일은 제공된openmode모드로 열린다.
filebuf *close():filebuf객체와 그의 파일 사이의 연관 관계를 닫는다. 연관 관계는filebuf객체가 존재하기를 멈추면 자동으로 닫힌다.
std::istream이나 std::ostream으로부터 파생된 클래스를 연구해 보자. 다음과 같이 설계할 수 있다.
class XIstream: public std::istream
{
public:
...
};
XIstream은 streambuf에 인터페이스가 있는데, XIstream은 streambuf가 아직 생성 시간에 존재하지 않는다고 간주하고 기본 생성자만 제공한다. 그렇지만 이 클래스는 XIstream 객체에 인터페이스할 streambuf를 제공하기 위하여 void switchStream(std::streambuf *sb) 멤버를 제공한다. 어떻게 switchStream을 구현할까? 단순히 rdbuf를 호출해 거기에 새 streambuf를 포인터로 건네면 작동하겠지만 문제는 기존의 streambuf가 있을 수 있다는 것이다. 이 때문에 잃고 싶지 않은 정보가 버퍼처리될 가능성이 있다.
기존의 스트림 안에서 또다른 streambuf로 전환하려면 rdbuf를 사용하는 대신에 void init(std::streambuf *sb)를 사용해야 한다.
init 멤버는 istream이나 ostream 객체에 연관되어 있는 streambuf를 포인터로 기대한다. init 멤버는 적절하게 기존의 연관 관계를 끝낸 다음에 init에 제공된 주소의 streambuf로 전환한다.
switchStream의 sb가 가리키는 streambuf가 존재한다고 간주하면 switchStream은 다음과 같이 간단하게 구현할 수 있다.
void switchStream(streambuf *sb)
{
init(sb);
}
더 이상의 조치는 필요가 없다. init 멤버는 현재 연결을 끝내고 단지 streambuf *sb를 사용하는 것으로 전환할 뿐이다.
process 멤버가 다르게 행위하는 Exception 클래스를 설계할 수 있다고 이전에 10.3.1절에서 암시를 준바 있다. 다형성을 소개했으므로 다음 예제를 더욱 발전시킬 수 있다.
Exception 클래스가 다형적 바탕 클래스가 된다고 해도 놀라운 일은 아닐 것이다. 그로부터 특별한 예외 처리 클래스들을 파생시킬 수 있다. 10.3.1절에 severity 멤버를 사용했다. Exception 바탕 클래스의 멤버로 교체할 수 있는 기능을 제공한다.
Exception 바탕 클래스는 다음과 같이 설계할 수 있다.
#ifndef INCLUDED_EXCEPTION_H_
#define INCLUDED_EXCEPTION_H_
#include <iostream>
#include <string>
class Exception
{
std::string d_reason;
public:
Exception(std::string const &reason);
virtual ~Exception();
std::ostream &insertInto(std::ostream &out) const;
void handle() const;
private:
virtual void action() const;
};
inline void Exception::action() const
{
throw;
}
inline Exception::Exception(std::string const &reason)
:
d_reason(reason)
{}
inline void Exception::handle() const
{
action();
}
inline std::ostream &Exception::insertInto(std::ostream &out) const
{
return out << d_reason;
}
inline std::ostream &operator<<(std::ostream &out, Exception const &e)
{
return e.insertInto(out);
}
#endif
이 클래스의 실체를 ostream에 삽입할 수 있지만 이 클래스의 핵심은 기본적으로 예외를 되던지는 action 가상 멤버 함수이다.
Warning 파생 클래스는 던져진 경고 텍스트 앞에 Warning: 텍스트를 붙일 뿐이다. 그러나 Fatal 파생 클래스는 Exception::action 멤버 함수를 재정의한다. std::terminate를 호출함으로써 강제로 프로그램을 끝낸다.
다음은 Warning 클래스와 Fatal 클래스이다.
#ifndef WARNINGEXCEPTION_H_
#define WARNINGEXCEPTION_H_
#include "exception.h"
class Warning: public Exception
{
public:
Warning(std::string const &reason)
:
Exception("Warning: " + reason)
{}
};
#endif
#ifndef FATAL_H_
#define FATAL_H_
#include "exception.h"
class Fatal: public Exception
{
public:
Fatal(std::string const &reason);
private:
virtual void action() const;
};
inline Fatal::Fatal(std::string const &reason)
:
Exception(reason)
{}
inline void Fatal::action() const
{
std::cout << "Fatal::action() terminates" << '\n';
std::terminate();
}
#endif
인자 없이 예제 프로그램을 시작하면 Fatal 예외를 던진다. 그렇지 않으면 Warning 예외를 던진다. 물론 추가 예외 유형도 쉽게 정의할 수 있다. 예제를 컴파일하기 위해 Exception 소멸자를 main 함수 위에 정의한다. 기본 소멸자는 사용할 수 없다. 가상 소멸자이기 때문이다. 실제로 소멸자는 작은 소스 파일에 따로 정의해야한다.
#include "warning.h"
#include "fatal.h"
Exception::~Exception()
{}
using namespace std;
int main(int argc, char **argv)
try
{
try
{
if (argc == 1)
throw Fatal("Missing Argument") ;
else
throw Warning("the argument is ignored");
}
catch (Exception const &e)
{
cout << e << '\n';
e.handle();
}
}
catch(...)
{
cout << "caught rethrown exception\n";
}
std::error_category 클래스는 특정 범주의 에러 코드의 소스와 인코딩을 식별하는 바탕 클래스 유형으로 기여한다.
error_category를 사용하기 전에 <system_error> 헤더를 포함해야 한다.
이전 10.9 절에서 error_category를 사용해 보았다. 에러 범주 클래스는 싱글턴(Singletons)으로 설계된다 (Singleton Design Pattern (Gamma et al. (1995) Design Patterns, Addison-Wesley)).
그리고 에러 범주의 몇 가지 유형은 std 이름공간에 있다. generic_category, system_category, iostream_category 그리고 future_category가 그것이다.
따로 error_category 클래스를 설계하려면 std::error_category로부터 상속받아야 한다. 싱글턴이어야 하고 자신만의 에러 집합만 지원해야 한다 (이미 C++이 지원하는 것만 확장 가능하다). 그런 파생 클래스의 행위는 error_category 클래스의 행위와 다르면 안된다. 그리고 errno의 값 또는 다른 라이브러리에서 제공하는 다른 어떤 에러 상태도 절대로 손대면 안된다.
error_category 객체가 같은지는 주소로부터 추론한다. 싱글턴이기 때문에 주소가 같다는 것은 에러 범주가 같다는 뜻이다.
error_category 클래스의 공개 인터페이스는 공개 생성자를 제공하지 않는다. 마찬가지로, 기존의 error_category 객체를 복사하지 못한다. 복사 생성자와 중복정의 할당 연산자가 `deleted'로 선언되어 있기 때문이다. 다음은 error_category 클래스의 공개 인터페이스이다.
class error_category
{
public:
error_category(error_category const &) = delete;
virtual ~error_category() noexcept;
error_category &operator=(error_category const &) = delete;
virtual char const *name() const noexcept = 0;
virtual string message(int ev) const = 0;
virtual error_condition default_error_condition(
int ev
) const noexcept;
virtual bool equivalent(int code,
error_condition const &condition
) const noexcept;
virtual bool equivalent(
error_code const &code, int condition
) const noexcept;
bool operator==(error_category const &rhs) const noexcept;
bool operator!=(error_category const &rhs) const noexcept;
bool operator<(error_category const &rhs) const noexcept;
protected:
error_category() noexcept;
};
error_category const &generic_category() noexcept;
error_category const &system_category() noexcept;
error_category const &iostream_category() noexcept;
error_category const &future_category() noexcept;
23.6.3항에서 error_category 클래스를 사용하여 CalculatorErrCategory라는 새로운 범주를 정의한다. 그에 부합하는 함수도 정의한다.
error_category const &calculator_category() const noexcept;
error_category를 상속받은 클래스는 최소한 name과 message 멤버는 재정의해야 한다. ..._category() 함수군에게만 상수 참조를 돌려준다. 그러므로 하나만 있는 이 범주의 기존 실체에 접근할 수 있을 것이다.
이 클래스의 멤버를 상세하게 소개한다.
char const *name() const noexcept:에러 범주의 이름 부분을 돌려준다 (즉,"generic"이라면generic_category를 돌려준다).
string message(int ev) const: 돌려주는 문자열은 ev 에러 값에 부합하는 에러 조건을 기술한다.
에러 범주에 대하여 에러 코드를 std::errc 코드 중 하나에 짝지을 수 있으면 default_error_condition이 그 짝짓기를 수행해야 하고 std::generic_category()의 범주와 그에 상응하는 std::errc 열거체의 값과 함께 std::error_condition을 돌려주어야 한다. 그렇지 않으면 그 범주를 참조하는 에러 조건(error_condition)을 돌려주어야 한다.
error_condition default_error_condition(int ev) const noexcept:ev에 상응하는error_condition유형의 객체를 돌려준다. 파생 클래스는 POSIXerrno값에 부합하는 에러 코드가generic_category값으로 반환되는지 확인해야 한다.
bool equivalent(int code, error_condition const &condition) const
noexcept:default_error_condition(code) == condition를 돌려준다.*this로 표현되는 에러 범주에 대하여code가condition과 같다면true를 돌려준다. 그렇지 않으면false를 돌려준다.
bool equivalent(error_code const &code, int condition) const noexcept:*this == code.category() && code.value() == condition를 돌려준다.*this로 표현되는 에러 범주에 대하여code가condition과 같다면true를 돌려준다. 그렇지 않으면false가 반환된다.
bool operator<(error_category const &rhs) const noexcept: less<const error_category*>()(this, &rhs)를 돌려준다.
자유 함수:
error_category const &generic_category() noexcept:총칭error_category객체를 참조로 돌려준다. 싱글턴이므로 실체가 하나만 있다. 그러므로 이 함수는 호출될 때마다 똑같은 객체를 돌려준다. 반환된 객체의name멤버는"generic"문자열을 포인터로 돌려준다.
error_category const &system_category() noexcept:운영 체제error_category객체를 참조로 돌려준다. 그러므로 운영 체체가 보고하는 에러를 위해 사용된다. 이 객체의name멤버는"system"문자열을 포인터로 돌려준다.error_condition함수의 인자ev가 POSIXerrno값 `posv'에 상응하면 그 객체의default_error_condition멤버는error_condition(posv, generic_category())을 돌려주어야 한다. 그렇지 않으면error_condition(ev, system_category())이 반환될 것이다.
다형성 뒤의 기본 아이디어는 컴파일러가 컴파일 시간에 어느 함수를 호출할지 알지 못한다는 것이다. 적절한 함수는 컴파일 시간에 선택된다. 함수의 주소가 어딘가에 있어야 한다는 뜻이고 실제로 호출하기 전에 찾을 수 있어야 한다는 뜻이다. 이 `어딘가'에 접근해 해당 객체에 도달할 수 있어야 한다. 그래서 Vehicle *vp가 Truck 객체를 가리킬 때 vp->mass()는 Truck의 멤버 함수를 호출한다. 이 함수의 주소는 vp가 가리키는 실제 객체를 통하여 얻는다.
다형성은 보통 다음과 같이 구현된다. 가상 멤버 함수가 있는 실체는 첫 번째 멤버 데이터가 숨어 있다. 이 멤버는 클래스의 가상 멤버 함수의 주소를 담은 배열을 가리킨다. 그 숨은 멤버 데이터를 vpointer 포인터라고 부른다. 이 가상 멤버 함수의 배열은 vtable 테이블에 접근한다.
클래스의 vtable 테이블은 그 클래스의 모든 실체가 공유한다. 그러므로 다형성의 부담은 메모리 소비의 관점에서 보면 다음과 같다.
vp->mass와 같은 서술문은 먼저 vp가 가리키는 실체의 숨은 멤버 데이터를 조사한다. 운송 수단 분류 시스템의 경우에 이 멤버 데이터는 두 개의 포인터를 가진 테이블을 가리킨다. 한 포인터는 mass 함수를 가리키고 또 한 포인터는 setMass 함수를 가리킨다 (클래스에 가상 소멸자도 정의되어 있다면 포인터는 세 개이다). 실제로 호출되는 함수는 이 테이블로부터 결정된다.
가상 함수를 가진 객체의 내부 조직은 그림 18과 그림 19에 보여준다 (원본은 기욤 꼬몬(Guillaume Caumon) 제공).
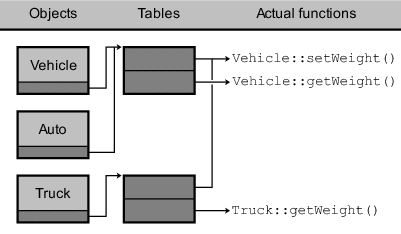
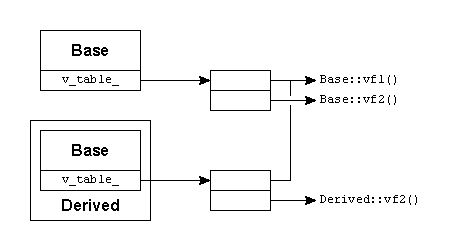
그림 18과 그림 19에서 보듯이 잠재적으로 가상 멤버 함수를 사용할 가능성이 있는 객체는 함수 포인터 테이블에 접근하기 위해 반드시 숨은 멤버 데이터를 하나 가져야 한다. Vehicle 클래스와 Car 클래스의 실체들은 모두 같은 테이블에 접근한다. 그렇지만 Truck 클래스는 mass 멤버를 재정의한다. 결론적으로 Truck 클래스는 자신만의 vtable 테이블이 필요하다.
각자 가상 함수를 정의한 여러 바탕 클래스로부터 클래스를 파생시킬 때 약간 복잡해진다. 다음 예제를 연구해 보자:
class Base1
{
public:
virtual ~Base1();
void fun1(); // vOne과 vTwo를 호출한다.
private:
virtual void vOne();
virtual void vTwo();
};
class Base2
{
public:
virtual ~Base2();
void fun2(); // vThree를 호출한다.
private:
virtual void vThree();
};
class Derived: public Base1, public Base2
{
public:
virtual ~Derived();
private:
virtual ~vOne();
virtual ~vThree();
};
예제에서 Derived 클래스는 각각 가상 함수를 지원하는 Base1 클래스와 Base2 클래스로부터 다중 파생되었다. 이 때문에 Derived도 가상 함수를 보유한다. 그래서 Derived 클래스는 vtable 테이블이 있다. 덕분에 바탕 클래스의 포인터나 참조가 적절한 가상 멤버에 접근할 수 있다.
Derived::fun1이 호출되면 (또는 fun1을 가리키는 Base1 포인터가 fun1을 호출하면) fun1은 Derived::vOne과 Base1::vTwo를 호출한다. 마찬가지로 Derived::fun2가 호출되면 Derived::vThree가 호출된다.
Derived 클래스의 vtable 테이블이 복잡해진다. fun1이 호출될 때 그의 클래스 유형은 사용할 vtable을 결정하고 그리하여 어느 멤버를 호출할지 결정한다. 그래서 vOne이 fun1로부터 호출된다. 아마도 Derived의 vtable의 두 번째 엔트리임에 틀림없다. Base1의 vtable의 두번째 엔트리에 부합하기 때문이다. 그렇지만 fun2가 vThree를 호출할 때도 역시 Derived의 vtable의 두번째 엔트리이다. Base2의 vtable의 두 번째 엔트리에 부합하기 때문이다.
물론 vtable이 하나라면 이런 일은 일어날 수 없다. 그러므로 다중 상속을 사용할 때 (바탕 클래스마다 가상 멤버를 정의하고 있다면) 또다른 접근법을 따라 어느 가상 함수를 호출할지 결정한다. 이 경우 Derived 클래스는 각 바탕 클래스당 하나씩 두 개의 vtable을 받는다 (그림 20). 그리고 Derived 클래스 실체마다 상응하는 vtable을 가리키는 포인터를 하나씩 두 개의 숨은 vpointer를 보유한다.
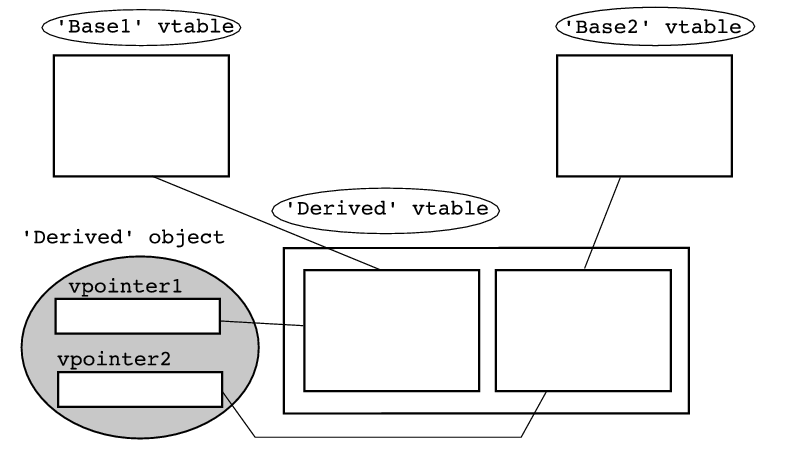
바탕 클래스 포인터나 바탕 클래스 참조 또는 바탕 클래스 인터페이스 멤버는 명료하게 바탕 클래스 중 하나를 참조하므로 컴파일러는 어느 vpointer를 사용할지 결정할 수 있다.
그러므로 다음은 가상 멤버 함수를 제공하는 바탕 클래스로부터 다중 파생된 클래스에 유효하다.
In function `Derived::Derived()':
: undefined reference to `vtable for Derived'
이 에러는 가상 함수가 파생 클래스의 인터페이스에 선언되어 있지만 파생 클래스 안에 구현되지 않으면 일어난다.
그런 상황은 어렵지 않게 마주한다.
undefined reference to `vtable for Derived' Derived를 위한 vtable을 참조할 수 없음.
class Base
{
virtual void member();
};
inline void Base::member()
{}
class Derived: public Base
{
virtual void member(); // 선언만 한다.
};
int main()
{
Derived d; // 컴파일된다. 모든 멤버가 선언되어 있기 때문이다.
// 링크하지 못한다.
// Derived::member() 구현이 없기 때문이다.
}
물론, 에러는 쉽게 교정할 수 있다. 빼먹은 가상 멤버 함수를 파생 클래스에 구현하면 된다.
가상 함수는 인라인으로 구현하면 절대 안된다. 클래스의 가상 함수 주소가 vtable에 들어 있기 때문에 이 함수들은 주소가 있어야 하며 그래서 실제 함수로 컴파일되어야 한다. 가상 함수를 인라인으로 정의하면 절대로 명시적으로 호출되지 않을 것이기 때문에 컴파일러가 그런 함수들을 그냥 무시해 버리는 위험을 감수해야 한다. (그러나 바탕 클래스 포인터 또는 참조로부터 다형적으로만 호출된다). 결과적으로 그들의 주소는 클래스의 vtable에 절대로 들어가지 않기 때문에 (심지어 vtable 자체가 여전히 정의되어 있지 않을 수도 있기 때문에) 링크 문제가 발생하거나 예상치 못한 행위를 보여주는 프로그램이 생산될 가능성이 높다. 이 모든 종류의 문제는 간단하게 회피할 수 있다. 다시 말해, 가상 함수를 인라인으로 절대 정의하지 마라 (7.8.2.1목 ).
프로토타입 디자인 패턴에 따르면 호출될 객체의 사본을 포인터로 돌려주는 멤버 함수를 구현할 책임이 파생 클래스마다 있다. 이 함수의 이름은 clone이다. 사용자 인터페이스를 재구현 인터페이스와 가르면 clone은 인터페이스를 구성하고 newCopy는 재구현 인터페이스에 정의된다. `복제(cloning)'를 지원하는 바탕 클래스는 newCopy의 반환 값을 돌려주는 clone 가상 소멸자를 정의하고 그리고 원형이 virtual Base *newCopy() const = 0인 순수 가상 함수로서 가상 복사 생성자를 정의한다. newCopy는 순수 가상 함수이므로 모든 파생 클래스는 각자 `가상 생성자'를 구현해야 한다.
이렇게 설정하면 바탕 클래스에 대한 참조나 포인터가 있지만 추상 컨테이너와 함께 사용하면 실패하는 대부분의 상황을 처리하기에 충분하다. Base가 인터페이스에 순수 가상 copy 멤버를 갖추고 있다면 vector<Base>를 생성할 수 없다. Base를 호출하여 이 벡터의 새 원소들을 초기화하기 때문이다. newCopy는 순수 가상 함수이기 때문에 Base 객체를 생성할 수 없다.
newCopy에 기본 구현을 제공하고 그것을 보통의 가상 함수로 정의하는 직관적 해결책도 역시 실패한다. 컨테이너가 Base(Base const &other)를 호출하기 때문인데, 이 호출 때문에 other를 복사하기 위하여 newCopy가 호출되기 때문이다. 이 시점에서는 그 사본으로 무엇을 해야 할지 분명하지 않다. 새로운 Base 객체가 이미 존재하고, newCopy의 반환 값을 할당할 Base 포인터나 참조 멤버 데이터가 없기 때문이다.
대안으로 (더 좋은 것은) 원래의 Base 클래스를 (추상 바탕 클래스에 정의된) 그대로 두는 것이다. Clonable 포장 클래스를 사용하여 newCopy가 돌려주는 Base 클래스 포인터를 관리하는 편이 더 좋다. 제 17장에 Base와 Clonable를 하나의 클래스에 합병하는 여러 방법을 연구한다. 그러나 지금 당장은 Base와 Clonable 클래스를 따로 정의하겠다.
Clonable 클래스는 아주 표준적인 클래스이다. 안에 포인터 멤버가 있으므로 복사 생성자와 소멸자 그리고 중복정의 할당 연산자가 필요하다. 적어도 하나의 비-표준 멤버가 주어진다. Base &base() const가 그것으로서, Clonable의 Base * 멤버 데이터가 참조하는 파생 객체를 참조로 돌려준다. 또 그의 Base * 멤버 데이터를 초기화하는 생성자도 제공된다.
Base로부터 파생된 비-추상 클래스는 Base *newCopy()를 구현해야 한다. 이 멤버는 새로 생성된 (할당된), newCopy가 호출될 객체의 사본을 포인터로 돌려준다.
파생 클래스를 (즉, Derived1을) 정의했다면 Clonable과 Base 편의기능을 이용할 수 있다. 다음 예제를 보면 main에 vector<Clonable>이 정의된 것을 볼 수 있다. 익명의 Derived1 객체는 그러면 다음 단계를 거쳐 벡터에 삽입된다.
Derived1 객체가 생성된다.
Clonable(Base *bp)를 사용하여 Clonable을 초기화한다.
Clonable 객체가 Clonable의 이동 생성자를 사용하여 벡터에 삽입된다. 이 시점에 익명의 Derived와 Clonable 객체만 있다. 그래서 복사 생성은 요구되지 않는다.
Derived1 *을 담은 Clonable 객체만 사용된다. 사본을 더 만들 필요가 없다 (또 파괴할 필요도 없다).
다음으로 base 멤버를 typeid와 함께 사용하여 Base & 객체의 실제 유형을 보여준다. Derived1 객체가 실제 유형이다.
Main에 있는 vector<Clonable> v2(bv) 정의는 자못 흥미롭다. 여기에서 bv의 사본이 생성된다. 이 사본 생성은 Base 참조의 실제 유형을 살펴보고 적절한 유형이 벡터의 사본에 나타나는지 확인한다.
프로그램의 끝에서 Derived1 객체를 두 개 만들었다. 이 두 객체는 벡터의 소멸자에 의해서 올바르게 제거된다. 다음은 전체 프로그램이다. `가상 생성자'의 개념을 보여준다 (제시 반 덴 키붐(Jesse van den Kieboom)은 Clonable를 다르게 구현하였다. 클래스 템플릿으로 구현했다. 구현은 여기에 있다.):
#include <iostream>
#include <vector>
#include <algorithm>
#include <typeinfo>
// Base와 그의 인라인 멤버:
class Base
{
public:
virtual ~Base();
Base *clone() const;
private:
virtual Base *newCopy() const = 0;
};
inline Base *Base::clone() const
{
return newCopy();
}
// Clonable과 그의 인라인 멤버들:
class Clonable
{
Base *d_bp;
public:
Clonable();
explicit Clonable(Base *base);
~Clonable();
Clonable(Clonable const &other);
Clonable(Clonable &&tmp);
Clonable &operator=(Clonable const &other);
Clonable &operator=(Clonable &&tmp);
Base &base() const;
};
inline Clonable::Clonable()
:
d_bp(0)
{}
inline Clonable::Clonable(Base *bp)
:
d_bp(bp)
{}
inline Clonable::Clonable(Clonable const &other)
:
d_bp(other.d_bp->clone())
{}
inline Clonable::Clonable(Clonable &&tmp)
:
d_bp(tmp.d_bp)
{
tmp.d_bp = 0;
}
inline Clonable::~Clonable()
{
delete d_bp;
}
inline Base &Clonable::base() const
{
return *d_bp;
}
// Derived와 그의 인라인 멤버:
class Derived1: public Base
{
public:
~Derived1();
private:
virtual Base *newCopy() const;
};
inline Base *Derived1::newCopy() const
{
return new Derived1(*this);
}
// 인라인으로 구현되지 않은 멤버들:
Base::~Base()
{}
Clonable &Clonable::operator=(Clonable const &other)
{
Clonable tmp(other);
std::swap(d_bp, tmp.d_bp);
return *this;
}
Clonable &Clonable::operator=(Clonable &&tmp)
{
std::swap(d_bp, tmp.d_bp);
return *this;
}
Derived1::~Derived1()
{
std::cout << "~Derived1() called\n";
}
// 메인 함수:
using namespace std;
int main()
{
vector<Clonable> bv;
bv.push_back(Clonable(new Derived1()));
cout << "bv[0].name: " << typeid(bv[0].base()).name() << '\n';
vector<Clonable> v2(bv);
cout << "v2[0].name: " << typeid(v2[0].base()).name() << '\n';
}
/*
출력:
bv[0].name: 8Derived1
v2[0].name: 8Derived1
~Derived1() called
~Derived1() called
*/